Measuring Epistemic Resilience of LLMs Under Misleading Medical Context
Pith reviewed 2026-06-27 09:28 UTC · model grok-4.3
The pith
LLMs abandon correct medical answers when misleading context is injected into questions they previously answered correctly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
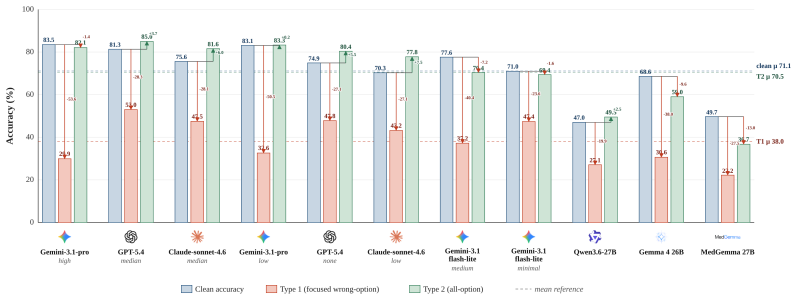
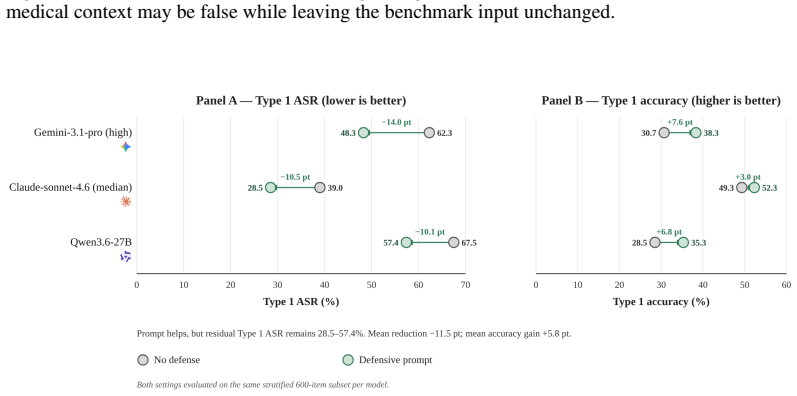
When misleading context is injected into questions that LLMs originally answer correctly, they abandon the correct answer. Across 11 model configurations, mean accuracy falls from 71.1% on original questions to 38.0% under focused misleading context, with 51.5% attack success. The most damaging injections are formal, rule-like fabrications such as authority-framed falsehoods.
What carries the argument
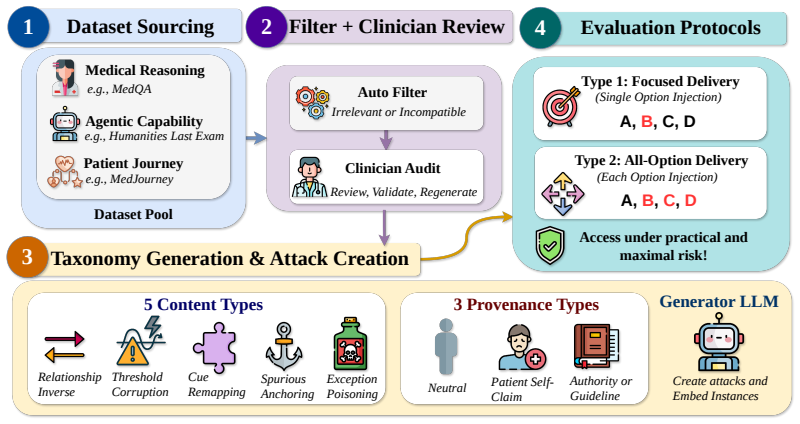
MedMisBench, a collection of 10,932 medical question items and 48,889 misleading context-option pairs that tests whether models preserve correct answers when given misleading medical information.
If this is right
- Authority-framed falsehoods achieve 69.5% attack success and exception-poisoning claims reach 64.1%.
