ISAP-3D: Identity-Slot Aligned Part-Aware 3D Generation
Pith reviewed 2026-06-27 10:08 UTC · model grok-4.3
The pith
Semantic identity tokens anchor parts to specific slots, eliminating permutation ambiguity in 3D generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
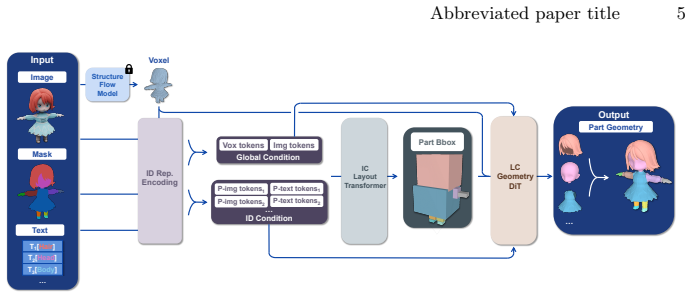
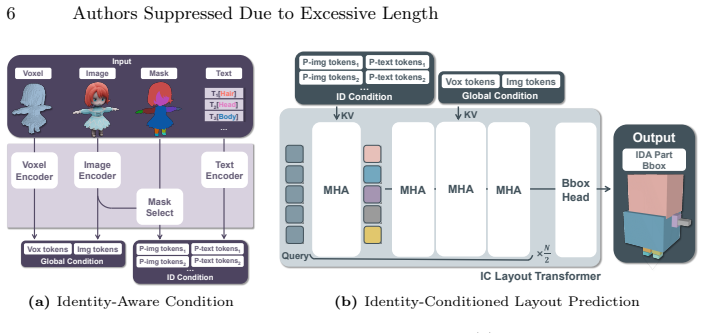
We attribute this ambiguity to identity-slot permutation freedom: without explicit identity-slot alignment, the correspondence between semantic parts and generation slots is not identifiable during training, allowing multiple slot assignments to fit the same supervision and leading to inconsistent decomposition. Based on this insight, we argue that stable part-aware generation requires identity-aligned one-to-one slot modelling. We therefore propose an identity-slot aligned framework, ISAP-3D, which anchors each part with semantic identity tokens and performs identity-conditioned one-to-one layout prediction, followed by layout-conditioned geometry synthesis. Structured local-global conditio
What carries the argument
Semantic identity tokens that anchor each part to enable identity-conditioned one-to-one layout prediction before geometry synthesis.
If this is right
- Part allocation becomes stable without slot swapping or merging.
- Controllability improves because identities directly condition the layout stage.
- Alignment is preserved from semantic tokens through spatial layout to final geometry.
- A unified semantic protocol in the dataset supports consistent identity-slot mapping across objects.
Where Pith is reading between the lines
- Similar explicit anchoring could address assignment ambiguities in other structured generation tasks such as scene layout or multi-object synthesis.
- The dataset construction approach may serve as a template for standardizing part semantics in future 3D benchmarks.
- If identity alignment reduces training variance, it could lower the data requirements for learning consistent part decompositions.
Load-bearing premise
That structural ambiguity is caused primarily by the lack of explicit identity-slot alignment during training.
What would settle it
Training an otherwise identical model without the identity tokens on the same part-level dataset and checking whether slot swapping or merging reappears in the outputs.
