A Multi-Modal Framework with Cross-Subject Pseudo-Labeling and Semantic Alignment for Micro-Gesture Recognition
Pith reviewed 2026-06-27 07:41 UTC · model grok-4.3
The pith
Cross-modal pseudo-labeling improves single-modal robustness for micro-gesture recognition across subjects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
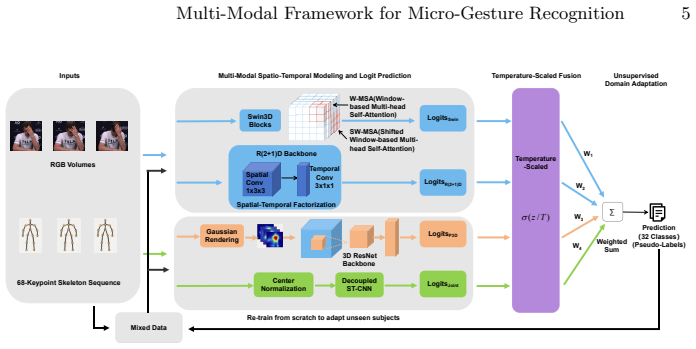
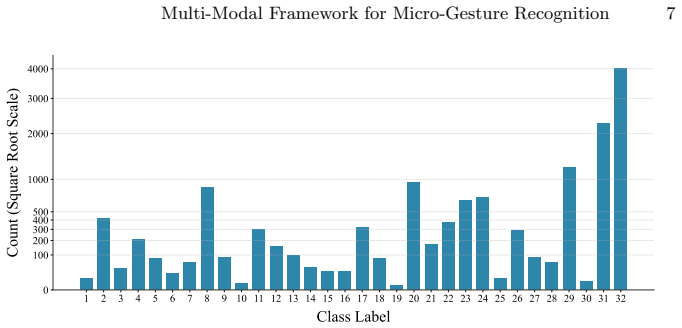
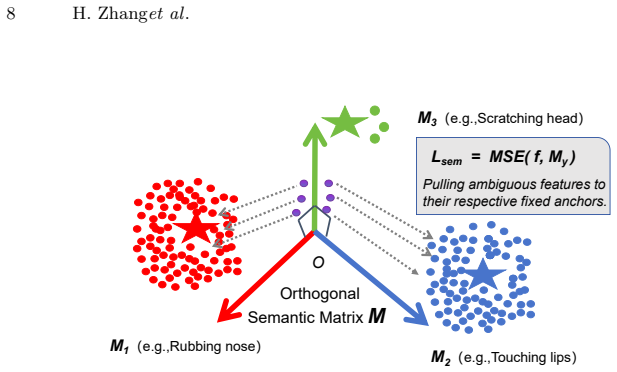
The authors combine saliency-guided multi-modal feature extraction with square-root smoothed class weighting and an orthogonal semantic embedding loss, then apply a cross-modal pseudo-labeling strategy for unsupervised domain adaptation that generates pseudo-labels across modalities to strengthen single-modal models under cross-subject shifts, followed by temperature-scaled soft-voting fusion, reaching 68.13 percent F1-score.
What carries the argument
Cross-Modal Pseudo-Labeling (CMPL) strategy, which generates and refines pseudo-labels by exchanging information across skeleton, heatmap, and RGB streams to close the domain gap in unsupervised adaptation.
If this is right
- Single-modal branches gain robustness when trained with labels transferred from other modalities.
- The square-root weighting and orthogonal loss together maintain tail-class accuracy without lowering head-class scores.
- Temperature scaling during late fusion reduces overconfident errors in the final prediction.
- The saliency-guided extraction supplies complementary fine-grained cues that survive domain shifts.
Where Pith is reading between the lines
- The same cross-modal labeling pattern could transfer to other video tasks that face subject-specific domain gaps and scarce labels.
- If the pseudo-labels prove reliable, the method reduces dependence on subject-specific annotations for deployment.
- Applying the approach to datasets with even lower motion contrast would test whether the accuracy assumption holds outside the challenge setting.
Load-bearing premise
Pseudo-labels produced by combining signals from different modalities stay accurate enough to raise rather than lower performance when class distributions are long-tailed and signal-to-noise ratios are low.
What would settle it
Run the framework with CMPL disabled and record the drop in F1-score on the same cross-subject test set; if the drop is small or negative while pseudo-label accuracy on a validation split falls below 60 percent, the adaptation benefit disappears.
