Adaptive Multi-Resolution Procedural Knowledge Compression for Large Language Models
Pith reviewed 2026-06-27 09:43 UTC · model grok-4.3
The pith
SKIM compresses procedural skills for LLMs to 30-60 percent of original token length while preserving performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
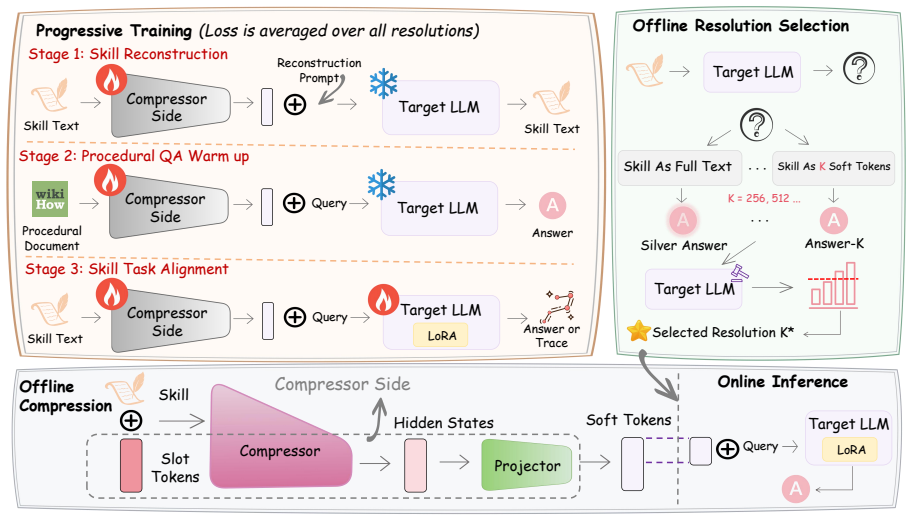
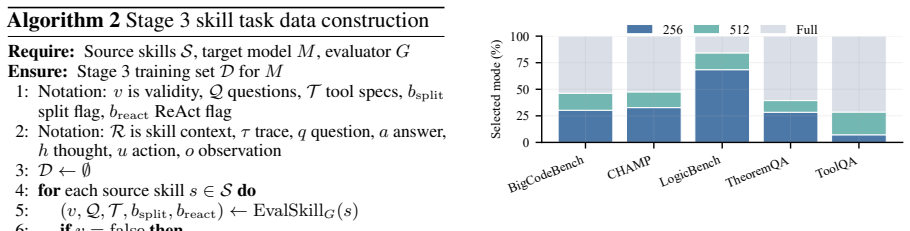
SKIM is an adaptive multi-resolution soft token compression framework for procedural skills. Depending on the complexity of each skill, SKIM creates different numbers of soft tokens that not only improve the efficiency of LLM inference, but also preserve the effectiveness of skill usage. It satisfies three requirements: preserving logical dependencies among workflows and tool protocols, enabling lightweight offline compression for frequently updated skills, and adapting to varying complexities across skills.
What carries the argument
Adaptive multi-resolution soft token compression framework (SKIM) that produces varying numbers of soft tokens per skill based on its complexity.
If this is right
- Repeated skill invocations incur lower prefill cost and latency in LLM contexts.
- Task performance is retained more reliably than with compression methods built for factual text.
- Community skills can be compressed offline without heavy computational overhead.
- Compression ratios adjust automatically to the complexity of each individual skill.
Where Pith is reading between the lines
- The same resolution-adaptive token mechanism could be tested on compressing multi-step agent plans or code snippets.
- SKIM-style compression might combine with KV-cache optimizations to further reduce memory during long workflows.
- Dynamic selection of resolution during inference could be explored if skill usage patterns change within a single session.
Load-bearing premise
Soft tokens created at different resolutions can preserve logical dependencies among workflows and tool protocols for skills of varying complexity.
What would settle it
A direct comparison showing that SKIM-compressed skills produce substantially lower success rates than full-text skills on tasks that chain multiple tool protocols.
