Multi-Modal Agents for Power Distribution Defect Detection: An Evaluation of Foundation Models
Pith reviewed 2026-06-27 06:52 UTC · model grok-4.3
The pith
Foundation models show strengths and limits when used as multi-modal agents for power distribution defect detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
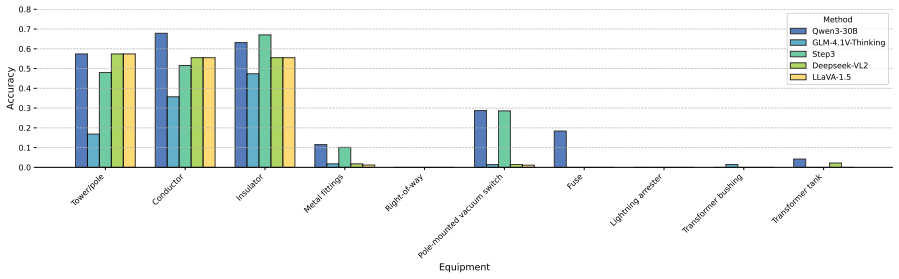
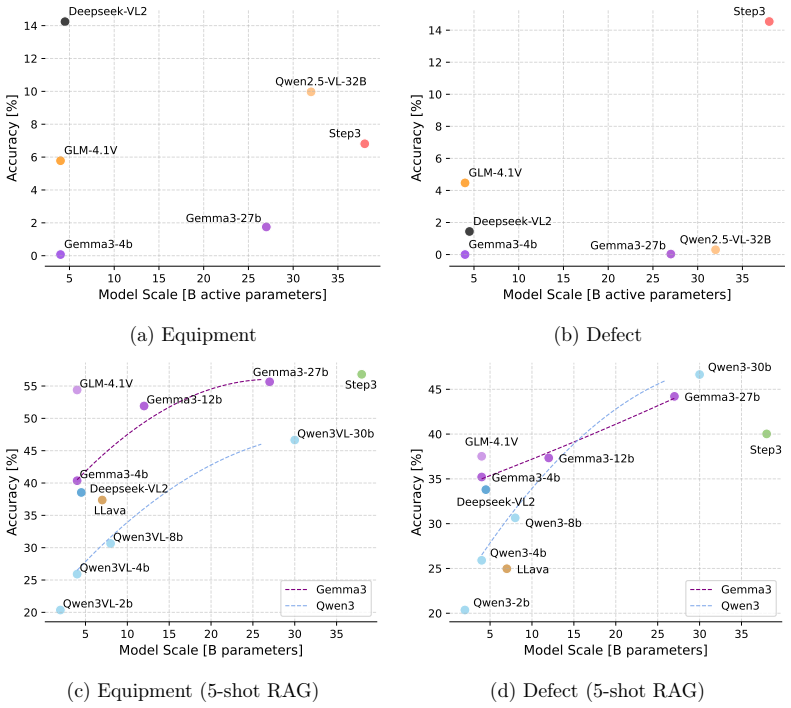
Systematic evaluation of multimodal foundation models as unified engines for perception, reasoning, and tool usage in power distribution defect detection yields empirical evidence on their readiness for autonomous agents in high-stakes industrial settings, supported by a custom dataset and benchmark.
What carries the argument
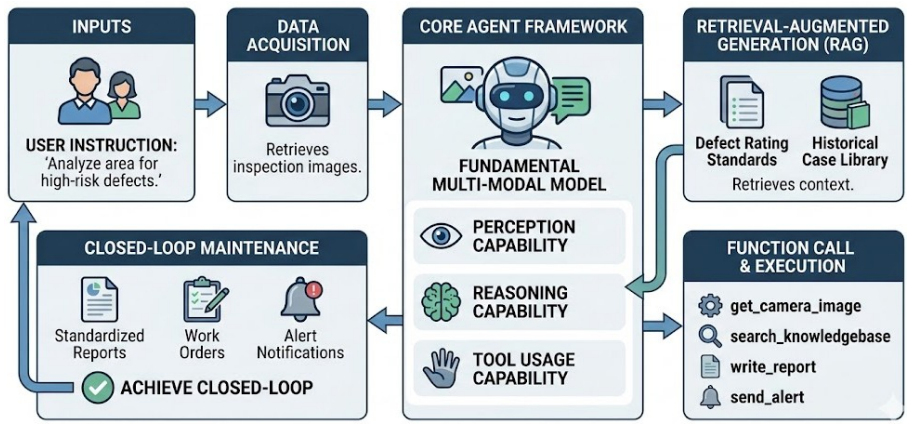
The multi-modal agent framework that requires models to combine visual perception of defects, domain-knowledge reasoning for diagnosis, and tool calls for maintenance actions.