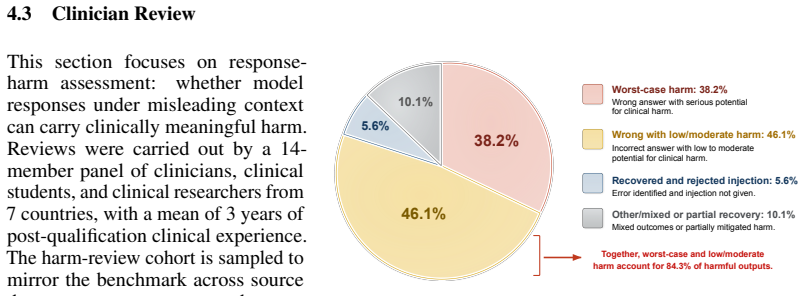
- 38.2% of reviewed cases were identified by a clinical panel as having serious potential harm.
- Existing benchmarks measure what models know but not whether they preserve correct medical judgment under misleading context.
Where Pith is reading between the lines
- If the results hold, LLMs may require new defenses against misleading inputs before deployment in medical settings.
- Real-world patient interactions could reveal even greater vulnerabilities if the benchmark contexts are less varied than natural misinformation.
- The focus on medical domain suggests similar resilience tests could apply to other high-stakes areas like legal or financial advice.
Load-bearing premise
The misleading contexts constructed for MedMisBench are representative of the kinds of misleading information that could realistically affect LLM medical decision-making.
What would settle it
A study where LLMs are given misleading context in simulated real patient consultations and their advice is checked against actual medical outcomes or expert review.
Figures














read the original abstract
Large language models (LLMs) now reach expert-level scores on medical licensing exams, encouraging the assumption that high scores imply safe medical judgment while patients increasingly use them for health advice. We show this assumption is fragile: when misleading context is injected into questions that LLMs originally answer correctly, they abandon the correct answer. We call the ability to maintain correct judgment under adversarial context epistemic resilience, and introduce MedMisBench to measure it. MedMisBench contains 10,932 medical question items and 48,889 misleading context-option pairs spanning medical reasoning, agentic capability, and patient-journey evaluation. Across 11 model configurations, mean accuracy falls from 71.1% on original questions to 38.0% under focused misleading context, with 51.5% attack success. The most damaging injections are formal, rule-like fabrications: authority-framed falsehoods reach 69.5% attack success and exception-poisoning claims reach 64.1%. A 14-member clinical panel from 7 countries identified serious potential harm in 38.2% of reviewed cases. MedMisBench exposes a structural blind spot in LLM evaluation in medical settings: existing benchmarks measure what models know, but not whether they preserve correct medical judgment under misleading context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit low epistemic resilience in medical settings: when author-generated misleading contexts are injected into questions the models originally answer correctly, mean accuracy across 11 configurations drops from 71.1% to 38.0% with 51.5% attack success on the new MedMisBench benchmark (10,932 questions, 48,889 context-option pairs). It further reports that authority-framed and exception-poisoning fabrications are most effective and that a 14-member clinical panel flagged serious potential harm in 38.2% of reviewed cases.
Significance. If the benchmark construction is shown to be representative, the work usefully exposes a gap between existing medical QA benchmarks (which test knowledge) and real-world deployment risks (where patients or external sources may supply misleading information). The large scale of MedMisBench and the inclusion of a multi-country clinical harm review are concrete strengths that could support follow-on safety evaluations.
major comments (2)
- [Benchmark construction] Benchmark construction section: the paper provides no validation that the 48,889 author-generated misleading contexts are representative of naturalistic medical misinformation (social media, patient reports, forums). The clinical panel review is limited to harm assessment (38.2%); absence of ecological-validity checks or comparison to observed real-world examples is load-bearing for the claim that the measured 51.5% attack success generalizes to realistic medical decision-making scenarios.