Figures




read the original abstract
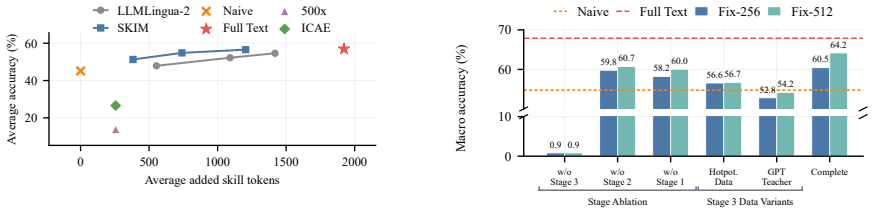
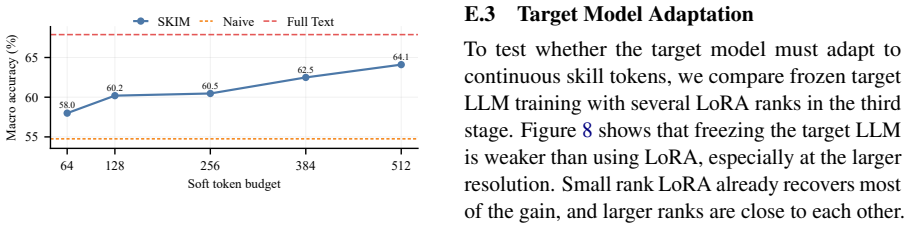
Large language models (LLMs) are widely used to tackle complex tasks with autonomous workflows. Recently, reusable natural language skills have emerged as a popular paradigm to inject procedural knowledge into LLM applications. Since popular skills are often invoked repeatedly, placing their full text in every context significantly increases prefill cost and latency. While text compression techniques have the potential to solve this problem, most existing methods are designed to compress factual knowledge in documents instead of procedural knowledge, making them insufficient for skill compression. In this paper, we argue that an effective skill compression method should: 1) preserve logical dependencies among workflows and tool protocols, 2) enable lightweight, offline compression for frequently updated community skills, and 3) be adaptable to varying complexities across skills. To address this, we present SKIM (SKIll coMpression), an adaptive multi-resolution soft token compression framework for procedural skills. Depending on the complexity of each skill, SKIM creates different numbers of soft tokens that not only improve the efficiency of LLM inference, but also preserve the effectiveness of skill usage. Experiments indicate that SKIM compresses skills to 30 to 60 percent of their original token length while preserving task performance better than existing compression methods.We have released our code at https://github.com/bebr2/SKIM .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SKIM, an adaptive multi-resolution soft token compression framework for procedural skills in LLMs. It creates varying numbers of soft tokens per skill based on complexity to meet three requirements: preserving logical dependencies among workflows and tool protocols, enabling lightweight offline compression, and adapting to skill complexities. The central empirical claim is that SKIM compresses skills to 30-60% of original token length while preserving task performance better than existing methods; code is released at https://github.com/bebr2/SKIM.
Significance. If the end-to-end task performance results hold across procedural skills of varying complexity, this addresses a practical bottleneck in LLM applications that repeatedly invoke reusable natural language skills, potentially lowering prefill costs and latency. The open release of code supports reproducibility, which strengthens the contribution for an empirical methods paper in this area.
minor comments (2)
- Abstract: the sentence 'Experiments indicate that SKIM compresses skills to 30 to 60 percent of their original token length while preserving task performance better than existing compression methods.We have released our code' is missing a space after the period.
- The abstract states the three requirements an effective method must meet but does not preview how the experiments directly test preservation of logical dependencies (requirement 1); the full paper should make this mapping explicit in the evaluation section.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the code release, and recommendation of minor revision. The referee's description of SKIM and its goals is accurate. No major comments appear in the report, so we have no points requiring rebuttal or clarification at this stage.
