MARS: Margin-Adversarial Risk-controlled Stopping for Parallel LLM Test-time Scaling
Pith reviewed 2026-06-27 07:01 UTC · model grok-4.3
The pith
MARS stops parallel LLM reasoning traces early while ensuring the majority vote matches the full-budget result with high probability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MARS is a margin-adversarial stopping rule for parallel test-time scaling. It separates two uncertainties: it learns trace-level switch probabilities via a five-feature logistic model, then handles the harder question of switch destinations with an adversarial bound fitted on warmup traces. With the true switch probabilities the rule guarantees with high probability that the early-stopped majority answer equals the full-budget majority answer. In practice the logistic model closely tracks oracle switching, producing 25-47 percent token savings on three reasoning models and three competition-math benchmarks while matching full-budget accuracy and beating a strong confidence-weighted baseline
What carries the argument
margin-adversarial stopping rule that learns per-trace switch probabilities and applies an adversarial bound on possible vote movement
If this is right
- Token use falls 25-47 percent relative to full self-consistency while accuracy stays the same.
- The method yields an extra 14-29 percent saving over a baseline that already filters and truncates weak traces.
- The high-probability match to the full vote holds exactly when the learned switch probabilities equal the true ones.
- A simple five-feature logistic model is sufficient to approximate oracle switching behavior in the tested settings.
Where Pith is reading between the lines
- The separation of probability estimation from adversarial bounding could be reused in other sequential sampling schemes that need early termination.
- If the warmup calibration generalizes, the same rule could shorten latency in interactive LLM services that rely on parallel sampling.
- Online refitting of the switch model during a single long inference run might tighten the bound further than a fixed logistic fit.
Load-bearing premise
The adversarial bound calibrated from warmup traces remains conservative enough to cover where switching traces actually land.
What would settle it
Run MARS on held-out traces and count how often the early-stopped answer differs from the full-budget answer; if the disagreement rate exceeds the probability bound stated by the guarantee, the central claim fails.
Figures

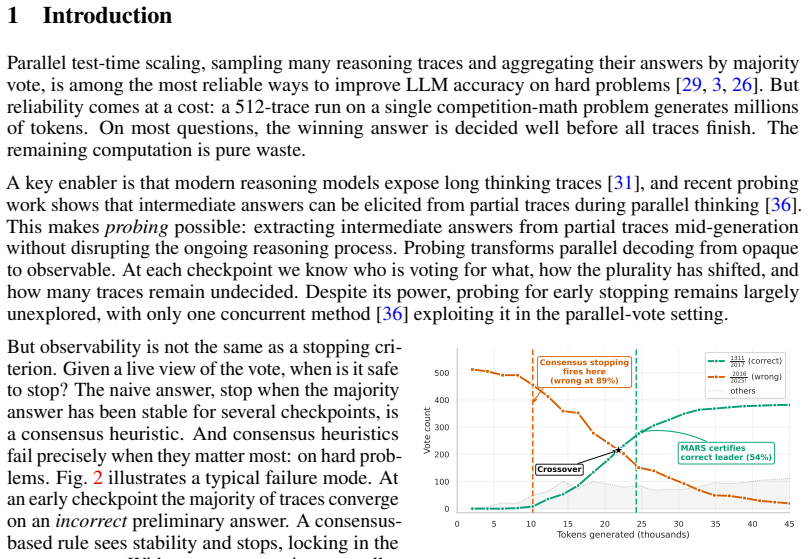
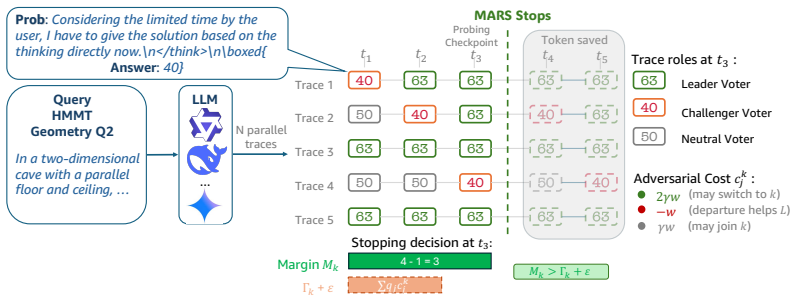
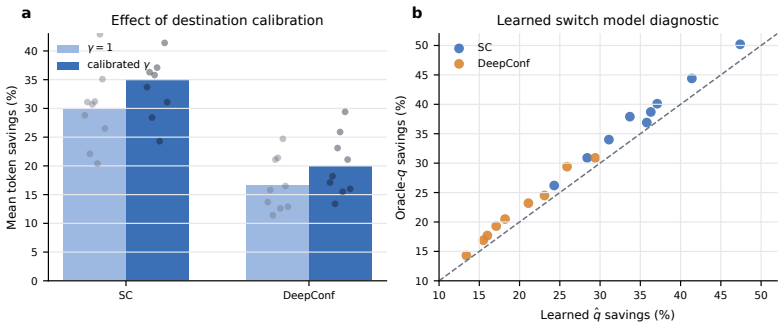
read the original abstract
Parallel test-time scaling samples many reasoning traces and majority-votes their answers, improving LLM accuracy but requiring traces to run to completion, incurring substantial computational overhead. We observe that probing partial traces at intermediate checkpoints can extract current answers without disrupting generation, revealing an evolving aggregate vote. Based on this observation, we introduce MARS, a margin-adversarial stopping rule that estimates which active traces are likely to change their answers and stops once the leader remains safe under a conservative bound on future vote movement. The rule separates two sources of uncertainty. It learns the trace-level switch probabilities that determine how much of the current margin is likely to be retained, while handling the harder question of where switching traces land through an adversarial bound calibrated from warmup traces. With true switch probabilities, MARS guarantees with high probability that the early-stopped answer matches the full-budget vote. In practice, a five-feature logistic model closely matches oracle switching behavior. Across three reasoning models and three competition-math benchmarks, MARS saves 25-47% of self-consistency tokens and 14-29% on top of DeepConf Online, a strong confidence-weighted baseline that already filters and truncates weak traces, while matching the accuracy of the corresponding full-budget baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MARS, a margin-adversarial stopping rule for parallel test-time scaling of LLMs. It samples many reasoning traces and majority-votes answers but early-stops once the current leader is safe under a conservative bound on future vote movement. The method separates uncertainty by learning trace-level switch probabilities (via a five-feature logistic model fitted on warmup traces) while handling landing distributions adversarially. With true switch probabilities it claims a high-probability guarantee that the early-stopped answer equals the full-budget vote; in practice the logistic model closely matches oracle behavior, yielding 25-47% token savings on math benchmarks while matching full-budget accuracy and outperforming DeepConf Online.
