MODF-SIR: A Multi-agent Omni-modal Distilled Framework for Social Intelligence Reasoning
Pith reviewed 2026-06-27 09:42 UTC · model grok-4.3
The pith
A multi-agent framework on a lightweight multimodal model reaches state-of-the-art social reasoning with roughly 30 percent of the training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
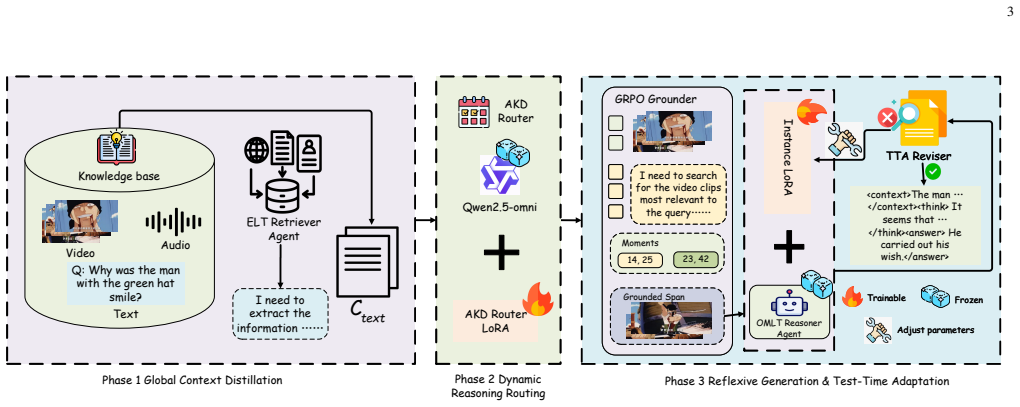
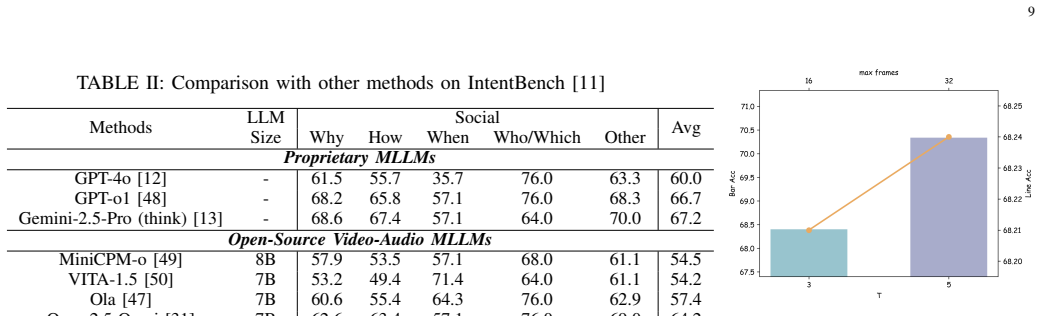
The framework integrates multi-agent collaboration, precise localization of multi-modal social data, extraction of long-tail events into formatted text, and distillation-enhanced test-time adaptation with LoRA fine-tuning on a lightweight MLLM, enabling state-of-the-art results on social intelligence reasoning benchmarks while using only around 30 percent of the training data from IntentTrain.
What carries the argument
The MODF-SIR multi-agent omni-modal distilled framework that augments a lightweight MLLM with knowledge distillation, long-tail event text extraction, and distillation-enhanced test-time adaptation across the full reasoning pipeline.
If this is right
- Long-tail social events can be preserved and used effectively by converting them to explicit text before tokenization.
- Test-time adaptation applied to extraction, chain-of-thought, and self-reflection steps improves instance-level reasoning without full retraining.
- State-of-the-art performance on social benchmarks is achievable with substantially less training data than standard approaches.
- Multi-agent division of labor allows the system to localize relevant multi-modal inputs and handle noise from head events.
Where Pith is reading between the lines
- If the gains trace mainly to explicit text formatting of rare events, the same step could be tested on other multimodal tasks that suffer from imbalanced signal strength.
- The low data requirement opens the possibility of deploying similar systems on smaller curated datasets for domains where full-scale training data is scarce.
- Adding self-reflection inside the adapted pipeline may point to iterative refinement as a general lever for improving social or commonsense reasoning.
Load-bearing premise
The combination of multi-agent collaboration, long-tail event extraction to text, distillation-enhanced test-time adaptation, and LoRA fine-tuning produces genuine gains in social reasoning rather than benchmark-specific improvements.
