SpecLoR: Spectral Lookahead Rectification for Motion-Coherent Text-to-Video Generation
Pith reviewed 2026-06-27 09:58 UTC · model grok-4.3
The pith
SpecLoR corrects drifted sampling trajectories in text-to-video generation by rectifying the amplitude spectrum of lookahead clean latents to match natural video priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
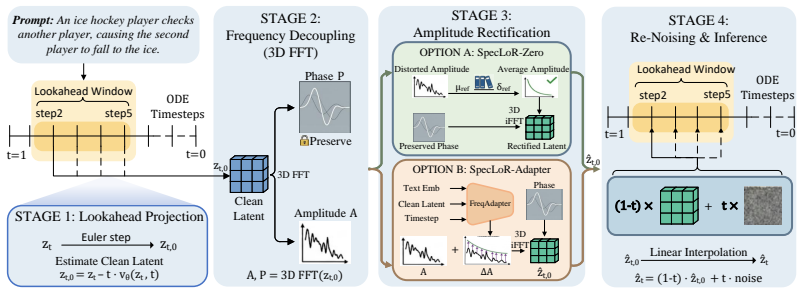
SpecLoR performs lookahead to estimate the clean latent z_{t,0} early in sampling, computes its 3D spatiotemporal spectrum, rectifies the amplitude to match the prior of natural videos while leaving phase intact, and re-noises the corrected state to resume ODE integration, reducing physical artifacts and enhancing motion coherence.
What carries the argument
Spectral Lookahead Rectification, which shifts correction to the frequency domain by matching amplitude spectra of early clean latent estimates to natural video priors while preserving phase.
If this is right
- Sampling trajectories stay closer to the manifold of natural videos.
- Physical artifacts such as inconsistent object trajectories decrease across benchmarks.
- Motion coherence improves while adding only four neural function evaluations.
- Corrections avoid direct spatial edits that would risk local geometry and incur high cost.
Where Pith is reading between the lines
- The same amplitude-matching step could be tested on image or 3D generative models that use flow or diffusion sampling.
- Adaptive choice of when to apply the lookahead step might further reduce overhead on longer sequences.
- Frequency-domain priors may prove more stable than spatial priors when videos contain complex camera motion.
- The method leaves open whether phase information alone is always sufficient or whether limited phase adjustments would help in some cases.
Load-bearing premise
The three-dimensional spatiotemporal amplitude spectrum of natural videos supplies a universal, timestep-independent prior that amplitude rectification alone can safely enforce.
What would settle it
Generate matched sets of videos with and without SpecLoR on identical prompts and measure whether physical artifact counts or motion coherence scores differ by a statistically detectable margin.
Figures


read the original abstract
Flow Matching has enabled robust text-to-video generation via latent ODE sampling. However, velocity approximation and numerical discretization errors inevitably accumulate, causing sampling trajectories to drift. Consequently, generated videos often suffer from severe spatiotemporal inconsistencies. Nevertheless, directly correcting these drifted, noisy latents is challenging: (i) timestep-dependent noise obscures reliable structural cues; (ii) spatial interventions risk disrupting intricate local geometry while incurring heavy computational costs. To address this, we propose Spectral Lookahead Rectification (SpecLoR), a plug-and-play inference method that bypasses noise via lookahead prediction, and circumvents spatiotemporal entanglement by shifting corrections to the frequency domain, where universal statistical priors of natural videos are readily available. First, during early sampling stages, SpecLoR looks ahead to estimate the clean latent $z_{t,0}$ and computes its 3D spatiotemporal spectrum. Next, SpecLoR rectifies the amplitude spectrum to match the prior, leaving the phase intact. Finally, the corrected state is re-noised to resume ODE integration. Experiments on Wan2.2 demonstrate that SpecLoR significantly reduces physical artifacts and enhances motion coherence across multiple benchmarks with minimal computational overhead (4 additional NFEs).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Spectral Lookahead Rectification (SpecLoR), a plug-and-play inference-time correction for flow-matching text-to-video models. During early sampling, it computes a lookahead estimate of the clean latent z_{t,0}, extracts its 3D spatiotemporal amplitude spectrum, rectifies the amplitude to match a fixed prior derived from natural videos while preserving phase, and re-noises the result to continue ODE integration. The central claim is that this reduces physical artifacts and improves motion coherence on the Wan2.2 model with only 4 additional NFEs.
