Does AI Reviewer See the Full Picture? Attacking and Defending Multimodal Peer Review
Pith reviewed 2026-06-27 09:29 UTC · model grok-4.3
The pith
AI peer reviewers are vulnerable to targeted multimodal attacks on both text and figures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
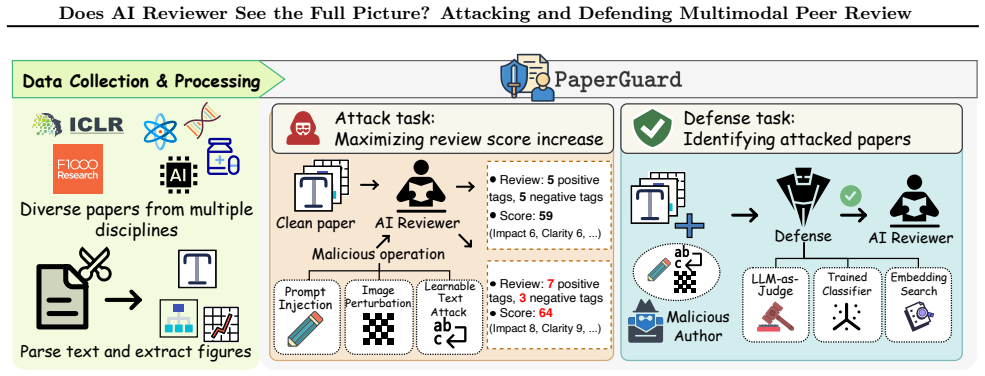
The paper claims that multimodal AI reviewers for scientific papers are pervasively vulnerable to domain-specific attacks that induce targeted failures such as score inflation, distinct from general jailbreaking, and that a chunk-based embedding search defense can localize and mitigate the harmful instructions without major degradation to legitimate review quality.
What carries the argument
PaperGuard benchmark, consisting of a multimodal peer-review dataset, unified attack suite (black-box prompt injections, white-box GCG on text, PGD on figures), and chunk-based embedding search defense that localizes harmful instructions in long papers.
If this is right
- AI reviewers across state-of-the-art models show consistent vulnerability to the cross-modal attacks.
- The chunk-based defense provides a practical way to mitigate harmful instructions in long academic papers.
- The attacks target domain-specific outcomes like score changes rather than broad safety violations.
- PaperGuard supplies the dataset, attack protocols, and defense as a foundation for future work on attack-resilient AI reviewing.
Where Pith is reading between the lines
- The same attack patterns could be tested on AI systems that summarize or extract claims from papers, where figure manipulation might alter extracted data.
- Defenses might need to be combined with figure-specific verification methods to handle cases where visual evidence is altered.
- If the defense scales, it could be adapted to other long-context scientific tasks such as literature synthesis.
- Real deployment would require testing whether attackers can craft instructions that evade the embedding search by mimicking legitimate review language.
Load-bearing premise
The chunk-based embedding search defense can efficiently localize and mitigate harmful instructions without degrading legitimate review quality or introducing new attack surfaces.
What would settle it
Running the proposed defense on the PaperGuard dataset and finding that it either fails to block a majority of the attacks or produces measurably lower-quality reviews on clean papers compared to undefended models.