Circularity Check
No significant circularity
full rationale
The paper presents SKIM as an empirical framework for skill compression rather than a mathematical derivation. The abstract and description contain no equations, fitted parameters, or load-bearing self-citations that reduce claims to inputs by construction. The three requirements are stated design goals, and results are reported from end-to-end experiments on task performance. No self-definitional, fitted-prediction, or uniqueness-imported steps are identifiable from the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of soft tokens per skill
axioms (1)
- domain assumption Soft tokens at multiple resolutions can preserve logical dependencies among workflows and tool protocols
invented entities (1)
-
multi-resolution soft tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[2]
2024 , eprint=
Phi-4 Technical Report , author=. 2024 , eprint=
2024
-
[3]
2026 , eprint=
TokMem: One-Token Procedural Memory for Large Language Models , author=. 2026 , eprint=
2026
-
[4]
2026 , eprint=
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications , author=. 2026 , eprint=
2026
-
[8]
2026 , eprint=
Decoupled Reasoning with Implicit Fact Tokens (DRIFT): A Dual-Model Framework for Efficient Long-Context Inference , author=. 2026 , eprint=
2026
-
[9]
In-context Autoencoder for Context Compression in a Large Language Model , booktitle =
Tao Ge and Jing Hu and Lei Wang and Xun Wang and Si. In-context Autoencoder for Context Compression in a Large Language Model , booktitle =. 2024 , url =
2024
-
[10]
2025 , eprint=
DeepSeek-OCR: Contexts Optical Compression , author=. 2025 , eprint=
2025
-
[11]
2026 , eprint=
Autoencoding-Free Context Compression for LLMs via Contextual Semantic Anchors , author=. 2026 , eprint=
2026
-
[12]
2026 , eprint=
COMI: Coarse-to-fine Context Compression via Marginal Information Gain , author=. 2026 , eprint=
2026
-
[13]
Proceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region , pages=
Mitigating entity-level hallucination in large language models , author=. Proceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region , pages=
2024
-
[14]
Proceedings of the 2025 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region , pages=
Dynamic and Parametric Retrieval Augmented Generation , author=. Proceedings of the 2025 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region , pages=
2025
-
[15]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Parametric retrieval augmented generation , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[16]
2026 , eprint=
Skill Retrieval Augmentation for Agentic AI , author=. 2026 , eprint=
2026
-
[17]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Dragin: Dynamic retrieval augmented generation based on the real-time information needs of large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[18]
CoRR , volume =
Tri Nguyen and Mir Rosenberg and Xia Song and Jianfeng Gao and Saurabh Tiwary and Rangan Majumder and Li Deng , title =. CoRR , volume =. 2016 , url =
2016
-
[27]
Applebaum and Zain Anwar and Maame Sarfo
Nikhil Khandekar and Qiao Jin and Guangzhi Xiong and Soren Dunn and Serina S. Applebaum and Zain Anwar and Maame Sarfo. MedCalc-Bench: Evaluating Large Language Models for Medical Calculations , booktitle =. 2024 , url =
2024
-
[28]
Yuchen Zhuang and Yue Yu and Kuan Wang and Haotian Sun and Chao Zhang , editor =. ToolQA:. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , year =
2023
-
[29]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions , booktitle =
Terry Yue Zhuo and Minh Chien Vu and Jenny Chim and Han Hu and Wenhao Yu and Ratnadira Widyasari and Imam Nur Bani Yusuf and Haolan Zhan and Junda He and Indraneil Paul and Simon Brunner and Chen Gong and James Hoang and Armel Randy Zebaze and Xiaoheng Hong and Wen. BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instruc...
2025
-
[30]
Narasimhan and Yuan Cao , title =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R. Narasimhan and Yuan Cao , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[31]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =. 2022 , url =
2022
-
[32]
2026 , note =
Luca Beurer-Kellner and Aleksei Kudrinskii and Marco Milanta and Kristian Bonde Nielsen and Hemang Sarkar and Liran Tal , title =. 2026 , note =
2026
-
[33]
2025 , month = dec, url =
2025
-
[34]
2026 , eprint=
OpenAI GPT-5 System Card , author=. 2026 , eprint=
2026
-
[35]
2018 , eprint=
WikiHow: A Large Scale Text Summarization Dataset , author=. 2018 , eprint=
2018
-
[36]
2025 , eprint=
Context Cascade Compression: Exploring the Upper Limits of Text Compression , author=. 2025 , eprint=
2025
-
[37]
2026 , eprint=
SkVM: Revisiting Language VM for Skills across Heterogenous LLMs and Harnesses , author=. 2026 , eprint=
2026
-
[38]
2026 , eprint=
Red Skills or Blue Skills? A Dive Into Skills Published on ClawHub , author=. 2026 , eprint=
2026
-
[39]
2026 , eprint=
HarmfulSkillBench: How Do Harmful Skills Weaponize Your Agents? , author=. 2026 , eprint=
2026
-
[40]
2026 , note =
OpenClaw , title =. 2026 , note =
2026
-
[41]
2026 , eprint=
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks , author=. 2026 , eprint=
2026
-
[42]
2026 , eprint=
SkillRet: A Large-Scale Benchmark for Skill Retrieval in LLM Agents , author=. 2026 , eprint=
2026
-
[43]
Hewett, Mojan Javaheripi, Piero Kauffmann, James R
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J. Hewett, Mojan Javaheripi, Piero Kauffmann, James R. Lee, Yin Tat Lee, Yuanzhi Li, Weishung Liu, Caio C. T. Mendes, Anh Nguyen, Eric Price, Gustavo de Rosa, Olli Saarikivi, and 8 others. 2024. https://arxiv.org/abs/2412.08905 Phi-4 technic...