Figures
read the original abstract
Micro-gestures (MGs) are spontaneous and subtle body movements that frequently convey hidden human emotions. Recognizing MGs in untrimmed videos remains highly challenging due to their extremely low signal-to-noise ratio, severe long-tailed class distribution, and the inherent domain shift encountered in cross-subject evaluation scenarios. In this paper, we propose a comprehensive multi-modal framework for Track 1 of the 4th MiGA-IJCAI Challenge. To capture fine-grained representations, we design a saliency-guided multi-modal extraction pipeline integrating 68-keypoint skeleton joint coordinates, 3D heatmap volumes, and high-resolution RGB visual features. We introduce a gentle square-root smoothed weighting mechanism paired with an Orthogonal Semantic Embedding Loss to protect tail classes without compromising overall recognition capabilities. More importantly, to bridge the cross-subject generalization gap, we propose a Cross-Modal Pseudo-Labeling (CMPL) strategy for unsupervised domain adaptation, which significantly boosts single-modal robustness. A temperature-scaled soft-voting mechanism is finally utilized to alleviate overconfidence during late fusion. Extensive experiments demonstrate that our framework achieves a competitive F1-score of 68.13\%, securing the 4th place.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-modal framework for micro-gesture recognition on Track 1 of the 4th MiGA-IJCAI Challenge. It combines a saliency-guided extraction pipeline across skeleton joints, 3D heatmaps, and RGB features; a square-root smoothed weighting scheme with an Orthogonal Semantic Embedding Loss for tail-class protection; a Cross-Modal Pseudo-Labeling (CMPL) strategy for unsupervised cross-subject domain adaptation; and temperature-scaled soft-voting for late fusion. The framework reports a test-set F1-score of 68.13%, placing 4th.
Significance. If the reported ranking holds and the individual components can be shown to contribute measurably, the work supplies a practical engineering solution for low-SNR, long-tailed, cross-subject micro-gesture recognition. The competition result itself constitutes reproducible empirical evidence on an external test set; the CMPL component, if validated, would address a recognized difficulty in multi-modal domain adaptation for subtle actions.
major comments (2)
- [Abstract / CMPL strategy description] The central claim that CMPL 'significantly boosts single-modal robustness' (abstract) is load-bearing yet unsupported: the manuscript provides neither an ablation isolating CMPL from saliency-guided extraction and late-fusion voting, nor any quantitative measure of pseudo-label noise or error amplification under the stated long-tailed, low-SNR regime.
- [Experiments section] No baseline comparisons, ablation tables, or statistical significance tests are referenced for the 68.13% F1-score, so the contribution of the square-root weighting, Orthogonal Semantic Embedding Loss, or temperature scaling cannot be verified relative to simpler multi-modal fusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will strengthen the empirical sections accordingly.
read point-by-point responses
-
Referee: [Abstract / CMPL strategy description] The central claim that CMPL 'significantly boosts single-modal robustness' (abstract) is load-bearing yet unsupported: the manuscript provides neither an ablation isolating CMPL from saliency-guided extraction and late-fusion voting, nor any quantitative measure of pseudo-label noise or error amplification under the stated long-tailed, low-SNR regime.
Authors: We agree the abstract claim requires direct support. The revised manuscript will add an ablation isolating CMPL (with and without it, on single-modal streams) and report pseudo-label accuracy plus error rates on a held-out validation split under the long-tailed regime. revision: yes
-
Referee: [Experiments section] No baseline comparisons, ablation tables, or statistical significance tests are referenced for the 68.13% F1-score, so the contribution of the square-root weighting, Orthogonal Semantic Embedding Loss, or temperature scaling cannot be verified relative to simpler multi-modal fusion.
Authors: We concur that component contributions need explicit verification. The revision will include ablation tables for square-root weighting, Orthogonal Semantic Embedding Loss, and temperature scaling, plus comparisons to standard multi-modal fusion baselines, with results from multiple runs and statistical significance tests. revision: yes
Circularity Check
No circularity: results measured on external challenge test set with no internal equations or self-citations reducing claims to fitted inputs
full rationale
The paper describes a multi-modal pipeline (saliency-guided extraction, square-root weighting, Orthogonal Semantic Embedding Loss, CMPL for UDA, temperature-scaled voting) and reports an F1-score of 68.13% on the MiGA-IJCAI Challenge test set. No equations are presented that define a quantity in terms of itself or rename a fitted parameter as a prediction. No self-citation chains or uniqueness theorems are invoked to justify core components. The evaluation is external and falsifiable, making the derivation self-contained against the provided benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-modal pseudo-labels generated from multiple modalities can be trusted to adapt models across subjects without introducing harmful label noise.
