Otters++: A Time-to-first-spike Based Energy Efficient Optical Spiking Transformer
Pith reviewed 2026-06-27 06:40 UTC · model grok-4.3
The pith
Otters++ replaces digital decay calculations with physical In₂O₃ synapse decay to enable energy-efficient TTFS spiking transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
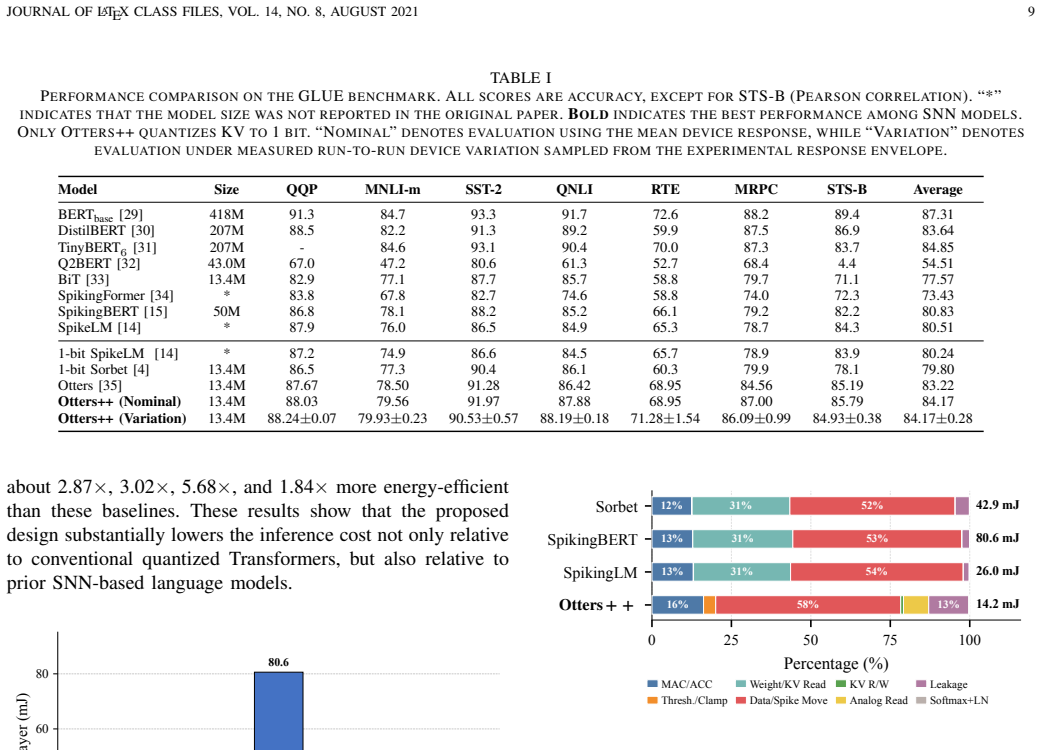
By using the measured decay curve of an In₂O₃ optoelectronic synapse as the TTFS temporal term, Otters++ eliminates explicit digital decay computation; a hybrid training procedure that equates the SNN layer to a quantized network for gradients, combined with device-noise sampling, produces Transformer models that achieve 84.17 percent average GLUE score with lower energy than prior spiking baselines.
What carries the argument
Layer-wise functional equivalence between the Otters++ SNN and an equivalent quantized network, used to route straight-through gradients and distillation around the non-differentiable first-spike events.
If this is right
- Spiking Transformers become trainable at scale without the usual gradient problems of direct TTFS coding.
- Energy accounting must include device sharing and multi-hop optical communication to remain realistic.
- Run-to-run device variation can be mitigated by sampling it during training rather than post-hoc correction.
- The same physical-decay substitution could be applied to other TTFS layers if their decay profiles match the model.
Where Pith is reading between the lines
- If the physical decay remains stable across temperature or aging, the method could reduce the need for per-layer digital calibration circuits.
- The QNN-equivalence trick may generalize to other discrete spiking encodings that lack direct gradients.