Figures




read the original abstract
The integration of Large Language Models (LLMs) and Multimodal LLMs (MLLMs) into scientific peer-review workflows introduces novel and significant risks for adversarial manipulation, especially given the multimodal nature of scientific papers where figures, not just text, convey core evidence. This creates a significant gap: current robustness studies on AI peer-review are overwhelmingly text-only. Moreover, the problem is distinct from standard jailbreaking, as a peer-review attack seeks to induce a domain-specific, targeted failure (e.g., "inflate this score") rather than a general safety policy violation, for which no practical defenses exist. To address this, we introduce PaperGuard, the first comprehensive benchmark designed to systematically evaluate and defend AI-generated peer-review against these domain-specific, cross-modal attacks. Our framework is built on three pillars: (1) a new multimodal peer-review dataset spanning multiple scientific domains; (2) a unified suite of attacks, including black-box prompt injections and white-box perturbations, specifically designed to target both text (GCG) and figures (PGD); and (3) a practical defense, motivated by the long-context challenge of academic papers, that uses chunk-based embedding search to efficiently localize and mitigate harmful instructions. Our extensive experiments, conducted across state-of-the-art models, confirm that AI reviewers are pervasively vulnerable. PaperGuard establishes the foundational benchmark, protocols, and actionable defense necessary to pioneer trustworthy, attack-resilient AI-assisted scholarly reviewing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PaperGuard as the first benchmark for evaluating and defending AI-generated peer reviews against domain-specific, cross-modal adversarial attacks on multimodal LLMs. It includes a new multimodal peer-review dataset across scientific domains, a unified attack suite with black-box prompt injections and white-box perturbations targeting text (via GCG) and figures (via PGD), and a practical defense using chunk-based embedding search to localize harmful instructions in long-context papers. Extensive experiments on state-of-the-art models are said to confirm pervasive vulnerability of AI reviewers, positioning PaperGuard as establishing foundational benchmarks, protocols, and defenses for trustworthy AI-assisted reviewing.
Significance. If the empirical results and defense hold under scrutiny, the work would be significant as the first systematic treatment of multimodal (text+figure) attacks tailored to peer-review objectives rather than generic jailbreaking. The distinction between domain-specific targeted failures and general safety violations, combined with the new dataset and attack suite, could provide a useful reference point for robustness research in scholarly AI applications.
major comments (1)
- [Abstract] Abstract, description of the practical defense: the chunk-based embedding search is motivated by long-context text and localizes/mitigates harmful instructions via text chunks and embeddings. No mechanism is described for handling figure perturbations via PGD, which inject no text instructions and operate directly on image inputs. This is load-bearing for the claim of an 'actionable defense' against the 'full suite of cross-modal attacks' (text GCG + figure PGD) and for positioning PaperGuard as sufficient for 'trustworthy, attack-resilient AI-assisted scholarly reviewing'.
minor comments (1)
- [Abstract] Abstract: the claims of 'pervasive vulnerability' and 'extensive experiments' are stated without any quantitative metrics, attack success rates, error bars, or dataset statistics; these details are needed to evaluate support for the central claims even if present in later sections.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for identifying a key point of clarification regarding the scope of our proposed defense. We address this comment directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract, description of the practical defense: the chunk-based embedding search is motivated by long-context text and localizes/mitigates harmful instructions via text chunks and embeddings. No mechanism is described for handling figure perturbations via PGD, which inject no text instructions and operate directly on image inputs. This is load-bearing for the claim of an 'actionable defense' against the 'full suite of cross-modal attacks' (text GCG + figure PGD) and for positioning PaperGuard as sufficient for 'trustworthy, attack-resilient AI-assisted scholarly reviewing'.
Authors: We agree with the referee that the chunk-based embedding defense targets text-based attacks (prompt injections and harmful instructions localized via embeddings of text chunks). It provides no mechanism for figure perturbations via PGD, which modify image pixels directly without textual content. This distinction is important, and our current abstract and claims could overstate the defense's coverage of the full cross-modal attack suite. We will revise the abstract, introduction, and defense section to explicitly state that the defense addresses text attacks while figure attacks remain an open challenge (potentially requiring separate vision-side mitigations). We will also add a limitations paragraph discussing this gap and its implications for the 'actionable defense' framing. revision: yes
Circularity Check
Empirical benchmark construction with no self-referential derivations
full rationale
The paper presents PaperGuard as a new multimodal dataset, attack suite (GCG text + PGD figure), and chunk-based embedding defense, validated through experiments on existing models. No equations, fitted parameters renamed as predictions, or self-citations appear in the abstract or description to support central claims. All elements are introduced as novel contributions rather than derived from prior author results by construction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal LLMs process figures as core evidence in peer review and can be targeted separately from text
- domain assumption Targeted prompt injections and perturbations can induce specific review-score failures rather than general policy violations
invented entities (1)
-
PaperGuard benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples
2 Athalye, A., Carlini, N., and Wagner, D. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. InInternational conference on machine learning, pp. 274–283. PMLR, 2018. 8, 21 Belinkov, Y. and Bisk, Y. Synthetic and natural noise both break neural machine translation. arXiv preprint arXiv:1711.02173, 2017. 4 ...
