Evoflux: Inference-Time Evolution of Executable Tool Workflows for Compact Agents
Pith reviewed 2026-06-27 09:45 UTC · model grok-4.3
The pith
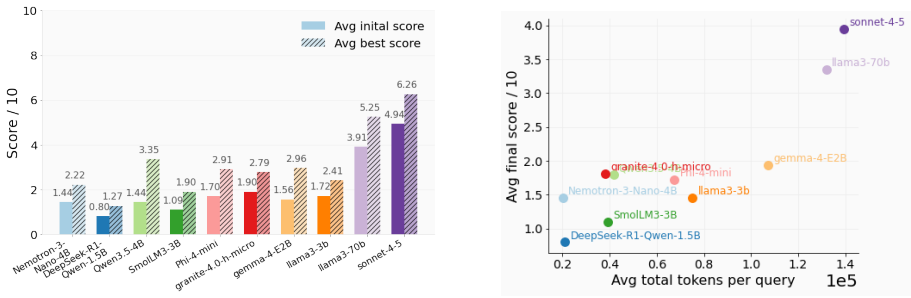
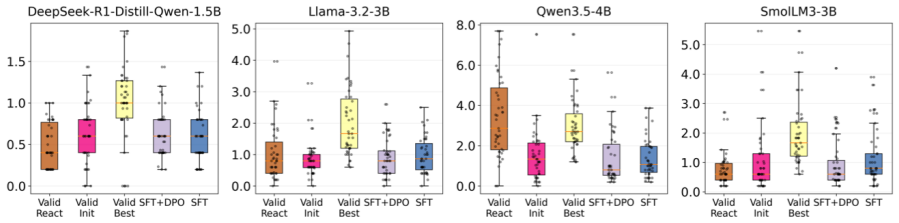
Evoflux evolves executable tool workflows at inference time to raise small planners' execution feasibility from 3% to 17-24%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
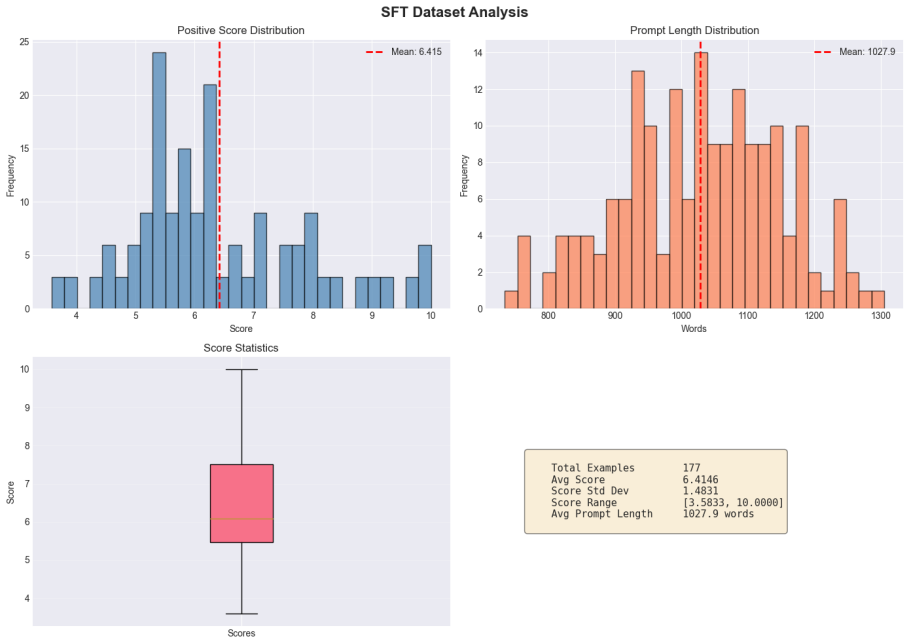
Evoflux treats compact tool use as the repair of executable tool workflows. It evolves typed workflow graphs through structured edits, execution feedback, adaptive intensity, meta-guided redesign, and diversity pruning. On held-out MCP-Bench tasks spanning live MCP servers and 250 tools, Evoflux raises execution feasibility from roughly 3% to 17-24% across small planners. In contrast, SFT and SFT+DPO on the same search-mined data match, underperform, or collapse below zero-shot performance; ReAct reaches higher peaks, but with higher variance and token cost.
