Circuit Synchronization Precedes Generalization: A Causal Precursor to Grokking
Pith reviewed 2026-06-27 07:06 UTC · model grok-4.3
The pith
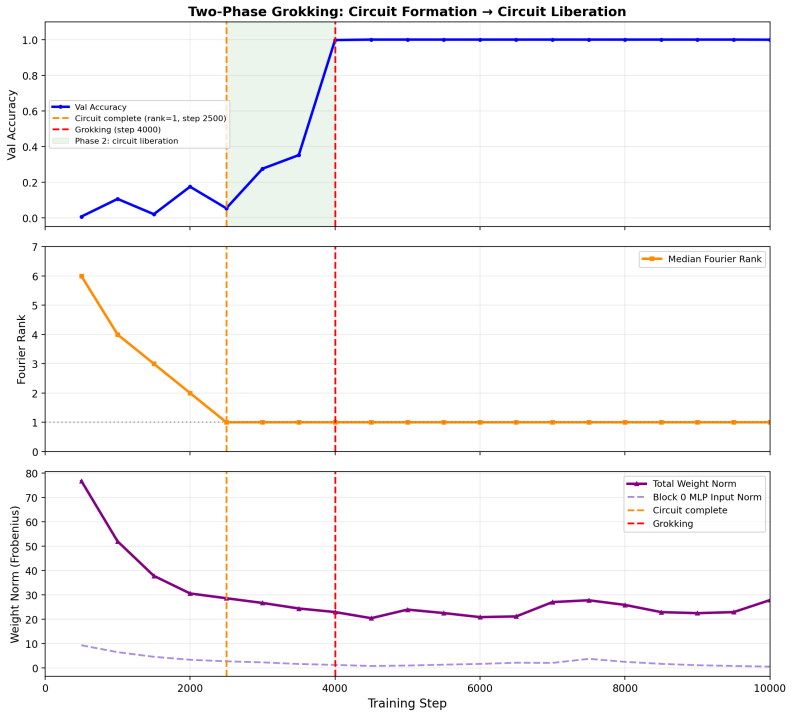
Frequency Synchronization Degree reaches final levels 500-3000 steps before grokking on modular arithmetic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
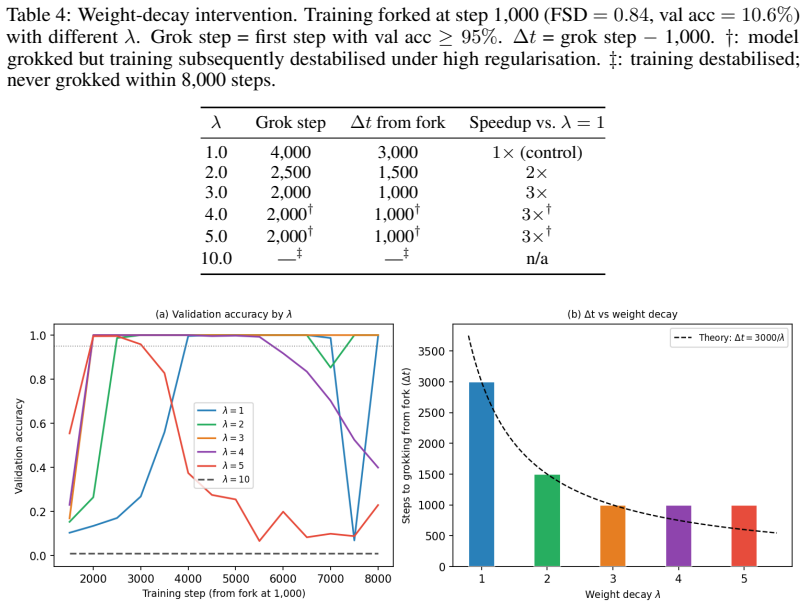
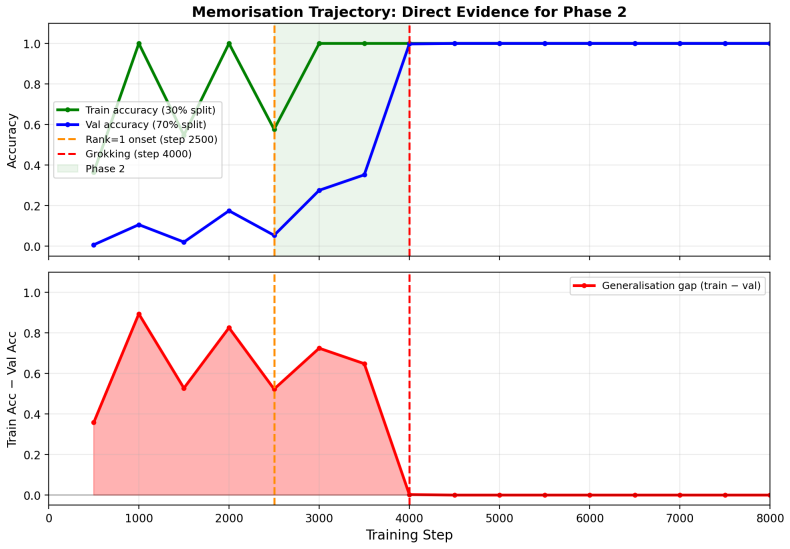
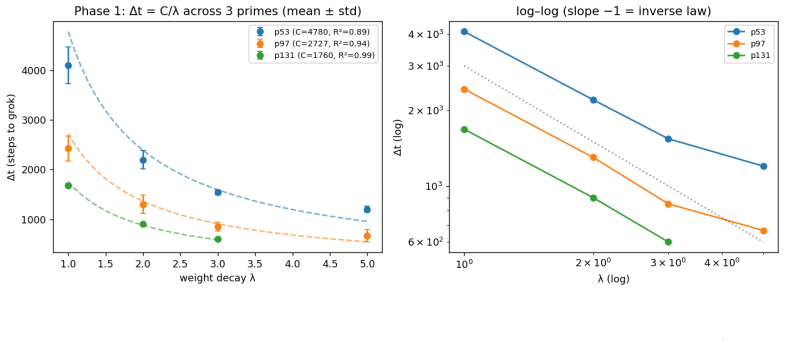
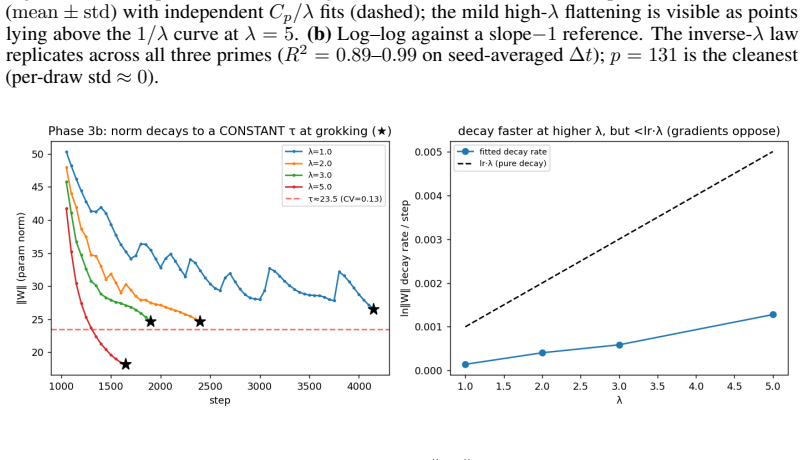
The core discovery is that the Frequency Synchronization Degree, a normalized permutation-tested metric of Fourier-component alignment computed without circuit knowledge, reaches its final value well before the abrupt rise in validation accuracy. Forking at the FSD ceiling and modulating weight decay lambda moves the grokking step forward monotonically, with the time delta scaling as 1/lambda (R-squared 0.89-0.99 on seed averages). Grokking occurs at nearly constant memorization norm across lambda values. A basis-faithful generalization of FSD precedes grokking on S5 while the original Fourier version does not, and FSD-based scheduling of a weight-decay increase accelerates generalization ov
What carries the argument
Frequency Synchronization Degree (FSD), a normalized, permutation-tested scalar that quantifies how tightly the model's weight components align in frequency space.
