A Unified Zeroth-Order Approach for Decentralized Minimax Optimization
Pith reviewed 2026-06-27 08:45 UTC · model grok-4.3
The pith
ZOMA unifies zeroth-order estimators, bias corrections, and accelerations for decentralized minimax optimization under the nonconvex Polyak-Lojasiewicz condition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a multi-level unified framework called ZOMA, incorporating a hybrid zeroth-order estimator that accommodates coordinate-wise and randomized uniform smoothing, subsumes bias-correction strategies including gradient tracking, exact diffusion, and EXTRA, and facilitates acceleration techniques including zeroth-order versions of STORM, PAGE, and L2S, enables novel decentralized zeroth-order minimax methods with unified convergence guarantees that match state-of-the-art centralized zeroth-order minimax methods and provide linear speed-up in the number of users for nonconvex Polyak-Lojasiewicz minimax optimization.
What carries the argument
The ZOMA framework, which unifies a hybrid zeroth-order estimator with bias-correction strategies and acceleration techniques to derive and analyze decentralized minimax algorithms from function values alone.
If this is right
- The framework generates many novel decentralized zeroth-order minimax methods.
- Convergence guarantees match those of state-of-the-art centralized zeroth-order minimax methods.
- Linear speed-up occurs in the number of users.
- The unified rates supply a systematic way to assess suitability for specific problem structures and method designs.
Where Pith is reading between the lines
- Designers could mix estimator types with different bias corrections to fit hardware constraints while retaining the same theoretical rates.
- The same unification pattern could be tested on stochastic or constrained minimax problems beyond the current nonconvex PL setting.
- Simulations could be extended to measure wall-clock time benefits in distributed hardware where communication costs dominate.
Load-bearing premise
The hybrid zeroth-order estimator can be paired with any of the listed bias-correction strategies and acceleration techniques while preserving the stated convergence rates under only the nonconvex Polyak-Lojasiewicz condition.
What would settle it
Numerical results on a nonconvex Polyak-Lojasiewicz minimax problem where a specific pairing of the hybrid estimator with EXTRA bias correction and STORM acceleration fails to achieve the claimed rate would falsify the unified guarantee.
Figures
read the original abstract
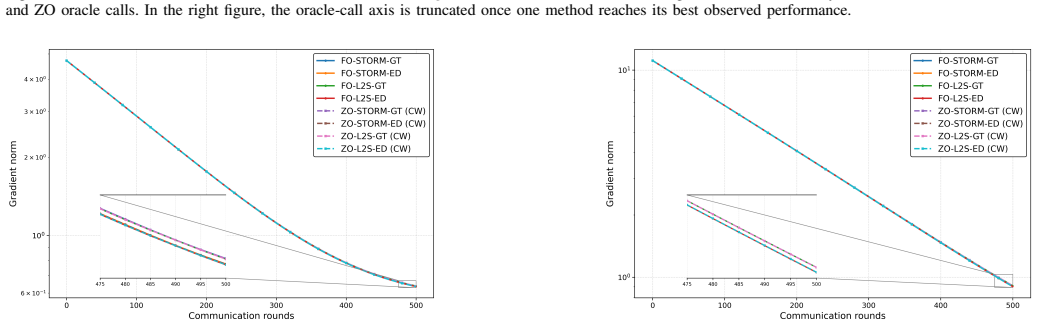
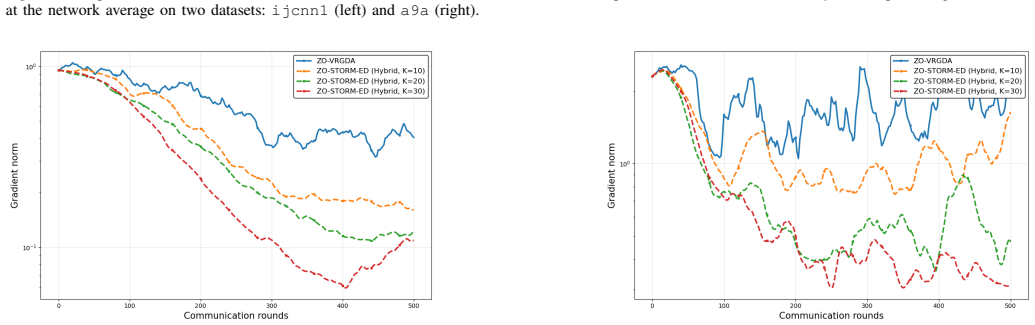
We propose ZOMA, a unified Zeroth-Order decentralized accelerated MinimAx framework for multi-agent nonconvex Polyak--\L{}ojasiewicz minimax optimization. The proposed framework only requires evaluating the function value and, as such, is tailored to gradient-free environments, where exact gradient information is either unavailable or computationally prohibitive to obtain. A central contribution of our \textbf{ZOMA} framework is a multi-level unification, along the following directions: (i) \emph{estimator} - our framework adopts a hybrid zeroth-order estimator, which accommodates, among others, both coordinate-wise and randomized uniform smoothing estimators; (ii) \emph{bias correction} - our framework subsumes a wide range of bias-correction strategies, including gradient tracking (GT), exact diffusion (ED), and EXTRA and (iii) \emph{acceleration} - our framework facilitates a broad class of acceleration techniques, including zeroth-order versions of STORM, PAGE, and L2S. The general nature of \textbf{ZOMA} leads to many novel decentralized zeroth-order minimax methods and allows us to establish unified convergence guarantees, matching the performance of state-of-the-art centralized zeroth-order minimax methods, while providing benefits, such as linear speed-up in the number of users. The unified framework also provides a systematic way to assess algorithmic suitability by specializing the convergence rates to specific problem structures and method designs. We validate the performance of the proposed algorithms via numerical simulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ZOMA, a unified Zeroth-Order decentralized accelerated MinimAx framework for multi-agent nonconvex Polyak-Łojasiewicz minimax optimization. It unifies a hybrid zeroth-order estimator (accommodating coordinate-wise and randomized uniform smoothing), bias-correction strategies (GT, ED, EXTRA), and acceleration techniques (zeroth-order STORM, PAGE, L2S). The framework establishes unified convergence guarantees matching state-of-the-art centralized zeroth-order minimax methods, with linear speedup in the number of users, and is validated via numerical simulations.
Significance. If the central unification holds with uniform rates across combinations under the stated assumptions, the work would provide a systematic framework for designing and analyzing decentralized zeroth-order minimax algorithms, enabling assessment of suitability for specific problem structures. The explicit multi-level unification and matching of centralized performance with decentralized linear speedup would be a notable contribution in gradient-free multi-agent optimization.
major comments (1)
- [Abstract and §1] Abstract and §1 (Introduction): The claim that the hybrid zeroth-order estimator can be paired with any listed bias-correction (GT/ED/EXTRA) and acceleration (STORM/PAGE/L2S) while preserving the stated convergence rates under only the nonconvex Polyak-Łojasiewicz condition is load-bearing for the unification contribution. The analysis must explicitly verify that bias/variance bounds remain uniform without introducing case-specific network-diameter factors or extra smoothness requirements; otherwise the rates are not truly unified.
minor comments (1)
- [Numerical simulations] The numerical simulations section could specify which estimator-bias-acceleration combinations were tested to better illustrate the unification.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the load-bearing aspect of the unification claim. We address the major comment below and are prepared to strengthen the presentation of uniformity if needed.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1 (Introduction): The claim that the hybrid zeroth-order estimator can be paired with any listed bias-correction (GT/ED/EXTRA) and acceleration (STORM/PAGE/L2S) while preserving the stated convergence rates under only the nonconvex Polyak-Łojasiewicz condition is load-bearing for the unification contribution. The analysis must explicitly verify that bias/variance bounds remain uniform without introducing case-specific network-diameter factors or extra smoothness requirements; otherwise the rates are not truly unified.