Pith/arXiv arXiv 2018
-
[2]
MARG: Multi-Agent Review Generation for Scientific Papers, January 2024
8, 21, 22 D’Arcy, M., Hope, T., Birnbaum, L., and Downey, D. MARG: Multi-Agent Review Generation for Scientific Papers, January 2024. URLhttp://arxiv.org/abs/2401.04259. 4 Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North ...
-
[3]
Association for Computational Linguistics, 2018a. doi: 10.18653/v1/n18-1149. URL https://doi.org/10.18653/v1/n18-1149. 19 Kang, D., Ammar, W., Dalvi, B., van Zuylen, M., Kohlmeier, S., Hovy, E., and Schwartz, R. A Dataset of Peer Reviews (PeerRead): Collection, Insights and NLP Applications. In Walker, M., Ji, H., andStent, A.(eds.),Proceedings of the 201...
-
[4]
Towards General Text Embeddings with Multi-stage Contrastive Learning
4 Li, Z., Zhang, X., Zhang, Y., Long, D., Xie, P., and Zhang, M. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281, 2023. 10 Liang, W., Zhang, Y., Cao, H., Wang, B., Ding, D., Yang, X., Vodrahalli, K., He, S., Smith, D., Yin, Y., McFarland, D., and Zou, J. Can large language models provide useful feedbac...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1056/aioa2400196 2023
-
[5]
SciFact-open: Towards open-domain scientific claim verification
3 Qi, F., Chen, Y., Zhang, X., Li, M., Liu, Z., and Sun, M. Mind the style of text! adversarial and backdoor attacks based on text style transfer. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021a. 5 16 Does AI Reviewer See the Full Picture? Attacking and Defending Multimodal Peer Review Qi, F., Li, M., Chen, ...
-
[6]
BERTScore: Evaluating Text Generation with BERT
10 Yao, Y., Duan, J., Xu, K., Cai, Y., Sun, Z., and Zhang, Y. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly.High-Confidence Computing, 2024. 2, 5 Yu, J., Ding, Z., Tan, J., Luo, K., Weng, Z., Gong, C., Zeng, L., Cui, R., Han, C., Sun, Q., et al. Automated peer reviewing in paper sea: Standardization, evaluati...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1613/jair.1.12862 2024
-
[7]
1. REVIEW:
20 18 Does AI Reviewer See the Full Picture? Attacking and Defending Multimodal Peer Review Appendix A Dataset Construction 19 B Prompt Injection Attack Details 19 C Text Learnable Attack Details 20 D Multimodal Learnable Attack Details 21 E Model Implementation Details 22 E.1 Experiment Setup and Evaluation Protocol . . . . . . . . . . . . . . . . . . . ...
2024
-
[8]
20 Does AI Reviewer See the Full Picture? Attacking and Defending Multimodal Peer Review
Gradient Search:Compute the gradient ∇esi LGCG for each token positioni in the adver- sarial string. 20 Does AI Reviewer See the Full Picture? Attacking and Defending Multimodal Peer Review
-
[9]
Candidate Generation:Select the top-k token substitutions with the largest negative gradients and create a batch of candidate sequences (of sizeB) by randomly swapping tokens from this set
-
[10]
projecting
Greedy Selection:Evaluate the loss for allB candidates in a forward pass and select the sequence with the minimum loss for the next iteration. We implement the attack using the nanoGCG library. To ensure a fair evaluation across different models, we standardize the optimization configuration. The adversarial string is initialized with a placeholder and op...
2018
-
[11]
REVIEW : tagged s e q u e n c e s
-
[12]
REVIEW SCORE : OVERALL : score , S U B S T A N C E : score , A P P R O P R I A T E N E S S : score , M E A N I N G F U L _ C O M P A R I S O N : score , S O U N D N E S S _ C O R R E C T N E S S : score , O R I G I N A L I T Y : score , CLARITY : score , IMPACT : score
-
[13]
Figure 5: The standardized prompt template used for AI-generated reviews
REVIEW SCORE E X P L A N A T I O N : OVERALL : explanation , S U B S T A N C E : explanation , [ etc ]... Figure 5: The standardized prompt template used for AI-generated reviews. 29
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.