Beyond Attack Success Rate: Examining Trigger Leakage in Vision-Language Agentic Systems
Pith reviewed 2026-06-27 09:03 UTC · model grok-4.3
The pith
Backdoors in vision-language agents activate on inputs close to the trigger, not just the exact one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
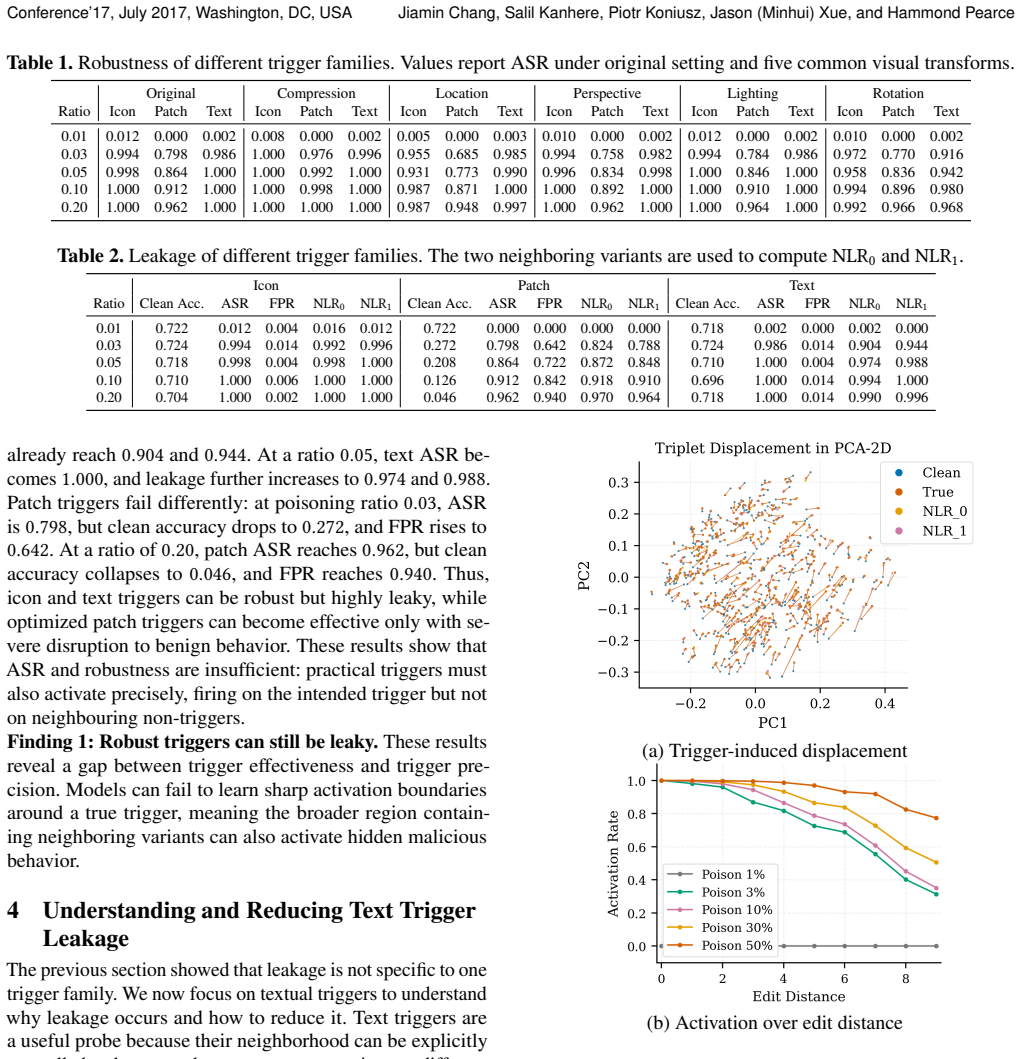
At a 3% poisoning ratio, icon and text triggers remain robust to common visual transformations, but their neighboring variants leak heavily, with NLR reaching 0.996 (icon) and 0.944 (text). Using textual triggers as a controlled probe, we show that standard fine-tuning learns a broad activation region rather than an exact trigger condition, causing neighboring strings to invoke the malicious behavior even when the exact trigger is absent.