Significance. If the empirical claims hold, SpecLoR would supply a lightweight, training-free mechanism for enforcing universal spectral statistics to counteract drift in latent video ODEs. The frequency-domain formulation avoids direct spatial edits and the explicit use of a timestep-independent natural-video prior is a clear conceptual contribution. The low overhead (4 NFEs) would make it attractive for practical deployment if the gains are reproducible across models and benchmarks.
major comments (3)
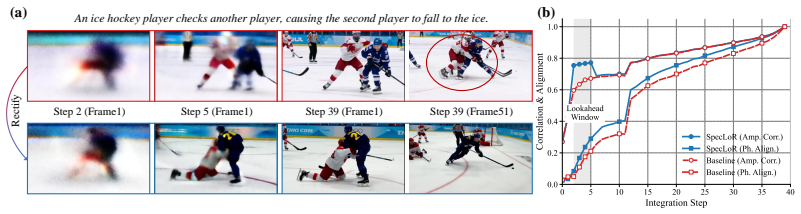
- [Method description (lookahead rectification step)] The central claim requires that early-stage lookahead estimates z_{t,0} already contain usable structural signal rather than being dominated by velocity-approximation error. No measurement or ablation of lookahead fidelity (e.g., PSNR or spectrum correlation versus timestep or noise level) is supplied, leaving the load-bearing assumption untested.
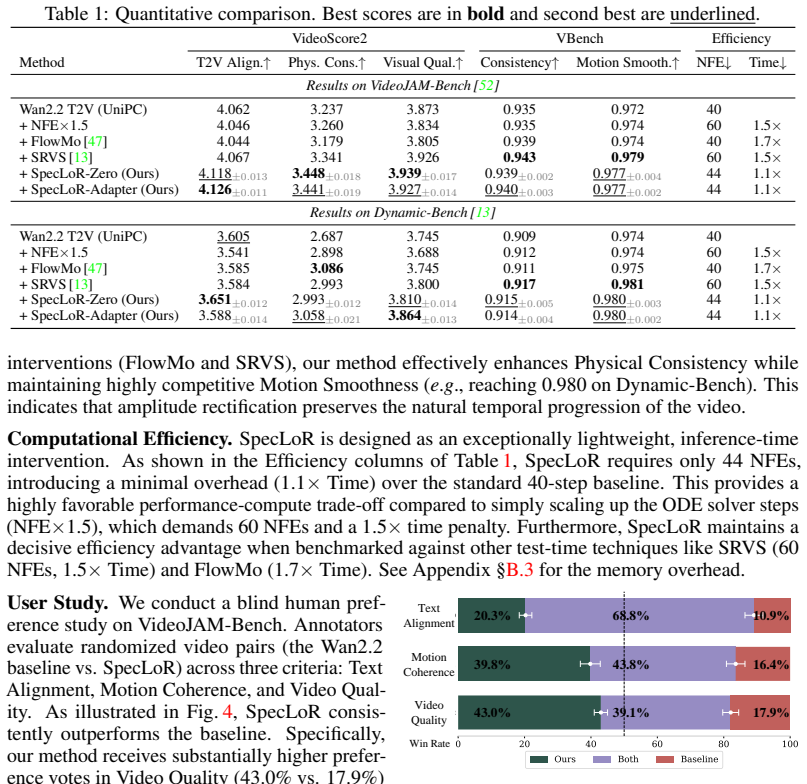
- [Abstract and Experiments section] The abstract states that SpecLoR 'significantly reduces physical artifacts and enhances motion coherence across multiple benchmarks' yet reports neither quantitative metrics, error bars, baseline comparisons, nor ablation results. Without these data the magnitude and reliability of the claimed improvement cannot be assessed.