If this is right
- Models can generate expert-level defect descriptions from images as a starting point for automation.
- Reasoning performance indicates how well models translate visual findings into maintenance plans.
- Tool usage capability shows potential for agents to query knowledge bases and produce work orders without human intervention.
- The benchmark supplies a concrete testbed for measuring progress toward autonomous industrial agents.
Where Pith is reading between the lines
- The same three-capability structure could be reused to benchmark agents for other utility networks such as gas pipelines or rail infrastructure.
- Identified gaps in reasoning or tool use may be addressable by adding domain-specific training examples rather than scaling model size alone.
- Successful closed-loop agents would shift inspection from periodic human patrols to continuous monitoring with automated response.
Load-bearing premise
The custom evaluation dataset and benchmark accurately represent real-world power distribution conditions and model results on them will generalize to closed-loop use in operational grids.
What would settle it
Running the best models from the benchmark on live operational power grid imagery and comparing their end-to-end defect detection accuracy, diagnosis correctness, and work-order generation against experienced human inspectors.
Figures

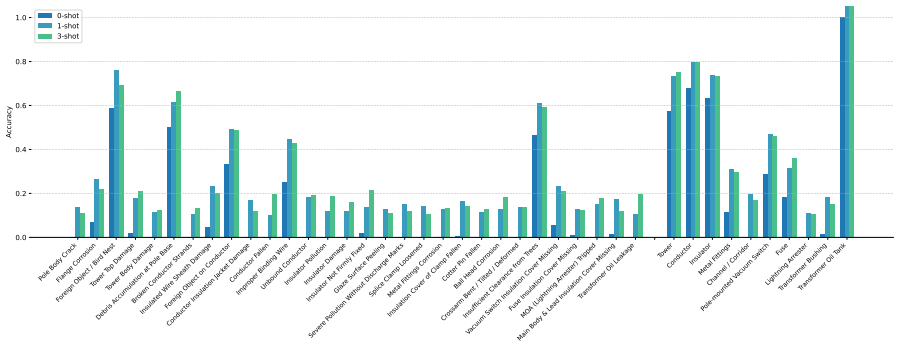
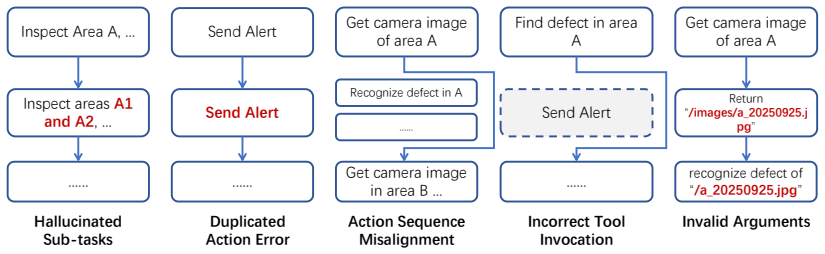
read the original abstract
The power distribution network is critical to reliable electricity delivery, yet traditional inspection methods face limitations in semantic understanding, generalization, and closed-loop automation. To address these challenges, this paper proposes a Multi-Modal Agent framework specifically for power distribution defect detection. Central to this study is the systematic evaluation of multimodal foundation models as unified cognitive engines. We rigorously assess their integrated performance across three critical capabilities: (1) Perception, where the model must accurately identify equipment and generate expert-level descriptions of defects; (2) Reasoning, where the model interprets visual findings to diagnose causes, assess severity, and plan maintenance strategies based on domain knowledge; and (3) Tool Usage, where the model acts as an autonomous operator to execute actions -- such as querying knowledge bases or generating work orders -- to achieve closed-loop maintenance. To support this evaluation, a domain-specific evaluation dataset and a comprehensive benchmark are developed. Experimental results demonstrate the strengths and limitations of current foundation models in these three dimensions, providing empirical evidence for deploying autonomous agents in high-stakes industrial environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Multi-Modal Agent framework for power distribution defect detection and systematically evaluates multimodal foundation models on three capabilities—perception (equipment identification and defect description), reasoning (cause diagnosis, severity assessment, and maintenance planning), and tool usage (autonomous actions such as knowledge-base queries and work-order generation)—using a newly developed domain-specific dataset and benchmark. It asserts that the resulting experiments demonstrate model strengths and limitations and supply empirical evidence for deploying such agents in high-stakes industrial environments.
