Fourier Features Let Agents Learn High Precision Policies with Imitation Learning
Pith reviewed 2026-06-27 10:40 UTC · model grok-4.3
The pith
Fourier features let point-cloud policies learn high-precision manipulation by accessing high-frequency details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
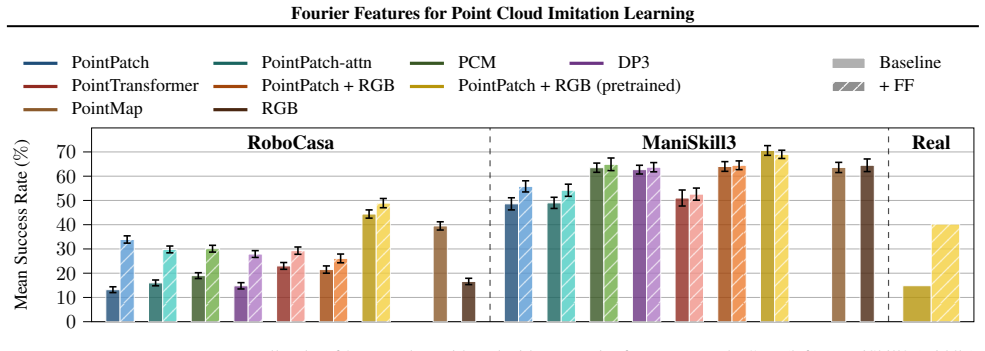
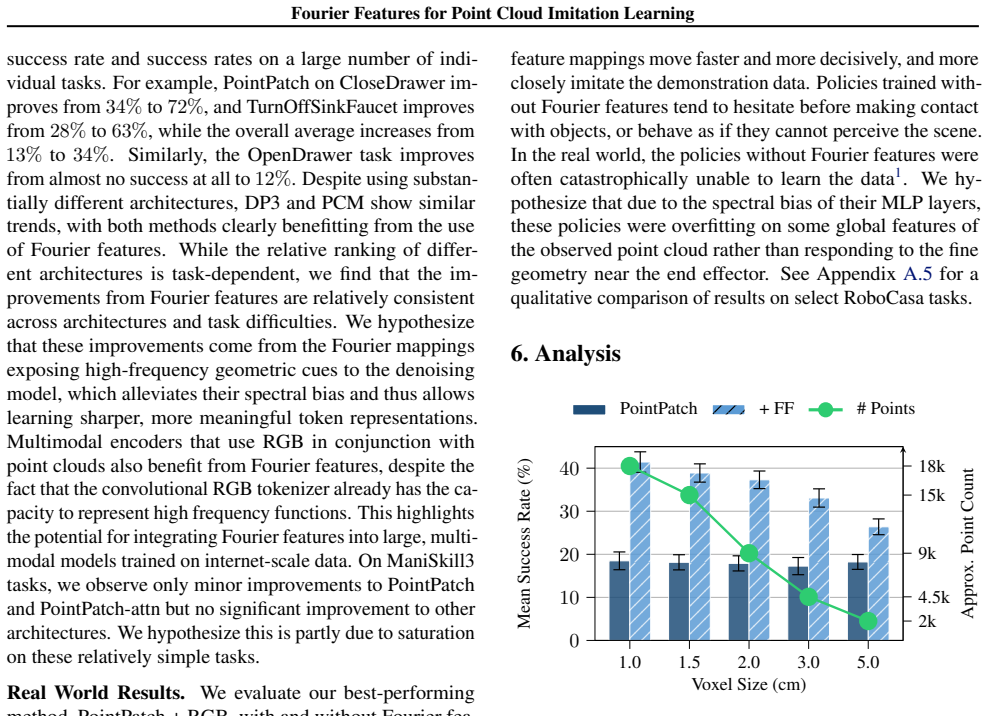
Mapping point clouds from Cartesian space into high-dimensional Fourier space equips the encoder with direct high-frequency features; this change produces significant performance gains on high-precision manipulation tasks across diverse architectures and benchmarks while remaining robust to hyperparameter variation.