- [Spectral rectification procedure] The method assumes the 3D amplitude spectrum of natural videos constitutes a universal, timestep-independent prior that can be matched by amplitude-only rectification. No derivation or sensitivity analysis is given showing why phase preservation plus amplitude matching is sufficient to restore geometry rather than introducing new inconsistencies.
minor comments (1)
- [Method] Notation for the lookahead estimate (z_{t,0}) and the re-noising step should be defined explicitly with reference to the underlying flow-matching ODE.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below and will revise the manuscript to incorporate additional analysis and clarifications where appropriate.
read point-by-point responses
-
Referee: [Method description (lookahead rectification step)] The central claim requires that early-stage lookahead estimates z_{t,0} already contain usable structural signal rather than being dominated by velocity-approximation error. No measurement or ablation of lookahead fidelity (e.g., PSNR or spectrum correlation versus timestep or noise level) is supplied, leaving the load-bearing assumption untested.
Authors: We agree that direct validation of lookahead fidelity strengthens the central assumption. In the revised manuscript we will add an ablation that reports PSNR and 3D spectral correlation between the lookahead estimate z_{t,0} and the corresponding clean latent, evaluated across a range of early timesteps and noise levels on the Wan2.2 model. revision: yes
-
Referee: [Abstract and Experiments section] The abstract states that SpecLoR 'significantly reduces physical artifacts and enhances motion coherence across multiple benchmarks' yet reports neither quantitative metrics, error bars, baseline comparisons, nor ablation results. Without these data the magnitude and reliability of the claimed improvement cannot be assessed.
Authors: The experiments section already contains quantitative metrics, baseline comparisons, and ablations; however, the abstract presents only a qualitative summary. We will revise the abstract to include specific numerical improvements (with error bars) drawn from the reported results and will ensure all claims are directly supported by the quantitative tables and figures. revision: yes
-
Referee: [Spectral rectification procedure] The method assumes the 3D amplitude spectrum of natural videos constitutes a universal, timestep-independent prior that can be matched by amplitude-only rectification. No derivation or sensitivity analysis is given showing why phase preservation plus amplitude matching is sufficient to restore geometry rather than introducing new inconsistencies.
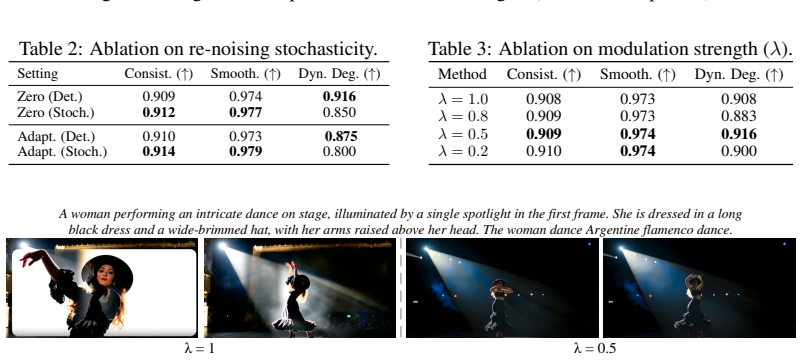
Authors: We will add a short derivation in the method section that recalls the classical result that phase encodes structural geometry while amplitude governs energy distribution across frequencies; we will also include a sensitivity study that varies the strength of amplitude rectification and measures resulting geometric consistency (via optical-flow and edge-alignment metrics) to demonstrate that the chosen prior does not introduce new inconsistencies. revision: yes
Circularity Check
No significant circularity; derivation uses external natural-video priors
full rationale
The paper presents SpecLoR as an inference-time correction that computes a 3D spatiotemporal spectrum from an early lookahead estimate of the clean latent z_{t,0}, then matches its amplitude to a fixed prior derived from natural videos while preserving phase. No equations, fitted parameters, or self-citations are shown that would make the rectification reduce to a self-definitional fit, a renamed input, or a load-bearing self-citation chain. The prior is described as an external universal statistical property independent of the current sampling trajectory, and the method is framed as a plug-and-play addition rather than a tautological re-expression of its own inputs. The central claim therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. HunyuanVideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, et al. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Kling Team, Jialu Chen, Yuanzheng Ci, Xiangyu Du, Zipeng Feng, Kun Gai, Sainan Guo, Feng Han, Jingbin He, Kang He, et al. Kling-Omni technical report.arXiv preprint arXiv:2512.16776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Phenaki: Variable length video generation from open domain textual descriptions