If this is right
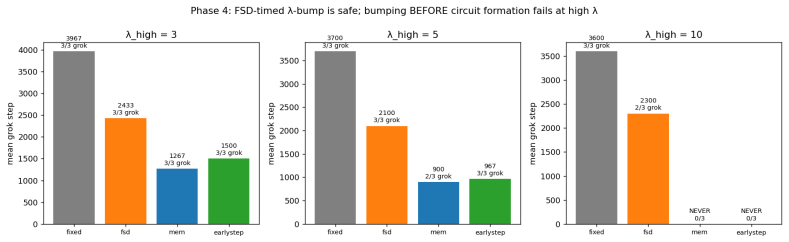
- Grokking timing can be advanced by raising weight decay precisely at the FSD plateau, with larger lambda producing proportionally earlier generalization.
- Generalization occurs once a fixed memorization norm is reached, independent of the particular lambda path taken after the plateau.
- FSD remains an earlier predictor than restricted-logit loss across all nine tested configurations.
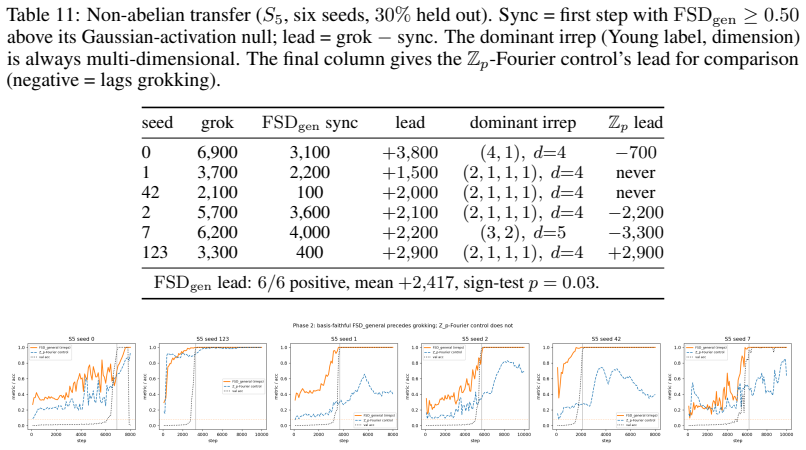
- A generalized FSD detects the precursor even when the task group lacks a simple Fourier basis.
- Scheduling a weight-decay increase at the FSD ceiling accelerates grokking relative to any fixed schedule without destabilizing training.
Where Pith is reading between the lines
- If FSD tracks circuit formation across tasks, monitoring internal frequency alignment could supply an early signal for when generalization will occur in other algorithmic reasoning settings.
- The fixed-norm threshold at grokking points to a geometric mechanism in which the model must reach a particular distance from the origin before the generalizing solution becomes accessible.
- The absence of both grokking and the FSD precursor in MLP-only models suggests that attention layers are required to assemble the synchronizing circuit.
- The method of forking at a detected plateau could be tested as a general technique for accelerating phase transitions in other delayed-generalization problems.
Load-bearing premise
That the FSD metric specifically registers formation of the algorithmic circuit rather than some other training dynamic that happens to coincide with grokking.
What would settle it
Run the forking intervention at the observed FSD ceiling on new moduli or model sizes and check whether the 1/lambda scaling of the grokking delay still appears; if the scaling disappears while FSD still plateaus, the causal link is broken.