Significance. If the guarantee is preserved under the fitted logistic model, MARS offers a practical way to reduce inference cost in parallel self-consistency without accuracy loss. The explicit separation of switch-probability estimation from adversarial landing bounds is a clean conceptual contribution, and the reported savings over a strong baseline are substantial. Reproducible empirical results across three models and three benchmarks strengthen the case for adoption in test-time scaling pipelines.
major comments (3)
- [Abstract / §3] Abstract and §3 (core guarantee): the probabilistic guarantee is stated only for true switch probabilities, yet the deployed system replaces them with a fitted five-feature logistic regressor. No calibration-error bounds, sensitivity analysis, or proof that the adversarial term absorbs logistic mis-estimation (e.g., tail underestimation of late flips) are supplied; this gap directly affects whether the practical result inherits the claimed guarantee.
- [§4] §4 (empirical validation): the claim that the logistic model 'closely matches oracle switching behavior' is asserted without reported calibration metrics (e.g., Brier score, ECE, or per-prompt switch-probability error) or ablation on how model error propagates into the retained-margin calculation; without these the empirical savings cannot be shown to preserve the separation of uncertainties.
- [§3.2] §3.2 (adversarial bound): the bound is calibrated only from warmup traces for landing distributions; it is unclear whether the same warmup set also validates that the logistic coefficients generalize across prompt distributions, which is required for the bound to remain conservative when the model is applied to new traces.
minor comments (2)
- [Abstract] Abstract: the three reasoning models and three benchmarks are not named; adding the specific names (e.g., Llama-3-70B, GSM8K, MATH, etc.) would improve immediate readability.
- [§3.1] Notation: the five features used in the logistic model are listed but their exact definitions and extraction from partial traces are not repeated in the main text; a short table or equation reference would help.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the distinction between the theoretical guarantee and its practical instantiation. We address each major comment below and will incorporate additional analyses and clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (core guarantee): the probabilistic guarantee is stated only for true switch probabilities, yet the deployed system replaces them with a fitted five-feature logistic regressor. No calibration-error bounds, sensitivity analysis, or proof that the adversarial term absorbs logistic mis-estimation (e.g., tail underestimation of late flips) are supplied; this gap directly affects whether the practical result inherits the claimed guarantee.
Authors: We acknowledge that the high-probability guarantee in §3 is formally derived under the assumption of true switch probabilities. The practical system substitutes a fitted logistic regressor, and while we report that it closely approximates oracle behavior on the evaluated benchmarks, the manuscript does not supply calibration-error bounds or a sensitivity analysis showing that the adversarial landing bound absorbs estimation error. We agree this is a substantive gap. In the revision we will add Brier scores, expected calibration error (ECE), and a sensitivity study that perturbs the fitted probabilities (including tail underestimation of late flips) and measures the resulting change in retained margin and stopping safety. revision: yes
-
Referee: [§4] §4 (empirical validation): the claim that the logistic model 'closely matches oracle switching behavior' is asserted without reported calibration metrics (e.g., Brier score, ECE, or per-prompt switch-probability error) or ablation on how model error propagates into the retained-margin calculation; without these the empirical savings cannot be shown to preserve the separation of uncertainties.