Authors: The unified analysis (Section 4 and Appendix B) derives bias and variance bounds for the hybrid zeroth-order estimator in a general form that depends only on the smoothing radius, the PL constant, and the standard assumptions on the bias-correction operators. These bounds are shown to hold uniformly across all listed combinations of GT/ED/EXTRA with STORM/PAGE/L2S; no additional network-diameter factors appear beyond those already embedded in the bias-correction analysis itself, and no extra smoothness is imposed. The resulting rates therefore match the centralized zeroth-order minimax rates uniformly while retaining the linear speedup. We can add an explicit remark or short subsection in Section 3 that restates this uniformity for clarity. revision: partial
Circularity Check
No circularity: ZOMA unification is definitional by framework construction; convergence rates presented as derived, not reduced to self-citations or fits.
full rationale
The provided abstract defines ZOMA explicitly to subsume hybrid estimators, GT/ED/EXTRA bias corrections, and STORM/PAGE/L2S accelerations, then states that this leads to unified convergence guarantees matching centralized ZO methods. No equations appear that would make any claimed rate equivalent to its inputs by construction, no self-citations are referenced as load-bearing, and no fitted parameters are renamed as predictions. The derivation chain is therefore self-contained; the unification is an explicit design choice whose correctness is to be verified externally rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The target problem satisfies the nonconvex Polyak-Łojasiewicz condition for minimax optimization.
Reference graph
Works this paper leans on
-
[1]
Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models,
P.-Y . Chen, H. Zhang, Y . Sharma, J. Yi, and C.-J. Hsieh, “Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models,” inACM Workshop on Artificial Intelligence and Security, 2017, pp. 15–26
2017
-
[2]
Autozoom: Autoencoder-based zeroth order optimization method for attacking black-box neural networks,
C.-C. Tu, P. Ting, P.-Y . Chen, S. Liu, H. Zhang, J. Yi, C.-J. Hsieh, and S.-M. Cheng, “Autozoom: Autoencoder-based zeroth order optimization method for attacking black-box neural networks,” inAAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 742–749
2019
-
[3]
Fine-tuning language models with just forward passes,
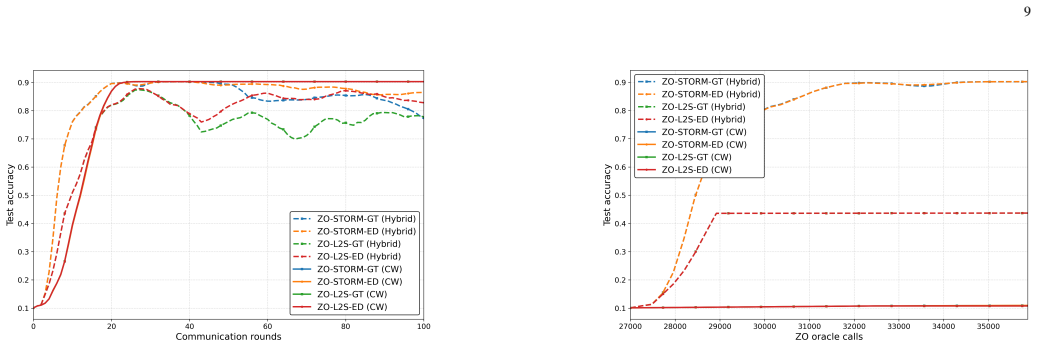
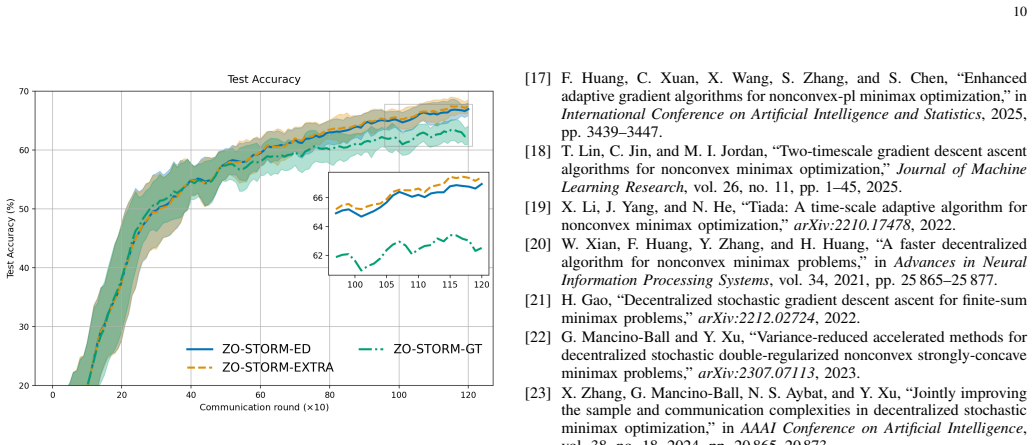
S. Malladi, T. Gao, E. Nichani, A. Damian, J. D. Lee, D. Chen, and S. Arora, “Fine-tuning language models with just forward passes,” in Advances in Neural Information Processing Systems, vol. 36, 2023, pp. 53 038–53 075. 10 Fig. 4. Simulation results on training a fair classifier with the FashionMNIST dataset. We report the test accuracy of thehybridZO va...
