How Seemingly Inconsequential Design Choices Dictate Performance of LLMs in Pathology
Pith reviewed 2026-06-27 09:36 UTC · model grok-4.3
The pith
Seemingly minor input choices raise general LLMs from 15% to 40% accuracy on pathology whole-slide tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
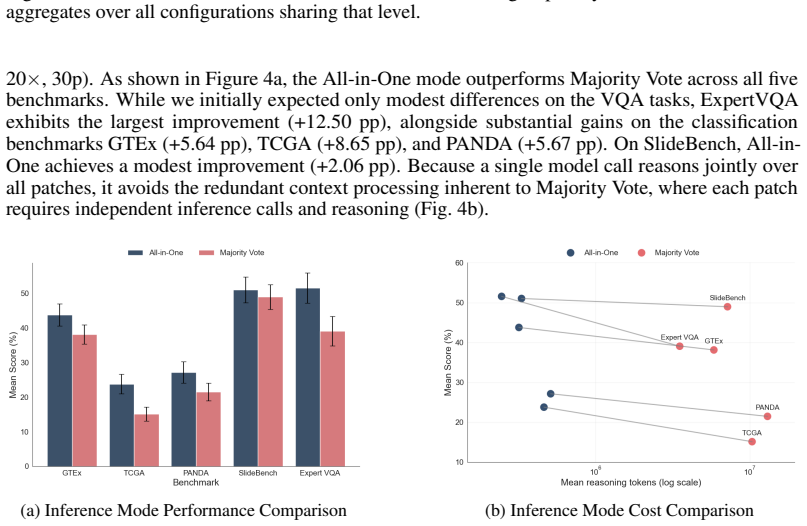
Prior studies have overstated the gap between specialized pathology models and general-purpose LLMs by using non-optimized input configurations; a single balanced configuration of large patches at lower magnification processed jointly raises GPT-5 from 15.1% to 39.5% on TCGA cancer-type classification and from 38.1% to 62.9% on GTEx organ classification, with per-task optimization yielding further gains and the configuration generalizing to other models and the held-out CPTAC cohort.
What carries the argument
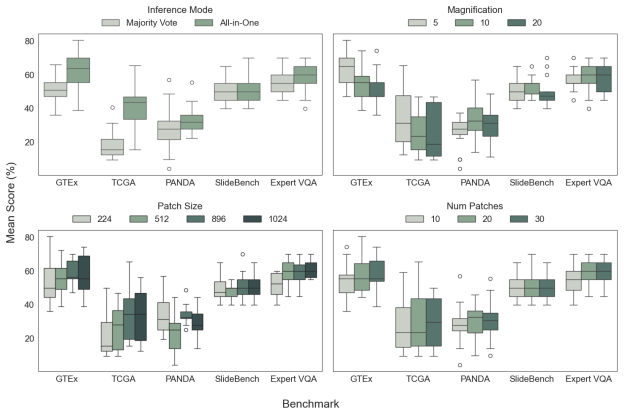
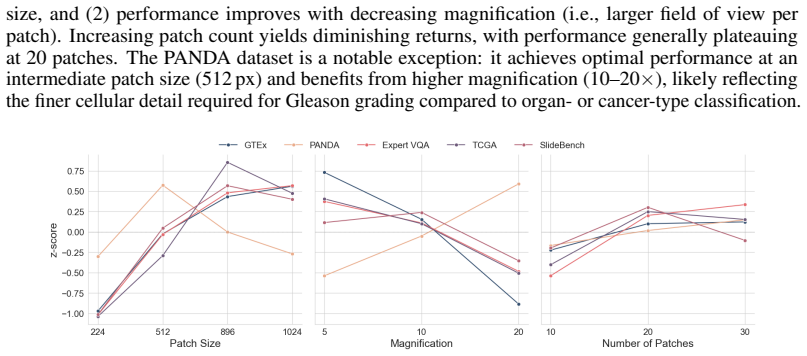
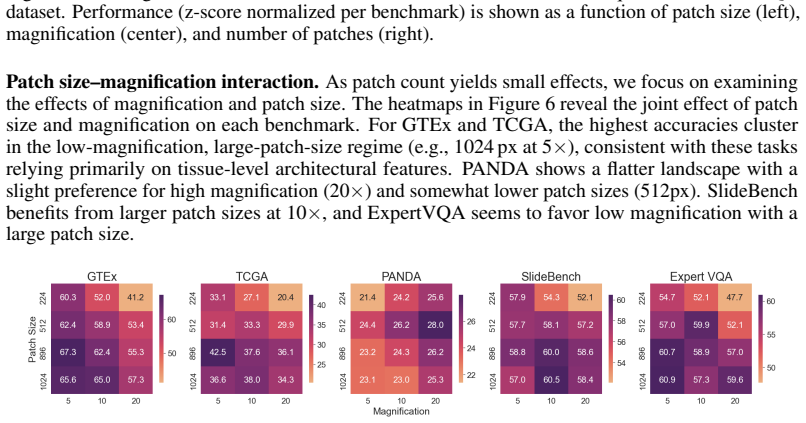
Factorial analysis of the four input design factors (inference mode, patch size, magnification, patch count) that control how whole-slide images are divided and fed to an LLM.