Figures





read the original abstract
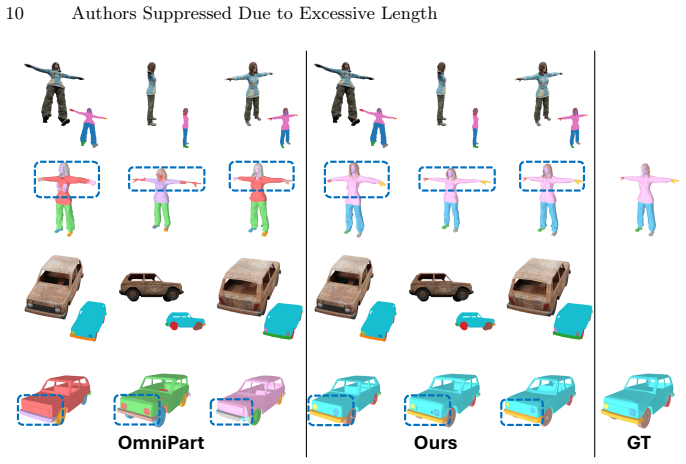
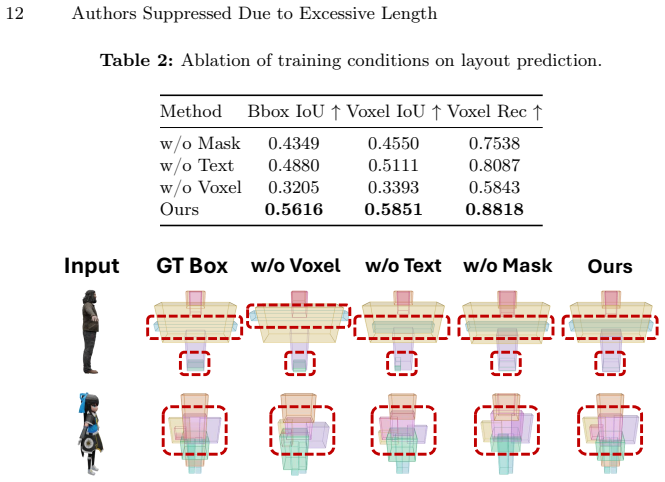
Part-aware 3D generation aims to synthesize structured objects with semantically meaningful components, yet often suffers from structural ambiguity due to identity-layout entanglement. Existing methods either infer part identity and spatial layout implicitly, which can lead to unstable part allocation (e.g., slot swapping or part merging), or rely on strong layout conditions that are difficult to obtain in practice. We attribute this ambiguity to identity-slot permutation freedom: without explicit identity-slot alignment, the correspondence between semantic parts and generation slots is not identifiable during training, allowing multiple slot assignments to fit the same supervision and leading to inconsistent decomposition. Based on this insight, we argue that stable part-aware generation requires identity-aligned one-to-one slot modelling. We therefore propose an identity-slot aligned framework, ISAP-3D, which anchors each part with semantic identity tokens and performs identity-conditioned one-to-one layout prediction, followed by layout-conditioned geometry synthesis. Structured local-global conditioning maintains identity alignment across semantic, spatial, and geometric stages. We also construct a part-level dataset with a unified semantic protocol to enable learnable and consistent identity-slot alignment. Extensive experiments demonstrate improved structural stability, controllability, and robustness over state-of-the-art part-aware generation baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that structural ambiguity in part-aware 3D generation arises from identity-slot permutation freedom, which prevents identifiable correspondence between semantic parts and generation slots during training. It proposes the ISAP-3D framework that anchors parts using semantic identity tokens, performs identity-conditioned one-to-one layout prediction, and follows with layout-conditioned geometry synthesis under structured local-global conditioning to maintain alignment. A part-level dataset with unified semantic protocol is introduced to support learnable alignment, and extensive experiments are reported to show gains in structural stability, controllability, and robustness over baselines.
Significance. If the experimental claims hold, the work could be significant for structured 3D generation by offering an explicit mechanism to resolve permutation symmetry in slot-based models, a recurring issue in part-aware synthesis. The dataset construction with unified semantics is a concrete enabling contribution that may support future consistent part-level modeling.
minor comments (2)
- Abstract: the phrase 'extensive experiments demonstrate improved structural stability' is stated without any accompanying metrics, table references, or baseline comparisons; the full experimental section should include specific quantitative results (e.g., IoU, stability scores) to substantiate the central claim.
- The introduction of 'semantic identity tokens' and 'identity-conditioned one-to-one layout prediction' would benefit from an early equation or diagram in §3 showing how the tokens are embedded and how the one-to-one constraint is enforced in the loss.
Simulated Author's Rebuttal
We thank the referee for the careful summary of our work and the positive assessment of its potential significance. We note the recommendation for minor revision. No specific major comments were provided in the report, so we have no individual points to address at this time. We remain available to incorporate any additional feedback.