What would settle it
An ablation study that removes the multi-agent structure, the long-tail event text conversion, and the distillation-enhanced TTA while keeping the base lightweight model and training data fixed, then checks whether benchmark scores remain comparable or drop sharply.
Figures



read the original abstract
We propose a multi-agent collaborative framework built upon a lightweight Multimodal Large Language Model (MLLM), specifically designed for social intelligence reasoning. A key feature of our approach is that both the training and inference phases are augmented via knowledge distillation. Within this architecture, multi-modal data pertinent to social intelligence is precisely localized. Furthermore, relevant long-tail events are identified, extracted, and rendered as formatted, explicit text. This formatting strategy prevents critical long-tail information from being overshadowed by head events and environmental noise during the tokenization process. Specifically, we integrate Test-Time Adaptation (TTA) across the entire reasoning pipeline, encompassing the extraction and representation of long-tail events, Chain-of-Thought (CoT) prompting, and self-reflection. This TTA mechanism is also distillation-enhanced, utilizing Low-Rank Adaptation (LoRA) to fine-tune the foundation model exclusively for instance-level reasoning. Extensive evaluations against various open-source and proprietary AI models across multiple benchmarks demonstrate the effectiveness of the proposed framework. With around 30% of training data from IntentTrain, we achieve state-of-the-art results. Codes are available at https://github.com/eeee-sys/MODF-SIR, demo is available at https://huggingface.co/spaces/Harry-1234/MODF-SIR, LoRA is available at https://huggingface.co/Harry-1234/MODF-SIR and the dataset for training router is available at https://huggingface.co/datasets/Harry-1234/IntentRouterTrain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MODF-SIR, a multi-agent collaborative framework built on a lightweight Multimodal Large Language Model (MLLM) for social intelligence reasoning. Training and inference are augmented by knowledge distillation; multi-modal social data is localized, long-tail events are extracted and rendered as explicit formatted text to avoid overshadowing during tokenization, and the pipeline incorporates distillation-enhanced Test-Time Adaptation (TTA) with Chain-of-Thought prompting, self-reflection, and LoRA fine-tuning for instance-level reasoning. The authors claim state-of-the-art results across multiple benchmarks while using only around 30% of the training data from IntentTrain.
Significance. If the empirical claims hold and the gains are shown to arise from the architecture rather than benchmark-specific tuning, the combination of multi-agent collaboration, explicit long-tail event handling, and distillation-enhanced TTA on a lightweight MLLM could provide an efficient, data-frugal approach to social reasoning tasks, with potential impact on multi-agent MLLM systems.
major comments (2)
- [Abstract] Abstract: the central claim of achieving state-of-the-art results 'across multiple benchmarks' is unsupported by any named benchmarks, baseline models, metrics, error bars, ablation studies, or held-out validation details, rendering the contribution impossible to evaluate.
- [Abstract] Abstract: no evidence is supplied that performance improvements derive from multi-agent collaboration, long-tail event extraction, or distillation-enhanced TTA rather than data selection, prompt engineering, or test-time adaptation tuned to the (unspecified) benchmarks.
minor comments (1)
- [Abstract] Abstract: the term 'omni-modal' in the title is not defined or distinguished from the 'multi-modal' usage in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting issues with the abstract. We agree that the abstract requires revision to include specific details on benchmarks, baselines, metrics, and evidence for component contributions. The full manuscript contains these elements in the experiments and ablations sections, but we will update the abstract and clarify attributions in a revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of achieving state-of-the-art results 'across multiple benchmarks' is unsupported by any named benchmarks, baseline models, metrics, error bars, ablation studies, or held-out validation details, rendering the contribution impossible to evaluate.
Authors: We agree the abstract is too high-level and omits these specifics, making evaluation difficult from the abstract alone. The full manuscript reports results on named benchmarks including IntentTrain and others, with comparisons to open-source and proprietary baselines, specific metrics, ablation studies, and held-out validation. Error bars appear in experimental figures. We will revise the abstract to name the benchmarks, list key baselines and metrics, reference the ablation studies, and note the use of 30% training data from IntentTrain. revision: yes
-
Referee: [Abstract] Abstract: no evidence is supplied that performance improvements derive from multi-agent collaboration, long-tail event extraction, or distillation-enhanced TTA rather than data selection, prompt engineering, or test-time adaptation tuned to the (unspecified) benchmarks.