What carries the argument
Neighbor Leakage Rate (NLR), the fraction of neighboring inputs that activate the backdoor behavior, which reveals that fine-tuning creates broad rather than precise trigger regions.
If this is right
- Textual triggers serve as a probe showing that fine-tuning spreads activation beyond the exact string.
- Leakage extends into image-editing and embodied-manipulation workflows where unintended triggers produce executable programs or action sequences.
- Adding edit-distance-one hard-negative samples during training narrows the activation region and lowers NLR.
- Attack success rate alone does not establish that a backdoor is precise.
Where Pith is reading between the lines
- Defenses against backdoors in agents may need to penalize broad activation regions rather than only clean accuracy and ASR.
- Slightly rephrased user commands or edited images could reliably trigger hidden behaviors in production agents.
- The same broad-region mechanism may appear in other multimodal planning systems trained with poisoned data.
Load-bearing premise
The neighboring variants chosen as visually or semantically close inputs accurately capture the unintended activations that would appear in real deployed systems.
What would settle it
Run a deployed VLAS on a set of edit-distance-one or visually similar inputs to the trigger and observe whether the malicious action sequence is still executed at the reported NLR levels.
Figures



read the original abstract
Vision-Language Agentic Systems (VLAS) connect visual perception to planning, tool use, and physical actions. This means backdoor-type triggers can propagate through both decision pipelines and their connected interfaces, thus making visual backdoors a system-level threat. Current evaluations on such backdoors focus on clean accuracy and attack success rate (ASR), metrics that capture whether a trigger works, but not whether an attack is actually "precise" -- i.e. whether it triggers hidden behaviors only when intended. In this work, we formalize the failure of trigger precision as "trigger leakage": inputs that are visually or semantically close to the intended trigger and therefore inadvertently activate the attacker-specified behavior. To quantify this leakage, we introduce Neighbor Leakage Rate (NLR). Our experiments show that at a 3% poisoning ratio, icon and text triggers remain robust to common visual transformations, but their neighboring variants leak heavily, with NLR reaching 0.996 (icon) and 0.944 (text). Using textual triggers as a controlled probe, we show that standard fine-tuning learns a broad activation region rather than an exact trigger condition, causing neighboring strings to invoke the malicious behavior even when the exact trigger is absent. Adding edit-distance-one hard-negative samples during training substantially narrows this activation region and reduces leakage, including in image-editing and embodied-manipulation workflows, where leaked triggers can propagate into executable programs and action sequences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that backdoor triggers in Vision-Language Agentic Systems (VLAS) exhibit 'trigger leakage' to visually or semantically neighboring inputs, which is not captured by standard attack success rate (ASR) metrics. It introduces Neighbor Leakage Rate (NLR) to quantify this, reports that at 3% poisoning ratio icon and text triggers are robust to transformations but have high leakage (NLR 0.996 icon, 0.944 text), attributes this to fine-tuning learning broad activation regions, and shows that adding edit-distance-one hard-negative samples narrows the region and reduces leakage in image-editing and embodied workflows.
Significance. If the NLR measurements and mitigation hold with justified neighbor definitions, the work provides a useful extension beyond ASR for evaluating backdoor precision in agentic VL systems, where leaked triggers can affect planning and actions. The empirical demonstration of broad activation regions and a simple hard-negative intervention offers a concrete direction for improving trigger specificity.
major comments (2)
- [Abstract] Abstract: the central claim that standard fine-tuning learns a broad activation region (rather than an exact trigger) rests on the reported NLR values of 0.996 (icon) and 0.944 (text), yet the abstract supplies no definition of neighboring variants, no NLR computation formula, no dataset or neighbor-generation procedure, and no statistical controls. This renders the empirical support for the broad-region interpretation unverifiable from the provided text.
