ReCal: Reward Calibration for RL-based LLM Routing
Pith reviewed 2026-06-27 10:13 UTC · model grok-4.3
The pith
ReCal uses hierarchical reward decomposition and variance-aware reweighting to fix ambiguous and biased signals in RL-based LLM routing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
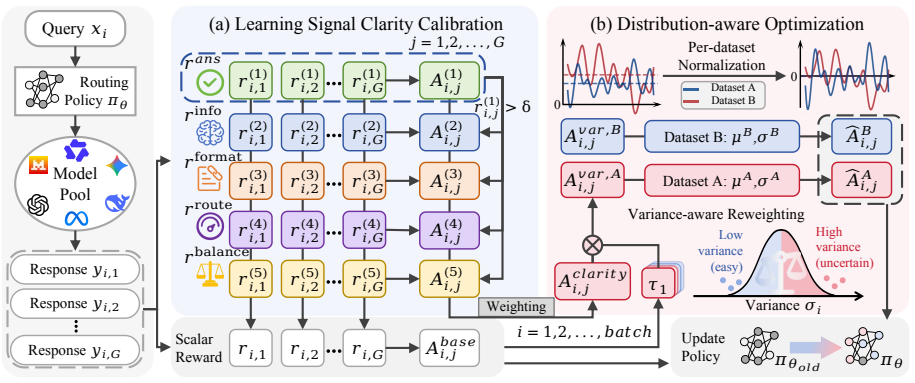
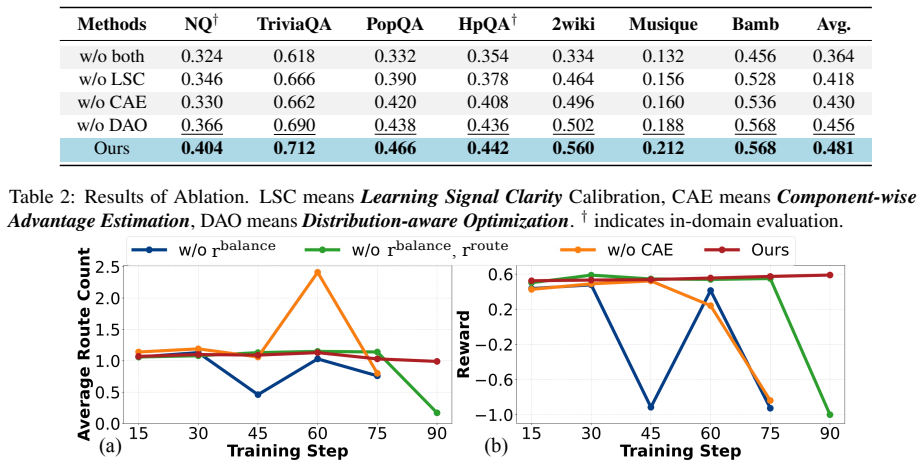
ReCal addresses the core problems of ambiguous credit assignment from scalar rewards and optimization bias from variable reward magnitudes by introducing hierarchical reward decomposition with component-wise advantage estimation, then applying a distribution-aware strategy of variance-aware reweighting plus per-dataset normalization; experiments on seven datasets show this yields consistently higher routing performance and greater training stability than prior RL routing methods.
What carries the argument
Hierarchical reward decomposition with component-wise advantage estimation, paired with variance-aware reweighting and per-dataset normalization.
If this is right
- Routing policies learn to handle correctness and format objectives without one dominating the other.
- Training curves exhibit lower variance because high-variability instances no longer dominate gradient updates.
- The same router can be applied across datasets of differing difficulty without manual reward rescaling.
Where Pith is reading between the lines
- The same decomposition-plus-reweighting pattern could be applied to other multi-objective RL settings such as tool-use agents.
- If component advantages remain stable across model sizes, the method might reduce the cost of retraining routers when new LLMs are added.
- Per-dataset normalization raises the question of how to handle streaming or continual addition of new task distributions without periodic re-normalization.
Load-bearing premise
That breaking rewards into components for separate advantages and then reweighting by variance plus normalizing per dataset will yield cleaner signals without creating new biases or instabilities on mixed tasks.