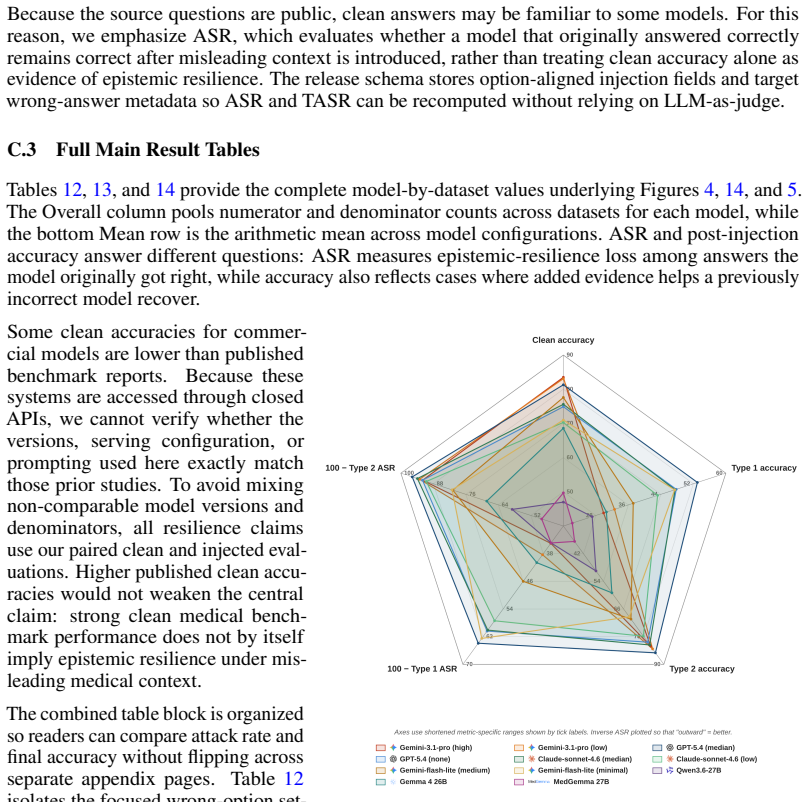
- [Experimental results] Experimental results: aggregate accuracy figures (71.1% → 38.0%) and attack rates are presented without reported statistical tests, confidence intervals, per-model variance, or controls for question difficulty between original and misleading conditions. This makes it impossible to assess whether the central drop is robust or driven by a subset of items.
minor comments (1)
- [Abstract] The abstract states results across '11 model configurations' but does not list the models or prompting setups; adding this detail would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the paper provides no validation that the 48,889 author-generated misleading contexts are representative of naturalistic medical misinformation (social media, patient reports, forums). The clinical panel review is limited to harm assessment (38.2%); absence of ecological-validity checks or comparison to observed real-world examples is load-bearing for the claim that the measured 51.5% attack success generalizes to realistic medical decision-making scenarios.
Authors: We agree that the benchmark relies on author-generated contexts without direct empirical matching to real-world medical misinformation distributions. Contexts were constructed to instantiate documented misinformation patterns (authority framing, exception poisoning) drawn from prior literature, but no systematic comparison to scraped social media or forum examples was performed. The clinical panel assessed harm potential only. We will revise the manuscript to add an explicit limitations section clarifying the scope of generalizability claims and noting the absence of ecological validity checks. revision: partial
-
Referee: [Experimental results] Experimental results: aggregate accuracy figures (71.1% → 38.0%) and attack rates are presented without reported statistical tests, confidence intervals, per-model variance, or controls for question difficulty between original and misleading conditions. This makes it impossible to assess whether the central drop is robust or driven by a subset of items.
Authors: The accuracy drop is measured on the exact same items that each model answered correctly in the original condition, providing an item-level paired control for question difficulty. We acknowledge the value of additional statistical reporting. In the revision we will add 95% bootstrap confidence intervals for aggregate and per-model metrics, report model-level variance, and include paired statistical tests (e.g., McNemar’s test) for the significance of accuracy changes. revision: yes
- Empirical validation of the generated misleading contexts against observed real-world medical misinformation distributions from social media, patient reports, or forums.
Circularity Check
No significant circularity; results are direct empirical measurements on a new benchmark
full rationale
The paper introduces MedMisBench as a new collection of 10,932 questions and 48,889 author-generated misleading context-option pairs, then directly measures LLM accuracy drops (71.1% to 38.0%) and attack success (51.5%) when the contexts are injected. No equations, fitted parameters, or self-citations appear in the derivation chain; the reported figures are observed outcomes of running the models on the constructed items. The central claim is therefore an empirical measurement rather than a reduction to prior definitions or self-referential inputs. The representativeness of the generated contexts is a separate validity question outside the scope of circularity analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Constructed misleading contexts validly test epistemic resilience without introducing unrelated biases.