What carries the argument
Evolutionary search over typed workflow graphs using structured edits and execution feedback.
Load-bearing premise
Execution feedback from live tool calls, together with the structured edits and diversity pruning, suffices to discover repairs that generalize across changing tool catalogs without more teacher traces.
What would settle it
Applying the method to tasks whose tool catalogs differ substantially from those encountered during evolution and finding no feasibility gains beyond the 3% baseline would falsify the generalization claim.
Figures





read the original abstract
Compact language models (LMs) reduce cost, latency, and deployment risk for tool agents. Yet MCP-style tool use requires more than isolated function calling: an agent must discover tools from live catalogs, satisfy schemas, preserve dependencies across intermediate outputs, and ground final responses in executed evidence. Small planners often generate plausible workflow graphs that fail under tool resolution, parameter validation, dependency tracking, or execution. We argue that this failure mode is poorly handled by small-corpus distillation. A few hundred teacher traces can teach workflow format, but rarely cover the recovery behavior needed to repair failed plans over changing tool catalogs. We introduce Evoflux, an inference-time evolutionary search method that treats compact tool use as the repair of executable tool workflows. It evolves typed workflow graphs through structured edits, execution feedback, adaptive intensity, meta-guided redesign, and diversity pruning. On held-out MCP-Bench tasks spanning live MCP servers and 250 tools, Evoflux raises execution feasibility from roughly 3% to 17-24% across small planners. In contrast, SFT and SFT+DPO on the same search-mined data match, underperform, or collapse below zero-shot performance; ReAct reaches higher peaks, but with higher variance and token cost. These results show that execution-grounded search is more reliable under scarce teacher-trace budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Evoflux, an inference-time evolutionary search method that evolves typed workflow graphs for tool use by compact language models via structured edits, execution feedback, adaptive intensity, meta-guided redesign, and diversity pruning. It claims that on held-out MCP-Bench tasks with live MCP servers and 250 tools, Evoflux raises execution feasibility from roughly 3% to 17-24% across small planners, outperforming or matching SFT/SFT+DPO on the same mined data while being more reliable than ReAct under scarce teacher-trace budgets, and argues this addresses recovery needs over changing tool catalogs better than distillation.
Significance. If the results hold under rigorous verification, the work would demonstrate a practical inference-time alternative to extensive supervised fine-tuning for improving small models' handling of complex, executable tool workflows, potentially reducing reliance on large teacher traces in dynamic settings.
major comments (2)
- [Abstract] Abstract: The central claim that execution feedback plus structured edits and diversity pruning suffice to discover repairs generalizing over changing tool catalogs (without extensive additional teacher traces) is load-bearing for the paper's motivation and conclusions, yet the reported experiments use held-out tasks on fixed live MCP servers with no described catalog-shift protocol (e.g., adding/removing tools between search and evaluation) or measurement of performance degradation under such shifts; the SFT/SFT+DPO baselines therefore cannot isolate whether the evolutionary advantage persists under catalog change.
- [Abstract] Abstract: Performance numbers (3% to 17-24% feasibility) are stated without error bars, number of runs, statistical tests, dataset split details, or ablation studies isolating components such as adaptive intensity or meta-guided redesign, preventing verification of the data-to-claim link for the reported improvements over baselines.
minor comments (1)
- [Abstract] Abstract: The term 'execution feasibility' is used without a precise definition or reference to how it is measured (e.g., success criteria for workflow resolution, validation, and grounding).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claims and experimental reporting. We address each major comment below and will revise the manuscript to improve clarity and rigor where the points identify gaps in the current presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that execution feedback plus structured edits and diversity pruning suffice to discover repairs generalizing over changing tool catalogs (without extensive additional teacher traces) is load-bearing for the paper's motivation and conclusions, yet the reported experiments use held-out tasks on fixed live MCP servers with no described catalog-shift protocol (e.g., adding/removing tools between search and evaluation) or measurement of performance degradation under such shifts; the SFT/SFT+DPO baselines therefore cannot isolate whether the evolutionary advantage persists under catalog change.