If this is right
- Comparisons between general LLMs and specialized pathology models have overstated the performance gap.
- A single non-tuned configuration improves results across multiple models and datasets.
- Per-task optimization of the four factors can produce still larger gains.
- The same input choices transfer to fully held-out cohorts without retraining.
Where Pith is reading between the lines
- Input optimization of this kind may narrow apparent gaps between general and specialized models on other high-resolution image domains.
- Benchmark papers should document and vary input configuration details when testing general models on large images.
- Future work could test whether additional factors such as color normalization or patch overlap produce further gains.
Load-bearing premise
The four tested input design factors and the MultiPathQA benchmark plus held-out cohorts sufficiently represent the variables and tasks that determine LLM performance on real-world pathology WSIs.
What would settle it
A new experiment on additional pathology tasks or models in which the balanced large-patch low-magnification joint configuration produces no accuracy gain or a loss would falsify the claim.
Figures


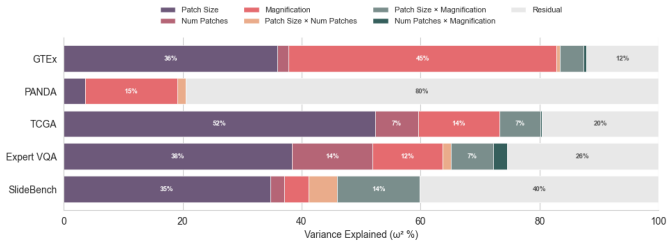




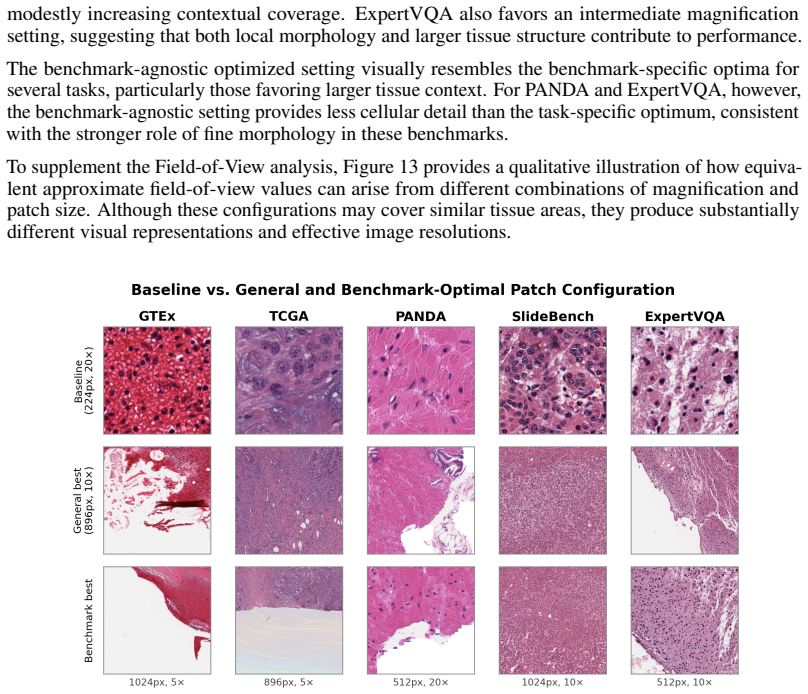

read the original abstract
General-purpose large language models (LLMs) are routinely used as baselines when evaluating specialized pathology models on whole-slide images (WSIs). Because WSIs exceed contemporary model context limits, LLM baselines routinely use small, high-magnification patches processed independently via majority voting, without systematic evaluation of seemingly inconsequential design choices such as patch size, patch count, and magnification. Generalist LLMs have consistently underperformed specialized systems, reinforcing the perception that domain-specific training or architectural adaptation is necessary for pathology tasks involving WSIs. Here, we conduct a systematic factorial analysis of four input design factors: inference mode, patch size, magnification, and patch count. We demonstrate that prior studies have overstated the gap between specialized models and general-purpose LLMs by choosing non-optimized input configurations. On the MultiPathQA benchmark, switching to a single balanced configuration (large patches at lower magnification, processed jointly) raises GPT-5 from 15.1% to 39.5% on cancer-type classification (TCGA) and from 38.1% to 62.9% on organ classification (GTEx). Per-task optimization yields further gains up to 43.9% (TCGA) and 71.6% (GTEx). The same configuration generalizes to two other models and to a fully held-out CPTAC cohort, where it improves Gemini 3 Flash by 23.4 percentage points without any task-specific tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that non-optimized input design choices (inference mode, patch size, magnification, patch count) in prior LLM evaluations on whole-slide pathology images have overstated the performance gap versus specialized models. Through a factorial analysis on the MultiPathQA benchmark, a single balanced configuration (large patches at lower magnification, joint processing) raises GPT-5 from 15.1% to 39.5% on TCGA cancer-type classification and 38.1% to 62.9% on GTEx organ classification; per-task optimization yields up to 43.9% and 71.6%. The configuration generalizes to other models and improves Gemini 3 Flash by 23.4 pp on the held-out CPTAC cohort without task-specific tuning.