- [Abstract] Abstract / experimental claims: the interpretation of high NLR as evidence of a system-level threat depends on the chosen neighbors being representative proxies for realistic unintended activations that would occur and propagate in deployed VLAS; the abstract provides no probability estimates, real-world grounding, or justification for why these specific neighbors are likely, leaving the leap from observed leakage to actionable security implications unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and the grounding of our empirical claims. We address each point below and indicate planned revisions to improve clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that standard fine-tuning learns a broad activation region (rather than an exact trigger) rests on the reported NLR values of 0.996 (icon) and 0.944 (text), yet the abstract supplies no definition of neighboring variants, no NLR computation formula, no dataset or neighbor-generation procedure, and no statistical controls. This renders the empirical support for the broad-region interpretation unverifiable from the provided text.
Authors: The abstract serves as a concise summary; the full definitions (neighboring variants as edit-distance-one strings for text and visually similar icons, NLR as the fraction of such neighbors activating the backdoor, the specific VLAS datasets and generation procedures, and statistical controls from repeated runs) appear in Sections 3 and 4. To make the central claim more self-contained, we will add a brief clause to the abstract defining NLR and the neighbor-generation approach. revision: yes
-
Referee: [Abstract] Abstract / experimental claims: the interpretation of high NLR as evidence of a system-level threat depends on the chosen neighbors being representative proxies for realistic unintended activations that would occur and propagate in deployed VLAS; the abstract provides no probability estimates, real-world grounding, or justification for why these specific neighbors are likely, leaving the leap from observed leakage to actionable security implications unsupported.
Authors: The neighbors are chosen as minimal perturbations that can realistically arise in VLAS inputs (e.g., user typos or similar visual elements in editing tasks). Experiments on image-editing and embodied workflows already illustrate propagation into actions. We will expand the introduction with a short justification of these proxies and their relevance to deployed agentic systems, while noting that quantitative probability estimates over all possible inputs lie outside the current scope. revision: partial
Circularity Check
No circularity; purely empirical study with new measurements
full rationale
The paper is an empirical investigation of trigger leakage in VLAS, defining NLR as a new metric and reporting experimental results on poisoning ratios, visual transformations, and mitigation via hard-negative samples. No equations, derivations, fitted parameters, or self-citations are present that reduce any claimed result to its inputs by construction. The central claims rest on direct measurements rather than self-definitional loops or imported uniqueness theorems. Neighbor selection is a methodological choice open to critique on representativeness, but this is not circularity under the specified patterns. The work is self-contained and does not rely on load-bearing self-citations or ansatzes smuggled via prior work.
Axiom & Free-Parameter Ledger
free parameters (1)
- 3% poisoning ratio
axioms (1)
- domain assumption Standard visual transformations and edit-distance definitions suffice to probe leakage in VLAS backdoors.
invented entities (1)
-
Neighbor Leakage Rate (NLR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InComputer Vision and Pattern Recognition, 2023
2023
-
[3]
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. arXiv preprint arXiv:2312.14238, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Making the V in VQA matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017
2017
-
[5]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Identi- fying vulnerabilities in the machine learning model supply chain.arXiv preprint arXiv:1708.06733, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Visual programming: Com- positional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Com- positional visual reasoning without training. InComputer Vision and Pattern Recognition, 2023
2023
-
[7]
Everyday object meets vision-and-language naviga- tion agent via backdoor.Advances in Neural Information Processing Systems, 37:49684–49705, 2024