- Larger models could see amplified energy gains if the per-synapse savings scale linearly with parameter count.
Load-bearing premise
The measured decay curve of the custom In₂O₃ optoelectronic synapse can be used directly as the TTFS temporal decay term across all layers of a scaled transformer without introducing unmodeled mismatch or extra digital overhead.
What would settle it
Running the trained Otters++ model on physical In₂O₃ hardware and observing either accuracy falling below 80 percent on GLUE or total energy exceeding that of the best prior digital TTFS baseline would falsify the central claim.
Figures



read the original abstract
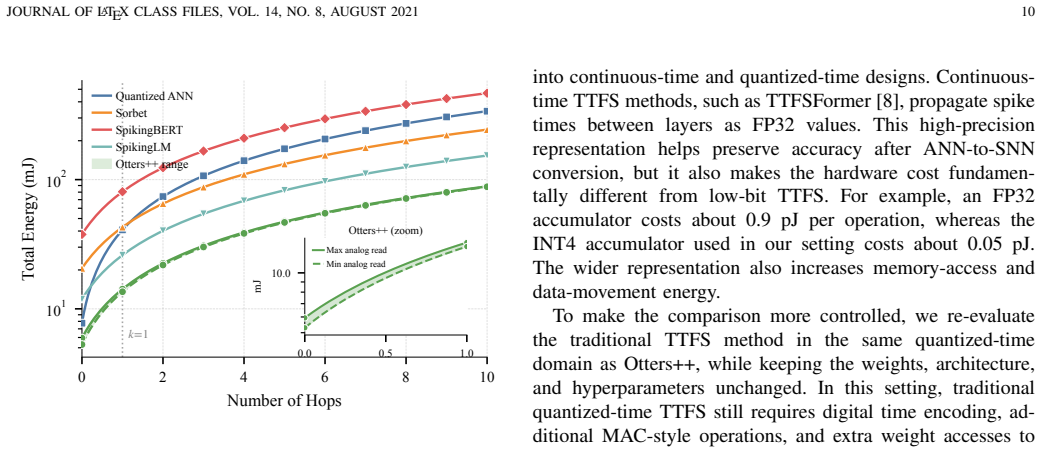
Spiking neural networks (SNNs) are promising for energy-efficient inference, and time-to-first-spike (TTFS) coding is especially attractive because each neuron fires at most once. In practice, however, this benefit is often reduced by the cost of computing a temporal decay term and multiplying it by the synaptic weight. We address this issue by turning a physical hardware "bug," the natural signal decay in optoelectronic devices, into the main computation of TTFS, named Otters++. Specifically, we use the measured decay of a custom In$_2$O$_3$ optoelectronic synapse to directly realize the TTFS temporal term, removing the need for explicit digital decay computation. To scale this idea to Transformer models, we establish a layer-wise functional equivalence between the Otters++ and a quantized neural network (QNN), and develop a hybrid training method that uses device-faithful SNN computation in the forward pass and QNN straight-through gradients through the equivalent QNN path in the backward pass, together with model distillation. This avoids differentiation through discrete first-spike events and reduces the over-sparsity problem in direct TTFS-SNN training. We further make training aware of measured device noise by sampling run-to-run variation, and refine the system-level energy model by accounting for device sharing and multi-hop communication. On GLUE dataset, Otters++ improves the average score to 84.17\% while maintaining a clear energy advantage over prior spiking Transformer baselines. These results show that physically grounded TTFS computing can be efficient, trainable, and robust under realistic hardware effects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Otters++, a TTFS-based optical spiking transformer that directly uses the measured natural decay of a custom In₂O₃ optoelectronic synapse to implement the temporal decay term, eliminating explicit digital computation. It establishes a layer-wise functional equivalence to a QNN to enable hybrid training (device-faithful SNN forward pass, QNN straight-through gradients in backward pass, plus distillation), samples run-to-run device variation during training, and refines the system energy model for device sharing and multi-hop effects. On GLUE it reports an average score of 84.17% while claiming energy advantages over prior spiking Transformer baselines.