Significance. If the results hold, the work shows that input configuration choices can close much of the reported gap between generalist LLMs and domain-specific pathology systems, with direct implications for benchmarking practices. Credit is due for the use of external held-out cohorts (CPTAC) and evaluation across multiple models without fitted parameters or self-referential derivations.
major comments (2)
- [Abstract and Results] Abstract and Results sections: the concrete percentage-point gains (15.1%→39.5%, 38.1%→62.9%, +23.4 pp) are reported without error bars, confidence intervals, or any statistical significance tests. This is load-bearing for the central claim that design choices dictate performance, as the improvements cannot be assessed for reliability versus experimental variance.
- [Methods] Methods (factorial analysis description): the systematic evaluation of the four factors does not report how variance across random seeds, multiple runs, or interaction effects was quantified, nor does it provide the full experimental protocol. This undermines confidence in the robustness of the recommended 'balanced configuration' and its generalization.
minor comments (1)
- [Introduction/Methods] Ensure the MultiPathQA benchmark, including task definitions and cohort details, is explicitly defined with references in the main text rather than assumed from the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical reporting and methodological transparency. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results sections: the concrete percentage-point gains (15.1%→39.5%, 38.1%→62.9%, +23.4 pp) are reported without error bars, confidence intervals, or any statistical significance tests. This is load-bearing for the central claim that design choices dictate performance, as the improvements cannot be assessed for reliability versus experimental variance.
Authors: We agree that error bars and significance tests would strengthen the presentation. The reported figures come from single deterministic runs per configuration (fixed temperature=0 where supported) due to the high cost of proprietary LLM API calls on thousands of WSI patches. The factorial design itself demonstrates robustness via consistent directional improvements across four factors, two tasks, three models, and a held-out cohort. We will add a limitations paragraph explicitly noting the single-run nature and the magnitude of gains relative to typical LLM variance, and we will compute and report binomial confidence intervals on the classification accuracies in the revised Results. revision: partial
-
Referee: [Methods] Methods (factorial analysis description): the systematic evaluation of the four factors does not report how variance across random seeds, multiple runs, or interaction effects was quantified, nor does it provide the full experimental protocol. This undermines confidence in the robustness of the recommended 'balanced configuration' and its generalization.