Circularity Check
No significant circularity identified
full rationale
The paper attributes structural ambiguity to identity-slot permutation freedom and proposes identity-aligned one-to-one slot modeling as the remedy. This is framed as an independent modeling insight and architectural choice (semantic anchoring followed by conditioned layout and geometry stages) rather than any derivation that reduces by construction to fitted inputs, self-definitions, or self-citation chains. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The dataset construction is presented as an enabling step, not a hidden assumption that collapses the claim. The central pipeline remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Identity-slot permutation freedom is the cause of structural ambiguity (slot swapping, part merging) in part-aware 3D generation.
invented entities (1)
-
semantic identity tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2401.05293 (2024)
Alldieck, T., Kolotouros, N., Sminchisescu, C.: Score distillation sampling with learned manifold corrective. arXiv preprint arXiv:2401.05293 (2024)
arXiv 2024
-
[2]
In: CVPR
Chen, M., Shapovalov, R., Laina, I., Monnier, T., Wang, J., Novotny, D., Vedaldi, A.: Partgen: Part-level 3d generation and reconstruction with multi-view diffusion models. In: CVPR. pp. 5881–5892 (June 2025)
2025
-
[3]
arXiv preprint arXiv:2507.13346 (2025)
Chen, M., Wang, J., Shapovalov, R., Monnier, T., Jung, H., Wang, D., Ranjan, R., Laina, I., Vedaldi, A.: Autopartgen: Autogressive 3d part generation and discovery. arXiv preprint arXiv:2507.13346 (2025)
arXiv 2025
-
[4]
In: CVPR
Chen, R., Zhang, J., Liang, Y., Luo, G., Li, W., Liu, J., Li, X., Long, X., Feng, J., Tan, P.: Dora: Sampling and benchmarking for 3d shape variational auto-encoders. In: CVPR. pp. 16251–16261 (June 2025) Abbreviated paper title 15
2025
-
[5]
arXiv preprint arXiv:2307.05663 (2023)
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., VanderBilt, E., Kembhavi, A., Vondrick, C., Gkioxari, G., Ehsani, K., Schmidt, L., Farhadi, A.: Objaverse-xl: A universe of 10m+ 3d objects. arXiv preprint arXiv:2307.05663 (2023)
Pith/arXiv arXiv 2023
-
[6]
In: CVPR
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: CVPR. pp. 13142–13153 (June 2023)
2023
-
[7]
arXiv preprint arXiv:2510.26140 (2025)
Ding, L., Dong, S., Li, Y., Gao, C., Chen, X., Han, R., Kuang, Y., Zhang, H., Huang, B., Huang, Z., Wang, Z., Xu, D., Xue, T.: Fullpart: Generating each 3d part at full resolution. arXiv preprint arXiv:2510.26140 (2025)
arXiv 2025
-
[8]
In: AAAI
Ding, Y., Zhuang, S., Li, K., Yue, Z., Qiao, Y., Wang, Y.: Muses: 3d-controllable image generation via multi-modal agent collaboration. In: AAAI. vol. 39, pp. 2753– 2761 (2025)
2025
-
[9]
In: ICCV (2025)
Dong, S., Ding, L., Chen, X., Li, Y., WANG, Y., Wang, Y., WANG, Q., Kim, J., Gao, C., Huang, Z., Wang, Z., Xue, T., Xu, D.: From one to more: Contextual part latents for 3d generation. In: ICCV (2025)
2025
-
[10]
arXiv preprint arXiv:2503.21732 (2025)
He, X., Zou, Z.X., Chen, C.H., Guo, Y.C., Liang, D., Yuan, C., Ouyang, W., Cao, Y.P., Li, Y.: Sparseflex: High-resolution and arbitrary-topology 3d shape modeling. arXiv preprint arXiv:2503.21732 (2025)
arXiv 2025
-
[11]
arXiv preprint arXiv:2512.09435 (2025)
He, X., Wu, Y., Guo, X., Ye, C., Zhou, J., Hu, T., Han, X., Du, D.: Uni- part: Part-level 3d generation with unified 3d geom-seg latents. arXiv preprint arXiv:2512.09435 (2025)
arXiv 2025
-
[12]
arXiv preprint arXiv:2506.16504 (2025)
Lai, Z., Zhao, Y., Liu, H., Zhao, Z., Lin, Q., Shi, H., Yang, X., Yang, M., Yang, S., Feng, Y., Zhang, S., Huang, X., Luo, D., Yang, F., Yang, F., Wang, L., Liu, S., Tang, Y., Cai, Y., He, Z., Liu, T., Liu, Y., Jiang, J., Linus, Huang, J., Guo, C.: Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details. arXiv preprint arXiv:2506.1...