Significance. If the quantitative results prove robust and the benchmark is shown to be representative, the work would supply a useful empirical baseline on the current limits of off-the-shelf multimodal models for industrial inspection tasks and could guide targeted improvements in perception, reasoning, and closed-loop tool use. The creation of a domain-specific benchmark itself is a constructive step that future studies could build upon.
major comments (2)
- [Abstract] Abstract: the central claim that 'experimental results demonstrate the strengths and limitations' and 'provide empirical evidence for deploying autonomous agents in high-stakes industrial environments' is load-bearing, yet the abstract supplies no quantitative results, error bars, dataset statistics, or baseline comparisons, leaving the evidential foundation unassessable.
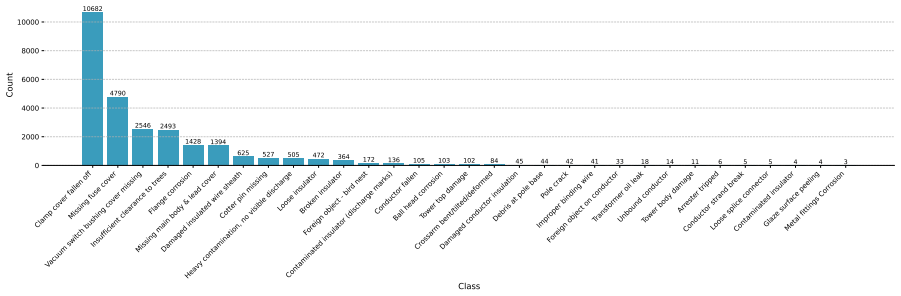
- [Dataset and benchmark description] Dataset and benchmark description (presumably §3 or §4): the claim that the evaluation supplies evidence for operational-grid deployment rests on the assumption that the custom dataset faithfully captures real-world defect distributions, environmental conditions, and failure modes. No external cross-validation against utility records or live-grid telemetry is described, leaving the proxy quality of the benchmark unsecured.
minor comments (1)
- [Abstract] The abstract would be strengthened by the inclusion of at least one key quantitative finding (e.g., accuracy or success rate on each of the three capabilities) to support the stated conclusions.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which help improve the clarity and rigor of our work. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'experimental results demonstrate the strengths and limitations' and 'provide empirical evidence for deploying autonomous agents in high-stakes industrial environments' is load-bearing, yet the abstract supplies no quantitative results, error bars, dataset statistics, or baseline comparisons, leaving the evidential foundation unassessable.
Authors: We agree with this observation. The revised abstract will incorporate key quantitative results, including dataset size, main performance metrics for perception, reasoning, and tool usage tasks, and comparisons to relevant baselines to better support the claims. revision: yes
-
Referee: [Dataset and benchmark description] Dataset and benchmark description (presumably §3 or §4): the claim that the evaluation supplies evidence for operational-grid deployment rests on the assumption that the custom dataset faithfully captures real-world defect distributions, environmental conditions, and failure modes. No external cross-validation against utility records or live-grid telemetry is described, leaving the proxy quality of the benchmark unsecured.