Figures


read the original abstract
Grokking is the delayed generalisation phenomenon where a transformer trained on modular arithmetic abruptly transitions from near-chance to near-perfect validation accuracy. It has been attributed to a Fourier-based algorithmic circuit, but its timing, causal structure, and controllability remain poorly understood. We introduce the Frequency Synchronization Degree (FSD), a normalised, permutation-tested metric for Fourier circuit synchronisation requiring no prior knowledge of the circuit. Across nine modular addition configurations (five primes, three seeds), FSD reaches its post-grokking level 500 to 3000 steps before grokking (mean lead 1722 steps, every configuration positive, sign-test p approx 0.004), and synchronises before a restricted-logit loss baseline in all nine cases, making it the earliest available predictor. We give direct causal evidence that the inter-phase gap is a regularisation phenomenon: forking training at the FSD-ceiling step and varying weight decay lambda produces monotonically earlier grokking, with delta-t proportional to 1/lambda. This law replicates across three primes (R-squared 0.89 to 0.99 on seed-averaged delta-t); per-run R-squared is unstable due to the chaotic transition, so we report error bars rather than single runs. Grokking occurs at a near-constant memorisation norm across lambda, grounding the constant in a threshold mechanism. This is not an artefact of applying a Fourier detector to a Fourier circuit: on the non-abelian group S5, a basis-faithful generalisation of FSD precedes grokking on all six seeds, while the original Fourier FSD does not. Using the FSD ceiling to schedule a weight-decay increase also accelerates grokking over a fixed schedule without destabilising training. An attention-only variant groks with a strong FSD precursor while an MLP-only model never groks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Frequency Synchronization Degree (FSD), a permutation-tested metric for detecting Fourier-circuit synchronization in transformers trained on modular arithmetic without prior circuit knowledge. It reports that FSD reaches its post-grokking value 500–3000 steps before grokking (mean lead 1722 steps) across nine configurations (five primes, three seeds), precedes a restricted-logit baseline in all cases, and that forking training at the FSD-ceiling step while varying weight-decay lambda produces monotonically earlier grokking with delta-t proportional to 1/lambda (R² 0.89–0.99 on seed-averaged data across three primes). The work further shows a near-constant memorization-norm threshold at grokking, replicates a basis-faithful FSD variant on the non-abelian group S5, demonstrates acceleration via FSD-scheduled lambda increase, and contrasts attention-only (groks with FSD precursor) versus MLP-only (never groks) models.
Significance. If the central claims hold, the work supplies the earliest known predictor of grokking and the first direct causal evidence that the memorization-to-generalization gap is a regularization phenomenon controllable by weight decay. The explicit intervention experiment, replication across primes, constant-norm grounding, and S5 control (showing FSD is not an artifact of applying a Fourier detector to a Fourier task) are notable strengths. The scheduling result further indicates practical utility for accelerating generalization.
major comments (3)
- [Forking experiment] Forking experiment (results section describing the lambda-variation intervention): no control conditions are reported for forking at the identical FSD-ceiling step without altering lambda, or for applying the lambda change at random steps. Because changing lambda necessarily rescales gradients and alters escape dynamics from the memorization regime, the observed monotonic acceleration (and 1/lambda scaling) could arise from these global trajectory effects rather than from the FSD state specifically enabling faster generalization.
- [Methods and results on FSD ceiling] Definition and application of the FSD-ceiling threshold (methods and results sections): the threshold appears chosen post-hoc to align with the observed ceiling; the manuscript provides neither an a-priori selection rule nor a sensitivity analysis across plausible thresholds. This choice directly determines the forking point and is therefore load-bearing for both the lead-time statistics and the causal claims.
- [Results on delta-t scaling] Reporting of R² values and error bars (results on delta-t scaling): the manuscript relies on seed-averaged R² (0.89–0.99) because per-run transitions are chaotic, yet full per-configuration variance, number of seeds per prime, and exact error-bar construction are not detailed. This weakens the quantitative support for the 1/lambda law that underpins the regularization interpretation.
minor comments (3)
- [Abstract and statistical reporting] The abstract states 'sign-test p approx 0.004' for the lead-time sign test; the exact test statistic, correction for multiple comparisons, and per-configuration p-values should be reported in the main text or supplementary methods.