What would settle it
A controlled run on one of the seven datasets where the ReCal router shows no improvement or worse final accuracy and higher variance in training curves than the strongest baseline after identical numbers of episodes.
Figures


read the original abstract
Large language model (LLM) routing has emerged as an effective paradigm for leveraging the complementary strengths of multiple LLMs through dynamic model and reasoning-strategy selection. Recent reinforcement learning (RL)-based routing methods further improve routing quality by optimizing routing policies from interaction feedback. However, they still struggle to provide informative and comparable learning signals under heterogeneous tasks with varying difficulty. In practice, multiple objectives (e.g., correctness, format behavior) are aggregated into a single scalar reward, leading to ambiguous credit assignment and conflicting optimization signals. Moreover, reward signals exhibit significant variability across instances, where some instances produce higher or more variable rewards, introducing optimization bias that favors trivial samples over informative ones. To address these issues, we propose \textbf{ReCal}, a \textbf{\underline{Re}}ward \textbf{\underline{Cal}}ibration framework for RL-based LLM routing. We first introduce a hierarchical reward decomposition mechanism with component-wise advantage estimation. We further propose a distribution-aware optimization strategy that calibrates optimization variability through variance-aware reweighting and per-dataset normalization. Experiments on seven datasets demonstrate that ReCal consistently improves routing performance, and training stability over baselines. Code is available at https://anonymous.4open.science/r/ReCal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReCal, a reward calibration framework for RL-based LLM routing. It addresses ambiguous credit assignment from aggregated scalar rewards and optimization bias from variable reward signals across heterogeneous tasks by introducing hierarchical reward decomposition with component-wise advantage estimation, plus a distribution-aware strategy using variance-aware reweighting and per-dataset normalization. Experiments on seven datasets are claimed to show consistent gains in routing performance and training stability over baselines, with code released.
Significance. If the empirical claims hold with proper controls, the framework could improve credit assignment and reduce bias in RL for LLM routing, a growing area where multiple objectives and task heterogeneity are common. The explicit mechanisms for decomposition and variance calibration are a strength, as is the public code link.
major comments (1)
- [Abstract] Abstract: the central empirical claim ('Experiments on seven datasets demonstrate that ReCal consistently improves routing performance and training stability over baselines') supplies no details on the seven datasets, baselines, metrics, statistical tests, ablation studies, or variance across runs; without these the support for the claim cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the review and the opportunity to respond. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim ('Experiments on seven datasets demonstrate that ReCal consistently improves routing performance and training stability over baselines') supplies no details on the seven datasets, baselines, metrics, statistical tests, ablation studies, or variance across runs; without these the support for the claim cannot be evaluated.
Authors: We agree the abstract is high-level and omits specifics. The seven datasets, baselines, metrics, ablation studies, and per-run variance (reported as mean ± std) are fully detailed in Section 4, with consistent gains shown across all tasks and reduced training variance. We will revise the abstract to include a concise reference to the evaluation protocol and stability metrics. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces ReCal via explicit new mechanisms (hierarchical reward decomposition with component-wise advantage estimation, variance-aware reweighting, and per-dataset normalization) to address credit assignment and optimization bias in RL routing. These components are defined and motivated directly from the problem statement rather than by fitting parameters to data and relabeling the fit as a prediction. No equations, uniqueness theorems, or ansatzes are shown to reduce to self-citations or prior author work by construction. The central empirical claim rests on experiments across seven datasets, which constitute independent validation outside any internal re-expression of inputs. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yoshua Bengio, J\' e r\^ o me Louradour, Ronan Collobert, and Jason Weston. 2009. https://doi.org/10.1145/1553374.1553380 Curriculum learning . In Proceedings of the 26th Annual International Conference on Machine Learning, ICML '09, page 41–48, New York, NY, USA. Association for Computing Machinery