2023
-
[4]
Revisiting zeroth- order optimization for memory-efficient llm fine-tuning: A benchmark,
Y . Zhang, P. Li, J. Hong, J. Li, Y . Zhang, W. Zheng, P.-Y . Chen, J. D. Lee, W. Yin, M. Hong, Z. Wang, S. Liu, and T. Chen, “Revisiting zeroth- order optimization for memory-efficient llm fine-tuning: A benchmark,” arXiv:2402.11592, 2024
arXiv 2024
-
[5]
A decentralized parallel algorithm for training generative adversarial nets,
M. Liu, W. Zhang, Y . Mroueh, X. Cui, J. Ross, T. Yang, and P. Das, “A decentralized parallel algorithm for training generative adversarial nets,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 11 056–11 070
2020
-
[6]
Communication-efficient distributed stochastic auc maximization with deep neural networks,
Z. Guo, M. Liu, Z. Yuan, L. Shen, W. Liu, and T. Yang, “Communication-efficient distributed stochastic auc maximization with deep neural networks,” inInternational Conference on Machine Learn- ing, 2020, pp. 3864–3874
2020
-
[7]
Robust multi- agent reinforcement learning via minimax deep deterministic policy gradient,
S. Li, Y . Wu, X. Cui, H. Dong, F. Fang, and S. Russell, “Robust multi- agent reinforcement learning via minimax deep deterministic policy gradient,” inAAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 4213–4220
2019
-
[8]
Improved zeroth-order vari- ance reduced algorithms and analysis for nonconvex optimization,
K. Ji, Z. Wang, Y . Zhou, and Y . Liang, “Improved zeroth-order vari- ance reduced algorithms and analysis for nonconvex optimization,” in International Conference on Machine Learning, 2019, pp. 3100–3109
2019
-
[9]
Min-max optimization without gradients: Convergence and applications to black-box evasion and poisoning attacks,
S. Liu, S. Lu, X. Chen, Y . Feng, K. Xu, A. Al-Dujaili, M. Hong, and U.-M. O’Reilly, “Min-max optimization without gradients: Convergence and applications to black-box evasion and poisoning attacks,” inInter- national Conference on Machine Learning, 2020, pp. 6282–6293
2020
-
[10]
Zeroth-order stochastic variance reduction for nonconvex optimization,
S. Liu, B. Kailkhura, P.-Y . Chen, P. Ting, S. Chang, and L. Amini, “Zeroth-order stochastic variance reduction for nonconvex optimization,” inAdvances in Neural Information Processing Systems, vol. 31, 2018, pp. 3731–3741
2018
-
[11]
On gradient descent ascent for nonconvex-concave minimax problems,
T. Lin, C. Jin, and M. I. Jordan, “On gradient descent ascent for nonconvex-concave minimax problems,” inInternational Conference on Machine Learning, 2020, pp. 6083–6093
2020
-
[12]
Efficient methods for structured nonconvex-nonconcave min-max optimization,
J. Diakonikolas, C. Daskalakis, and M. I. Jordan, “Efficient methods for structured nonconvex-nonconcave min-max optimization,” inInter- national Conference on Artificial Intelligence and Statistics, 2021, pp. 2746–2754
2021
-
[13]
A unified single-loop alternat- ing gradient projection algorithm for nonconvex–concave and convex– nonconcave minimax problems,
Z. Xu, H. Zhang, Y . Xu, and G. Lan, “A unified single-loop alternat- ing gradient projection algorithm for nonconvex–concave and convex– nonconcave minimax problems,”Mathematical Programming, vol. 201, no. 1, pp. 635–706, 2023
2023
-
[14]
Faster single-loop algo- rithms for minimax optimization without strong concavity,
J. Yang, A. Orvieto, A. Lucchi, and N. He, “Faster single-loop algo- rithms for minimax optimization without strong concavity,” inInter- national Conference on Artificial Intelligence and Statistics, 2022, pp. 5485–5517