Authors: We will expand the Methods section with the complete experimental protocol (exact patch extraction code, API parameters, prompt templates, and decision rules for each factor combination). Because the study used a full 2^4 factorial design on fixed data splits and deterministic inference settings, interaction effects were not separately modeled; main-effect trends are reported. We will add an explicit statement that random-seed variance was not quantified owing to cost and determinism, while noting that the same balanced configuration improved performance on two additional models and the fully held-out CPTAC cohort without any re-tuning. revision: yes
Circularity Check
No circularity: empirical benchmark study with direct measurements on held-out data
full rationale
The paper conducts a factorial experiment on four input design factors (inference mode, patch size, magnification, patch count) and reports measured accuracy changes on MultiPathQA (TCGA/GTEx) plus a fully held-out CPTAC cohort. No equations, no fitted parameters renamed as predictions, no self-citation load-bearing uniqueness claims, and no ansatz or renaming of known results. All reported gains (e.g., 15.1% to 39.5%) are direct empirical outcomes from tested configurations, externally verifiable on the stated benchmarks without reduction to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Basit Alawode, Arif Mahmood, Muaz Khalifa Al-Radi, Shahad Albastaki, Asim Khan, Muham- mad Bilal, Moshira Ali Abdalla, Mohammed Bennamoun, and Sajid Javed. Mllm-hwsi: A multimodal large language model for hierarchical whole slide image understanding.arXiv preprint arXiv:2603.23067, 2026
-
[2]
Navigating Gigapixel Pathology Images with Large Multimodal Models
Thomas A Buckley, Kian R Weihrauch, Katherine Latham, Andrew Z Zhou, Padmini A Manrai, and Arjun K Manrai. Navigating gigapixel pathology images with large multimodal models. arXiv preprint arXiv:2511.19652, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Artificial intelligence for diagnosis and gleason grading of prostate cancer: the panda challenge.Nature medicine, 28(1):154–163, 2022
Wouter Bulten, Kimmo Kartasalo, Po-Hsuan Cameron Chen, Peter Ström, Hans Pinckaers, Kunal Nagpal, Yuannan Cai, David F Steiner, Hester Van Boven, Robert Vink, et al. Artificial intelligence for diagnosis and gleason grading of prostate cancer: the panda challenge.Nature medicine, 28(1):154–163, 2022
2022
-
[4]
A novel approach to high-quality postmortem tissue procurement: the gtex project.Biopreservation and biobanking, 13(5):311–319, 2015
Latarsha J Carithers, Kristin Ardlie, Mary Barcus, Philip A Branton, Angela Britton, Stephen A Buia, Carolyn C Compton, David S DeLuca, Joanne Peter-Demchok, Ellen T Gelfand, et al. A novel approach to high-quality postmortem tissue procurement: the gtex project.Biopreservation and biobanking, 13(5):311–319, 2015
2015
-
[5]
Jingyun Chen, Linghan Cai, Zhikang Wang, Yi Huang, Songhan Jiang, Shenjin Huang, Hongpeng Wang, and Yongbing Zhang. Pathagent: Toward interpretable analysis of whole- slide pathology images via large language model-based agentic reasoning.arXiv preprint arXiv:2511.17052, 2025
-
[6]
Scaling vision transformers to gigapixel images via hierarchical self-supervised learning
Richard J Chen, Chengkuan Chen, Yicong Li, Tiffany Y Chen, Andrew D Trister, Rahul G Krishnan, and Faisal Mahmood. Scaling vision transformers to gigapixel images via hierarchical self-supervised learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16144–16155, 2022
2022
-
[7]
Towards a general- purpose foundation model for computational pathology.Nature medicine, 30(3):850–862, 2024
Richard J Chen, Tong Ding, Ming Y Lu, Drew FK Williamson, Guillaume Jaume, Andrew H Song, Bowen Chen, Andrew Zhang, Daniel Shao, Muhammad Shaban, et al. Towards a general- purpose foundation model for computational pathology.Nature medicine, 30(3):850–862, 2024
2024
-
[8]
Slidechat: A large vision-language assistant for whole-slide pathology image understanding
Ying Chen, Guoan Wang, Yuanfeng Ji, Yanjun Li, Jin Ye, Tianbin Li, Ming Hu, Rongshan Yu, Yu Qiao, and Junjun He. Slidechat: A large vision-language assistant for whole-slide pathology image understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5134–5143, 2025
2025
-
[9]
A multimodal whole-slide foundation model for pathology.Nature medicine, pages 1–13, 2025
Tong Ding, Sophia J Wagner, Andrew H Song, Richard J Chen, Ming Y Lu, Andrew Zhang, Anurag J Vaidya, Guillaume Jaume, Muhammad Shaban, Ahrong Kim, et al. A multimodal whole-slide foundation model for pathology.Nature medicine, pages 1–13, 2025
2025
-
[10]
The cptac data portal: a resource for cancer proteomics research.Journal of proteome research, 14(6):2707–2713, 2015
Nathan J Edwards, Mauricio Oberti, Ratna R Thangudu, Shuang Cai, Peter B McGarvey, Shine Jacob, Subha Madhavan, and Karen A Ketchum. The cptac data portal: a resource for cancer proteomics research.Journal of proteome research, 14(6):2707–2713, 2015
2015
-
[11]
Pathfinder: A multi-modal multi-agent system for medical diagnostic decision-making applied to histopathol- ogy
Fatemeh Ghezloo, Mehmet Saygin Seyfioglu, Rustin Soraki, Wisdom O Ikezogwo, Beibin Li, Tejoram Vivekanandan, Joann G Elmore, Ranjay Krishna, and Linda Shapiro. Pathfinder: A multi-modal multi-agent system for medical diagnostic decision-making applied to histopathol- ogy. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 234...