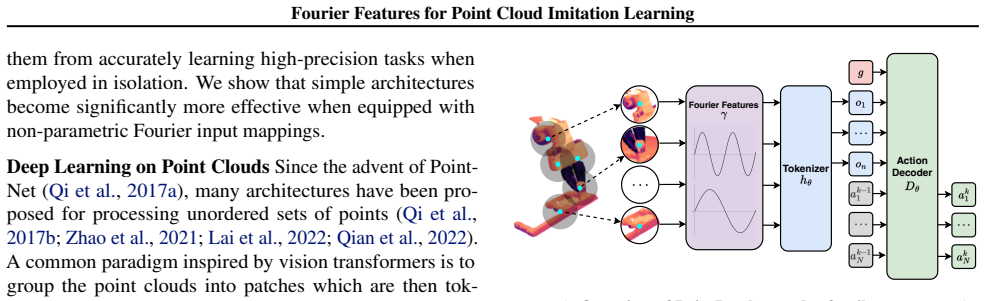
What carries the argument
The mapping of point clouds from Cartesian space into high-dimensional Fourier space, supplying direct high-frequency features to the policy network.
If this is right
- Policies achieve higher success rates on fine-grained manipulation tasks from the RoboCasa and ManiSkill3 suites.
- The same Fourier mapping improves results across multiple point-cloud encoder architectures.
- Performance gains hold on physical robot hardware as well as simulation.
- The method remains effective without extensive hyperparameter tuning.
Where Pith is reading between the lines
- The same Cartesian-to-Fourier transform could be applied to other 3D input modalities such as depth images or voxel grids to test generality beyond point clouds.
- If spectral bias is the dominant bottleneck, Fourier features might reduce the need for deeper networks or larger datasets in geometric imitation tasks.
- Tasks that combine point clouds with RGB could use Fourier features on the 3D branch to compensate for perspective and scale ambiguities in the image branch.
Load-bearing premise
The performance gap between point-cloud and image-based policies arises primarily from spectral bias in networks conditioned on Cartesian features.
What would settle it
A controlled task requiring only low-frequency spatial distinctions where adding Fourier features produces no measurable improvement over Cartesian inputs.
Figures


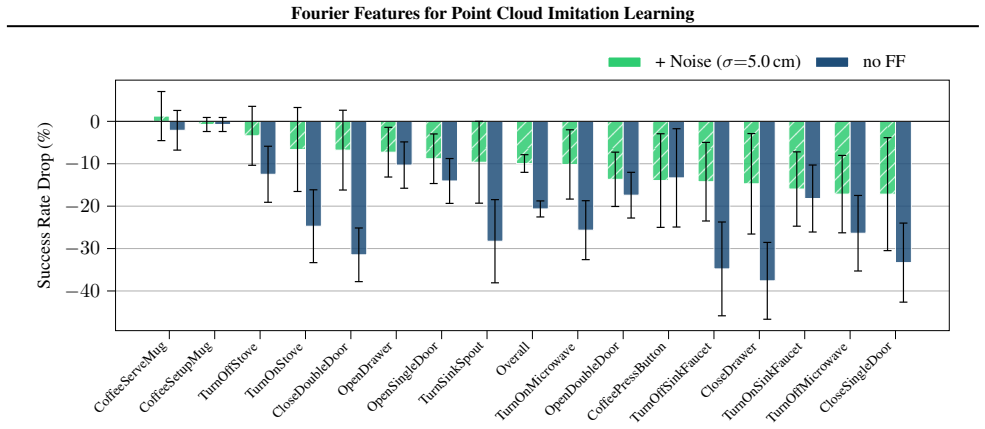

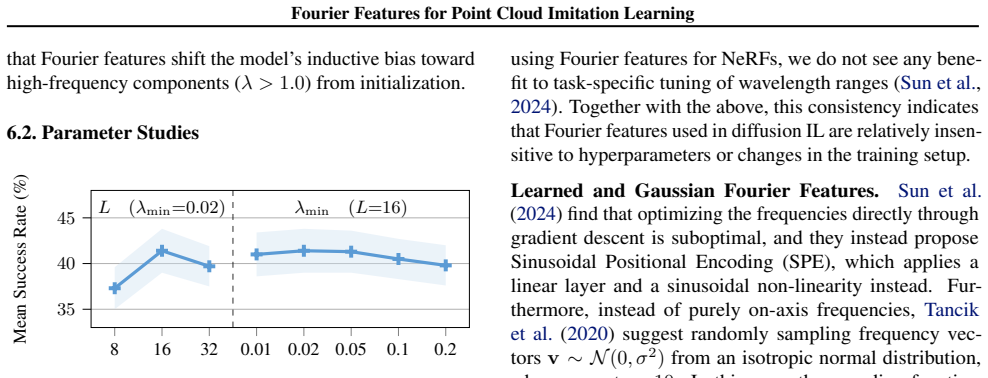



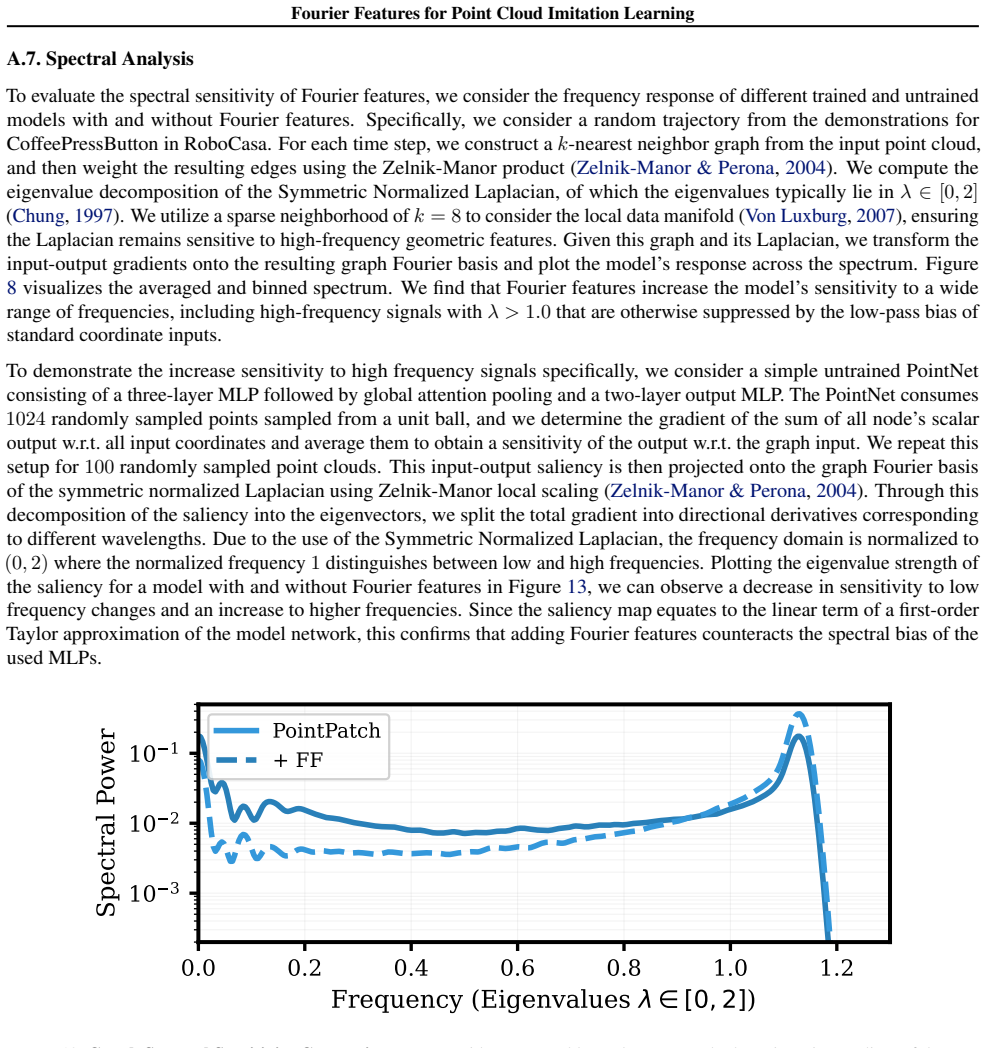
read the original abstract
