Influence Factors on RAG Poisoning
Pith reviewed 2026-06-27 12:22 UTC · model grok-4.3
The pith
Retriever architecture, dataset, and retrieval depth most strongly determine RAG poisoning exposure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
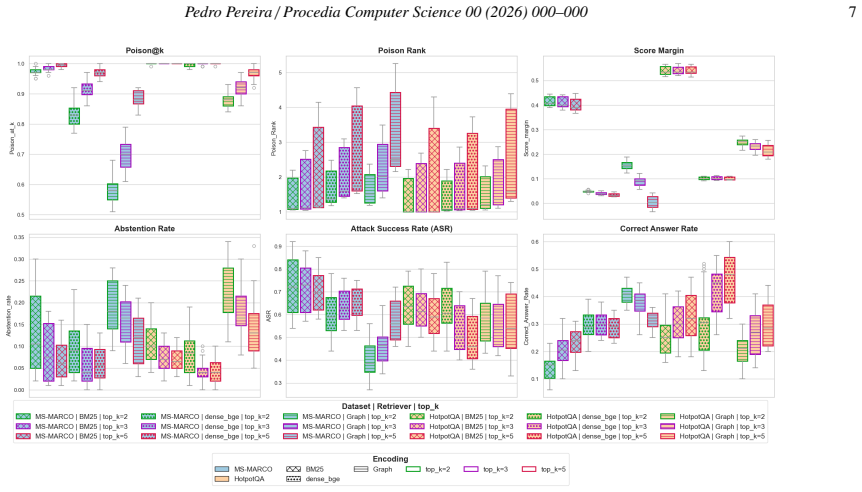
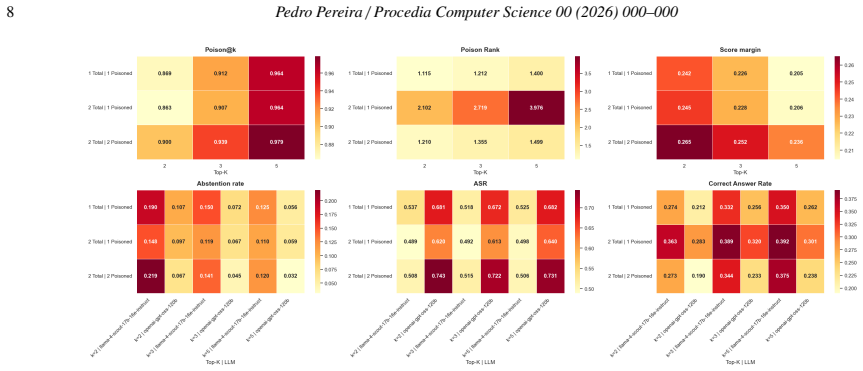
Retriever architecture, dataset, and retrieval depth are the strongest factors affecting poisoning exposure, while generator choice and database composition have a major impact on downstream attack success. Dense and graph-based retrievers generally improve robustness relative to BM25, whereas larger retrieval depth increases the likelihood of retrieving poisoned passages. Replicating poisoned content across multiple databases amplifies adversarial influence, while additional clean sources can mitigate it.
What carries the argument
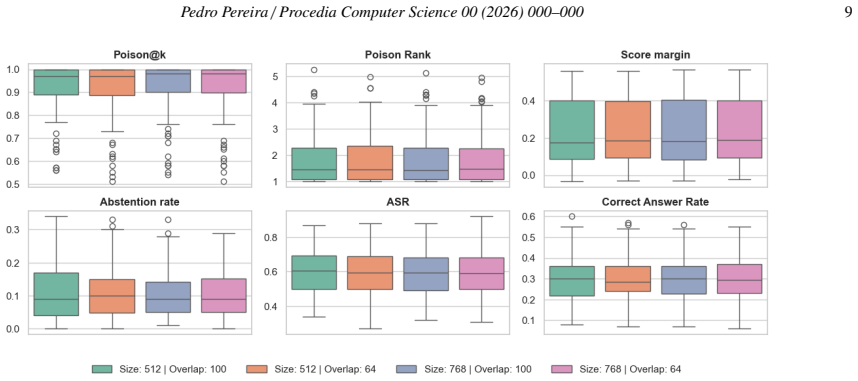
Full factorial sweep of 432 RAG configurations that records separate retrieval-level and generation-level success rates under controlled poisoning.