Authors: We acknowledge that no external cross-validation is provided. The dataset was curated with guidance from power distribution experts to mirror typical defect scenarios and conditions encountered in the field. In the revision, we will expand the dataset description section to detail the curation methodology, expert involvement, and any available statistics on defect distributions. We will also explicitly note the limitations regarding live data validation, which is often restricted by operational and privacy considerations in the industry. revision: partial
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper conducts an empirical evaluation of off-the-shelf multimodal foundation models on perception, reasoning, and tool usage for power distribution defect detection, supported by a newly developed domain-specific dataset and benchmark. No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. Central claims rest on direct experimental results rather than any self-definitional reductions, self-citation chains, or renamings of known results. The work is therefore self-contained with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning Transferable Visual Models From Natural Language Supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning Transferable Visual Models From Natural Language Supervision,” inProceedings of the 38th International Conference on Machine Learning. PMLR, Jul. 2021, pp. 8748–8763. [Online]. Available: https://proceedings...
2021
-
[2]
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision,
C. Jia, Y. Yang, Y. Xia, Y.-T. Chen, Z. Parekh, H. Pham, Q. Le, Y.-H. Sung, Z. Li, and T. Duerig, “Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision,” inProceedings of the 38th International Conference on Machine Learning. PMLR, Jul. 2021, pp. 4904–4916. [Online]. Available: https://proceedings.mlr.press/v139/jia21b.html
2021
-
[3]
Blip: Bootstrapping language-image pre- training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre- training for unified vision-language understanding and generation,” inInternational conference on machine learning. PMLR, 2022, pp. 12888–12900. [Online]. Available: https://proceedings.mlr.press/v162/li22n.html
2022
-
[4]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19730–19742
2023
-
[5]
In- structBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning,
W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, and S. Hoi, “In- structBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning,” arXiv preprint arXiv:2305.06500, 2023
Pith/arXiv arXiv 2023
-
[6]
Flamingo: a visual language model for few-shot learning,
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, and M. Reynolds, “Flamingo: a visual language model for few-shot learning,”Advances in neural information processing systems, vol. 35, pp. 23716–23736,
-
[7]
Available: https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 960a172bc7fbf0177ccccbb411a7d800-Abstract-Conference.html
[Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 960a172bc7fbf0177ccccbb411a7d800-Abstract-Conference.html
2022
-
[8]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,”Ad- vances in neural information processing systems, vol. 36, pp. 34892–34916,
-
[9]
Available: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 6dcf277ea32ce3288914faf369fe6de0-Abstract-Conference.html 13
[Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 6dcf277ea32ce3288914faf369fe6de0-Abstract-Conference.html 13
2023
-
[10]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models,
D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models,” Oct. 2023, arXiv:2304.10592 [cs]. [Online]. Available: http://arxiv.org/abs/2304.10592
Pith/arXiv arXiv 2023
-
[11]
Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution,
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Geet al., “Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution,” arXiv preprint arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[12]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day,
C. Li, C. Wong, S. Zhang, N. Usuyama, H. Liu, J. Yang, T. Naumann, H. Poon, and J. Gao, “Llava-med: Training a large language-and-vision assistant for biomedicine in one day,”Advances in Neural Information Processing Systems, vol. 36, pp. 28541–28564,
-
[13]
Available: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 5abcdf8ecdcacba028c6662789194572-Abstract-Datasets_and_Benchmarks.html
[Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 5abcdf8ecdcacba028c6662789194572-Abstract-Datasets_and_Benchmarks.html
2023
-
[14]
Drivelm: Driving with graph visual question answering,
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li, “Drivelm: Driving with graph visual question answering,” inEuropean conference on computer vision. Springer, 2024, pp. 256–274
2024
-
[15]
Science China Information Sciences , year=
Z. Xi, W. Chen, X. Guo, W. He, Y. Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhou, R. Zheng, X. Fan, X. Wang, L. Xiong, Y. Zhou, W. Wang, C. Jiang, Y. Zou, X. Liu, Z. Yin, S. Dou, R. Weng, W. Qin, Y. Zheng, X. Qiu, X. Huang, Q. Zhang, and T. Gui, “The rise and potential of large language model based agents: a survey,”Science China Information Sciences, ...