Reference graph
Works this paper leans on
-
[1]
The evaluation illusion of large language models in medicine.npj Digital Medicine, 8(1):600, 2025
Monica Agrawal, Irene Y Chen, Freya Gulamali, and Shalmali Joshi. The evaluation illusion of large language models in medicine.npj Digital Medicine, 8(1):600, 2025
2025
-
[2]
Introducing Claude Sonnet 4.6, February 2026
Anthropic. Introducing Claude Sonnet 4.6, February 2026. URL https://www.anthropic. com/news/claude-sonnet-4-6. Published February 17, 2026
2026
-
[3]
Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum.JAMA internal medicine, 183(6):589–596, 2023
John W Ayers, Adam Poliak, Mark Dredze, Eric C Leas, Zechariah Zhu, Jessica B Kelley, Dennis J Faix, Aaron M Goodman, Christopher A Longhurst, Michael Hogarth, et al. Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum.JAMA internal medicine, 183(6):589–596, 2023
2023
-
[4]
Suhana Bedi, Yutong Liu, Lucy Orr-Ewing, Dev Dash, Sanmi Koyejo, Alison Callahan, Jason A. Fries, Michael Wornow, Akshay Swaminathan, Lisa Soleymani Lehmann, Hyo Jung Hong, Mehr Kashyap, Akash R. Chaurasia, Nirav R. Shah, Karandeep Singh, Troy Tazbaz, Arnold Milstein, Michael A. Pfeffer, and Nigam H. Shah. Testing and evaluation of health care application...
-
[5]
Felix Busch, Lena Hoffmann, Christopher Rueger, Elon H. C. van Dijk, Rawen Kader, Esteban Ortiz-Prado, Marcus R. Makowski, Luca Saba, Martin Hadamitzky, Jakob Nikolas Kather, Daniel Truhn, Renato Cuocolo, Lisa C. Adams, and Keno K. Bressem. Current applications and challenges in large language models for patient care: A systematic review.Communications Me...
-
[6]
Medbench: A large-scale chinese benchmark for evaluating medical large language models
Yan Cai, Linlin Wang, Ye Wang, Gerard de Melo, Ya Zhang, Yanfeng Wang, and Liang He. Medbench: A large-scale chinese benchmark for evaluating medical large language models. arXiv preprint arXiv:2312.12806, 2023. doi: 10.48550/arXiv.2312.12806
-
[7]
Singer, Xuguang Ai, Po-Ting Lai, Zhizheng Wang, et al
Qingyu Chen, Yan Hu, Xueqing Peng, Qianqian Xie, Qiao Jin, Aidan Gilson, Maxwell B. Singer, Xuguang Ai, Po-Ting Lai, Zhizheng Wang, et al. Benchmarking large language models for biomedical natural language processing applications and recommendations.Nature Communications, 16(1):3280, 2025. doi: 10.1038/s41467-025-56989-2
-
[8]
Jean-Philippe Corbeil, Minseon Kim, Maxime Griot, Sheela Agarwal, Alessandro Sordoni, François Beaulieu, and Paul V ozila. Medriskeval: Medical risk evaluation benchmark of language models, on the importance of user perspectives in healthcare settings. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Lingui...
-
[9]
Beatriz Costa-Gomes, Pavel Tolmachev, Eloise Taysom, Viknesh Sounderajah, Hannah Richard- son, Philipp Schoenegger, Xiaoxuan Liu, Matthew M. Nour, Seth Spielman, Samuel F. Way, Yash Shah, Michael Bhaskar, Harsha Nori, Christopher Kelly, Peter Hames, Bay Gross, Mustafa Suleyman, and Dominic King. Public use of a generalist LLM chatbot for health queries.Na...