High-precision robotic manipulation requires fine-grained spatial reasoning that is often difficult to achieve with RGB-only policies due to depth ambiguity and perspective scale issues. Policies that leverage 3D information directly, such as those based on point clouds, offer a stronger geometric prior over purely image-based ones, yet their performance remains highly task-dependent. We hypothesize that this discrepancy may be due to the spectral bias of neural networks towards learning low frequency functions, which especially affects architectures conditioned on slow-moving Cartesian features. We thus propose to map point clouds from Cartesian space into high-dimensional Fourier space, effectively equipping the point cloud encoder with direct access to high-frequency features. We experimentally validate the use of Fourier features on challenging manipulation tasks from the RoboCasa and ManiSkill3 benchmarks and on a real robot setup. Despite their simplicity, we find that Fourier features provide significant benefits across diverse encoder architectures and benchmarks and are robust across hyperparameters. Our results indicate that Fourier features let policies leverage geometric details more effectively than Cartesian features, showing their potential as a general-purpose tool for point cloud-based imitation learning. We provide source code and videos on our project page: https://fourier-il.github.io/fourier-il
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that neural networks exhibit spectral bias toward low-frequency functions when conditioned on Cartesian point-cloud coordinates, limiting high-precision robotic manipulation; mapping inputs to high-dimensional Fourier features provides direct access to high-frequency geometric details, yielding significant performance gains across encoder architectures on RoboCasa and ManiSkill3 benchmarks plus a real-robot setup. The method is presented as a simple, robust, general-purpose tool for point-cloud imitation learning, with source code released.