Ruben Villegas, Mohammad Babaeizadeh, Pieter-Jan Kindermans, Hernan Moraldo, Han Zhang, Moham- mad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. Phenaki: Variable length video generation from open domain textual descriptions. InInt. Conf. Learn. Represent., 2023
2023
-
[6]
Waver: Wave your way to lifelike video genera- tion.arXiv preprint arXiv:2508.15761, 2025
Yifu Zhang, Hao Yang, Yuqi Zhang, Yifei Hu, Fengda Zhu, Chuang Lin, Xiaofeng Mei, Yi Jiang, Bingyue Peng, and Zehuan Yuan. Waver: Wave your way to lifelike video generation.arXiv preprint arXiv:2508.15761, 2025
-
[7]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Seedance 2.0: Advancing Video Generation for World Complexity
Team Seedance. Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2604.14148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InInt. Conf. Learn. Represent., 2023
2023
-
[10]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, et al. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInt. Conf. Learn. Represent., 2023
2023
-
[11]
FreeInit: Bridging initialization gap in video diffusion models
Tianxing Wu, Chenyang Si, Yuming Jiang, Ziqi Huang, and Ziwei Liu. FreeInit: Bridging initialization gap in video diffusion models. InEur. Conf. Comput. Vis., pages 378–394. Springer, 2024
2024
-
[12]
Restart sampling for improving generative processes
Yilun Xu, Mingyang Deng, Xiang Cheng, Yonglong Tian, Ziming Liu, and Tommi Jaakkola. Restart sampling for improving generative processes. InAdv. Neural Inform. Process. Syst., pages 76806–76838, 2023
2023
-
[13]
Sangwon Jang, Taekyung Ki, Jaehyeong Jo, Saining Xie, Jaehong Yoon, and Sung Ju Hwang. Self-refining video sampling.arXiv preprint arXiv:2601.18577, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
A general framework for inference-time scaling and steering of diffusion models
Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and Rajesh Ranganath. A general framework for inference-time scaling and steering of diffusion models. InInt. Conf. Mach. Learn., 2024
2024
-
[15]
Inference-time text-to-video alignment with diffusion latent beam search
Yuta Oshima, Masahiro Suzuki, Yutaka Matsuo, and Hiroki Furuta. Inference-time text-to-video alignment with diffusion latent beam search. InAdv. Neural Inform. Process. Syst., 2025
2025
-
[16]
Haoran He, Jiajun Liang, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, and Ling Pan. Scaling image and video generation via test-time evolutionary search.arXiv preprint arXiv:2505.17618, 2025
-
[17]
FreqPrior: Improving video diffusion models with frequency filtering gaussian noise
Yunlong Yuan, Yuanfan Guo, Chunwei Wang, Wei Zhang, Hang Xu, and Li Zhang. FreqPrior: Improving video diffusion models with frequency filtering gaussian noise. InInt. Conf. Learn. Represent., 2025
2025
-
[18]
Statistics of natural time-varying images.Network: computation in neural systems, 6(3):345, 1995
Dawei W Dong and Joseph J Atick. Statistics of natural time-varying images.Network: computation in neural systems, 6(3):345, 1995
1995
-
[19]
The importance of phase in signals.Proceedings of the IEEE, 69(5):529–541, 1981
Alan V Oppenheim and Jae S Lim. The importance of phase in signals.Proceedings of the IEEE, 69(5):529–541, 1981
1981
-
[20]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdv. Neural Inform. Process. Syst., volume 33, pages 6840–6851, 2020. 10
2020
-