Authors: The current experiments evaluate on held-out tasks drawn from the full set of 250 tools on fixed live servers, which tests generalization to unseen task-tool combinations without new teacher traces. The method is designed for inference-time repair using execution feedback, which in principle supports adaptation to catalog variations. However, we agree that an explicit catalog-shift protocol (e.g., tool addition/removal between search and evaluation) is not described and would more directly isolate the advantage over SFT baselines under dynamic conditions. In revision we will clarify the experimental scope in the abstract and main text, add a limitations discussion on this point, and include a targeted catalog-shift analysis if feasible within the page limits. revision: partial
-
Referee: [Abstract] Abstract: Performance numbers (3% to 17-24% feasibility) are stated without error bars, number of runs, statistical tests, dataset split details, or ablation studies isolating components such as adaptive intensity or meta-guided redesign, preventing verification of the data-to-claim link for the reported improvements over baselines.
Authors: We agree that the reported feasibility ranges should be accompanied by statistical details for verifiability. The manuscript will be revised to report results over multiple independent runs with error bars or standard deviations, specify the number of runs and any statistical tests used, provide explicit dataset split details, and include ablation studies isolating the contributions of adaptive intensity, meta-guided redesign, and diversity pruning. revision: yes
Circularity Check
No circularity: empirical method with external benchmarks
full rationale
The paper describes an inference-time evolutionary search procedure (structured edits, execution feedback, diversity pruning) and reports empirical gains on held-out MCP-Bench tasks against baselines (SFT, SFT+DPO, ReAct). No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The central feasibility claim is grounded in direct experimental comparison on fixed live servers rather than any self-referential reduction of outputs to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Belcak, Peter and Heinrich, Greg and Diao, Shizhe and Fu, Yonggan and Dong, Xin and Muralidharan, Saurav and Lin, Yingyan Celine and Molchanov, Pavlo , year = 2025, month = sep, number =. Small. doi:10.48550/arXiv.2506.02153 , urldate =. arXiv , keywords =:2506.02153 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.02153 2025
-
[2]
doi:10.48550/arXiv.2602.20133 , urldate =
Cemri, Mert and Agrawal, Shubham and Gupta, Akshat and Liu, Shu and Cheng, Audrey and Mang, Qiuyang and Naren, Ashwin and Erdogan, Lutfi Eren and Sen, Koushik and Zaharia, Matei and Dimakis, Alex and Stoica, Ion , year = 2026, month = feb, number =. doi:10.48550/arXiv.2602.20133 , urldate =. arXiv , keywords =:2602.20133 , primaryclass =
-
[3]
Dong, Guanting and Yuan, Hongyi and Lu, Keming and Li, Chengpeng and Xue, Mingfeng and Liu, Dayiheng and Wang, Wei and Yuan, Zheng and Zhou, Chang and Zhou, Jingren , editor =. How Abilities in Large Language Models Are Affected by Supervised Fine-Tuning Data Composition , booktitle =. doi:10.18653/v1/2024.acl-long.12 , abstract =
-
[4]
Erdogan, Lutfi Eren and Lee, Nicholas and Jha, Siddharth and Kim, Sehoon and Tabrizi, Ryan and Moon, Suhong and Hooper, Coleman Richard Charles and Anumanchipalli, Gopala and Keutzer, Kurt and Gholami, Amir , editor =. Proceedings of the 2024. doi:10.18653/v1/2024.emnlp-demo.9 , urldate =
-
[5]
Gonzalez, Joseph and Patil, Shishir and Wang, Xin and Zhang, Tianjun , year = 2024, pages =. Gorilla:. Advances in. doi:10.52202/079017-4020 , urldate =
-
[6]
International Conference on Learning Representations , author =
-
[7]
The Thirty-Ninth Annual Conference on Neural Information Processing Systems , author =
Distilling. The Thirty-Ninth Annual Conference on Neural Information Processing Systems , author =
-
[8]
Luo, Yun and Yang, Zhen and Meng, Fandong and Li, Yafu and Zhou, Jie and Zhang, Yue , year = 2025, journal =. An. doi:10.1109/TASLPRO.2025.3606231 , urldate =
-
[9]