Pith/arXiv arXiv 2025
-
[13]
arXiv preprint arXiv:2512.03052 (2025)
Lai, Z., Zhao, Y., Zhao, Z., Liu, H., Lin, Q., Huang, J., Guo, C., Yue, X.: Lattice: Democratize high-fidelity 3d generation at scale. arXiv preprint arXiv:2512.03052 (2025)
arXiv 2025
-
[14]
arXiv preprint arXiv:2502.06608 (2025)
Li, Y., Zou, Z.X., Liu, Z., Wang, D., Liang, Y., Yu, Z., Liu, X., Guo, Y.C., Liang, D., Ouyang, W., et al.: Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models. arXiv preprint arXiv:2502.06608 (2025)
Pith/arXiv arXiv 2025
-
[15]
arXiv preprint arXiv:2512.07628 (2025)
Li, Z., Li, W., Wang, T., Wang, Z., Wu, J., Wang, H., Yang, Y., Huang, Z., Li, Y., Guo,C.,Liu,P.:Moca:Mixture-of-componentsattentionforscalablecompositional 3d generation. arXiv preprint arXiv:2512.07628 (2025)
arXiv 2025
-
[16]
Lin, Y., Lin, C., Pan, P., Yan, H., Feng, Y., Mu, Y., Fragkiadaki, K.: Partcrafter: Structured 3d mesh generation via compositional latent diffusion transformers (2025)
2025
-
[17]
In: ICCV (2025)
Liu, M., Uy, M.A., Xiang, D., Su, H., Fidler, S., Sharp, N., Gao, J.: Partfield: Learning 3d feature fields for part segmentation and beyond. In: ICCV (2025)
2025
-
[18]
arXiv preprint arXiv:2303.11328 (2023)
Liu, R., Wu, R., Hoorick, B.V., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero-1- to-3: Zero-shot one image to 3d object. arXiv preprint arXiv:2303.11328 (2023)
arXiv 2023
-
[19]
arXiv preprint arXiv:2309.03453 (2023)
Liu, Y., Lin, C., Zeng, Z., Long, X., Liu, L., Komura, T., Wang, W.: Syncdreamer: Generating multiview-consistent images from a single-view image. arXiv preprint arXiv:2309.03453 (2023)
Pith/arXiv arXiv 2023
-
[20]
In: CVPR
Long, X., Guo, Y.C., Lin, C., Liu, Y., Dou, Z., Liu, L., Ma, Y., Zhang, S.H., Habermann, M., Theobalt, C., Wang, W.: Wonder3d: Single image to 3d using cross-domain diffusion. In: CVPR. pp. 9970–9980 (June 2024) 16 Authors Suppressed Due to Excessive Length
2024
-
[21]
arXiv preprint arXiv:2509.06784 (2025)
Ma, C., Li, Y., Yan, X., Xu, J., Yang, Y., Wang, C., Zhao, Z., Guo, Y., Chen, Z., Guo, C.: P3-sam: Native 3d part segmentation. arXiv preprint arXiv:2509.06784 (2025)
arXiv 2025
-
[22]
arXiv preprint arXiv:2209.14988 (2022)
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022)
Pith/arXiv arXiv 2022
-
[23]
arXiv preprint arXiv:2308.16512 (2023)
Shi, Y., Wang, P., Ye, J., Mai, L., Li, K., Yang, X.: Mvdream: Multi-view diffusion for 3d generation. arXiv preprint arXiv:2308.16512 (2023)
Pith/arXiv arXiv 2023
-
[24]
arXiv preprint arXiv:2506.09980 (2025)
Tang, J., Lu, R., Li, Z., Hao, Z., Li, X., Wei, F., Song, S., Zeng, G., Liu, M.Y., Lin, T.Y.: Efficient part-level 3d object generation via dual volume packing. arXiv preprint arXiv:2506.09980 (2025)
arXiv 2025
-
[25]
arXiv preprint arXiv:2501.12202 (2025)
Team, T.H.: Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation. arXiv preprint arXiv:2501.12202 (2025)
Pith/arXiv arXiv 2025
-
[26]
arXiv preprint arXiv:2506.15442 (2025)
Team, T.H.: Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material. arXiv preprint arXiv:2506.15442 (2025)
Pith/arXiv arXiv 2025
-
[27]
In: CVPR
Wang, H., Du, X., Li, J., Yeh, R.A., Shakhnarovich, G.: Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: CVPR. pp. 12619– 12629 (2023)
2023
-
[28]
arXiv preprint arXiv:2602.22785 (2026)