Significance. If the direct substitution of the single measured decay curve and the layer-wise equivalence hold without unmodeled mismatch or extra overhead, the work would be significant for energy-efficient optical neuromorphic hardware, as it turns a device physics effect into the core computation and provides a practical training pathway for scaled TTFS transformers. The hybrid training method and noise-aware refinement are concrete strengths that address known TTFS training difficulties.
major comments (3)
- [Abstract] Abstract: the central claim that the measured In₂O₃ decay curve can be substituted directly for the TTFS temporal term across all layers of a scaled transformer rests on an unverified assumption of no device-to-device mismatch or multi-hop effects; no per-layer equivalence error metrics, sensitivity analysis, or variation impact on GLUE scores are supplied, which is load-bearing for both the accuracy and energy-advantage assertions.
- [Abstract] Abstract: the hybrid training method is described at a high level (device-faithful forward + QNN straight-through backward + distillation) but supplies no quantitative verification that the layer-wise equivalence mapping remains accurate once device noise sampling is introduced, undermining confidence that the reported 84.17% GLUE score is achieved under the actual hardware model.
- [Abstract] Abstract: the GLUE average of 84.17% is stated without error bars, standard deviations across runs, or ablation showing the effect of the device-variation sampling procedure, making it impossible to assess whether the result is robust or sensitive to the core hardware assumption.
minor comments (2)
- Notation for the optoelectronic synapse decay should be defined once with a clear symbol (e.g., τ_device) and used consistently when contrasting with the digital decay term.
- A diagram or table explicitly mapping the QNN equivalent operations to the optical TTFS operations per layer would improve readability of the equivalence claim.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of the work's significance and for the constructive feedback. We address each of the major comments below and will update the manuscript to incorporate additional analyses and reporting as needed.
read point-by-point responses
-
Referee: [Abstract] the central claim that the measured In₂O₃ decay curve can be substituted directly for the TTFS temporal term across all layers of a scaled transformer rests on an unverified assumption of no device-to-device mismatch or multi-hop effects; no per-layer equivalence error metrics, sensitivity analysis, or variation impact on GLUE scores are supplied, which is load-bearing for both the accuracy and energy-advantage assertions.
Authors: We agree that explicit metrics would strengthen the manuscript. In the revised version, we will add per-layer equivalence error metrics comparing the device decay to the TTFS model, a sensitivity analysis to device-to-device mismatch and multi-hop effects, and an evaluation of how variation impacts the reported GLUE scores. These additions will directly address the load-bearing assumptions for the accuracy and energy claims. revision: yes
-
Referee: [Abstract] the hybrid training method is described at a high level (device-faithful forward + QNN straight-through backward + distillation) but supplies no quantitative verification that the layer-wise equivalence mapping remains accurate once device noise sampling is introduced, undermining confidence that the reported 84.17% GLUE score is achieved under the actual hardware model.
Authors: We will provide quantitative verification in the revision, including measurements of the equivalence error with and without device noise sampling during training. This will confirm that the hybrid training maintains accuracy under the hardware model used for the 84.17% GLUE result. revision: yes
-
Referee: [Abstract] the GLUE average of 84.17% is stated without error bars, standard deviations across runs, or ablation showing the effect of the device-variation sampling procedure, making it impossible to assess whether the result is robust or sensitive to the core hardware assumption.