2022
-
[15]
Universal gradient descent ascent method for nonconvex-nonconcave minimax optimization,
T. Zheng, L. Zhu, A. M.-C. So, J. Blanchet, and J. Li, “Universal gradient descent ascent method for nonconvex-nonconcave minimax optimization,” inAdvances in Neural Information Processing Systems, vol. 36, 2023, pp. 54 075–54 110
2023
-
[16]
Accelerated stochas- tic min-max optimization based on bias-corrected momentum,
H. Cai, S. A. Alghunaim, and A. H. Sayed, “Accelerated stochas- tic min-max optimization based on bias-corrected momentum,” arXiv:2406.13041, 2024
Pith/arXiv arXiv 2024
-
[17]
Enhanced adaptive gradient algorithms for nonconvex-pl minimax optimization,
F. Huang, C. Xuan, X. Wang, S. Zhang, and S. Chen, “Enhanced adaptive gradient algorithms for nonconvex-pl minimax optimization,” in International Conference on Artificial Intelligence and Statistics, 2025, pp. 3439–3447
2025
-
[18]
Two-timescale gradient descent ascent algorithms for nonconvex minimax optimization,
T. Lin, C. Jin, and M. I. Jordan, “Two-timescale gradient descent ascent algorithms for nonconvex minimax optimization,”Journal of Machine Learning Research, vol. 26, no. 11, pp. 1–45, 2025
2025
-
[19]
Tiada: A time-scale adaptive algorithm for nonconvex minimax optimization,
X. Li, J. Yang, and N. He, “Tiada: A time-scale adaptive algorithm for nonconvex minimax optimization,”arXiv:2210.17478, 2022
arXiv 2022
-
[20]
A faster decentralized algorithm for nonconvex minimax problems,
W. Xian, F. Huang, Y . Zhang, and H. Huang, “A faster decentralized algorithm for nonconvex minimax problems,” inAdvances in Neural Information Processing Systems, vol. 34, 2021, pp. 25 865–25 877
2021
-
[21]
Decentralized stochastic gradient descent ascent for finite-sum minimax problems,
H. Gao, “Decentralized stochastic gradient descent ascent for finite-sum minimax problems,”arXiv:2212.02724, 2022
arXiv 2022
-
[22]
G. Mancino-Ball and Y . Xu, “Variance-reduced accelerated methods for decentralized stochastic double-regularized nonconvex strongly-concave minimax problems,”arXiv:2307.07113, 2023
arXiv 2023
-
[23]
Jointly improving the sample and communication complexities in decentralized stochastic minimax optimization,
X. Zhang, G. Mancino-Ball, N. S. Aybat, and Y . Xu, “Jointly improving the sample and communication complexities in decentralized stochastic minimax optimization,” inAAAI Conference on Artificial Intelligence, vol. 38, no. 18, 2024, pp. 20 865–20 873
2024
-
[24]
Decentralized gradient descent maximization method for com- posite nonconvex strongly-concave minimax problems,
Y . Xu, “Decentralized gradient descent maximization method for com- posite nonconvex strongly-concave minimax problems,”SIAM Journal on Optimization, vol. 34, no. 1, pp. 1006–1044, 2024
2024
-
[25]
Communication-efficient algorithms for distributed nonconvex minimax optimization problems,
H. Cai, S. A. Alghunaim, and A. H. Sayed, “Communication-efficient algorithms for distributed nonconvex minimax optimization problems,” arXiv:2507.21901, 2025
Pith/arXiv arXiv 2025
-
[26]
——, “DAMA: A unified accelerated approach for decentralized non- convex minimax optimization-part I: Algorithm development and re- sults,”arXiv:2512.13920, 2025
arXiv 2025
-
[27]
——, “DAMA: A unified accelerated approach for decentralized non- convex minimax optimization-part II: Convergence and performance analyses,”arXiv:2512.13923, 2025
arXiv 2025
-
[28]
Stochastic first-and zeroth-order methods for nonconvex stochastic programming,