If this is right
- Dense and graph-based retrievers reduce the chance that poisoned passages are retrieved compared with BM25.
- Raising retrieval depth raises the probability that poisoned passages reach the generator.
- Duplicating poisoned documents across several databases increases the attack's effect on generated answers.
- Adding clean documents to the knowledge base can offset the influence of poisoned ones.
- Choice of generator model changes how much retrieved poisoned content alters the final output.
Where Pith is reading between the lines
- RAG builders can lower poisoning risk most effectively by first changing the retriever or reducing retrieval depth rather than swapping the generator alone.
- The same factor ranking may shift when the test queries come from real users instead of the synthetic prompts used here.
- Mitigation strategies that combine multiple clean sources with depth limits are likely to outperform single-component fixes.
Load-bearing premise
The chosen retrieval and generation success metrics plus the 432 synthetic configurations stand in for the behavior of practical poisoning attacks and real-world RAG deployments.
What would settle it
Repeating the factor ranking on a live production RAG system that uses organic user queries and different success definitions produces a materially different ordering of influence strengths.
Figures
read the original abstract
Retrieval-Augmented Generation (RAG) systems enhance large language models by grounding responses in retrieved documents from external knowledge sources at inference time. However, this reliance on retrieved content introduces vulnerabilities to poisoning attacks, in which adversarial documents can manipulate both the retrieval process and the generated outputs. This paper investigates poisoning robustness in RAG through a full factorial experimental study covering 432 configurations. We analyze the impacts of dataset, retriever type, retrieval depth, database composition, chunking strategy, and generator model on retrieval-level and generation-level metrics. The results show that retriever architecture, dataset, and retrieval depth are the strongest factors affecting poisoning exposure, while generator choice and database composition have a major impact on downstream attack success. Dense and graph-based retrievers generally improve robustness relative to BM25, whereas larger retrieval depth increases the likelihood of retrieving poisoned passages. We further show that replicating poisoned content across multiple databases amplifies adversarial influence, while additional clean sources can mitigate it. These findings highlight that poisoning vulnerability in RAG is not attributable to a single component, but instead arises from the interaction of retrieval, generation, and knowledge-base configuration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a full-factorial experimental study of 432 RAG configurations shows retriever architecture, dataset, and retrieval depth as the strongest factors affecting poisoning exposure, while generator choice and database composition have major impact on attack success. Dense and graph-based retrievers are more robust than BM25; larger retrieval depth increases poisoned passage retrieval; replicating poisoned content amplifies influence while additional clean sources mitigate it. The study analyzes impacts of dataset, retriever type, retrieval depth, database composition, chunking strategy, and generator model on retrieval-level and generation-level metrics.
Significance. If the chosen metrics, poisoning document construction, and 432 synthetic configurations prove representative, the full-factorial design would be a strength, providing empirical evidence that RAG poisoning vulnerability arises from interactions across components rather than any single one. This could guide practical defenses by prioritizing retriever selection and depth limits over other factors.
major comments (2)
- [Abstract] Abstract: The central claims on factor ranking (retriever architecture, dataset, and retrieval depth as strongest for exposure; generator and database composition for success) rest on the experimental results, yet the abstract supplies no quantitative values, effect sizes, error bars, statistical tests, or definitions of the retrieval-level and generation-level success metrics (e.g., exact match vs. embedding similarity vs. top-k hit rate). This prevents assessment of whether the 432 configurations support the reported ordering.
- [Abstract] Abstract: The representativeness assumption for the synthetic configurations, poisoned document construction method, and chosen metrics is load-bearing for generalizing the factor rankings to practical RAG poisoning attacks; without details on whether configurations include realistic partial attacker control over the knowledge base or real-world constraints, the claim that these factors are strongest does not necessarily follow.
minor comments (1)
- [Abstract] The abstract mentions 'retrieval-level and generation-level metrics' without defining them or referencing where exact formulas appear in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract would benefit from additional quantitative support and scope clarifications to better substantiate the factor rankings. We address each comment below and will revise the abstract accordingly in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims on factor ranking (retriever architecture, dataset, and retrieval depth as strongest for exposure; generator and database composition for success) rest on the experimental results, yet the abstract supplies no quantitative values, effect sizes, error bars, statistical tests, or definitions of the retrieval-level and generation-level success metrics (e.g., exact match vs. embedding similarity vs. top-k hit rate). This prevents assessment of whether the 432 configurations support the reported ordering.