Authors: The manuscript includes dedicated ablation studies and analyses in the experiments section that isolate the contributions of multi-agent collaboration, long-tail event extraction/rendering as formatted text, and distillation-enhanced TTA with LoRA and self-reflection. These show gains beyond basic TTA or prompt engineering. However, the abstract does not reference this evidence. We will revise the abstract to briefly note these components and their demonstrated roles, and ensure the main text more explicitly contrasts against alternative explanations such as data selection. No new experiments are required as the ablations already address this. revision: yes
Circularity Check
No circularity: empirical framework with external benchmarks
full rationale
The paper proposes an engineering framework (multi-agent collaboration, long-tail event extraction to text, distillation-enhanced TTA, LoRA) and reports empirical SOTA results on benchmarks using ~30% IntentTrain data. No equations, derivations, or mathematical claims exist that could reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains. All load-bearing claims rest on external benchmark evaluations, which are falsifiable outside the paper. No self-citations are invoked as uniqueness theorems or to justify ansatzes. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Machine theory of mind,
N. Rabinowitz, F. Perbet, F. Song, C. Zhang, S. A. Eslami, and M. Botvinick, “Machine theory of mind,” inInternational conference on machine learning. PMLR, 2018, pp. 4218–4227
2018
-
[2]
Un- derstanding and sharing intentions: The origins of cultural cognition,
M. Tomasello, M. Carpenter, J. Call, T. Behne, and H. Moll, “Un- derstanding and sharing intentions: The origins of cultural cognition,” Behavioral and brain sciences, vol. 28, no. 5, pp. 675–691, 2005
2005
-
[3]
De- constructing and reconstructing theory of mind,
S. M. Schaafsma, D. W. Pfaff, R. P. Spunt, and R. Adolphs, “De- constructing and reconstructing theory of mind,”Trends in cognitive sciences, vol. 19, no. 2, pp. 65–72, 2015
2015
-
[4]
The neural basis of mentalizing,
C. D. Frith and U. Frith, “The neural basis of mentalizing,”Neuron, vol. 50, no. 4, pp. 531–534, 2006
2006
-
[5]
Mtag: Modal-temporal attention graph for unaligned human multimodal language sequences,
J. Yang, Y . Wang, R. Yi, Y . Zhu, A. Rehman, A. Zadeh, S. Poria, and L.-P. Morency, “Mtag: Modal-temporal attention graph for unaligned human multimodal language sequences,” inProceedings of the 2021 conference of the North American chapter of the association for com- putational linguistics: human language technologies, 2021, pp. 1009– 1021
2021
-
[6]
The multimodal facilitation effect in human communication,
L. Drijvers and J. Holler, “The multimodal facilitation effect in human communication,”Psychonomic Bulletin & Review, vol. 30, no. 2, pp. 792–801, 2023
2023
-
[7]
Kahneman,Thinking, fast and slow
D. Kahneman,Thinking, fast and slow. macmillan, 2011
2011
-
[8]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging llm-as-a-judge with mt-bench and chatbot arena,”Advances in neural information processing systems, vol. 36, pp. 46 595–46 623, 2023
2023
-
[9]
Worldsense: Evaluating real-world omnimodal understanding for multimodal llms,
J. Hong, S. Yan, J. Cai, X. Jiang, Y . Hu, and W. Xie, “Worldsense: Evaluating real-world omnimodal understanding for multimodal llms,” arXiv preprint arXiv:2502.04326, 2025. 10
Pith/arXiv arXiv 2025
-
[10]
Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities,
Z. Zhou, R. Wang, and Z. Wu, “Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities,”arXiv preprint arXiv:2505.17862, 2025
arXiv 2025
-
[11]
Humanomniv2: From understanding to omni- modal reasoning with context,
Q. Yang, S. Yao, W. Chen, S. Fu, D. Bai, J. Zhao, B. Sun, B. Yin, X. Wei, and J. Zhou, “Humanomniv2: From understanding to omni- modal reasoning with context,”arXiv preprint arXiv:2506.21277, 2025
arXiv 2025
-
[12]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radfordet al., “Gpt-4o system card,”arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[13]
Gemini 2.5 Pro,
Google, “Gemini 2.5 Pro,” https://deepmind.google/technologies/gemini/ pro/, 2025
2025
-
[14]
Show and tell: Lessons learned from the 2015 mscoco image captioning challenge,
O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: Lessons learned from the 2015 mscoco image captioning challenge,” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 4, pp. 652–663, 2016