Authors: The revised manuscript will include error bars and standard deviations for the GLUE scores across multiple runs, along with an ablation study isolating the effect of the device-variation sampling. This will allow assessment of robustness to the hardware assumptions. revision: yes
Circularity Check
No circularity; central claims rest on external device measurements and QNN equivalence mapping
full rationale
The paper grounds its TTFS temporal term directly in measured In₂O₃ optoelectronic synapse decay (an external hardware input) and establishes layer-wise functional equivalence to a separate QNN for hybrid training. Neither step defines a quantity in terms of itself nor renames a fitted parameter as a prediction. No self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text. The GLUE result follows from training under the stated device-faithful forward pass, not from any definitional reduction. This is the common case of a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- device decay parameters
axioms (1)
- domain assumption Layer-wise functional equivalence between Otters++ SNN and quantized NN holds for both forward and backward passes
invented entities (1)
-
custom In₂O₃ optoelectronic synapse
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Pushing large language models to the 6g edge: Vision, challenges, and opportunities,
Z. Lin, G. Qu, Q. Chen, X. Chen, Z. Chen, and K. Huang, “Pushing large language models to the 6g edge: Vision, challenges, and opportunities,” arXiv preprint arXiv:2309.16739, 2023
-
[2]
How hungry is ai? benchmarking energy, water, and carbon footprint of llm inference,
N. Jegham, M. Abdelatti, L. Elmoubarki, and A. Hendawi, “How hungry is ai? benchmarking energy, water, and carbon footprint of llm inference,”arXiv preprint arXiv:2505.09598, 2025
-
[3]
Spikellm: Scaling up spiking neural network to large language models via saliency-based spiking,
X. Xing, B. Gao, Z. Zhang, D. A. Clifton, S. Xiao, L. Du, G. Li, and J. Zhang, “Spikellm: Scaling up spiking neural network to large language models via saliency-based spiking,”arXiv preprint arXiv:2407.04752, 2024
-
[4]
Sorbet: A neuromorphic hardware- compatible transformer-based spiking language model,
K. Tang, Z. Yan, and W.-F. Wong, “Sorbet: A neuromorphic hardware- compatible transformer-based spiking language model,” inForty-second International Conference on Machine Learning, 2025
2025
-
[5]
Lite-snn: designing lightweight and efficient spiking neural network through spatial-temporal compressive network search and joint optimization,
Q. Liu, J. Yan, M. Zhang, G. Pan, and H. Li, “Lite-snn: designing lightweight and efficient spiking neural network through spatial-temporal compressive network search and joint optimization,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, 2024, pp. 3097–3105
2024
-
[6]
Human-inspired computing for robust and efficient audio-visual speech recognition,
Q. Liu, J. Wang, Y . Wang, X. Yang, G. Pan, and H. Li, “Human-inspired computing for robust and efficient audio-visual speech recognition,” IEEE Transactions on Computers, vol. 74, no. 9, pp. 2950–2961, 2025
2025
-
[7]
A ttfs-based energy and utilization efficient neuromorphic cnn accelerator,
M. Yu, T. Xiang, S. P, K. T. N. Chu, B. Amornpaisannon, Y . Tavva, V . P. K. Miriyala, and T. E. Carlson, “A ttfs-based energy and utilization efficient neuromorphic cnn accelerator,”Frontiers in Neuroscience, vol. 17, p. 1121592, 2023
2023
-
[8]
Ttfsformer: A ttfs-based loss- less conversion of spiking transformer,
L. Zhao, Z. Huang, J. Ding, and Z. Yu, “Ttfsformer: A ttfs-based loss- less conversion of spiking transformer,” inForty-second International Conference on Machine Learning, 2025
2025
-
[9]
Reconsidering the energy efficiency of spiking neural networks