Authors: We agree that the abstract should provide readers with direct quantitative grounding for the reported factor ordering. In the revision we will add concise references to key results from the full-factorial analysis (e.g., relative effect magnitudes or significance levels obtained across the 432 configurations) together with brief definitions of the retrieval-level metric (poisoned passage hit rate within top-k) and generation-level metric (attack success measured by exact match on the target output). revision: yes
-
Referee: [Abstract] Abstract: The representativeness assumption for the synthetic configurations, poisoned document construction method, and chosen metrics is load-bearing for generalizing the factor rankings to practical RAG poisoning attacks; without details on whether configurations include realistic partial attacker control over the knowledge base or real-world constraints, the claim that these factors are strongest does not necessarily follow.
Authors: The study deliberately employs a controlled full-factorial design over synthetic configurations to isolate and rank component influences; this is explicitly the scope of the work. We will revise the abstract to state that the configurations assume an attacker can insert poisoned passages into the knowledge base and to note that the reported rankings apply within this experimental regime rather than claiming direct extrapolation to every partial-control real-world scenario. revision: yes
Circularity Check
Purely empirical full-factorial study; no derivations or self-referential predictions
full rationale
The paper reports results from a full factorial experiment across 432 configurations measuring impacts of dataset, retriever type, retrieval depth, database composition, chunking strategy, and generator model on retrieval-level and generation-level metrics. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citations appear in the provided text. Central claims (e.g., retriever architecture, dataset, and retrieval depth as strongest factors) are direct experimental outcomes rather than reductions to inputs by construction. This is self-contained empirical analysis with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Disabling Self-Correction in Retrieval-Augmented Generation via Stealthy Retriever Poisoning
Dai, Y ., Ji, Z., Li, Z., Li, K., Wang, S., 2025. Disabling Self-Correction in Retrieval-Augmented Generation via Stealthy Retriever Poisoning. arXiv e-prints , arXiv:2508.20083doi:10.48550/arXiv.2508.20083,arXiv:2508.20083
-
[3]
Disabling self-correction in retrieval-augmented generation via stealthy retriever poisoning
Dai, Y ., Ji, Z., Li, Z., Li, K., Wang, S., 2025. Disabling self-correction in retrieval-augmented generation via stealthy retriever poisoning. URL: https://arxiv.org/abs/2508.20083,arXiv:2508.20083
arXiv 2025
-
[4]
Defending against knowledge poisoning attacks during retrieval-augmented generation
Edemacu, K., Shashidhar, V .M., Tuape, M., Abudu, D., Jang, B., Kim, J.W., 2026. Defending against knowledge poisoning attacks during retrieval-augmented generation. URL:https://arxiv.org/abs/2508.02835,arXiv:2508.02835
arXiv 2026
-
[5]
Fan, W., Ding, Y ., Ning, L., Wang, S., Li, H., Yin, D., Chua, T.S., Li, Q., 2024. A survey on rag meeting llms: Towards retrieval-augmented large language models, in: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Association for Computing Machinery, New York, NY , USA. p. 6491–6501. doi:10.1145/3637528.3671470
-
[6]
Retrieval-Augmented Generation for Large Language Models: A Survey
Gao, Y ., Xiong, Y ., Gao, X., Jia, K., Pan, J., Bi, Y ., Dai, Y ., Sun, J., Guo, Q., Wang, M., Wang, H., 2023. Retrieval-augmented generation for large language models: A survey. CoRR abs/2312.10997. URL:https://doi.org/10.48550/arXiv.2312.10997, doi:10.48550/ ARXIV.2312.10997,arXiv:2312.10997
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.10997 2023
-
[7]
InFindings of the Conference on Empirical Methods in Natural Language Processing (EMNLP)
Karpukhin, V ., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., Yih, W.t., 2020. Dense passage retrieval for open-domain question answering, in: Webber, B., Cohn, T., He, Y ., Liu, Y . (Eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Online. pp. 6...