Pith/arXiv arXiv 2024
-
[44]
Le Chen, Erhu Feng, Yubin Xia, and Haibo Chen. 2026. https://arxiv.org/abs/2604.03088 Skvm: Revisiting language vm for skills across heterogenous llms and harnesses . Preprint, arXiv:2604.03088
Pith/arXiv arXiv 2026
-
[45]
Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. 2023. https://doi.org/10.18653/V1/2023.EMNLP-MAIN.489 Theoremqa: A theorem-driven question answering dataset . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023 , pages 7889-...
-
[46]
Hongcheol Cho, Ryangkyung Kang, and Youngeun Kim. 2026. https://arxiv.org/abs/2605.05726 Skillret: A large-scale benchmark for skill retrieval in llm agents . Preprint, arXiv:2605.05726
Pith/arXiv arXiv 2026
-
[47]
Tao Ge, Jing Hu, Lei Wang, Xun Wang, Si - Qing Chen, and Furu Wei. 2024. https://openreview.net/forum?id=uREj4ZuGJE In-context autoencoder for context compression in a large language model . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
-
[48]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen - Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen - Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lora: Low-rank adaptation of large language models . In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net
2022
-
[49]
Haichuan Hu, Ye Shang, and Quanjun Zhang. 2026. https://arxiv.org/abs/2604.13064 Red skills or blue skills? a dive into skills published on clawhub . Preprint, arXiv:2604.13064
Pith/arXiv arXiv 2026
-
[50]
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2024. https://doi.org/10.18653/v1/2024.acl-long.91 L ong LLML ingua: Accelerating and enhancing LLM s in long context scenarios via prompt compression . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa...
-
[51]
Yukun Jiang, Yage Zhang, Michael Backes, Xinyue Shen, and Yang Zhang. 2026. https://arxiv.org/abs/2604.15415 Harmfulskillbench: How do harmful skills weaponize your agents? Preprint, arXiv:2604.15415
Pith/arXiv arXiv 2026
-
[52]
Applebaum, Zain Anwar, Maame Sarfo - Gyamfi, Conrad W
Nikhil Khandekar, Qiao Jin, Guangzhi Xiong, Soren Dunn, Serina S. Applebaum, Zain Anwar, Maame Sarfo - Gyamfi, Conrad W. Safranek, Abid A Anwar, Andrew Zhang, Aidan Gilson, Maxwell B. Singer, Amisha D. Dave, Andrew Taylor, Aidong Zhang, Qingyu Chen, and Zhiyong Lu. 2024. http://papers.nips.cc/paper\_files/paper/2024/hash/99e81750f3fdfcaf9613db2dbf4bd623-A...
2024
-
[53]
Mahnaz Koupaee and William Yang Wang. 2018. https://arxiv.org/abs/1810.09305 Wikihow: A large scale text summarization dataset . Preprint, arXiv:1810.09305
Pith/arXiv arXiv 2018
-
[54]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. https://doi.org/10.1145/3600006.3613165 Efficient memory management for large language model serving with pagedattention . In Proceedings of the 29th Symposium on Operating Systems Principles, SOSP '23, page 611–626, New York, ...
-
[55]
Xuancheng Li, Haitao Li, Yujia Zhou, Qingyao Ai, and Yiqun Liu. 2025 a . https://doi.org/10.1145/3767695.3769499 Atacompressor: Adaptive task-aware compression for efficient long-context processing in llms . In Proceedings of the 2025 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region,...
-
[56]
Zongqian Li, Yixuan Su, and Nigel Collier. 2025 b . https://doi.org/10.18653/v1/2025.acl-long.1219 500x C ompressor: Generalized prompt compression for large language models . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 25081--25091, Vienna, Austria. Association for Computationa...
-
[57]
Fanfan Liu and Haibo Qiu. 2025. https://arxiv.org/abs/2511.15244 Context cascade compression: Exploring the upper limits of text compression . Preprint, arXiv:2511.15244
arXiv 2025
-
[58]
Yujun Mao, Yoon Kim, and Yilun Zhou. 2024. https://doi.org/10.18653/V1/2024.FINDINGS-ACL.785 CHAMP: A competition-level dataset for fine-grained analyses of llms' mathematical reasoning capabilities . In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024 , Findings of ACL , pages ...