Z. Yan, Z. Bai, and W.-F. Wong, “Reconsidering the energy efficiency of spiking neural networks,”arXiv preprint arXiv:2409.08290, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Temporal-coded spiking neural networks with dynamic firing threshold: Learning with event-driven backpropagation,
W. Wei, M. Zhang, H. Qu, A. Belatreche, J. Zhang, and H. Chen, “Temporal-coded spiking neural networks with dynamic firing threshold: Learning with event-driven backpropagation,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 10 552–10 562
2023
-
[11]
Ettfs: An efficient training framework for time-to-first-spike neuron,
K. Che, W. Fang, Z. Ma, L. Yuan, T. Masquelier, and Y . Tian, “Ettfs: An efficient training framework for time-to-first-spike neuron,”arXiv e-prints, pp. arXiv–2410, 2024
2024
-
[12]
From light sensing to adaptive learning: hafnium diselenide reconfigurable memcapacitive devices in neuromorphic computing,
B. Alqahtani, H. Li, A. M. Syed, and N. El-Atab, “From light sensing to adaptive learning: hafnium diselenide reconfigurable memcapacitive devices in neuromorphic computing,”Light: Science & Applications, vol. 14, no. 1, p. 30, 2025
2025
-
[13]
An artificial visual neuron with multiplexed rate and time-to-first-spike coding,
F. Li, D. Li, C. Wang, G. Liu, R. Wang, H. Ren, Y . Tang, Y . Wang, Y . Chen, K. Lianget al., “An artificial visual neuron with multiplexed rate and time-to-first-spike coding,”Nature Communications, vol. 15, no. 1, p. 3689, 2024
2024
-
[14]
Spikelm: towards general spike-driven language modeling via elastic bi-spiking mechanisms,
X. Xing, Z. Zhang, Z. Ni, S. Xiao, Y . Ju, S. Fan, Y . Wang, J. Zhang, and G. Li, “Spikelm: towards general spike-driven language modeling via elastic bi-spiking mechanisms,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[15]
Spikingbert: Distilling bert to train spiking language models using implicit differentiation,
M. Bal and A. Sengupta, “Spikingbert: Distilling bert to train spiking language models using implicit differentiation,” inProceedings of the AAAI conference on artificial intelligence, vol. 38, no. 10, 2024, pp. 10 998–11 006
2024
-
[16]
Emerging optoelectronic artificial synapses and memristors based on low-dimensional nanomaterials,
P. Xie, D. Li, S. Yip, and J. C. Ho, “Emerging optoelectronic artificial synapses and memristors based on low-dimensional nanomaterials,” Applied Physics Reviews, vol. 11, no. 1, 2024. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12
2024
-
[17]
Advanced opto- electronic devices for neuromorphic analog based on low-dimensional semiconductors,
X. Wang, Y . Zong, D. Liu, J. Yang, and Z. Wei, “Advanced opto- electronic devices for neuromorphic analog based on low-dimensional semiconductors,”Advanced Functional Materials, vol. 33, no. 15, p. 2213894, 2023
2023
-
[18]
A fully solution-printed photosynaptic transistor array with ultralow energy consumption for artificial-vision neural networks,
J. Shi, J. Jie, W. Deng, G. Luo, X. Fang, Y . Xiao, Y . Zhang, X. Zhang, and X. Zhang, “A fully solution-printed photosynaptic transistor array with ultralow energy consumption for artificial-vision neural networks,” Advanced Materials, vol. 34, no. 18, p. 2200380, 2022
2022
-
[19]
Monolithic 2d perovskites enabled artificial photonic synapses for neuromorphic vision sensors,
Y . Wang, Y . Zha, C. Bao, F. Hu, Y . Di, C. Liu, F. Xing, X. Xu, X. Wen, Z. Ganet al., “Monolithic 2d perovskites enabled artificial photonic synapses for neuromorphic vision sensors,”Advanced Materials, vol. 36, no. 18, p. 2311524, 2024
2024
-
[20]
Double-opponent spiking neuron array with orientation selectivity for encoding and spatial-chromatic processing,