-
[8]
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V ., Goyal, N., K ¨uttler, H., Lewis, M., Yih, W.t., Rockt ¨aschel, T., Riedel, S., Kiela, D., 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks, in: Proceedings of the 34th International Conference on Neural Information Processing Systems, Curran Associates Inc., Red Hook, NY , USA
2020
-
[9]
Retrieval-augmented generation for educational application: A systematic survey
Li, Z., Wang, Z., Wang, W., Hung, K., Xie, H., Wang, F.L., 2025. Retrieval-augmented generation for educational application: A systematic survey. Computers and Education: Artificial Intelligence 8, 100417. doi:https://doi.org/10.1016/j.caeai.2025.100417
-
[10]
SafeRAG: Benchmarking security in retrieval-augmented generation of large language model, in: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Liang, X., Niu, S., Li, Z., Zhang, S., Wang, H., Xiong, F., Fan, Z., Tang, B., Zhao, J., Yang, J., Song, S., Wang, M., 2025. SafeRAG: Benchmarking security in retrieval-augmented generation of large language model, in: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (Eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Ling...
2025
-
[11]
Mo, Y ., Tang, M., Lin, R., Zhou, B., Li, X., 2025. Broken bags: Disrupting service through the contamination of large language models with misinformation. IEEE Access 13, 109607–109623. doi:10.1109/ACCESS.2025.3582519
-
[12]
LLM statistics 2025: Adoption, trends, and market insights
Muhammad, A., 2025. LLM statistics 2025: Adoption, trends, and market insights. Technical Report. Hostinger. URL:https://www. hostinger.com/tutorials/llm-statistics
2025
-
[13]
Nguyen, T., Rosenberg, M., Song, X., Gao, J., Tiwary, S., Majumder, R., Deng, L., 2016. Ms marco: A human gen- erated machine reading comprehension dataset URL:https://www.microsoft.com/en-us/research/publication/ ms-marco-human-generated-machine-reading-comprehension-dataset/
2016
-
[14]
A survey of large language mod- els: Evolution, architectures, adaptation, benchmarking, applications, challenges, and societal implications
Sajjadi Mohammadabadi, S.M., Kara, B.C., Eyupoglu, C., Uzay, C., Tosun, M.S., Karakus ¸, O., 2025. A survey of large language mod- els: Evolution, architectures, adaptation, benchmarking, applications, challenges, and societal implications. Electronics 14. doi:10.3390/ electronics14183580
2025
-
[15]
doi: 10.18653/v1/ 2024.findings-acl.348
Shi, W., Min, S., Yasunaga, M., Seo, M., James, R., Lewis, M., Zettlemoyer, L., Yih, W.t., 2024. REPLUG: Retrieval-augmented black- box language models, in: Duh, K., Gomez, H., Bethard, S. (Eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long ...
-
[16]
Glue pizza and eat rocks - exploiting vulnerabilities in retrieval-augmented generative models, in: Al-Onaizan, Y ., Bansal, M., Chen, Y .N
Tan, Z., Zhao, C., Moraffah, R., Li, Y ., Wang, S., Li, J., Chen, T., Liu, H., 2024. Glue pizza and eat rocks - exploiting vulnerabilities in retrieval-augmented generative models, in: Al-Onaizan, Y ., Bansal, M., Chen, Y .N. (Eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Association for Computational Lingu...
2024
-
[17]
Wang, D., Zhang, S., 2024. Large language models in medical and healthcare fields: applications, advances, and challenges. Artificial Intelligence Review 57, 299. URL:https://doi.org/10.1007/s10462-024-10921-0, doi:10.1007/s10462-024-10921-0
-
[18]
In: Proceedings of the 2018 Conference on Empirical Methods in Natu- ral Language Processing
Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W., Salakhutdinov, R., Manning, C.D., 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering, in: Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J. (Eds.), Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguis...
-
[19]
Practical poisoning attacks against retrieval-augmented generation
Zhang, B., Chen, Y ., Liu, Z., Nie, L., Li, T., Liu, Z., Fang, M., 2026. Practical poisoning attacks against retrieval-augmented generation. URL: https://arxiv.org/abs/2504.03957,arXiv:2504.03957
arXiv 2026
-
[20]
Exploring knowledge poisoning attacks to retrieval-augmented generation
Zhao, T., Chen, J., Ru, Y ., Zhu, H., Hu, N., Liu, J., Lin, Q., 2026. Exploring knowledge poisoning attacks to retrieval-augmented generation. Information Fusion 127, 103900. doi:https://doi.org/10.1016/j.inffus.2025.103900
-
[21]
Zou, W., Geng, R., Wang, B., Jia, J., 2025. Poisonedrag: knowledge corruption attacks to retrieval-augmented generation of large language models, in: Proceedings of the 34th USENIX Conference on Security Symposium, USENIX Association, USA
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.