Significance. If the reported gains hold and the mechanism is confirmed, the approach offers a lightweight, architecture-agnostic improvement for geometric reasoning in IL without requiring new network designs. Releasing source code and videos strengthens reproducibility and allows direct verification of the empirical claims.
major comments (2)
- [Abstract / hypothesis paragraph] Abstract and hypothesis paragraph: the central claim attributes performance gains specifically to mitigation of spectral bias via high-frequency Fourier access, yet no direct test (Fourier analysis of learned mappings, frequency-content ablation, or comparison holding input dimensionality fixed) is described to establish this causal mechanism over alternatives such as increased input dimension or altered optimization dynamics.
- [Experimental sections (implied by abstract)] Experimental validation sections: while positive results are reported on multiple benchmarks and a real robot, the abstract provides no quantitative numbers, baseline details, statistical tests, or ablation tables; without these, it is impossible to assess effect sizes, rule out post-hoc tuning, or confirm robustness claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript to improve clarity and strengthen the supporting evidence.
read point-by-point responses
-
Referee: [Abstract / hypothesis paragraph] Abstract and hypothesis paragraph: the central claim attributes performance gains specifically to mitigation of spectral bias via high-frequency Fourier access, yet no direct test (Fourier analysis of learned mappings, frequency-content ablation, or comparison holding input dimensionality fixed) is described to establish this causal mechanism over alternatives such as increased input dimension or altered optimization dynamics.
Authors: We agree that a direct test isolating the frequency mechanism from dimensionality or optimization effects would strengthen the causal interpretation. The current results demonstrate consistent gains across encoder architectures and tasks, but we did not perform Fourier analysis of the learned mappings or a fixed-dimensionality random-projection control. In the revision we will add an ablation comparing Fourier features against a high-dimensional random projection baseline (matched dimensionality, no explicit frequency structure) and will report the outcomes. We will also qualify the mechanistic claim in the abstract and hypothesis paragraph to reflect the current level of evidence. revision: yes
-
Referee: [Experimental sections (implied by abstract)] Experimental validation sections: while positive results are reported on multiple benchmarks and a real robot, the abstract provides no quantitative numbers, baseline details, statistical tests, or ablation tables; without these, it is impossible to assess effect sizes, rule out post-hoc tuning, or confirm robustness claims.
Authors: The main experimental sections and supplementary material already contain quantitative success rates, baseline comparisons, ablation tables, and robustness checks across hyperparameters and architectures. The abstract, however, is written at a high level and omits specific metrics. We will revise the abstract to include representative quantitative gains (e.g., success-rate improvements on RoboCasa and ManiSkill3) together with a brief statement on statistical robustness and the release of code for reproducibility. revision: yes
Circularity Check
No circularity; empirical validation on benchmarks is independent of any derivation or fitted inputs
full rationale
The paper advances a hypothesis that spectral bias explains performance gaps between Cartesian and point-cloud policies, then proposes Fourier feature mapping and reports experimental gains on RoboCasa and ManiSkill3. No equations, parameter fits, or self-citations are invoked to derive the claimed benefits; the results rest on direct policy comparisons rather than any reduction of outputs to inputs by construction. The central claim therefore remains self-contained against external benchmarks and does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural networks exhibit spectral bias towards low-frequency functions, especially when conditioned on slow-moving Cartesian features.