S. Ghadimi and G. Lan, “Stochastic first-and zeroth-order methods for nonconvex stochastic programming,”SIAM Journal on Optimization, vol. 23, no. 4, pp. 2341–2368, 2013
2013
-
[29]
Random gradient-free minimization of convex functions,
Y . Nesterov and V . Spokoiny, “Random gradient-free minimization of convex functions,”Foundations of Computational Mathematics, vol. 17, no. 2, pp. 527–566, 2017
2017
-
[30]
On the information-adaptive variants of admm: An iteration complexity perspective,
X. Gao, B. Jiang, and S. Zhang, “On the information-adaptive variants of admm: An iteration complexity perspective,”Journal of Scientific Computing, vol. 76, no. 1, pp. 327–363, 2018
2018
-
[31]
Zeroth-order online alternating direction method of multipliers: Convergence analysis and applications,
S. Liu, J. Chen, P.-Y . Chen, and A. Hero, “Zeroth-order online alternating direction method of multipliers: Convergence analysis and applications,” inInternational Conference on Artificial Intelligence and Statistics, 2018, pp. 288–297
2018
-
[32]
A primer on zeroth-order optimization in signal processing and machine learning: Principals, recent advances, and applications,
S. Liu, P.-Y . Chen, B. Kailkhura, G. Zhang, A. O. Hero, and P. K. Varshney, “A primer on zeroth-order optimization in signal processing and machine learning: Principals, recent advances, and applications,” IEEE Signal Processing Magazine, vol. 37, no. 5, pp. 43–54, 2020
2020
-
[33]
A zeroth-order variance-reduced method for decentralized stochastic non-convex optimization,
H. Chen, J. Chen, and K. Wei, “A zeroth-order variance-reduced method for decentralized stochastic non-convex optimization,”Optimization, pp. 1–43, 2025
2025
-
[34]
Zeroth-order algorithms for stochastic distributed nonconvex optimization,
X. Yi, S. Zhang, T. Yang, and K. H. Johansson, “Zeroth-order algorithms for stochastic distributed nonconvex optimization,”Automatica, vol. 142, p. 110353, 2022
2022
-
[35]
Distributed zero-order algorithms for nonconvex multiagent optimization,
Y . Tang, J. Zhang, and N. Li, “Distributed zero-order algorithms for nonconvex multiagent optimization,”IEEE Transactions on Control of Network Systems, vol. 8, no. 1, pp. 269–281, 2020
2020
-
[36]
Distributed zeroth or- der optimization over random networks: A Kiefer-Wolfowitz stochastic approximation approach,
A. K. Sahu, D. Jakovetic, D. Bajovic, and S. Kar, “Distributed zeroth or- der optimization over random networks: A Kiefer-Wolfowitz stochastic approximation approach,” inIEEE Conference on Decision and Control. IEEE, 2018, pp. 4951–4958
2018
-
[37]
Decentralized zeroth-order constrained stochas- tic optimization algorithms: Frank–Wolfe and variants with applications to black-box adversarial attacks,
A. K. Sahu and S. Kar, “Decentralized zeroth-order constrained stochas- tic optimization algorithms: Frank–Wolfe and variants with applications to black-box adversarial attacks,”Proceedings of the IEEE, vol. 108, no. 11, pp. 1890–1905, 2020
1905
-
[38]
A single-loop smoothed gradient descent-ascent algorithm for nonconvex-concave min-max problems,
J. Zhang, P. Xiao, R. Sun, and Z. Luo, “A single-loop smoothed gradient descent-ascent algorithm for nonconvex-concave min-max problems,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 7377–7389
2020
-
[39]
Stochastic recursive gradi- ent descent ascent for stochastic nonconvex-strongly-concave minimax problems,