2025
-
[12]
Attention-based deep multiple instance learning
Maximilian Ilse, Jakub Tomczak, and Max Welling. Attention-based deep multiple instance learning. InInternational conference on machine learning, pages 2127–2136. PMLR, 2018
2018
-
[13]
A co-evolving agentic ai system for medical imaging analysis.arXiv preprint arXiv:2509.20279, 2025
Songhao Li, Jonathan Xu, Tiancheng Bao, Yuxuan Liu, Yuchen Liu, Yihang Liu, Lilin Wang, Wenhui Lei, Sheng Wang, Yinuo Xu, et al. A co-evolving agentic ai system for medical imaging analysis.arXiv preprint arXiv:2509.20279, 2025. 10
-
[14]
Wsi-llava: A multimodal large language model for whole slide image
Yuci Liang, Xinheng Lyu, Wenting Chen, Meidan Ding, Jipeng Zhang, Xiangjian He, Song Wu, Xiaohan Xing, Sen Yang, Xiyue Wang, et al. Wsi-llava: A multimodal large language model for whole slide image. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22718–22727, 2025
2025
-
[15]
Data-efficient and weakly supervised computational pathology on whole-slide images.Nature biomedical engineering, 5(6):555–570, 2021
Ming Y Lu, Drew FK Williamson, Tiffany Y Chen, Richard J Chen, Matteo Barbieri, and Faisal Mahmood. Data-efficient and weakly supervised computational pathology on whole-slide images.Nature biomedical engineering, 5(6):555–570, 2021
2021
-
[16]
A visual-language foundation model for computational pathology.Nature medicine, 30(3):863–874, 2024
Ming Y Lu, Bowen Chen, Drew FK Williamson, Richard J Chen, Ivy Liang, Tong Ding, Guil- laume Jaume, Igor Odintsov, Long Phi Le, Georg Gerber, et al. A visual-language foundation model for computational pathology.Nature medicine, 30(3):863–874, 2024
2024
-
[17]
A multimodal generative ai copilot for human pathology.Nature, 634(8033):466–473, 2024
Ming Y Lu, Bowen Chen, Drew FK Williamson, Richard J Chen, Melissa Zhao, Aaron K Chow, Kenji Ikemura, Ahrong Kim, Dimitra Pouli, Ankush Patel, et al. A multimodal generative ai copilot for human pathology.Nature, 634(8033):466–473, 2024
2024
-
[18]
A new era of intelligence with gemini 3.Mountain View, CA: Google, 2025
Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu. A new era of intelligence with gemini 3.Mountain View, CA: Google, 2025
2025
-
[19]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5
2026
-
[20]
Andrew Sellergren, Chufan Gao, Fereshteh Mahvar, Timo Kohlberger, Fayaz Jamil, Madeleine Traverse, Alberto Tono, Bashir Sadjad, Lin Yang, Charles Lau, et al. Medgemma 1.5 technical report.arXiv preprint arXiv:2604.05081, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Quilt-llava: Visual instruction tuning by extracting localized narratives from open- source histopathology videos
Mehmet Saygin Seyfioglu, Wisdom O Ikezogwo, Fatemeh Ghezloo, Ranjay Krishna, and Linda Shapiro. Quilt-llava: Visual instruction tuning by extracting localized narratives from open- source histopathology videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13183–13192, 2024
2024
-
[22]
George Shaikovski, Adam Casson, Kristen Severson, Eric Zimmermann, Yi Kan Wang, Jeremy D Kunz, Juan A Retamero, Gerard Oakley, David Klimstra, Christopher Kanan, et al. Prism: A multi-modal generative foundation model for slide-level histopathology.arXiv preprint arXiv:2405.10254, 2024
-
[23]
Transmil: Transformer based correlated multiple instance learning for whole slide image classification
Zhuchen Shao, Hao Bian, Yang Chen, Yifeng Wang, Jian Zhang, Xiangyang Ji, et al. Transmil: Transformer based correlated multiple instance learning for whole slide image classification. Advances in neural information processing systems, 34:2136–2147, 2021
2021
-