-
[59]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. https://arxiv.org/abs/1611.09268 MS MARCO: A human generated machine reading comprehension dataset . CoRR, abs/1611.09268
Pith/arXiv arXiv 2016
-
[60]
OpenAI . 2025. https://openai.com/index/introducing-gpt-5-2/ Introducing GPT-5.2 . OpenAI blog post
2025
-
[61]
OpenClaw. 2026 a . C law H ub --- clawhub.ai. https://clawhub.ai/. [Accessed 19-05-2026]
2026
-
[62]
OpenClaw. 2026 b . O pen C law — P ersonal A I A ssistant --- openclaw.ai. https://openclaw.ai/. [Accessed 19-05-2026]
2026
-
[63]
Vicky Zhao, Lili Qiu, and Dongmei Zhang
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor R \"u hle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Dongmei Zhang. 2024. https://doi.org/10.18653/v1/2024.findings-acl.57 LLML ingua-2: Data distillation for efficient and faithful task-agnostic prompt compression . In Findings of the Associatio...
-
[64]
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, and Chitta Baral. 2024. https://doi.org/10.18653/v1/2024.acl-long.739 L ogic B ench: Towards systematic evaluation of logical reasoning ability of large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Li...
-
[65]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. https://doi.org/10.1145/3394486.3406703 Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters . In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD '20, page 3505–3506, New York, NY, U...
-
[66]
Weihang Su, Qian Dong, Qingyao Ai, and Yiqun Liu. 2025 a . Dynamic and parametric retrieval augmented generation. In Proceedings of the 2025 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, pages 453--458
2025
-
[67]
Weihang Su, Jianming Long, Qingyao Ai, Yichen Tang, Changyue Wang, Yiteng Tu, and Yiqun Liu. 2026. https://arxiv.org/abs/2604.24594 Skill retrieval augmentation for agentic ai . Preprint, arXiv:2604.24594
Pith/arXiv arXiv 2026
-
[68]
Weihang Su, Yichen Tang, Qingyao Ai, Changyue Wang, Zhijing Wu, and Yiqun Liu. 2024 a . Mitigating entity-level hallucination in large language models. In Proceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, pages 23--31
2024
-
[69]
Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, and Yiqun Liu. 2024 b . Dragin: Dynamic retrieval augmented generation based on the real-time information needs of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12991--13013
2024
-
[70]
Weihang Su, Yichen Tang, Qingyao Ai, Junxi Yan, Changyue Wang, Hongning Wang, Ziyi Ye, Yujia Zhou, and Yiqun Liu. 2025 b . Parametric retrieval augmented generation. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1240--1250
2025
-
[71]
Zijun Wu, Yongchang Hao, and Lili Mou. 2026. https://arxiv.org/abs/2510.00444 Tokmem: One-token procedural memory for large language models . Preprint, arXiv:2510.00444
arXiv 2026
-
[72]
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. 2024. https://doi.org/10.1145/3626772.3657878 C-pack: Packed resources for general chinese embeddings . In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '24, page 641–649, New York, NY, USA. Assoc...
-
[73]
Wenxuan Xie, Yujia Wang, Xin Tan, Chaochao Lu, Xia Hu, and Xuhong Wang. 2026. https://arxiv.org/abs/2602.10021 Decoupled reasoning with implicit fact tokens (drift): A dual-model framework for efficient long-context inference . Preprint, arXiv:2602.10021
arXiv 2026
-
[74]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[75]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. https://doi.org/10.18653/V1/D18-1259 Hotpotqa: A dataset for diverse, explainable multi-hop question answering . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October...
-
[76]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. https://openreview.net/forum?id=WE\_vluYUL-X React: Synergizing reasoning and acting in language models . In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net
2023
-
[77]
Yingli Zhou, Wang Shu, Yaodong Su, Wenchuan Du, Yixiang Fang, and Xuemin Lin. 2026. https://arxiv.org/abs/2605.07358 A comprehensive survey on agent skills: Taxonomy, techniques, and applications . Preprint, arXiv:2605.07358
Pith/arXiv arXiv 2026
-
[78]
Yuchen Zhuang, Yue Yu, Kuan Wang, Haotian Sun, and Chao Zhang. 2023. http://papers.nips.cc/paper\_files/paper/2023/hash/9cb2a7495900f8b602cb10159246a016-Abstract-Datasets\_and\_Benchmarks.html Toolqa: A dataset for LLM question answering with external tools . In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information ...
2023
-
[79]
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen Gong, James Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen - Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, and 2 others. 2025. https://openreview.net/forum?id=YrycTjllL0 Bigcodebench: Benchmarkin...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.