[21]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InIEEE Conf. Comput. Vis. Pattern Recog., pages 10684– 10695, 2022
2022
-
[22]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Building normalizing flows with stochastic interpolants
Michael Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InInt. Conf. Learn. Represent., 2023
2023
-
[24]
Maojiang Su, Mingcheng Lu, Jerry Yao-Chieh Hu, Shang Wu, Zhao Song, Alex Reneau, and Han Liu. A theoretical analysis of discrete flow matching generative models.arXiv preprint arXiv:2509.22623, 2025
-
[25]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InInt. Conf. Comput. Vis., pages 4195–4205, 2023
2023
-
[26]
HunyuanVideo 1.5 Technical Report
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Unipc: A unified predictor-corrector framework for fast sampling of diffusion models
Wenliang Zhao, Lujia Bai, Yongming Rao, Jie Zhou, and Jiwen Lu. Unipc: A unified predictor-corrector framework for fast sampling of diffusion models. InAdv. Neural Inform. Process. Syst., volume 36, pages 49842–49869, 2023
2023
-
[28]
Temporal regularization makes your video generator stronger.arXiv preprint arXiv:2503.15417, 2025
Harold Haodong Chen, Haojian Huang, Xianfeng Wu, Yexin Liu, Yajing Bai, Wen-Jie Shu, Harry Yang, and Ser-Nam Lim. Temporal regularization makes your video generator stronger.arXiv preprint arXiv:2503.15417, 2025
-
[29]
Xueji Fang, Liyuan Ma, Zhiyang Chen, Mingyuan Zhou, and Guo-jun Qi. InfLVG: Reinforce inference- time consistent long video generation with grpo.arXiv preprint arXiv:2505.17574, 2025
-
[30]
Video-T1: Test-time scaling for video generation
Fangfu Liu, Hanyang Wang, Yimo Cai, Kaiyan Zhang, Xiaohang Zhan, and Yueqi Duan. Video-T1: Test-time scaling for video generation. InInt. Conf. Comput. Vis., pages 18671–18681, 2025
2025
-
[31]
Improving Video Generation with Human Feedback
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Menghan Xia, Xintao Wang, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Enhance-A-Video: Better generated video for free.arXiv preprint arXiv:2502.07508, 2025
Yang Luo, Xuanlei Zhao, Mengzhao Chen, Kaipeng Zhang, Wenqi Shao, Kai Wang, Zhangyang Wang, and Yang You. Enhance-A-Video: Better generated video for free.arXiv preprint arXiv:2502.07508, 2025
-
[33]
Optical-flow guided prompt optimization for coherent video generation
Hyelin Nam, Jaemin Kim, Dohun Lee, and Jong Chul Ye. Optical-flow guided prompt optimization for coherent video generation. InIEEE Conf. Comput. Vis. Pattern Recog., pages 7837–7846, 2025
2025
-
[34]
FreeNoise: Tuning-free longer video diffusion via noise rescheduling
Haonan Qiu, Menghan Xia, Yong Zhang, Yingqing He, Xintao Wang, Ying Shan, and Ziwei Liu. FreeNoise: Tuning-free longer video diffusion via noise rescheduling. InInt. Conf. Learn. Represent., 2024
2024
-
[35]
FreeLong: Training-free long video generation with spectralblend temporal attention
Yu Lu, Yuanzhi Liang, Linchao Zhu, and Yi Yang. FreeLong: Training-free long video generation with spectralblend temporal attention. InAdv. Neural Inform. Process. Syst., pages 131434–131455, 2024
2024
-
[36]
LongDiff: Training-free long video generation in one go
Zhuoling Li, Hossein Rahmani, Qiuhong Ke, and Jun Liu. LongDiff: Training-free long video generation in one go. InIEEE Conf. Comput. Vis. Pattern Recog., pages 17789–17798, 2025
2025
-
[37]
VideoGuide: Improving video diffusion models without training through a teacher’s guide
Dohun Lee, Bryan Sangwoo Kim, Geon Yeong Park, and Jong Chul Ye. VideoGuide: Improving video diffusion models without training through a teacher’s guide. InIEEE Conf. Comput. Vis. Pattern Recog., pages 2599–2608, 2025
2025
-
[38]
Pascal Chang, Jingwei Tang, Markus Gross, and Vinicius C. Azevedo. How i warped your noise: a temporally-correlated noise prior for diffusion models. InInt. Conf. Learn. Represent., 2024
2024
-
[39]
Mariam Hassan, Bastien Van Delft, Wuyang Li, and Alexandre Alahi. Factorized video generation: Decoupling scene construction and temporal synthesis in text-to-video diffusion models.arXiv preprint arXiv:2512.16371, 2025