- [FSD definition] Notation for the normalized FSD metric and its permutation-test procedure is introduced without an explicit equation or pseudocode block; a compact definition would improve reproducibility.
- [Figures] Figure captions for the forking and scheduling experiments should explicitly state the number of seeds and whether shaded regions represent standard error or standard deviation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects of experimental design and reporting. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Forking experiment] Forking experiment (results section describing the lambda-variation intervention): no control conditions are reported for forking at the identical FSD-ceiling step without altering lambda, or for applying the lambda change at random steps. Because changing lambda necessarily rescales gradients and alters escape dynamics from the memorization regime, the observed monotonic acceleration (and 1/lambda scaling) could arise from these global trajectory effects rather than from the FSD state specifically enabling faster generalization.
Authors: We agree that the lack of these control conditions leaves the causal interpretation open to the alternative explanation of global trajectory changes. In the revised manuscript we will add the requested controls: forking at the FSD-ceiling step with lambda held fixed, and applying the same lambda change at randomly selected steps both before and after the FSD ceiling. These additions will allow direct comparison of acceleration attributable to the FSD state versus generic effects of the intervention. revision: yes
-
Referee: [Methods and results on FSD ceiling] Definition and application of the FSD-ceiling threshold (methods and results sections): the threshold appears chosen post-hoc to align with the observed ceiling; the manuscript provides neither an a-priori selection rule nor a sensitivity analysis across plausible thresholds. This choice directly determines the forking point and is therefore load-bearing for both the lead-time statistics and the causal claims.
Authors: We acknowledge that the FSD-ceiling threshold was identified from the observed plateau without an explicit a-priori rule or sensitivity analysis in the submitted manuscript. In revision we will introduce a pre-specified rule (the earliest step at which FSD reaches 95 % of its run-maximum value, subject to a minimum training length) and will include a sensitivity analysis demonstrating that lead-time statistics and the lambda-scaling results remain qualitatively unchanged across a range of nearby thresholds. revision: yes
-
Referee: [Results on delta-t scaling] Reporting of R² values and error bars (results on delta-t scaling): the manuscript relies on seed-averaged R² (0.89–0.99) because per-run transitions are chaotic, yet full per-configuration variance, number of seeds per prime, and exact error-bar construction are not detailed. This weakens the quantitative support for the 1/lambda law that underpins the regularization interpretation.
Authors: We will expand the methods and results sections to specify that three independent seeds were run per prime, that error bars represent the standard deviation of the seed-averaged delta-t values, and that per-configuration variance will be reported explicitly (both numerically and in supplementary plots). While per-run R² values remain unstable owing to the chaotic transition, the seed-averaged scaling law is robust; the added detail will make the quantitative support fully transparent. revision: yes
Circularity Check
No significant circularity: FSD defined independently via permutation testing; causal claim from explicit intervention
full rationale
The paper introduces FSD as a normalised permutation-tested metric requiring no prior circuit knowledge and demonstrates its precedence through direct measurement across configurations, with the causal regularisation claim resting on an explicit forking intervention at the FSD-ceiling step rather than any equation, fit, or self-citation that reduces the timing prediction to the input by construction. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation chain; the S5 control further shows the metric is not tautological to the Fourier case. The result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Modular arithmetic tasks are solved by a Fourier-basis algorithmic circuit inside the transformer.