L. Luo, H. Ye, Z. Huang, and T. Zhang, “Stochastic recursive gradi- ent descent ascent for stochastic nonconvex-strongly-concave minimax problems,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 20 566–20 577. 11
2020
-
[40]
Zeroth- order algorithms for nonconvex–strongly-concave minimax problems with improved complexities,
Z. Wang, K. Balasubramanian, S. Ma, and M. Razaviyayn, “Zeroth- order algorithms for nonconvex–strongly-concave minimax problems with improved complexities,”Journal of Global Optimization, vol. 87, no. 2, pp. 709–740, 2023
2023
-
[41]
Accelerated zeroth-order and first-order momentum methods from mini to minimax optimization,
F. Huang, S. Gao, J. Pei, and H. Huang, “Accelerated zeroth-order and first-order momentum methods from mini to minimax optimization,” Journal of Machine Learning Research, vol. 23, no. 36, pp. 1–70, 2022
2022
-
[42]
Gradient free minimax optimization: Variance reduction and faster convergence,
T. Xu, Z. Wang, Y . Liang, and H. V . Poor, “Gradient free minimax optimization: Variance reduction and faster convergence,” arXiv:2006.09361, 2020
arXiv 2006
-
[43]
Zeroth-order alternating gradient descent ascent algorithms for a class of nonconvex-nonconcave minimax problems,
Z. Xu, Z.-Q. Wang, J.-L. Wang, and Y .-H. Dai, “Zeroth-order alternating gradient descent ascent algorithms for a class of nonconvex-nonconcave minimax problems,”Journal of Machine Learning Research, vol. 24, no. 313, pp. 1–25, 2023
2023
-
[44]
Robust and faster zeroth-order minimax optimization: complexity and applications,
W. An, Y . Liu, F. Shang, and H. Liu, “Robust and faster zeroth-order minimax optimization: complexity and applications,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, pp. 37 050– 37 069
2024
-
[45]
Near-optimal decentralized momentum method for nonconvex-pl minimax problems,
F. Huang and S. Chen, “Near-optimal decentralized momentum method for nonconvex-pl minimax problems,”arXiv:2304.10902, 2023
arXiv 2023
-
[46]
Federated stochastic minimax optimization under heavy-tailed noises,
X. Zhang and H. Gao, “Federated stochastic minimax optimization under heavy-tailed noises,”arXiv:2511.04456, 2025
arXiv 2025
-
[47]
A unified and refined convergence analysis for non-convex decentralized learning,
S. A. Alghunaim and K. Yuan, “A unified and refined convergence analysis for non-convex decentralized learning,”IEEE Transactions on Signal Processing, vol. 70, pp. 3264–3279, 2022
2022
-
[48]
A. H. Sayed,Inference and Learning from Data. Cambridge University Press, 2022
2022
-
[49]
An efficient stochastic algorithm for decentralized nonconvex-strongly-concave minimax optimization,
L. Chen, H. Ye, and L. Luo, “An efficient stochastic algorithm for decentralized nonconvex-strongly-concave minimax optimization,” in International Conference on Artificial Intelligence and Statistics, 2024, pp. 1990–1998
2024
-
[50]
Momentum-based variance reduction in non-convex sgd,
A. Cutkosky and F. Orabona, “Momentum-based variance reduction in non-convex sgd,” inAdvances in Neural Information Processing Systems, vol. 32, 2019, pp. 15 236 – 15 245
2019
-
[51]
Page: A simple and optimal probabilistic gradient estimator for nonconvex optimization,
Z. Li, H. Bao, X. Zhang, and P. Richt ´arik, “Page: A simple and optimal probabilistic gradient estimator for nonconvex optimization,” in International Conference on Machine Learning, 2021, pp. 6286–6295
2021
-
[52]
On the convergence of sarah and beyond,
B. Li, M. Ma, and G. B. Giannakis, “On the convergence of sarah and beyond,” inInternational Conference on Artificial Intelligence and Statistics, 2020, pp. 223–233