2015
-
[15]
Tgif-qa: Toward spatio- temporal reasoning in visual question answering,
Y . Jang, Y . Song, Y . Yu, Y . Kim, and G. Kim, “Tgif-qa: Toward spatio- temporal reasoning in visual question answering,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2758–2766
2017
-
[16]
A survey on video moment localization,
M. Liu, L. Nie, Y . Wang, M. Wang, and Y . Rui, “A survey on video moment localization,”ACM Computing Surveys, vol. 55, no. 9, pp. 1–37, 2023
2023
-
[17]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdh- ery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,”arXiv preprint arXiv:2203.11171, 2022
Pith/arXiv arXiv 2022
-
[18]
Re- flexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Re- flexion: Language agents with verbal reinforcement learning,”Advances in neural information processing systems, vol. 36, pp. 8634–8652, 2023
2023
-
[19]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
2022
-
[20]
Modularized self-reflected video reasoner for multimodal llm with application to video question answering,
Z. Song, X. Wang, Z. Qian, H. Chen, L. Huang, H. Xue, and W. Zhu, “Modularized self-reflected video reasoner for multimodal llm with application to video question answering,” inForty-second International Conference on Machine Learning, 2025
2025
-
[21]
N. Lian, Y . Wang, H. Yao, J. Wang, B. Chen, Y . Wang, M. Zhang, and S.-T. Xia, “From verbatim to gist: Distilling pyramidal multimodal memory via semantic information bottleneck for long-horizon video agents,”arXiv preprint arXiv:2603.01455, 2026
Pith/arXiv arXiv 2026
-
[22]
Where llm agents fail and how they can learn from failures,
K. Zhu, Z. Liu, B. Li, M. Tian, Y . Yang, J. Zhang, P. Han, Q. Xie, F. Cui, W. Zhanget al., “Where llm agents fail and how they can learn from failures,”arXiv preprint arXiv:2509.25370, 2025
arXiv 2025
-
[23]
From denoising to refining: A corrective framework for vision-language dif- fusion model,
Y . Ji, T. Wang, Y . Ge, Z. Liu, S. Yang, Y . Shan, and P. Luo, “From denoising to refining: A corrective framework for vision-language dif- fusion model,”arXiv preprint arXiv:2510.19871, 2025
arXiv 2025
-
[24]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[25]
An empirical study of catastrophic forgetting in large language models during con- tinual fine-tuning,
Y . Luo, Z. Yang, F. Meng, Y . Li, J. Zhou, and Y . Zhang, “An empirical study of catastrophic forgetting in large language models during con- tinual fine-tuning,”IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[26]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[27]
Howto100m: Learning a text-video embedding by watching hundred million narrated video clips,
A. Miech, D. Zhukov, J.-B. Alayrac, M. Tapaswi, I. Laptev, and J. Sivic, “Howto100m: Learning a text-video embedding by watching hundred million narrated video clips,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 2630–2640
2019
-
[28]
Tall: Temporal activity local- ization via language query,
J. Gao, C. Sun, Z. Yang, and R. Nevatia, “Tall: Temporal activity local- ization via language query,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 5267–5275
2017
-
[29]
Merlot: Multimodal neural script knowledge models,
R. Zellers, X. Lu, J. Hessel, Y . Yu, J. S. Park, J. Cao, A. Farhadi, and Y . Choi, “Merlot: Multimodal neural script knowledge models,” Advances in neural information processing systems, vol. 34, pp. 23 634– 23 651, 2021
2021
-
[30]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
2020
-
[31]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhuet al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025
Pith/arXiv arXiv 2025
-
[32]
Shortcut learning in deep neural networks,
R. Geirhos, J.-H. Jacobsen, C. Michaelis, R. Zemel, W. Brendel, M. Bethge, and F. A. Wichmann, “Shortcut learning in deep neural networks,”Nature Machine Intelligence, vol. 2, no. 11, pp. 665–673, 2020
2020
-
[33]
Winoground: Probing vision and language models for visio- linguistic compositionality,
T. Thrush, R. Jiang, M. Bartolo, A. Singh, A. Williams, D. Kiela, and C. Ross, “Winoground: Probing vision and language models for visio- linguistic compositionality,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2022, pp. 5238–5248
2022
-
[34]
Ov-mer: Towards open-vocabulary multimodal emotion recognition,
Z. Lian, H. Sun, L. Sun, H. Chen, L. Chen, H. Gu, Z. Wen, S. Chen, S. Zhang, H. Yaoet al., “Ov-mer: Towards open-vocabulary multimodal emotion recognition,”arXiv preprint arXiv:2410.01495, 2024