Forward citations
Cited by 1 Pith paper
-
Human Universal Grasping
HUG trains a flow-matching model on a new 1M-frame egocentric human grasp dataset to generate retargetable grasps from single RGB-D images, beating baselines by 23-34% on a new 90-object benchmark.
Reference graph
Works this paper leans on
-
[1]
A., Hirata, R., and Wang, Z
Abello, A. A., Hirata, R., and Wang, Z. Dissecting the high-frequency bias in convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 863--871, 2021
2021
-
[2]
S., Courville, A., and Bellemare, M
Agarwal, R., Schwarzer, M., Castro, P. S., Courville, A., and Bellemare, M. G. Deep reinforcement learning at the edge of the statistical precipice. Advances in Neural Information Processing Systems, 2021
2021
-
[3]
T., Mildenhall, B., Verbin, D., Srinivasan, P
Barron, J. T., Mildenhall, B., Verbin, D., Srinivasan, P. P., and Hedman, P. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 5470--5479, 2022
2022
-
[4]
\_0 : A vision-language-action flow model for general robot control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al. \_0 : A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[5]
Rt-1: Robotics transformer for real-world control at scale
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Hsu, J., et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[6]
Pointgpt: Auto-regressively generative pre-training from point clouds
Chen, G., Wang, M., Yang, Y., Yu, K., Yuan, L., and Yue, Y. Pointgpt: Auto-regressively generative pre-training from point clouds. Advances in Neural Information Processing Systems, 36: 0 29667--29679, 2023
2023
-
[7]
Sugar: Pre-training 3d visual representations for robotics
Chen, S., Garcia, R., Laptev, I., and Schmid, C. Sugar: Pre-training 3d visual representations for robotics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 18049--18060, June 2024
2024
-
[8]
Diffusion policy: Visuomotor policy learning via action diffusion
Chi, C., Feng, S., Du, Y., Xu, Z., Cousineau, E., Burchfiel, B., and Song, S. Diffusion policy: Visuomotor policy learning via action diffusion. In Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[9]
Chung, F. R. Spectral Graph Theory, volume 92. American Mathematical Soc., 1997
1997
-
[10]
Towards fusing point cloud and visual representations for imitation learning
Donat, A., Jia, X., Huang, X., Taranovic, A., Blessing, D., Li, G., Zhou, H., Zhang, H., Lioutikov, R., and Neumann, G. Towards fusing point cloud and visual representations for imitation learning. In 7th Robot Learning Workshop: Towards Robots with Human-Level Abilities, 2025. URL https://openreview.net/forum?id=5cG7ilWX1V
2025
-
[11]
Adaptive positional encoding for bundle-adjusting neural radiance fields
Gao, Z., Dai, W., and Zhang, Y. Adaptive positional encoding for bundle-adjusting neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 3284--3294, 2023
2023
-
[12]
Act3d: 3d feature field transformers for multi-task robotic manipulation
Gervet, T., Xian, Z., Gkanatsios, N., and Fragkiadaki, K. Act3d: 3d feature field transformers for multi-task robotic manipulation. arXiv preprint arXiv:2306.17817, 2023
arXiv 2023
-
[13]
Rvt: Robotic view transformer for 3d object manipulation
Goyal, A., Xu, J., Guo, Y., Blukis, V., Chao, Y.-W., and Fox, D. Rvt: Robotic view transformer for 3d object manipulation. In Conference on Robot Learning, pp.\ 694--710. PMLR, 2023
2023
-
[14]
Pointpatch RL - masked reconstruction improves reinforcement learning on point clouds
Gyenes, B., Franke, N., Becker, P., and Neumann, G. Pointpatch RL - masked reconstruction improves reinforcement learning on point clouds. In 8th Annual Conference on Robot Learning, 2024. URL https://openreview.net/forum?id=3jNEz3kUSl
2024
-
[15]
M., Henrich, P., Younis, R., Neumann, G., Wagner, M., and Mathis-Ullrich, F
Gyenes, B., Franke, N., Scheikl, P. M., Henrich, P., Younis, R., Neumann, G., Wagner, M., and Mathis-Ullrich, F. Point cloud segmentation for autonomous clip positioning in laparoscopic cholecystectomy on a phantom. IEEE Robotics and Automation Letters, 10 0 (8): 0 8522--8529, 2025. doi:10.1109/LRA.2025.3585357
-
[16]
Deep residual learning for image recognition, 2015
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385
Pith/arXiv arXiv 2015
-
[17]
Denoising diffusion probabilistic models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 0 6840--6851, 2020
2020
-
[18]
Hornik, K., Stinchcombe, M., and White, H. Multilayer feedforward networks are universal approximators. Neural Networks, 2 0 (5): 0 359--366, 1989. ISSN 0893-6080. doi:https://doi.org/10.1016/0893-6080(89)90020-8. URL https://www.sciencedirect.com/science/article/pii/0893608089900208
-
[19]
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Galliker, M. Y., Ghosh, D., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., LeBlanc, D., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Ren, A. Z., Shi, L. X., Smith, L., Springenberg, J. T., Sta...