-
[16]
doi: 10.1007/s11704-024-40231-1
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y. Lin, W. X. Zhao, Z. Wei, and J. Wen, “A survey on large language model based autonomous agents,”Frontiers of Computer Science, vol. 18, no. 6, p. 186345, Dec. 2024. [Online]. Available: https://link.springer.com/10.1007/s11704-024-40231-1
-
[17]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative Agents: Interactive Simulacra of Human Behavior,” inProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. San Francisco CA USA: ACM, Oct. 2023, pp. 1–22. [Online]. Available: https://dl.acm.org/doi/10.1145/3586183.3606763
-
[18]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,” inThe eleventh international conference on learning representations, 2022. [Online]. Available: https: //openreview.net/forum?id=WE_vluYUL-X
2022
-
[19]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24824– 24837, 2022. [Online]. Available: https://proceedings.neurips.cc/paper/2022/hash/ 9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html
2022
-
[20]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in Neural Information Processing Systems, vol. 36, pp. 68539–68551,
-
[21]
Available: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ d842425e4bf79ba039352da0f658a906-Abstract-Conference.html
[Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ d842425e4bf79ba039352da0f658a906-Abstract-Conference.html
2023
-
[22]
Surv.57, 4 (2025), 101:1–101:40
Y. Qin, S. Hu, Y. Lin, W. Chen, N. Ding, G. Cui, Z. Zeng, X. Zhou, Y. Huang, C. Xiao, C. Han, Y. R. Fung, Y. Su, H. Wang, C. Qian, R. Tian, K. Zhu, S. Liang, X. Shen, B. Xu, Z. Zhang, Y. Ye, B. Li, Z. Tang, J. Yi, Y. Zhu, Z. Dai, L. Yan, X. Cong, Y. Lu, W. Zhao, 14 Y. Huang, J. Yan, X. Han, X. Sun, D. Li, J. Phang, C. Yang, T. Wu, H. Ji, G. Li, Z. Liu, an...
-
[23]
Applying Large Language Models for intelligent industrial automation,
Y. Xia, N. Jazdi, and M. Weyrich, “Applying Large Language Models for intelligent industrial automation,”atp magazin, vol. 66, no. 6–7, pp. 62–71, 2024. [Online]. Available: https://atpinfo.de/wp-content/uploads/2025/04/xia.pdf
2024
-
[24]
Large Language Models integration in Smart Grids,
S. Madani, A. Tavasoli, Z. K. Astaneh, and P.-O. Pineau, “Large Language Models integration in Smart Grids,” Apr. 2025, arXiv:2504.09059 [cs]. [Online]. Available: http://arxiv.org/abs/2504.09059
arXiv 2025
-
[25]
Autonomous industrial control using an agentic framework with large language models,
J. Vyas and M. Mercangöz, “Autonomous industrial control using an agentic framework with large language models,”IFAC-PapersOnLine, vol. 59, no. 6, pp. 349–354, 2025
2025
-
[26]
Gridmind: Llms-powered agents for power system analysis and operations,
H. Jin, K. Kim, and J. Kwon, “Gridmind: Llms-powered agents for power system analysis and operations,” inProceedings of the SC’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2025, pp. 560–568
2025
-
[27]
Llm-mtmp: A large language model-based multi-agent task and motion planning framework for power inspection robots,
Z. Wang, X. Zhou, J. Mao, C. Zhang, C. Cui, and J. Yang, “Llm-mtmp: A large language model-based multi-agent task and motion planning framework for power inspection robots,” Journal of Industrial Information Integration, p. 101014, 2025
2025
-
[28]
Large multimodal agents: a survey,
J. Xie, Z. Chen, R. Zhang, and G. Li, “Large multimodal agents: a survey,” Visual Intelligence, vol. 3, no. 1, p. 24, Dec. 2025. [Online]. Available: https: //link.springer.com/10.1007/s44267-025-00093-y
-
[29]
Evaluation and benchmarking of LLM agents: A survey
M. Mohammadi, Y. Li, J. Lo, and W. Yip, “Evaluation and Benchmarking of LLM Agents: A Survey,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2. Toronto ON Canada: ACM, Aug. 2025, pp. 6129–6139. [Online]. Available: https://dl.acm.org/doi/10.1145/3711896.3736570
-
[30]
Survey on Evaluation of LLM-based Agents,