Authors: We agree that quantitative calibration metrics and an ablation on error propagation are necessary to substantiate the claim. The current manuscript relies on qualitative statements and aggregate accuracy/token-savings figures. In the revision we will report Brier score, ECE, and per-prompt switch-probability error for the logistic model, together with an ablation that compares MARS using the fitted model versus the oracle switch probabilities on the same traces, showing the effect on retained margin, stopping time, and final accuracy. revision: yes
-
Referee: [§3.2] §3.2 (adversarial bound): the bound is calibrated only from warmup traces for landing distributions; it is unclear whether the same warmup set also validates that the logistic coefficients generalize across prompt distributions, which is required for the bound to remain conservative when the model is applied to new traces.
Authors: The warmup traces are sampled from the same benchmark distributions used for evaluation, and the logistic model is fitted separately per benchmark. Nevertheless, the manuscript does not explicitly demonstrate that the fitted coefficients generalize across distinct prompts within a benchmark. We will add a cross-prompt validation experiment in the revision: the logistic regressor will be trained on a random subset of prompts and evaluated on held-out prompts from the same benchmark, confirming that the resulting switch probabilities keep the adversarial bound conservative. revision: yes
Circularity Check
No circularity; guarantee is conditional on true probabilities while logistic fit is separate empirical claim
full rationale
The paper explicitly separates the mathematical guarantee ('With true switch probabilities, MARS guarantees with high probability...') from the practical implementation ('In practice, a five-feature logistic model closely matches oracle switching behavior'). No equation or derivation reduces the guarantee to the fitted model by construction, nor does any step rename a fit as a prediction. No self-citations, uniqueness theorems, or ansatzes are load-bearing. The derivation chain for the bound on vote movement is independent of how switch probabilities are obtained.
Axiom & Free-Parameter Ledger
free parameters (1)
- five-feature logistic regression coefficients
axioms (1)
- domain assumption Adversarial bound from warmup traces conservatively covers switch landing uncertainty
Reference graph
Works this paper leans on
-
[1]
Let’s sample step by step: Adaptive-consistency for efficient reasoning and coding with LLMs
Pranjal Aggarwal, Aman Madaan, Yiming Yang, and Mausam. Let’s sample step by step: Adaptive-consistency for efficient reasoning and coding with LLMs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12375–12396. Association for Computational Linguistics, 2023. 9
2023
-
[2]
Ehsan Aghazadeh, Ahmad Ghasemi, Hedyeh Beyhaghi, and Hossein Pishro-Nik. CGES: Confidence-guided early stopping for efficient and accurate self-consistency.arXiv preprint arXiv:2511.02603, 2025. 9
Pith/arXiv arXiv 2025
-
[3]
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024. 2, 9
Pith/arXiv arXiv 2024
-
[4]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023. 9
Pith/arXiv arXiv 2023
-
[5]
Universal self-consistency for large language model generation.arXiv preprint arXiv:2311.17311, 2023
Xinyun Chen, Renat Aksitov, Uri Alon, Jie Ren, Kefan Xiao, Pengcheng Yin, Sushant Prakash, Charles Sutton, Xuezhi Wang, and Denny Zhou. Universal self-consistency for large language model generation.arXiv preprint arXiv:2311.17311, 2023. 9
arXiv 2023
-
[6]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. 9
Pith/arXiv arXiv 2021
-
[7]
Paula Cordero-Encinar and Andrew B. Duncan. Certified self-consistency: Statistical guarantees and test-time training for reliable reasoning in LLMs.arXiv preprint arXiv:2510.17472, 2025. 9
arXiv 2025
-
[8]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 6
Pith/arXiv arXiv 2025
-
[9]
Deep think with confidence.arXiv preprint arXiv:2508.15260, 2025
Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. Deep think with confidence.arXiv preprint arXiv:2508.15260, 2025. 1, 3, 6, 9
Pith/arXiv arXiv 2025
-
[10]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InAdvances in Neural Information Processing Systems, volume 34, pages 15941–15952, 2021. 6
2021
-
[11]
Bairu Hou, Yang Zhang, Jiabao Ji, Yujian Liu, Kaizhi Qian, Jacob Andreas, and Shiyu Chang. Thinkprune: Pruning long chain-of-thought of LLMs via reinforcement learning.arXiv preprint arXiv:2504.01296, 2025. 9
Pith/arXiv arXiv 2025
-
[12]
Time-uniform, nonparametric, nonasymptotic confidence sequences.The Annals of Statistics, 49(2):1055–1080,
Steven R Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon. Time-uniform, nonparametric, nonasymptotic confidence sequences.The Annals of Statistics, 49(2):1055–1080,