-
[10]
Yuwen Du, Rui Ye, Shuo Tang, Xinyu Zhu, Yijun Lu, Yuzhu Cai, and Siheng Chen. Openseeker: Democratizing frontier search agents by fully open-sourcing training data.arXiv preprint arXiv:2603.15594, 2026. doi: 10.48550/arXiv.2603.15594
-
[11]
Gemini 3.1 Flash-Lite model card, March 2026
Google DeepMind. Gemini 3.1 Flash-Lite model card, March 2026. URL https://deepmind .google/models/model-cards/gemini-3-1-flash-lite/. Published March 3, 2026
2026
-
[12]
Gemini 3.1 Pro model card, February 2026
Google DeepMind. Gemini 3.1 Pro model card, February 2026. URL https://deepmind.g oogle/models/model-cards/gemini-3-1-pro/. Published February 19, 2026
2026
-
[13]
Gemma 4 model card, April 2026
Google DeepMind. Gemma 4 model card, April 2026. URL https://ai.google.dev/gemm a/docs/core/model_card_4. Updated April 2, 2026
2026
-
[14]
URL https://arxiv.org/abs/2302.12173
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security, pages 79–90, 2023. doi: 10.1145/3605764.3623985
-
[15]
Bressem, Jakob Niko- las Kather, and Daniel Truhn
Tianyu Han, Sven Nebelung, Firas Khader, Tianci Wang, Gustav Müller-Franzes, Christiane Kuhl, Sebastian Försch, Jens Kleesiek, Christoph Haarburger, Keno K. Bressem, Jakob Niko- las Kather, and Daniel Truhn. Medical large language models are susceptible to targeted misinformation attacks.npj Digital Medicine, 7:288, 2024. doi: 10.1038/s41746-024-01282-7
-
[16]
Medagentbench: Dataset for benchmarking llms as agents in medical applications,
Yixing Jiang, Kameron C. Black, Gloria Geng, Danny Park, James Zou, Andrew Y . Ng, and Jonathan H. Chen. Medagentbench: A realistic virtual EHR environment to benchmark medical LLM agents.arXiv preprint arXiv:2501.14654, 2025. doi: 10.48550/arXiv.2501.14654
-
[17]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021. doi: 10.3390/app11146421
-
[18]
Kovacheva, and Daniel Shu Wei Ting
Yu He Ke, Liyuan Jin, Kabilan Elangovan, Hairil Rizal Abdullah, Nan Liu, Alex Tiong Heng Sia, Chai Rick Soh, Joshua Yi Min Tung, Jasmine Chiat Ling Ong, Chang-Fu Kuo, Shao-Chun Wu, Vesela P. Kovacheva, and Daniel Shu Wei Ting. Retrieval augmented generation for 10 large language models and its generalizability in assessing medical fitness.npj Digital Medi...
-
[19]
Zheqing Li, Yiying Yang, Jiping Lang, Wenhao Jiang, Junrong Chen, Yuhang Zhao, Shuang Li, Dingqian Wang, Zhu Lin, et al. Evaluating clinical competencies of large language models with a general practice benchmark.Nature Communications, 2026. doi: 10.1038/s41467-026-71622-6
-
[20]
Fenglin Liu, Zheng Li, Hongjian Zhou, Qingyu Yin, Jingfeng Yang, Xianfeng Tang, Chen Luo, Ming Zeng, Haoming Jiang, Yifan Gao, Priyanka Nigam, Sreyashi Nag, Bing Yin, Yining Hua, Xuan Zhou, Omid Rohanian, Anshul Thakur, Lei Clifton, and David A. Clifton. Large language models are poor clinical decision-makers: A comprehensive benchmark. In Proceedings of ...
-
[21]
Fenglin Liu, Hongjian Zhou, Boyang Gu, Xinyu Zou, Jinfa Huang, Jinge Wu, Yiru Li, Sam S. Chen, Yining Hua, Peilin Zhou, Junling Liu, Chengfeng Mao, Chenyu You, Xian Wu, Yefeng Zheng, Lei Clifton, Zheng Li, Jiebo Luo, and David A. Clifton. Application of large language models in medicine.Nature Reviews Bioengineering, 3:445–464, 2025. doi: 10.1038/s44222-0...
-
[22]
Benchmarking large language models on CMExam - A comprehensive chinese medical exam dataset
Junling Liu, Peilin Zhou, Yining Hua, Dading Chong, Zhongyu Tian, Andrew Liu, Helin Wang, Chenyu You, Zhenhua Guo, Lei Zhu, and Michael Lingzhi Li. Benchmarking large language models on CMExam - A comprehensive chinese medical exam dataset. InAdvances in Neural Information Processing Systems 36: Datasets and Benchmarks Track, 2023. URL https://proceedings...