Pith/arXiv arXiv 2025
-
[20]
Pointmappolicy: Structured point cloud processing for multi-modal imitation learning
Jia, X., Wang, Q., Wang, A., Wang, H., Gyenes, B., Gospodinov, E., Jiang, X., Li, G., Zhou, H., Liao, W., Huang, X., Beck, M., Reuss, M., Lioutikov, R., and Neumann, G. Pointmappolicy: Structured point cloud processing for multi-modal imitation learning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025 a . URL https://o...
2025
-
[21]
Lift3d policy: Lifting 2d foundation models for robust 3d robotic manipulation
Jia, Y., Liu, J., Chen, S., Gu, C., Wang, Z., Luo, L., Li, X., Wang, P., Wang, Z., Zhang, R., and Zhang, S. Lift3d policy: Lifting 2d foundation models for robust 3d robotic manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 17347--17358, June 2025 b
2025
-
[22]
Jo, J. and Bengio, Y. Measuring the tendency of cnns to learn surface statistical regularities. arXiv preprint arXiv:1711.11561, 2017
Pith/arXiv arXiv 2017
-
[23]
Elucidating the design space of diffusion-based generative models
Karras, T., Aittala, M., Aila, T., and Laine, S. Elucidating the design space of diffusion-based generative models. In Oh, A. H., Agarwal, A., Belgrave, D., and Cho, K. (eds.), Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=k7FuTOWMOc7
2022
-
[24]
3d diffuser actor: Policy diffusion with 3d scene representations
Ke, T.-W., Gkanatsios, N., and Fragkiadaki, K. 3d diffuser actor: Policy diffusion with 3d scene representations. In Agrawal, P., Kroemer, O., and Burgard, W. (eds.), Proceedings of The 8th Conference on Robot Learning, volume 270 of Proceedings of Machine Learning Research, pp.\ 1949--1974. PMLR, 06--09 Nov 2025. URL https://proceedings.mlr.press/v270/ke25a.html
1949
-
[25]
Stratified transformer for 3d point cloud segmentation
Lai, X., Liu, J., Jiang, L., Wang, L., Zhao, H., Liu, S., Qi, X., and Jia, J. Stratified transformer for 3d point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 8500--8509, June 2022
2022
-
[26]
Pointvla: Injecting the 3d world into vision-language-action models
Li, C., Wen, J., Peng, Y., Peng, Y., and Zhu, Y. Pointvla: Injecting the 3d world into vision-language-action models. IEEE Robotics and Automation Letters, 11 0 (3): 0 2506--2513, 2026. doi:10.1109/LRA.2026.3653303
-
[27]
Lipman, Y., Chen, R. T. Q., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=PqvMRDCJT9t
2023
-
[28]
Pde-refiner: Achieving accurate long rollouts with neural pde solvers
Lippe, P., Veeling, B., Perdikaris, P., Turner, R., and Brandstetter, J. Pde-refiner: Achieving accurate long rollouts with neural pde solvers. Advances in Neural Information Processing Systems, 36: 0 67398--67433, 2023
2023
-
[29]
Improving robustness of 3d point cloud recognition from a fourier perspective
Miao, Y., Dong, Y., Zhang, J., Yu, L., Yang, X., and Gao, X.-S. Improving robustness of 3d point cloud recognition from a fourier perspective. Advances in Neural Information Processing Systems, 37: 0 68183--68210, 2024
2024
-
[30]
P., Tancik, M., Barron, J
Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., and Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65 0 (1): 0 99--106, 2021
2021
-
[31]
Robocasa: Large-scale simulation of everyday tasks for generalist robots