A. Yehudai, L. Eden, A. Li, G. Uziel, Y. Zhao, R. Bar-Haim, A. Cohan, and M. Shmueli- Scheuer, “Survey on Evaluation of LLM-based Agents,” Mar. 2025, arXiv:2503.16416 [cs]. [Online]. Available: http://arxiv.org/abs/2503.16416
Pith/arXiv arXiv 2025
-
[31]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi,
X. Yue, Y. Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y. Sunet al., “Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 9556–9567
2024
-
[32]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives,
K. Grauman, A. Westbury, L. Torresani, K. Kitani, J. Malik, T. Afouras, K. Ashutosh, V. Baiyya, S. Bansal, B. Booteet al., “Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19383–19400
2024
-
[33]
Gaia: a benchmark for general ai assistants,
G. Mialon, C. Fourrier, T. Wolf, Y. LeCun, and T. Scialom, “Gaia: a benchmark for general ai assistants,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[34]
Mind2web: Towards a generalist agent for the web,
X. Deng, Y. Gu, B. Zheng, S. Chen, S. Stevens, B. Wang, H. Sun, and Y. Su, “Mind2web: Towards a generalist agent for the web,”Advances in Neural Information Processing Sys- tems, vol. 36, pp. 28091–28114, 2023
2023
-
[35]
Agentvista: Evaluating multimodal agents in ultra-challenging realistic visual scenarios,
Z.Su, J.Gao, H.Guo, Z.Liu, L.Zhang, X.Geng, S.Huang, P.Xia, G.Jiang, C.Wanget al., “Agentvista: Evaluating multimodal agents in ultra-challenging realistic visual scenarios,” arXiv preprint arXiv:2602.23166, 2026. 15
arXiv 2026
-
[36]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” inProceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318
2002
-
[37]
Rouge: A package for automatic evaluation of summaries,
C.-Y. Lin, “Rouge: A package for automatic evaluation of summaries,” inText summariza- tion branches out, 2004, pp. 74–81
2004
-
[38]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[39]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging llm-as-a-judge with mt-bench and chatbot arena,”Advances in neural information processing systems, vol. 36, pp. 46595–46623, 2023
2023
-
[40]
Evaluating object halluci- nation in large vision-language models,
Y. Li, Y. Du, K. Zhou, J. Wang, W. X. Zhao, and J.-R. Wen, “Evaluating object halluci- nation in large vision-language models,” inProceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 292–305
2023
-
[41]
Object hallucination in image captioning,
A. Rohrbach, L. A. Hendricks, K. Burns, T. Darrell, and K. Saenko, “Object hallucination in image captioning,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 4035–4045
2018
-
[42]
Agentbench: Evaluating llms as agents,
X. Liu, H. Yu, H. Zhang, Y. Xu, X. Lei, H. Lai, Y. Gu, H. Ding, K. Men, K. Yanget al., “Agentbench: Evaluating llms as agents,”arXiv preprint arXiv:2308.03688, 2023
Pith/arXiv arXiv 2023
-
[43]
Ensemble of mrr and ndcg models for visual dialog,
I. Schwartz, “Ensemble of mrr and ndcg models for visual dialog,” inProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, 2021, pp. 3272–3363
2021
-
[44]
Mind the sim2real gap in user simulation for agentic tasks,
X. Zhou, W. Sun, Q. Ma, Y. Xie, J. Liu, W. Du, S. Welleck, Y. Yang, G. Neubig, S. T. Wuet al., “Mind the sim2real gap in user simulation for agentic tasks,”arXiv preprint arXiv:2603.11245, 2026
arXiv 2026
-
[45]
Let’s verify step by step,
H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schul- man, I. Sutskever, and K. Cobbe, “Let’s verify step by step,” inThe twelfth international conference on learning representations, 2023
2023
-
[46]
Hindsight credit assignment for long-horizon llm agents,
H.-Z. Tan, X.-W. Yang, H. Chen, J.-J. Shao, Y. Wen, Y. Shen, W. Luo, X. Du, L.-Z. Guo, and Y.-F. Li, “Hindsight credit assignment for long-horizon llm agents,”arXiv preprint arXiv:2603.08754, 2026
arXiv 2026
-
[47]
J. Liu, B. Chen, and C. Zhang, “Speculative prefill: Turbocharging ttft with lightweight and training-free token importance estimation,”arXiv preprint arXiv:2502.02789, 2025. 16
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.