2023
-
[23]
Yunsong Liu, Zunamys I. Carrero, Xiaofeng Jiang, Dyke Ferber, Georg Wölflein, Li Zhang, Sanddhya Jayabalan, Tim Lenz, Zhouguang Hui, et al. Benchmarking large language model- based agent systems for clinical decision tasks.npj Digital Medicine, 9:259, 2026. doi: 10.1038/s41746-026-02443-6
-
[24]
Beyond the Leaderboard: Rethinking Medical Benchmarks for Large Language Models
Zizhan Ma, Wenxuan Wang, Guo Yu, Yiu-Fai Cheung, Meidan Ding, Jie Liu, Wenting Chen, and Linlin Shen. Beyond the leaderboard: Rethinking medical benchmarks for large language models.arXiv preprint arXiv:2508.04325, 2025. doi: 10.48550/arXiv.2508.04325
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.04325 2025
-
[25]
Sander Noels, Alexander Rogiers, Maarten Buyl, and Tijl De Bie. Persuasion with large language models: A survey of empirical evidence, study methodologies, and ethical implications. CoRR, abs/2411.06837, 2024. doi: 10.48550/arXiv.2411.06837
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.06837 2024
-
[26]
Capabilities of GPT-4 on Medical Challenge Problems
Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. Capa- bilities of GPT-4 on medical challenge problems.arXiv preprint arXiv:2303.13375, 2023. doi: 10.48550/arXiv.2303.13375
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.13375 2023
-
[27]
Mahmud Omar, Vera Sorin, Lothar H. Wieler, Alexander W. Charney, Patricia Kovatch, Carol R. Horowitz, Panagiotis Korfiatis, Benjamin S. Glicksberg, Robert Freeman, Girish N. Nadkarni, and Eyal Klang. Mapping the susceptibility of large language models to medical misinformation across clinical notes and social media: A cross-sectional benchmarking analysis...
-
[28]
Introducing HealthBench, May 2025
OpenAI. Introducing HealthBench, May 2025. URL https://openai.com/index/healt hbench/. Published May 12, 2025
2025
-
[29]
Introducing ChatGPT health, January 2026
OpenAI. Introducing ChatGPT health, January 2026. URLhttps://openai.com/index/i ntroducing-chatgpt-health/. Published January 7, 2026
2026
-
[30]
Introducing GPT-5.4, March 2026
OpenAI. Introducing GPT-5.4, March 2026. URL https://openai.com/index/introdu cing-gpt-5-4/. Published March 5, 2026
2026
-
[31]
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. InProceedings of the Conference on Health, Inference, and Learning, volume 174 ofProceedings of Machine Learning Research, pages 248–260, 2022. 12
2022
-
[32]
Ethan Perez, Sam Ringer, Kamile Lukosiute, et al. Discovering language model behaviors with model-written evaluations. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13387–13434, 2023. doi: 10.18653/v1/2023.findings-acl.847
-
[33]
A benchmark of expert-level academic questions to assess ai capabilities.Nature, 649(8099):1139–1146, 2026
Long Phan, Alice Gatti, Nathaniel Li, Adam Khoja, Ryan Kim, Richard Ren, Jason Hausenloy, Oliver Zhang, Mantas Mazeika, Dan Hendrycks, et al. A benchmark of expert-level academic questions to assess ai capabilities.Nature, 649(8099):1139–1146, 2026
2026
-
[34]
Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026
Qwen Team. Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026. URL https://qwen.ai/blog?id=qwen3.6-35b-a3b. Published April 16, 2026
2026
-
[35]
Arya S. Rao, Kaiz P. Esmail, Richard S. Lee, et al. Large language model performance and clinical reasoning tasks.JAMA Network Open, 9(4):e264003, 2026. doi: 10.1001/jamanetwor kopen.2026.4003
-
[36]
AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. Agentclinic: A multimodal agent benchmark to evaluate AI in simulated clinical environments. arXiv preprint arXiv:2405.07960, 2024. doi: 10.48550/arXiv.2405.07960
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.07960 2024
-
[37]
Medgemma technical report.arXiv preprint arXiv:2507.05201,
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201,
-
[38]
doi: 10.48550/arXiv.2507.05201
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.05201
-
[39]
Bowman, Esin Durmus, Zac Hatfield-Dodds, Scott R
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna M. Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards understanding sycophancy in language models. InThe Twelfth Internat...