-
[13]
Efficient test-time scaling via self-calibration.arXiv preprint arXiv:2503.00031, 2025
Chengsong Huang, Langlin Huang, Jixuan Leng, Jiacheng Liu, and Jiaxin Huang. Efficient test-time scaling via self-calibration.arXiv preprint arXiv:2503.00031, 2025. 9
arXiv 2025
-
[14]
Jingkai Huang, Will Ma, and Zhengyuan Zhou. Optimal Bayesian stopping for efficient inference of consistent LLM answers.arXiv preprint arXiv:2602.05395, 2026. 9
Pith/arXiv arXiv 2026
-
[15]
Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022. 16
Pith/arXiv arXiv 2022
-
[16]
Junseok Kim, Nakyeong Yang, Kyungmin Min, and Kyomin Jung. Reliability-aware adaptive self-consistency for efficient sampling in LLM reasoning.arXiv preprint arXiv:2601.02970,
-
[17]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems, volume 35, pages 22199–22213, 2022. 9
2022
-
[18]
HALT-CoT: Model-agnostic early stopping for chain-of-thought reasoning via answer entropy
Yassir Laaouach. HALT-CoT: Model-agnostic early stopping for chain-of-thought reasoning via answer entropy. In4th Muslims in ML Workshop co-located with ICML 2025, 2025. 9
2025
-
[19]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR, 2023. 9
2023
-
[20]
Escape sky-high cost: Early-stopping self-consistency for multi-step reasoning
Yiwei Li, Peiwen Yuan, Shaoxiong Feng, Boyuan Pan, Xinglin Wang, Bin Sun, Heda Wang, and Kan Li. Escape sky-high cost: Early-stopping self-consistency for multi-step reasoning. In International Conference on Learning Representations, 2024. 9
2024
-
[21]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In International Conference on Learning Representations, 2024. 9
2024
-
[22]
Teaching models to express their uncertainty in words.Transactions on Machine Learning Research, 2022
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words.Transactions on Machine Learning Research, 2022. 16
2022
-
[23]
CITE: Anytime-valid statistical inference in LLM self-consistency.arXiv preprint arXiv:2605.05873,
Hirofumi Ota, Naoto Iwase, Yuki Ichihara, Junpei Komiyama, and Masaaki Imaizumi. CITE: Anytime-valid statistical inference in LLM self-consistency.arXiv preprint arXiv:2605.05873,
-
[24]
John C. Platt. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. InAdvances in Large Margin Classifiers, pages 61–74. MIT Press, 1999. 16
1999
-
[25]
Confident adaptive language modeling.Advances in Neural Information Processing Systems, 35:17456–17472, 2022
Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Tran, Yi Tay, and Donald Metzler. Confident adaptive language modeling.Advances in Neural Information Processing Systems, 35:17456–17472, 2022. 9
2022
-
[26]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute op- timally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
-
[27]
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback.arXiv preprint arXiv:2211.14275, 2022. 9
Pith/arXiv arXiv 2022
-
[28]
Sequential tests of statistical hypotheses.The Annals of Mathematical Statistics, 16(2):117–186, 1945
Abraham Wald. Sequential tests of statistical hypotheses.The Annals of Mathematical Statistics, 16(2):117–186, 1945. 9
1945
-
[29]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations, 2023. 2, 6, 9 11
2023
-
[30]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022. 9
2022
-
[31]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[32]
Dynamic early exit in reasoning models.arXiv preprint arXiv:2504.15895, 2025
Chenxu Yang, Qingyi Si, Yongjie Duan, Zheliang Zhu, Chenyu Zhu, Qiaowei Li, Minghui Chen, Zheng Lin, and Weiping Wang. Dynamic early exit in reasoning models.arXiv preprint arXiv:2504.15895, 2025. 9
arXiv 2025
-
[33]
Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023. 9
2023
-
[34]
Generative verifiers: Reward modeling as next-token prediction
Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. Generative verifiers: Reward modeling as next-token prediction. InInternational Conference on Learning Representations, 2025. 9
2025
-
[35]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. Sglang: Efficient execution of structured language model programs. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural I...
2024
-
[36]
Tong Zheng, Chengsong Huang, Runpeng Dai, et al. Parallel-probe: Towards efficient parallel thinking via 2D probing.arXiv preprint arXiv:2602.03845, 2026. 2, 3, 8, 9
arXiv 2026
-
[37]
Least-to-most prompting enables complex reasoning in large language models
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, and Ed Chi. Least-to-most prompting enables complex reasoning in large language models. InInternational Conference on Learning Representations, 2023. 9 12 A Proofs A.1 Margin decomposition Proposition A.1(Margin decompositi...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.