arXiv 2024
-
[35]
Deep long-tailed learning: A survey,
Y . Zhang, B. Kang, B. Hooi, S. Yan, and J. Feng, “Deep long-tailed learning: A survey,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 9, pp. 10 795–10 816, 2023
2023
-
[36]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[37]
Deepseekmath: Pushing the limits of mathematical reasoning in open language models,
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[38]
The acm multimedia 2022 computational paralinguistics challenge: V ocalisations, stuttering, activity, & mosquitoes,
B. Schuller, A. Batliner, S. Amiriparian, C. Bergler, M. Gerczuk, N. Holz, P. Larrouy-Maestri, S. Bayerl, K. Riedhammer, A. Mallol- Ragoltaet al., “The acm multimedia 2022 computational paralinguistics challenge: V ocalisations, stuttering, activity, & mosquitoes,” inProceed- ings of the 30th ACM International Conference on Multimedia, 2022, pp. 7120–7124
2022
-
[39]
Darwin, deception, and facial expression,
P. Ekman, “Darwin, deception, and facial expression,”Annals of the new York Academy of sciences, vol. 1000, no. 1, pp. 205–221, 2003
2003
-
[40]
The” something something
R. Goyal, S. Ebrahimi Kahou, V . Michalski, J. Materzynska, S. West- phal, H. Kim, V . Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitaget al., “The” something something” video database for learning and evaluat- ing visual common sense,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 5842–5850
2017
-
[41]
Slowfast networks for video recognition,
C. Feichtenhofer, H. Fan, J. Malik, and K. He, “Slowfast networks for video recognition,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6202–6211
2019
-
[42]
Multimodal transformer for unaligned multimodal language sequences,
Y .-H. H. Tsai, S. Bai, P. P. Liang, J. Z. Kolter, L.-P. Morency, and R. Salakhutdinov, “Multimodal transformer for unaligned multimodal language sequences,” inProceedings of the 57th annual meeting of the association for computational linguistics, 2019, pp. 6558–6569
2019
-
[43]
Let’s verify step by step,
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe, “Let’s verify step by step,” inThe twelfth international conference on learning represen- tations, 2023
2023
-
[44]
Concrete problems in ai safety,
D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Man ´e, “Concrete problems in ai safety,”arXiv preprint arXiv:1606.06565, 2016
Pith/arXiv arXiv 2016
-
[45]
Unified-io 2: Scaling autoregressive multimodal models with vision language audio and action,
J. Lu, C. Clark, S. Lee, Z. Zhang, S. Khosla, R. Marten, D. Hoiem, and A. Kembhavi, “Unified-io 2: Scaling autoregressive multimodal models with vision language audio and action,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 439–26 455
2024
-
[46]
Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms,
Z. Cheng, S. Leng, H. Zhang, Y . Xin, X. Li, G. Chen, Y . Zhu, W. Zhang, Z. Luo, D. Zhaoet al., “Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms,”arXiv preprint arXiv:2406.07476, 2024
Pith/arXiv arXiv 2024
-
[47]
Ola: Pushing the frontiers of omni-modal language model,
Z. Liu, Y . Dong, J. Wang, Z. Liu, W. Hu, J. Lu, and Y . Rao, “Ola: Pushing the frontiers of omni-modal language model,”arXiv preprint arXiv:2502.04328, 2025
arXiv 2025
-
[48]
A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carneyet al., “Openai o1 system card,”arXiv preprint arXiv:2412.16720, 2024
Pith/arXiv arXiv 2024
-
[49]
Minicpm-v: A gpt-4v level mllm on your phone,
Y . Yao, T. Yu, A. Zhang, C. Wang, J. Cui, H. Zhu, T. Cai, H. Li, W. Zhao, Z. Heet al., “Minicpm-v: A gpt-4v level mllm on your phone,”arXiv preprint arXiv:2408.01800, 2024
Pith/arXiv arXiv 2024
-
[50]
Vita-1.5: Towards gpt-4o level real-time vision and speech interaction,
C. Fu, H. Lin, X. Wang, Y .-F. Zhang, Y . Shen, X. Liu, H. Cao, Z. Long, H. Gao, K. Liet al., “Vita-1.5: Towards gpt-4o level real-time vision and speech interaction,”arXiv preprint arXiv:2501.01957, 2025
Pith/arXiv arXiv 2025
-
[51]
Introducing the next generation of claude,
A. Anthropic, “Introducing the next generation of claude,”https://www. anthropic. com/news/claude-3-family, 2024
2024
-
[52]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,
G. Team, P. Georgiev, V . I. Lei, R. Burnell, L. Bai, A. Gulati, G. Tanzer, D. Vincent, Z. Pan, S. Wanget al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,”arXiv preprint arXiv:2403.05530, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.