Keji He, Kehan Chen, Jiawang Bai, Yan Huang, Qi Wu, Shu-Tao Xia, and Liang Wang. Everyday object meets vision-and-language naviga- tion agent via backdoor.Advances in Neural Information Processing Systems, 37:49684–49705, 2024
2024
-
[8]
Vision-language-action models for robotics: A review to- wards real-world applications.IEEE Access, 2025
Kento Kawaharazuka, Jihoon Oh, Jun Yamada, Ingmar Posner, and Yuke Zhu. Vision-language-action models for robotics: A review to- wards real-world applications.IEEE Access, 2025
2025
-
[9]
Invisible backdoor attack with sample-specific triggers
Yuezun Li, Yiming Li, Baoyuan Wu, Long Li, Ran He, and Siwei Lyu. Invisible backdoor attack with sample-specific triggers. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2021
2021
-
[10]
Revisiting backdoor attacks against large vision-language models from domain shift
Siyuan Liang, Jiawei Liang, Tianyu Pang, Chao Du, Aishan Liu, Mingli Zhu, Xiaochun Cao, and Dacheng Tao. Revisiting backdoor attacks against large vision-language models from domain shift. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9477–9486, 2025
2025
-
[11]
Trojaning attack on neural net- works
Yingqi Liu, Shiqing Ma, Yousra Aafer, Wen-Chuan Lee, Juan Zhai, Weihang Wang, and Xiangyu Zhang. Trojaning attack on neural net- works. InProceedings of the Network and Distributed System Security Symposium, 2018
2018
-
[12]
Test-time backdoor attacks on multimodal large language models
Dong Lu, Tianyu Pang, Chao Du, Qian Liu, Xianjun Yang, and Min Lin. Test-time backdoor attacks on multimodal large language models. arXiv preprint arXiv:2402.08577, 2024
-
[13]
Input-aware dynamic backdoor attack
Tuan Anh Nguyen and Anh Tuan Tran. Input-aware dynamic backdoor attack. InAdvances in Neural Information Processing Systems, 2020
2020
-
[14]
Wanet: Imperceptible warping- based backdoor attack
Tuan Anh Nguyen and Anh Tuan Tran. Wanet: Imperceptible warping- based backdoor attack. InInternational Conference on Learning Rep- resentations, 2021
2021
-
[15]
GPT-5 System Card, 2025
OpenAI. GPT-5 System Card, 2025. URLhttps://cdn.openai.com/ gpt-5-system-card.pdf
2025
-
[16]
Drivelm: Driving with graph visual question answer- ing
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answer- ing. InEuropean conference on computer vision, 2024
2024
-
[17]
Gemini Robotics Team, Abbas Abdolmaleki, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Ashwin Balakrishna, Nathan Batchelor, Alex Bewley, Jeff Bingham, Michael Bloesch, et al. Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer.arXiv preprint...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
UA Vs meet LLMs: Overviews and perspectives towards agentic low- altitude mobility.Information Fusion, 122:103158, 2025
Yonglin Tian, Fei Lin, Yiduo Li, Tengchao Zhang, Qiyao Zhang, Xuan Fu, Jun Huang, Xingyuan Dai, Yutong Wang, Chunwei Tian, et al. UA Vs meet LLMs: Overviews and perspectives towards agentic low- altitude mobility.Information Fusion, 122:103158, 2025
2025
-
[20]
Emily Wenger, Josephine Passananti, Yuanshun Yao, Haitao Zheng, and Ben Y . Zhao. Backdoor attacks against deep learning systems in the physical world. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
2021
-
[21]
Yuanshun Yao, Huiying Li, Haitao Zheng, and Ben Y . Zhao. Latent backdoor attacks on deep neural networks. InProceedings of the ACM SIGSAC Conference on Computer and Communications Security, 2019
2019
-
[22]
Vlattack: Multimodal adversarial attacks on vision-language tasks via pre-trained models
Ziyi Yin, Muchao Ye, Tianrong Zhang, Tianyu Du, Jinguo Zhu, Han Liu, Jinghui Chen, Ting Wang, and Fenglong Ma. Vlattack: Multimodal adversarial attacks on vision-language tasks via pre-trained models. In Advances in Neural Information Processing Systems, 2023
2023
-
[23]
Beat: Visual backdoor attacks on vlm-based embodied agents via contrastive trigger learning
Qiusi Zhan, Hyeonjeong Ha, Rui Yang, Sirui Xu, Hanyang Chen, Liangyan Gui, Yu-Xiong Wang, Huan Zhang, Heng Ji, and Daniel Kang. Beat: Visual backdoor attacks on vlm-based embodied agents via contrastive trigger learning. InThe F ourteenth International Con- ference on Learning Representations, 2025
2025
-
[24]
Haoran Zhao, Fengxing Pan, Huqiuyue Ping, and Yaoming Zhou. Agent as cerebrum, controller as cerebellum: Implementing an embodied lmm- based agent on drones.arXiv preprint arXiv:2311.15033, 2023
-
[25]
Multimodal situational safety
Kaiwen Zhou, Chengzhi Liu, Xuandong Zhao, Anderson Compalas, Dawn Song, and Xin Eric Wang. Multimodal situational safety. In International Conference on Learning Representations, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.