D. Li, G. Liu, F. Li, H. Ren, Y . Tang, Y . Chen, Y . Wang, R. Wang, S. Wang, L. Xinget al., “Double-opponent spiking neuron array with orientation selectivity for encoding and spatial-chromatic processing,” Science Advances, vol. 11, no. 7, p. eadt3584, 2025
2025
-
[21]
Efficiently Training Time-to-First-Spike Spiking Neural Networks from Scratch
K. Che, W. Fang, Z. Ma, Y . Huang, P. Xue, L. Yuan, T. Masquelier, and Y . Tian, “Efficiently training time-to-first-spike spiking neural networks from scratch,”arXiv preprint arXiv:2410.23619, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Loihi asynchronous neuromorphic research chip,
A. Lines, P. Joshi, R. Liu, S. McCoy, J. Tse, Y .-H. Weng, and M. Davies, “Loihi asynchronous neuromorphic research chip,” in2018 24th IEEE International Symposium on Asynchronous Circuits and Systems (ASYNC), 2018, pp. 32–33
2018
-
[23]
Compute substrate for software 2.0,
J. Vasiljevic, L. Bajic, D. Capalija, S. Sokorac, D. Ignjatovic, L. Bajic, M. Trajkovic, I. Hamer, I. Matosevic, A. Cejkovet al., “Compute substrate for software 2.0,”IEEE micro, vol. 41, no. 2, pp. 50–55, 2021
2021
-
[24]
Sambanova sn10 rdu: A 7nm dataflow architecture to accelerate software 2.0,
R. Prabhakar, S. Jairath, and J. L. Shin, “Sambanova sn10 rdu: A 7nm dataflow architecture to accelerate software 2.0,” in2022 IEEE International Solid-State Circuits Conference (ISSCC), vol. 65. IEEE, 2022, pp. 350–352
2022
-
[25]
An active-matrix synaptic phototransistor array for in-sensor spectral processing,
D. Li, Y . Chen, H. Ren, Y . Tang, S. Zhang, Y . Wang, L. Xing, Q. Huang, L. Meng, and B. Zhu, “An active-matrix synaptic phototransistor array for in-sensor spectral processing,”Advanced Science, vol. 11, no. 39, p. 2406401, 2024
2024
-
[26]
Printable coffee-ring structures for highly uniform all-oxide optoelectronic synaptic transistors,
K. Liang, R. Wang, H. Ren, D. Li, Y . Tang, Y . Wang, Y . Chen, C. Song, F. Li, G. Liuet al., “Printable coffee-ring structures for highly uniform all-oxide optoelectronic synaptic transistors,”Advanced Optical Materials, vol. 10, no. 24, p. 2201754, 2022
2022
-
[27]
A data-driven dynamic execution orchestration architecture,
Z. Bai, P. Dangi, R. Juneja, Z. Li, Z. Yan, H. Lan, and T. Mitra, “A data-driven dynamic execution orchestration architecture,”International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2025
2025
-
[28]
W. Tang, Z. Wang, Z. Lin, L. Feng, Z. Liu, X. Li, P. Ye, X. Guo, and M. Si, “Monolithic 3d integration of vertically stacked cmos devices and circuits with high-mobility atomic-layer-deposited in 2 o 3 n-fet and polycrystalline si p-fet: Achieving large noise margin and high voltage gain of 134 v/v,” in2022 International Electron Devices Meeting (IEDM). I...
2022
-
[29]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inPro- ceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[30]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
V . Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,” 2020. [Online]. Available: https://arxiv.org/abs/1910.01108
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[31]
Tinybert: Distilling bert for natural language understanding,
X. Jiao, Y . Yin, L. Shang, X. Jiang, X. Chen, L. Li, F. Wang, and Q. Liu, “Tinybert: Distilling bert for natural language understanding,” inFindings of the Association for Computational Linguistics: EMNLP 2020, 2020, pp. 4163–4174
2020
-
[32]
Ternarybert: Distillation-aware ultra-low bit bert,
W. Zhang, L. Hou, Y . Yin, L. Shang, X. Chen, X. Jiang, and Q. Liu, “Ternarybert: Distillation-aware ultra-low bit bert,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 509–521
2020
-
[33]
Bit: Robustly binarized multi-distilled transformer,
Z. Liu, B. Oguz, A. Pappu, L. Xiao, S. Yih, M. Li, R. Krishnamoorthi, and Y . Mehdad, “Bit: Robustly binarized multi-distilled transformer,” Advances in neural information processing systems, vol. 35, pp. 14 303– 14 316, 2022