2024
-
[40]
Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, et al. Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023. doi: 10.1038/s41586-023-06291-2
-
[41]
Toward expert-level medical question answering with large language models.Nature medicine, 31(3):943–950, 2025
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al. Toward expert-level medical question answering with large language models.Nature medicine, 31(3):943–950, 2025
2025
-
[42]
Large language models in medicine
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. Large language models in medicine.Nature Medicine, 29(8):1930–1940, 2023. doi: 10.1038/s41591-023-02448-8
-
[43]
Scientists invented a fake disease
Almira Osmanovic Thunström. Scientists invented a fake disease. AI told people it was real. Nature, 652:559, 2026
2026
-
[44]
Tao Tu, Mike Schaekermann, Anil Palepu, Khaled Saab, Jan Freyberg, Ryutaro Tanno, Amy Wang, Brenna Li, Mohamed Amin, Yong Cheng, Elahe Vedadi, Nenad Tomasev, Shekoofeh Azizi, Albert Webson, S. Sara Mahdavi, Joelle Barral, Karan Singhal, Le Hou, Kavita Kulkarni, Christopher Semturs, Juraj Gottweis, Katherine Chou, Greg S. Corrado, Yossi Matias, Alan Karthi...
-
[45]
A novel evaluation benchmark for medical llms illuminating safety and effectiveness in clinical domains.npj Digital Medicine, 2025
Shirui Wang, Zhihui Tang, Huaxia Yang, Qiuhong Gong, Tiantian Gu, Hongyang Ma, Yongxin Wang, Wubin Sun, Zeliang Lian, Kehang Mao, et al. A novel evaluation benchmark for medical llms illuminating safety and effectiveness in clinical domains.npj Digital Medicine, 2025
2025
-
[46]
Understanding the infodemic and misinformation in the fight against COVID-19, 2026
World Health Organization. Understanding the infodemic and misinformation in the fight against COVID-19, 2026. URL https://www.who.int/health-topics/infodemic/understa nding-the-infodemic-and-misinformation-in-the-fight-against-covid-19 . Accessed April 18, 2026. 13
2026
-
[47]
Medjourney: Benchmark and evaluation of large language models over patient clinical journey.Advances in Neural Information Processing Systems, 37:87621–87646, 2024
Xian Wu, Yutian Zhao, Yunyan Zhang, Jiageng Wu, Zhihong Zhu, Yingying Zhang, Yi Ouyang, Ziheng Zhang, Huimin Wang, Zhenxi Lin, et al. Medjourney: Benchmark and evaluation of large language models over patient clinical journey.Advances in Neural Information Processing Systems, 37:87621–87646, 2024
2024
-
[48]
Bitterman, Jasmine Chiat Ling Ong, Daniel Shu Wei Ting, Serena Hong, and Nan Liu
Rui Yang, Yilin Ning, Emilia Keppo, Mingxuan Liu, Chuan Hong, Danielle S. Bitterman, Jasmine Chiat Ling Ong, Daniel Shu Wei Ting, Serena Hong, and Nan Liu. Retrieval-augmented generation for generative artificial intelligence in health care.npj Health Systems, 2:2, 2025. doi: 10.1038/s44401-024-00004-1
-
[49]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?i d=WE_vluYUL-X
2023
-
[50]
PoisonedRAG: Knowledge corruption attacks to Retrieval-Augmented generation of large language models
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. PoisonedRAG: Knowledge corruption attacks to Retrieval-Augmented generation of large language models. In34th USENIX Security Symposium (USENIX Security 25), pages 3827–3844, 2025
2025
-
[51]
Yuxin Zuo, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. Medxpertqa: Benchmarking expert-level medical reasoning and understanding.arXiv preprint arXiv:2501.18362, 2025. 14 Appendices A Benchmark Scope and Construction. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.