-
[40]
Yang Fei, George Stoica, Jingyuan Liu, Qifeng Chen, Ranjay Krishna, Xiaojuan Wang, and Benlin Liu. Structure from tracking: Distilling structure-preserving motion for video generation.arXiv preprint arXiv:2512.11792, 2025. 11
-
[41]
Ahmet Berke Gokmen, Yigit Ekin, Bahri Batuhan Bilecen, and Aysegul Dundar. RoPECraft: Training- free motion transfer with trajectory-guided rope optimization on diffusion transformers.arXiv preprint arXiv:2505.13344, 2025
-
[42]
Chenhui Zhu, Yilu Wu, Shuai Wang, Gangshan Wu, and Limin Wang. MotionRAG: Motion retrieval- augmented image-to-video generation.arXiv preprint arXiv:2509.26391, 2025
-
[43]
Weichen Fan, Amber Yijia Zheng, Raymond A Yeh, and Ziwei Liu. CFG-Zero*: Improved classifier-free guidance for flow matching models.arXiv preprint arXiv:2503.18886, 2025
-
[44]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021
2021
-
[45]
Diffusion rejection sampling
Byeonghu Na, Yeongmin Kim, Minsang Park, Donghyeok Shin, Wanmo Kang, and Il Chul Moon. Diffusion rejection sampling. InInt. Conf. Mach. Learn., volume 235, pages 37097–37121, 2024
2024
-
[46]
Test-time scaling of diffusion models via noise trajectory search
Vignav Ramesh and Morteza Mardani. Test-time scaling of diffusion models via noise trajectory search. InAdv. Neural Inform. Process. Syst., 2025
2025
-
[47]
Ariel Shaulov, Itay Hazan, Lior Wolf, and Hila Chefer. FlowMo: Variance-based flow guidance for coherent motion in video generation.arXiv preprint arXiv:2506.01144, 2025
-
[48]
Improved video vae for latent video diffusion model
Pingyu Wu, Kai Zhu, Yu Liu, Liming Zhao, Wei Zhai, Yang Cao, and Zheng-Jun Zha. Improved video vae for latent video diffusion model. InIEEE Conf. Comput. Vis. Pattern Recog., pages 18124–18133, 2025
2025
-
[49]
Fourier priors-guided diffusion for zero-shot joint low-light enhancement and deblurring
Xiaoqian Lv, Shengping Zhang, Chenyang Wang, Yichen Zheng, Bineng Zhong, Chongyi Li, and Liqiang Nie. Fourier priors-guided diffusion for zero-shot joint low-light enhancement and deblurring. InIEEE Conf. Comput. Vis. Pattern Recog., pages 25378–25388, 2024
2024
-
[50]
FreeU: Free lunch in diffusion u-net
Chenyang Si, Ziqi Huang, Yuming Jiang, and Ziwei Liu. FreeU: Free lunch in diffusion u-net. InIEEE Conf. Comput. Vis. Pattern Recog., pages 4733–4743, 2024
2024
-
[51]
FAM Diffusion: Frequency and attention modulation for high-resolution image generation with stable diffusion
Haosen Yang, Adrian Bulat, Isma Hadji, Hai X Pham, Xiatian Zhu, Georgios Tzimiropoulos, and Brais Martinez. FAM Diffusion: Frequency and attention modulation for high-resolution image generation with stable diffusion. InIEEE Conf. Comput. Vis. Pattern Recog., pages 2459–2468, 2025
2025
-
[52]
Hila Chefer, Uriel Singer, Amit Zohar, Yuval Kirstain, Adam Polyak, Yaniv Taigman, Lior Wolf, and Shelly Sheynin. VideoJAM: Joint appearance-motion representations for enhanced motion generation in video models.arXiv preprint arXiv:2502.02492, 2025
-
[53]
Xuan He, Dongfu Jiang, Ping Nie, Minghao Liu, Zhengxuan Jiang, Mingyi Su, Wentao Ma, Junru Lin, Chun Ye, Yi Lu, et al. VideoScore2: Think before you score in generative video evaluation.arXiv preprint arXiv:2509.22799, 2025
-
[54]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. VBench: Comprehensive benchmark suite for video generative models. InIEEE Conf. Comput. Vis. Pattern Recog., pages 21807–21818, 2024
2024
-
[55]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie Gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinyuan Chen, Yaohui Wang, Ping Luo, Ziwei Liu, Yali Wang, Limin Wang, and Yu Qiao. InternVid: A large-scale video-text dataset for multimodal understanding and generation.arXiv preprint arXiv:2307.06942, 2023. 12 A Summary of the Appendix We provide additional details and comprehensive analys...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.