2022
-
[34]
Spikingformer: Spike-driven residual learning for transformer-based spiking neural network,
C. Zhou, L. Yu, Z. Zhou, Z. Ma, H. Zhang, H. Zhou, and Y . Tian, “Spikingformer: Spike-driven residual learning for transformer-based spiking neural network,”arXiv preprint arXiv:2304.11954, 2023
-
[35]
Otters: An energy-efficient spiking transformer via optical time-to-first-spike encoding,
Z. Yan, J. Mao, Q. Liu, F. Li, T. Luo, G. Pan, B. Zhu, and W.-F. Wong, “Otters: An energy-efficient spiking transformer via optical time-to-first-spike encoding,” inThe Fourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=oK0ISeb5Dw
2026
-
[36]
1.1 computing’s energy problem (and what we can do about it),
M. Horowitz, “1.1 computing’s energy problem (and what we can do about it),” in2014 IEEE international solid-state circuits conference digest of technical papers (ISSCC). IEEE, 2014, pp. 10–14
2014
-
[37]
A 5.3-fj/conv.-step pipelined-sar adc with resistance assisted two- stage dynamic amplifier based on gm-unit,
Q. Su, D. Li, X. Guo, H. Zhang, B. He, H. Jia, D. Wu, and X. Liu, “A 5.3-fj/conv.-step pipelined-sar adc with resistance assisted two- stage dynamic amplifier based on gm-unit,” in2023 8th International Conference on Integrated Circuits and Microsystems (ICICM). IEEE, 2023, pp. 322–325
2023
-
[38]
Qkformer: Hierarchical spiking transformer using qk attention,
C. Zhou, H. Zhang, Z. Zhou, L. Yu, L. Huang, X. Fan, L. Yuan, Z. Ma, H. Zhou, and Y . Tian, “Qkformer: Hierarchical spiking transformer using qk attention,”Advances in Neural Information Processing Systems, vol. 37, pp. 13 074–13 098, 2024
2024
-
[39]
Spiking vision transformer with saccadic attention,
S. Wang, M. Zhang, D. Zhang, A. Belatreche, Y . Xiao, Y . Liang, Y . Shan, Q. Sun, E. Zhang, and Y . Yang, “Spiking vision transformer with saccadic attention,”arXiv preprint arXiv:2502.12677, 2025
-
[40]
Spiking transformer: Introducing accurate addition-only spiking self-attention for transformer,
Y . Guo, X. Liu, Y . Chen, W. Peng, Y . Zhang, and Z. Ma, “Spiking transformer: Introducing accurate addition-only spiking self-attention for transformer,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 24 398–24 408
2025
-
[41]
High-performance atomic- layer-deposited indium oxide 3-d transistors and integrated circuits for monolithic 3-d integration,
M. Si, Z. Lin, Z. Chen, and P. D. Ye, “High-performance atomic- layer-deposited indium oxide 3-d transistors and integrated circuits for monolithic 3-d integration,”IEEE Transactions on Electron Devices, vol. 68, no. 12, pp. 6605–6609, 2021
2021
-
[42]
Three-dimensional integrated metal- oxide transistors,
S. Yuvaraja, H. Faber, M. Kumar, N. Xiao, G. I. Maciel Garc ´ıa, X. Tang, T. D. Anthopoulos, and X. Li, “Three-dimensional integrated metal- oxide transistors,”Nature Electronics, vol. 7, no. 9, pp. 768–776, 2024
2024
-
[43]
Monolithic 3d transposable 3t embedded dram with back-end-of-line oxide channel transistor,
J. Kwak, G. Choe, J. Lee, and S. Yu, “Monolithic 3d transposable 3t embedded dram with back-end-of-line oxide channel transistor,” in2024 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2024, pp. 1–5. Zhanglu Yanreceived the BSc degree in computer science from Xian Jiaotong University, in 2019, and the MSc degree in artificial intellig...
2024
-
[44]
He is currently a senior research scientist with the Institute of High Performance Computing (IHPC), Agency for Science, Technology and Re- search, Singapore (A*STAR), Singapore. His current research interests include high-performance computing, machine learning, computer architecture, hardware–software co-exploration, quantum comput- ing, efficient AI an...
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.