Nasiriany, S., Maddukuri, A., Zhang, L., Parikh, A., Lo, A., Joshi, A., Mandlekar, A., and Zhu, Y. Robocasa: Large-scale simulation of everyday tasks for generalist robots. In Robotics: Science and Systems (RSS), 2024
2024
-
[32]
E., Liu, W., Tian, Y., and Yuan, L
Pang, Y., Wang, W., Tay, F. E., Liu, W., Tian, Y., and Yuan, L. Masked autoencoders for point cloud self-supervised learning. In European Conference on Computer Vision, pp.\ 604--621. Springer, 2022
2022
-
[33]
R., Su, H., Mo, K., and Guibas, L
Qi, C. R., Su, H., Mo, K., and Guibas, L. J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 652--660, 2017 a
2017
-
[34]
R., Yi, L., Su, H., and Guibas, L
Qi, C. R., Yi, L., Su, H., and Guibas, L. J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv preprint arXiv:1706.02413, 2017 b
Pith/arXiv arXiv 2017
-
[35]
Pointnext: Revisiting pointnet++ with improved training and scaling strategies
Qian, G., Li, Y., Peng, H., Mai, J., Hammoud, H., Elhoseiny, M., and Ghanem, B. Pointnext: Revisiting pointnet++ with improved training and scaling strategies. Advances in neural information processing systems, 35: 0 23192--23204, 2022
2022
-
[36]
W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp.\ 8748--8763. PmLR, 2021
2021
-
[37]
On the spectral bias of neural networks
Rahaman, N., Baratin, A., Arpit, D., Draxler, F., Lin, M., Hamprecht, F., Bengio, Y., and Courville, A. On the spectral bias of neural networks. In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp.\ 5301--5310. PMLR, 09--15 Jun 2019. ...
2019
-
[38]
Goal conditioned imitation learning using score-based diffusion policies
Reuss, M., Li, M., Jia, X., and Lioutikov, R. Goal conditioned imitation learning using score-based diffusion policies. In Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[39]
Scarselli, F., Gori, M., Tsoi, A. C., Hagenbuchner, M., and Monfardini, G. The graph neural network model. IEEE Transactions on Neural Networks, 20 0 (1): 0 61--80, 2009. doi:10.1109/TNN.2008.2005605
-
[40]
Denoising diffusion implicit models
Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models. In ICLR, 2021
2021
-
[41]
and Dhariwal, P
Song, Y. and Dhariwal, P. Improved techniques for training consistency models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=WNzy9bRDvG
2024
-
[42]
Sun, C., Yuan, Z., Xu, K., Mai, L., Siddharth, N., Chen, S., and Marina, M. K. Learning high-frequency functions made easy with sinusoidal positional encoding. arXiv preprint arXiv:2407.09370, 2024
arXiv 2024
-
[43]
P., Mildenhall, B., Fridovich-Keil, S., Raghavan, N., Singhal, U., Ramamoorthi, R., Barron, J
Tancik, M., Srinivasan, P. P., Mildenhall, B., Fridovich-Keil, S., Raghavan, N., Singhal, U., Ramamoorthi, R., Barron, J. T., and Ng, R. Fourier features let networks learn high frequency functions in low dimensional domains. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS '20, Red Hook, NY, USA, 2020. Cu...
2020
-
[44]
W., Chen, Y.-R., Huang, Z., Calandra, R., Chen, R., Luo, S., and Su, H
Tao, S., Xiang, F., Shukla, A., Qin, Y., Hinrichsen, X., Yuan, X., Bao, C., Lin, X., Liu, Y., Chan, T.-K., Gao, Y., Li, X., Mu, T., Xiao, N., Gurha, A., N, V., Choi, Y. W., Chen, Y.-R., Huang, Z., Calandra, R., Chen, R., Luo, S., and Su, H. Maniskill3: GPU parallelized robot simulation and rendering for generalizable embodied AI . In 7th Robot Learning Wo...