Wang, L., Guo, H.X., Wang, X., Sun, F., Sun, K., Liu, P., Xiao, H., Wang, Z., Fu, G., Li, E., Liu, Y., Wang, Y.: Scenetransporter: Optimal transport-guided com- positional latent diffusion for single-image structured 3d scene generation. arXiv preprint arXiv:2602.22785 (2026)
arXiv 2026
-
[29]
arXiv preprint arXiv:2305.16213 (2023)
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High- fidelity and diverse text-to-3d generation with variational score distillation. arXiv preprint arXiv:2305.16213 (2023)
arXiv 2023
-
[30]
arXiv preprint arXiv:2505.17412 (2025)
Wu, S., Lin, Y., Zhang, F., Zeng, Y., Yang, Y., Bao, Y., Qian, J., Zhu, S., Torr, P., Cao, X., Yao, Y.: Direct3d-s2: Gigascale 3d generation made easy with spatial sparse attention. arXiv preprint arXiv:2505.17412 (2025)
arXiv 2025
-
[31]
In: CVPR
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: CVPR. pp. 21469–21480 (June 2025)
2025
-
[32]
arXiv preprint arXiv:2509.08643 (2025)
Yan, X., Xu, J., Li, Y., Ma, C., Yang, Y., Wang, C., Zhao, Z., Lai, Z., Zhao, Y., Chen, Z., et al.: X-part: high fidelity and structure coherent shape decomposition. arXiv preprint arXiv:2509.08643 (2025)
arXiv 2025
-
[33]
arXiv preprint arXiv:2511.10040 (2025)
Yang, X., Lai, S., Lyu, J., Li, H., Pan, B., Li, Y., Guo, J., Zhou, Z., Guo, Y.: Log3d: Ultra-high-resolution 3d shape modeling via local-to-global partitioning. arXiv preprint arXiv:2511.10040 (2025)
arXiv 2025
-
[34]
arXiv preprint arXiv:2511.18801 (2025)
Yang, Y., Li, H., Zhu, H., Yang, L., Lei, G., Xu, S., Zhang, B.: Partdiffuser: Part- wise 3d mesh generation via discrete diffusion. arXiv preprint arXiv:2511.18801 (2025)
Pith/arXiv arXiv 2025
-
[35]
arXiv preprint arXiv:2504.07943 (2025)
Yang, Y., Guo, Y.C., Huang, Y., Zou, Z.X., Yu, Z., Li, Y., Cao, Y.P., Liu, X.: Holopart: Generative 3d part amodal segmentation. arXiv preprint arXiv:2504.07943 (2025)
arXiv 2025
-
[36]
arXiv preprint arXiv:2507.06165 (2025)
Yang, Y., Zhou, Y., Guo, Y.C., Zou, Z.X., Huang, Y., Liu, Y.T., Xu, H., Liang, D., Cao, Y.P., Liu, X.: Omnipart: Part-aware 3d generation with semantic decoupling and structural cohesion. arXiv preprint arXiv:2507.06165 (2025)
arXiv 2025
-
[37]
ACM Trans
Zhang, B., Tang, J., Nießner, M., Wonka, P.: 3dshape2vecset: A 3d shape represen- tation for neural fields and generative diffusion models. ACM Trans. Graph.42(4) (jul 2023)
2023
-
[38]
arXiv preprint arXiv:2406.13897 (2024) Abbreviated paper title 17
Zhang, L., Wang, Z., Zhang, Q., Qiu, Q., Pang, A., Jiang, H., Yang, W., Xu, L., Yu, J.: Clay: A controllable large-scale generative model for creating high-quality 3d assets. arXiv preprint arXiv:2406.13897 (2024) Abbreviated paper title 17
arXiv 2024
-
[39]
ACM Transactions on Graphics44(4), 1–21 (Jul 2025)
Zhang, L., Zhang, Q., Jiang, H., Bai, Y., Yang, W., Xu, L., Yu, J.: Bang: Dividing 3d assets via generative exploded dynamics. ACM Transactions on Graphics44(4), 1–21 (Jul 2025)
2025
-
[40]
In: NeurIPS (2023)
Zhao, Z., Liu, W., Chen, X., Zeng, X., Wang, R., Cheng, P., FU, B., Chen, T., YU, G., Gao, S.: Michelangelo: Conditional 3d shape generation based on shape- image-text aligned latent representation. In: NeurIPS (2023)
2023
-
[41]
In: CVPR
Zhu, D., Di, Y., Gavranovic, S., Ilic, S.: Sealion: Semantic part-aware latent point diffusion models for 3d generation. In: CVPR. pp. 11789–11798 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.