invented entities (1)
-
Frequency Synchronization Degree (FSD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chughtai, L
B. Chughtai, L. Chan, and N. Nanda. A toy model of universality: Reverse-engineering how networks learn group operations. In International Conference on Machine Learning (ICML), 2023
2023
-
[2]
Conmy, A
A. Conmy, A. Mavor-Parker, A. Lynch, S. Heimersheim, and A. Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability. In Advances in Neural Information Processing Systems (NeurIPS), volume 36, 2023
2023
- [3]
- [4]
-
[5]
Kumar, B
T. Kumar, B. Bordelon, S. J. Gershman, and C. Pehlevan. Grokking as the transition from lazy to rich training dynamics. In International Conference on Learning Representations (ICLR), 2024
2024
- [6]
-
[7]
K. Meng, D. Bau, A. Andonian, and Y. Belinkov. Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems (NeurIPS), volume 35, 2022
2022
-
[8]
W. Merrill, N. Tsilivis, and A. Shukla. A tale of two circuits: Grokking as competition of sparse and dense subnetworks. arXiv preprint arXiv:2303.11873, 2023
-
[9]
Olsson, N
C. Olsson, N. Elhage, N. Nanda, N. Joseph, N. DasSarma, T. Henighan, B. Mann, A. Askell, Y. Bai, A. Chen, et al. In-context learning and induction heads. Transformer Circuits Thread, 2022
2022
-
[10]
Stander, Q
D. Stander, Q. Yu, H. Fan, and S. Biderman. Grokking group multiplication with cosets. In International Conference on Machine Learning (ICML), 2024
2024
- [11]
-
[12]
Zhong, Z
Z. Zhong, Z. Liu, M. Tegmark, and J. Andreas. The clock and the pizza: Two stories in mechanistic explanation of neural networks. In Advances in Neural Information Processing Systems (NeurIPS), volume 36, 2023
2023
-
[13]
Elhage, N
N. Elhage, N. Nanda, C. Olsson, T. Henighan, N. Joseph, B. Mann, A. Askell, Y. Bai, A. Chen, T. Conerly, N. DasSarma, D. Drain, D. Ganguli, Z. Hatfield-Dodds, D. Hernandez, A. Jones, J. Kernion, L. Lovitt, K. Ndousse, D. Amodei, T. Brown, J. Clark, J. Kaplan, S. McCandlish, and C. Olah. A mathematical framework for transformer circuits. Transformer Circui...
2021
-
[14]
Barak, B
B. Barak, B. Edelman, S. Goel, S. Kakade, E. Malach, and C. Zhang. Hidden progress in deep learning: SGD learns parities near the computational limit. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, 2022
2022
-
[15]
Geiger, H
A. Geiger, H. Lu, T. Icard, and C. Potts. Causal abstractions of neural networks. In Advances in Neural Information Processing Systems (NeurIPS), volume 34, 2021
2021
-
[16]
Z. Liu, Z. Zhu, and M. Tegmark. Towards understanding grokking: An effective theory of representation learning. In NeurIPS, volume 35, 2022
2022
-
[17]
Z. Liu, E. J. Michaud, and M. Tegmark. Omnigrok: Grokking beyond algorithmic data. In International Conference on Learning Representations (ICLR), 2023
2023
-
[18]
Z. Liu, Y. Wang, S. Vaidya, F. Ruehle, J. Halverson, M. Soljacic, T. Y. Hou, and M. Tegmark. KAN : Kolmogorov-Arnold networks. arXiv preprint arXiv:2404.19756, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Nanda, L
N. Nanda, L. Chan, T. Lieberum, J. Smith, and J. Steinhardt. Progress measures for grokking via mechanistic interpretability. In International Conference on Learning Representations (ICLR), 2023
2023
-
[20]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
A. Power, Y. Burda, H. Edwards, I. Babuschkin, and V. Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv preprint arXiv:2201.02177, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Rahaman, A
N. Rahaman, A. Baratin, D. Arpit, F. Draxler, M. Lin, F. Hamprecht, Y. Bengio, and A. Courville. On the spectral bias of neural networks. In International Conference on Machine Learning (ICML), 2019
2019
-
[22]
Explaining grokking through circuit efficiency.arXiv preprint arXiv:2309.02390, 2023
V. Varma, R. Shah, Z. Kenton, J. Kram\'ar, and R. Kumar. Explaining grokking through circuit efficiency. arXiv preprint arXiv:2309.02390, 2023
-
[23]
K. Wang, A. Variengien, A. Conmy, B. Shlegeris, and J. Steinhardt. Interpretability in the wild: A circuit for indirect object identification in GPT -2 small. In ICLR, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.