-
[2]
Lei Chen and W.B. Heinzelman. 2005. https://doi.org/10.1109/JSAC.2004.842560 Qos-aware routing based on bandwidth estimation for mobile ad hoc networks . IEEE Journal on Selected Areas in Communications, 23(3):561--572
-
[3]
Kwok, and Yu Zhang
Shuhao Chen, Weisen Jiang, Baijiong Lin, James T. Kwok, and Yu Zhang. 2024. Routerdc: query-based router by dual contrastive learning for assembling large language models. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS '24, Red Hook, NY, USA. Curran Associates Inc
2024
-
[4]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, and 181 others. 2025. https://arxiv.org/abs/2412.19437 Deepseek-v3 technical report . Preprint, arXiv:2412.19437
Pith/arXiv arXiv 2025
-
[5]
Tao Feng, Yanzhen Shen, and Jiaxuan You. 2024. https://arxiv.org/abs/2410.03834 Graphrouter: A graph-based router for llm selections . In The Thirteenth International Conference on Learning Representations
arXiv 2024
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
Pith/arXiv arXiv 2024
-
[7]
URL https: //doi.org/10.1007/s10458-022-09552-y
Conor F. Hayes, Roxana R a dulescu, Eugenio Bargiacchi, Johan K\" a llstr\" o m, Matthew Macfarlane, Mathieu Reymond, Timothy Verstraeten, Luisa M. Zintgraf, Richard Dazeley, Fredrik Heintz, Enda Howley, Athirai A. Irissappane, Patrick Mannion, Ann Now\' e , Gabriel Ramos, Marcello Restelli, Peter Vamplew, and Diederik M. Roijers. 2022. https://doi.org/10...
-
[8]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. https://doi.org/10.18653/v1/2020.coling-main.580 Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps . In Proceedings of the 28th International Conference on Computational Linguistics, pages 6609--6625, Barcelona, Spain (Online). International Committee ...
-
[9]
Qitian Jason Hu, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. 2024. https://arxiv.org/abs/2403.12031 Routerbench: A benchmark for multi-llm routing system . Preprint, arXiv:2403.12031
Pith/arXiv arXiv 2024
-
[10]
Changxin Huang, Guangrun Wang, Zhibo Zhou, Ronghui Zhang, and Liang Lin. 2021. https://arxiv.org/abs/2107.01908 Reward-adaptive reinforcement learning: Dynamic policy gradient optimization for bipedal locomotion . Preprint, arXiv:2107.01908
arXiv 2021
-
[11]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, and 7 others. 2024. ht...
Pith/arXiv arXiv 2024
-
[12]
Fengqing Jiang, Zhangchen Xu, Luyao Niu, Boxin Wang, Jinyuan Jia, Bo Li, and Radha Poovendran. 2023. https://arxiv.org/abs/2311.16153 Identifying and mitigating vulnerabilities in llm-integrated applications . Preprint, arXiv:2311.16153
arXiv 2023
-
[13]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. https://arxiv.org/abs/2503.09516 Search-r1: Training llms to reason and leverage search engines with reinforcement learning . Preprint, arXiv:2503.09516
Pith/arXiv arXiv 2025
-
[14]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. https://doi.org/10.18653/v1/P17-1147 T rivia QA : A large scale distantly supervised challenge dataset for reading comprehension . In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601--1611, Vancouver, Canada. Assoc...
-
[15]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.550 Dense passage retrieval for open-domain question answering . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769--6781, Online. Ass...
-
[16]
Alex Kendall, Yarin Gal, and Roberto Cipolla. 2018. https://arxiv.org/abs/1705.07115 Multi-task learning using uncertainty to weigh losses for scene geometry and semantics . Preprint, arXiv:1705.07115
Pith/arXiv arXiv 2018
-
[17]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. https://doi.org/10.1162/tacl_a_00276 Natural questions: A benchma...
-
[18]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. https://doi.org/10.18653/v1/2023.acl-long.546 When not to trust language models: Investigating effectiveness of parametric and non-parametric memories . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: L...