2025
-
[45]
A connection between score matching and denoising autoencoders https://doi.org/10.1162/NECO_a_00142
Vincent, P. A connection between score matching and denoising autoencoders. Neural Computation, 23 0 (7): 0 1661--1674, 2011. doi:10.1162/NECO_a_00142
-
[46]
A tutorial on spectral clustering
Von Luxburg, U. A tutorial on spectral clustering. Statistics and computing, 17 0 (4): 0 395--416, 2007
2007
-
[47]
Wang, H., Wu, X., Huang, Z., and Xing, E. P. High-frequency component helps explain the generalization of convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 8684--8694, 2020
2020
-
[48]
Dust3r: Geometric 3d vision made easy
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., and Revaud, J. Dust3r: Geometric 3d vision made easy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 20697--20709, 2024
2024
-
[49]
Adapt3r: Adaptive 3d scene representation for domain transfer in imitation learning
Wilcox, A., Ghanem, M., Moghani, M., Barroso, P., Joffe, B., and Garg, A. Adapt3r: Adaptive 3d scene representation for domain transfer in imitation learning. CoRR, abs/2503.04877, March 2025. URL https://doi.org/10.48550/arXiv.2503.04877
-
[50]
Woo, S., Debnath, S., Hu, R., Chen, X., Liu, Z., Kweon, I. S., and Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. arXiv preprint arXiv:2301.00808, 2023
arXiv 2023
-
[51]
Diffusing states and matching scores: A new framework for imitation learning
Wu, R., Chen, Y., Swamy, G., Brantley, K., and Sun, W. Diffusing states and matching scores: A new framework for imitation learning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=kWRKNDU6uN
2025
-
[52]
u rth, T., Freymuth, N., Neumann, G., and K \
W \"u rth, T., Freymuth, N., Neumann, G., and K \"a rger, L. Diffusion-based hierarchical graph neural networks for simulating nonlinear solid mechanics. Advances in Neural Information Processing Systems, 39, 2026
2026
-
[53]
Point-bert: Pre-training 3d point cloud transformers with masked point modeling
Yu, X., Tang, L., Rao, Y., Huang, T., Zhou, J., and Lu, J. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 19313--19322, 2022
2022
-
[54]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Ze, Y., Zhang, G., Zhang, K., Hu, C., Wang, M., and Xu, H. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. In Proceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[55]
Ze, Y., Chen, Z., Wang, W., Chen, T., He, X., Yuan, Y., Peng, X. B., and Wu, J. Generalizable humanoid manipulation with 3d diffusion policies, 2025. URL https://arxiv.org/abs/2410.10803
arXiv 2025
-
[56]
and Perona, P
Zelnik-Manor, L. and Perona, P. Self-tuning spectral clustering. Advances in neural information processing systems, 17, 2004
2004
-
[57]
H., and Koltun, V
Zhao, H., Jiang, L., Jia, J., Torr, P. H., and Koltun, V. Point transformer. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 16259--16268, 2021
2021
-
[58]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Zhao, T. Z., Kumar, V., Levine, S., and Finn, C. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware . In Proceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi:10.15607/RSS.2023.XIX.016
-
[59]
Uni3d: Exploring unified 3d representation at scale
Zhou, J., Wang, J., Ma, B., Liu, Y.-S., Huang, T., and Wang, X. Uni3d: Exploring unified 3d representation at scale. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=wcaE4Dfgt8
2024
-
[60]
Point cloud matters: Rethinking the impact of different observation spaces on robot learning
Zhu, H., Wang, Y., Huang, D., Ye, W., Ouyang, W., and He, T. Point cloud matters: Rethinking the impact of different observation spaces on robot learning. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URL https://openreview.net/forum?id=zgSnSZ0Re6
2024
-
[61]
Scaling diffusion policy in transformer to 1 billion parameters for robotic manipulation
Zhu, M., Zhu, Y., Li, J., Wen, J., Xu, Z., Liu, N., Cheng, R., Shen, C., Peng, Y., Feng, F., et al. Scaling diffusion policy in transformer to 1 billion parameters for robotic manipulation. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pp.\ 10838--10845. IEEE, 2025
2025
-
[62]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pp.\ 2165--2183. PMLR, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.