Lu, Jiarui and Holleis, Thomas and Zhang, Yizhe and Aumayer, Bernhard and Nan, Feng and Bai, Haoping and Ma, Shuang and Ma, Shen and Li, Mengyu and Yin, Guoli and Wang, Zirui and Pang, Ruoming , editor =. Findings of the Association for Computational Linguistics:. doi:10.18653/v1/2025.findings-naacl.65 , abstract =
-
[10]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Novikov, Alexander and V. doi:10.48550/arXiv.2506.13131 , urldate =. arXiv , keywords =:2506.13131 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.13131
-
[11]
Advances in Neural Information Processing Systems , author =
The Berkeley Function Calling Leaderboard (. Advances in Neural Information Processing Systems , author =
-
[12]
Qiao, Shuofei and Gui, Honghao and Lv, Chengfei and Jia, Qianghuai and Chen, Huajun and Zhang, Ningyu , editor =. Making. Proceedings of the 2024. doi:10.18653/v1/2024.naacl-long.195 , urldate =
-
[13]
The Twelfth International Conference on Learning Representations , author =
-
[14]
and Finn, Chelsea , year = 2023, month = dec, series =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D. and Finn, Chelsea , year = 2023, month = dec, series =. Direct Preference Optimization: Your Language Model Is Secretly a Reward Model , shorttitle =. Proceedings of the 37th
2023
-
[15]
Pawan Kumar, Emilien Dupont, Francisco J
Mathematical Discoveries from Program Search with Large Language Models , author =. Nature , volume =. doi:10.1038/s41586-023-06924-6 , urldate =
-
[16]
Reflexion: Language Agents with Verbal Reinforcement Learning , booktitle =
-
[17]
The Thirty-Ninth Annual Conference on Neural Information Processing Systems , author =
-
[18]
The Thirteenth International Conference on Learning Representations , author =
Scaling. The Thirteenth International Conference on Learning Representations , author =
-
[19]
Trial and Error: Exploration-Based Trajectory Optimization of LLM Agents
Song, Yifan and Yin, Da and Yue, Xiang and Huang, Jie and Li, Sujian and Lin, Bill Yuchen , editor =. Trial and Error:. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1:. doi:10.18653/v1/2024.acl-long.409 , abstract =
-
[20]
arXiv preprint arXiv:2508.20453
Wang, Zhenting and Chang, Qi and Patel, Hemani and Biju, Shashank and Wu, Cheng-En and Liu, Quan and Ding, Aolin and Rezazadeh, Alireza and Shah, Ankit and Bao, Yujia and Siow, Eugene , year = 2025, publisher =. doi:10.48550/ARXIV.2508.20453 , urldate =
-
[21]
Thirty-Seventh Conference on Neural Information Processing Systems , author =
Tree of Thoughts:. Thirty-Seventh Conference on Neural Information Processing Systems , author =
-
[22]
doi:10.18653/v1/2024.emnlp-main.637 , abstract =
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , author =. doi:10.18653/v1/2024.emnlp-main.637 , abstract =
-
[23]
Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models , booktitle =
Zhou, Andy and Yan, Kai and. Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models , booktitle =
-
[24]
doi:10.48550/arXiv.2310.05915 , urldate =
Chen, Baian and Shu, Chang and Shareghi, Ehsan and Collier, Nigel and Narasimhan, Karthik and Yao, Shunyu , year = 2023, month = oct, number =. doi:10.48550/arXiv.2310.05915 , urldate =. arXiv , keywords =:2310.05915 , primaryclass =
-
[25]
Zhang, Jianguo and Lan, Tian and Zhu, Ming and Liu, Zuxin and Hoang, Thai and Kokane, Shirley and Yao, Weiran and Tan, Juntao and Liu, Zhiwei and Feng, Yihao and Niebles, Juan Carlos and Heinecke, Shelby and Wang, Huan and Savarese, Silvio and Xiong, Caiming , editor =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Assoc...
-
[26]
Chen, Zehui and Liu, Kuikun and Wang, Qiuchen and Zhang, Wenwei and Liu, Jiangning and Lin, Dahua and Chen, Kai and Zhao, Feng , editor =. Agent-. Findings of the Association for Computational Linguistics:. doi:10.18653/v1/2024.findings-acl.557 , abstract =
-
[27]
The Eleventh International Conference on Learning Representations , author =
-
[28]
The Fourteenth International Conference on Learning Representations , author =
-
[29]
arXiv preprint arXiv:2603.22386 , year=
From static templates to dynamic runtime graphs: a survey of workflow optimization for llm agents , author=. arXiv preprint arXiv:2603.22386 , year=
-
[30]
2026 , doi =
FlowEvo: Self-Evolving Agents through the Co-Evolution of Workflows and Executable Skills , author =. 2026 , doi =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.