-
[19]
Patrick Mannion, Sam Devlin, Karl Mason, Jim Duggan, and Enda Howley. 2017. https://doi.org/10.1016/j.neucom.2017.05.090 Policy invariance under reward transformations for multi-objective reinforcement learning . Neurocomputing, 263:60--73. Multiobjective Reinforcement Learning: Theory and Applications
-
[20]
Ng, Daishi Harada, and Stuart J
Andrew Y. Ng, Daishi Harada, and Stuart J. Russell. 1999. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the Sixteenth International Conference on Machine Learning, ICML '99, page 278–287, San Francisco, CA, USA. Morgan Kaufmann Publishers Inc
1999
-
[21]
Gonzalez, M Waleed Kadous, and Ion Stoica
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. 2025. https://arxiv.org/abs/2406.18665 Routellm: Learning to route llms with preference data . Preprint, arXiv:2406.18665
Pith/arXiv arXiv 2025
-
[22]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. https://arxiv.org/abs/2203.02155 Training language models to f...
Pith/arXiv arXiv 2022
-
[23]
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah Smith, and Mike Lewis. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.378 Measuring and narrowing the compositionality gap in language models . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 5687--5711, Singapore. Association for Computational Linguistics
-
[24]
Cheng Qian, Zuxin Liu, Shirley Kokane, Akshara Prabhakar, Jielin Qiu, Haolin Chen, Zhiwei Liu, Heng Ji, Weiran Yao, Shelby Heinecke, Silvio Savarese, Caiming Xiong, and Huan Wang. 2025. https://arxiv.org/abs/2510.08439 xrouter: Training cost-aware llms orchestration system via reinforcement learning . Preprint, arXiv:2510.08439
arXiv 2025
-
[25]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, and 25 others. 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . Preprint, arXiv:2412.15115
Pith/arXiv arXiv 2025
-
[26]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2024. https://arxiv.org/abs/2305.18290 Direct preference optimization: Your language model is secretly a reward model . Preprint, arXiv:2305.18290
Pith/arXiv arXiv 2024
-
[27]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. https://arxiv.org/abs/1707.06347 Proximal policy optimization algorithms . Preprint, arXiv:1707.06347
Pith/arXiv arXiv 2017
-
[28]
Dimitrios Sikeridis, Dennis Ramdass, and Pranay Pareek. 2025. https://arxiv.org/abs/2412.12170 Pickllm: Context-aware rl-assisted large language model routing . In International Workshop on AI for Transportation, pages 227--239. Springer
arXiv 2025
-
[29]
David Silver, Satinder Singh, Doina Precup, and Richard S. Sutton. 2021. https://doi.org/10.1016/j.artint.2021.103535 Reward is enough . Artificial Intelligence, 299:103535
-
[30]
Adith Swaminathan and Thorsten Joachims. 2015. https://proceedings.mlr.press/v37/swaminathan15.html Counterfactual risk minimization: Learning from logged bandit feedback . In Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pages 814--823, Lille, France. PMLR
2015
-
[31]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, and 179 others. 2024. https://arxiv.org/abs/2408.00118 Gemma 2: ...
Pith/arXiv arXiv 2024
-
[32]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. https://doi.org/10.1162/tacl_a_00475 M u S i Q ue: Multihop questions via single-hop question composition . Transactions of the Association for Computational Linguistics, 10:539--554
-
[33]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2024. https://arxiv.org/abs/2212.03533 Text embeddings by weakly-supervised contrastive pre-training . Preprint, arXiv:2212.03533
Pith/arXiv arXiv 2024
-
[34]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS '22, Red Hook, NY, USA. Curran Associates Inc
2022
-
[35]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. https://doi.org/10.18653/v1/D18-1259 H otpot QA : A dataset for diverse, explainable multi-hop question answering . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369--2380, Brussels...
-
[36]
Rui Yu, Shenghua Wan, Yucen Wang, Chen-Xiao Gao, Le Gan, Zongzhang Zhang, and De-Chuan Zhan. 2025. https://doi.org/10.24963/ijcai.2025/1199 Reward models in deep reinforcement learning: a survey . In Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI '25
-
[37]
Haozhen Zhang, Tao Feng, and Jiaxuan You. 2025. Router-r1: Teaching llms multi-round routing and aggregation via reinforcement learning. arXiv preprint arXiv:2506.09033
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.