[24]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Cpath-omni: A unified multimodal foundation model for patch and whole slide image analysis in computational pathology
Yuxuan Sun, Yixuan Si, Chenglu Zhu, Xuan Gong, Kai Zhang, Pingyi Chen, Ye Zhang, Zhongyi Shui, Tao Lin, and Lin Yang. Cpath-omni: A unified multimodal foundation model for patch and whole slide image analysis in computational pathology. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10360–10371, 2025
2025
-
[26]
Yuxuan Sun, Yixuan Si, Chenglu Zhu, Kai Zhang, Zhongyi Shui, Bowen Ding, Tao Lin, and Lin Yang. Cpathagent: An agent-based foundation model for interpretable high-resolution pathology image analysis mimicking pathologists’ diagnostic logic.Advances in Neural Information Processing Systems, 38:101673–101731, 2025
2025
-
[27]
Pathgen-1.6 m: 1.6 million pathology image-text pairs generation through multi-agent collaboration
Yuxuan Sun, Yunlong Zhang, Yixuan Si, Chenglu Zhu, Kai Zhang, Zhongyi Shui, Jingxiong Li, Xuan Gong, Xinheng Lyu, Tao Lin, et al. Pathgen-1.6 m: 1.6 million pathology image-text pairs generation through multi-agent collaboration. InInternational Conference on Learning Representations, volume 2025, pages 94611–94653, 2025
2025
-
[28]
A foundation model for clinical-grade computational pathology and rare cancers detection.Nature medicine, 30(10):2924–2935, 2024
Eugene V orontsov, Alican Bozkurt, Adam Casson, George Shaikovski, Michal Zelechowski, Kristen Severson, Eric Zimmermann, James Hall, Neil Tenenholtz, Nicolo Fusi, et al. A foundation model for clinical-grade computational pathology and rare cancers detection.Nature medicine, 30(10):2924–2935, 2024. 11
2024
-
[29]
Sheng Wang, Ruiming Wu, Charles Herndon, Yihang Liu, Shunsuke Koga, Jeanne Shen, and Zhi Huang. Pathology-cot: Learning visual chain-of-thought agent from expert whole slide image diagnosis behavior.arXiv preprint arXiv:2510.04587, 2025
-
[30]
A pathology foundation model for cancer diagnosis and prognosis prediction.Nature, 634(8035):970–978, 2024
Xiyue Wang, Junhan Zhao, Eliana Marostica, Wei Yuan, Jietian Jin, Jiayu Zhang, Ruijiang Li, Hongping Tang, Kanran Wang, Yu Li, et al. A pathology foundation model for cancer diagnosis and prognosis prediction.Nature, 634(8035):970–978, 2024
2024
-
[31]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
The cancer genome atlas pan-cancer analysis project.Nature genetics, 45(10):1113–1120, 2013
John N Weinstein, Eric A Collisson, Gordon B Mills, Kenna R Shaw, Brad A Ozenberger, Kyle Ellrott, Ilya Shmulevich, Chris Sander, and Joshua M Stuart. The cancer genome atlas pan-cancer analysis project.Nature genetics, 45(10):1113–1120, 2013
2013
-
[33]
Luca L Weishaupt, Chengkuan Chen, Drew FK Williamson, Richard J Chen, Guillaume Jaume, Tong Ding, Bowen Chen, Anurag Vaidya, Long Phi Le, Ming Y Lu, et al. Evidence- based diagnostic reasoning with multi-agent copilot for human pathology.arXiv preprint arXiv:2506.20964, 2025
-
[34]
A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, Cliff Wong, Zelalem Gero, Javier González, Yu Gu, et al. A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):181–188, 2024
2024
-
[35]
Andrew Zhang, Guillaume Jaume, Anurag Vaidya, Tong Ding, and Faisal Mahmood. Ac- celerating data processing and benchmarking of ai models for pathology.arXiv preprint arXiv:2502.06750, 2025
-
[36]
isup_grade
Wenchuan Zhang, Penghao Zhang, Jingru Guo, Tao Cheng, Jie Chen, Shuwan Zhang, Zhang Zhang, Yuhao Yi, and Hong Bu. Patho-r1: A multimodal reinforcement learning-based pathol- ogy expert reasoner. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 28418–28426, 2026. 12 Appendix A Implementation and evaluation details A.1 Patch...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.