2020
-
[53]
Achieving geometric convergence for distributed optimization over time-varying graphs,
A. Nedi ´c, A. Olshevsky, and W. Shi, “Achieving geometric convergence for distributed optimization over time-varying graphs,”SIAM Journal on Optimization, vol. 27, no. 4, pp. 2597–2633, 2017
2017
-
[54]
Exact diffusion for distributed optimization and learning—part I: Algorithm development,
K. Yuan, B. Ying, X. Zhao, and A. H. Sayed, “Exact diffusion for distributed optimization and learning—part I: Algorithm development,” IEEE Transactions on Signal Processing, vol. 67, no. 3, pp. 708–723, 2018
2018
-
[55]
Extra: An exact first-order algorithm for decentralized consensus optimization,
W. Shi, Q. Ling, G. Wu, and W. Yin, “Extra: An exact first-order algorithm for decentralized consensus optimization,”SIAM Journal on Optimization, vol. 25, no. 2, pp. 944–966, 2015
2015
-
[56]
Solving a class of non-convex min-max games using iterative first order methods,
M. Nouiehed, M. Sanjabi, T. Huang, J. D. Lee, and M. Razaviyayn, “Solving a class of non-convex min-max games using iterative first order methods,” inAdvances in Neural Information Processing Systems, vol. 32, 2019, pp. 14 905–14 916
2019
-
[57]
Loss landscapes and optimization in over-parameterized non-linear systems and neural networks,
C. Liu, L. Zhu, and M. Belkin, “Loss landscapes and optimization in over-parameterized non-linear systems and neural networks,”Applied and Computational Harmonic Analysis, vol. 59, pp. 85–116, 2022
2022
-
[58]
Global convergence and variance reduction for a class of nonconvex-nonconcave minimax problems,
J. Yang, N. Kiyavash, and N. He, “Global convergence and variance reduction for a class of nonconvex-nonconcave minimax problems,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 1153–1165
2020
-
[59]
Agnostic federated learning,
M. Mohri, G. Sivek, and A. T. Suresh, “Agnostic federated learning,” in International Conference on Machine Learning, 2019, pp. 4615–4625
2019
-
[60]
Solving a class of non-convex minimax optimization in federated learning,
X. Wu, J. Sun, Z. Hu, A. Zhang, and H. Huang, “Solving a class of non-convex minimax optimization in federated learning,” inAdvances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[61]
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,” arXiv:1708.07747, 2017. 12 APPENDIXA NOTATION To facilitate analysis, we first introduce the concatenated variables, i.e., z≜[x;y],z≜[x;y]∈R d1+d2 .(18) The averaged variable and gradient estimator are defined as zc,i ≜[x c,i;y c,i]≜ 1...
Pith/arXiv arXiv 2017
-
[62]
For convenience, let R≜Q k(x+µ xu, y;ξ)−Q k(z;ξ)− ⟨∇ xQk(z;ξ), µ xu⟩,(144) whereu,ξare independent ofz
Note that E qx i (zk,i;ξ j k,i,u j k,i)−q x i (zk,i−1;ξ j k,i,u j k,i) 2 =E d1(Qk(xk,i +µ xuj k,i,y k,i;ξ j k,i)−Q k(zk,i;ξ j k,i)) µx uj k,i − d1(Qk(xk,i−1 +µ xuj k,i,y k,i−1;ξ j k,i)−Q k(zk,i−1;ξ j k,i)) µx uj k,i 2 (a) =d 2 1E Qk(xk,i +µ xuj k,i,y k,i;ξ j k,i)−Q k(zk,i;ξ j k,i)− ⟨∇ xQk(zk,i;ξ j k,i), µxuj k,i⟩ µx uj k,i − Qk(xk,i−1 +µ xuj k,i,y k,i−1;ξ...
-
[63]
(181) Proof.According to Lemma 1, given aL-smooth functionP(z), thenP µx(x)≜E u∼Unil(Bd1)P(x+µ xu)isL ′(≤L)-smooth, it follows that Pµx(xc,i+1)≤P µx(xc,i) +⟨∇P µx(xc,i),x c,i+1 −x c,i⟩+ Lη2 x 2 ∥gx c,i∥2 ≤P µx(xc,i)−η x⟨∇Pµx(xc,i),g x c,i⟩+ Lη2 x 2 ∥gx c,i∥2 ≤P µx(xc,i)− ηx 2 ∥∇Pµx(xc,i)∥2 − ηx 2 ∥gx c,i∥2 + ηx 2 ∥∇Pµx(xc,i)−g x c,i∥2 + Lη2 x 2 ∥gx c,i∥2....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.