Reference graph
Works this paper leans on
-
[1]
Bertasius, G., Wang, H., Torresani, L.: Is space-time attention all you need for video understanding? In: International Conference on Machine Learning. pp. 813–
-
[2]
In: Advances in neural information pro- cessing systems
Cao, K., Wei, C., Gaidon, A., Arechiga, N., Ma, T.: Learning imbalanced datasets with label-distribution-aware margin loss. In: Advances in neural information pro- cessing systems. vol. 32 (2019)
2019
-
[3]
IEEE Transactions on Pattern Analysis and Machine Intelligence43(1), 172–186 (2019)
Cao, Z., Hidalgo, G., Simon, T., Wei, S.E., Sheikh, Y.: OpenPose: realtime multi- person 2d pose estimation using part affinity fields. IEEE Transactions on Pattern Analysis and Machine Intelligence43(1), 172–186 (2019)
2019
-
[4]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Carreira, J., Zisserman, A.: Quo vadis, action recognition? A new model and the Kinetics dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6299–6308 (2017)
2017
-
[5]
arXiv preprint arXiv:2408.03097 (2024)
Chen, G., Wang, F., Li, K., Wu, Z., Fan, H., Yang, Y., Wang, M., Guo, D.: Pro- totype learning for micro-gesture classification. arXiv preprint arXiv:2408.03097 (2024)
-
[6]
International Journal of Computer Vision131(5), 1346–1366 (2023)
Chen, H., Shi, H., Liu, X., Li, X., Zhao, G.: SMG: A micro-gesture dataset to- wards spontaneous body gestures for emotional stress state analysis. International Journal of Computer Vision131(5), 1346–1366 (2023)
2023
-
[7]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, Y., Zhang, Z., Yuan, C., Li, B., Deng, Y., Hu, W.: Channel-wise topology refinement graph convolution for skeleton-based action recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13359–13368 (2021)
2021
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cheng, K., Zhang, Y., He, X., Chen, W., Cheng, J., Lu, H.: Skeleton-based ac- tion recognition with shift graph convolutional network. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 183– 192 (2020)
2020
-
[9]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Cui, Y., Jia, M., Lin, T.Y., Song, Y., Belongie, S.: Class-balanced loss based on effective number of samples. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 9268–9277 (2019)
2019
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Duan, H., Zhao, Y., Chen, K., Lin, D., Dai, B.: Revisiting skeleton-based action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2969–2978 (2022)
2022
-
[11]
Psychiatry 32(1), 88–106 (1969) 12 H
Ekman, P., Friesen, W.V.: Nonverbal leakage and clues to deception. Psychiatry 32(1), 88–106 (1969) 12 H. Zhanget al
1969
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Feichtenhofer, C., Fan, H., Malik, J., He, K.: SlowFast networks for video recog- nition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6202–6211 (2019)
2019
-
[13]
In: Pro- ceedings of the European Conference on Computer Vision Workshops
Filntisis, P.P., Efthymiou, N., Potamianos, G., Maragos, P.: Emotion understand- ing in videos through body, context, and visual-semantic embedding loss. In: Pro- ceedings of the European Conference on Computer Vision Workshops. pp. 747–755. Springer (2020)
2020
-
[14]
The Journal of Machine Learning Research17(1), 2096–2030 (2016)
Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., Marchand, M., Lempitsky, V.: Domain-adversarial training of neural networks. The Journal of Machine Learning Research17(1), 2096–2030 (2016)
2096
-
[15]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Gu, J., Li, K., Wang, F., Wei, Y., Wu, Z., Fan, H., Wang, M.: Motion matters: Motion-guided modulation network for skeleton-based micro-action recognition. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 5461–5470 (2025)
2025
-
[16]
arXiv preprint arXiv:2507.08344 (2025)
Gu, J., Wang, F., Li, K., Wei, Y., Wu, Z., Guo, D.: MM-gesture: towards precise micro-gesture recognition through multimodal fusion. arXiv preprint arXiv:2507.08344 (2025)
-
[17]
In: International Conference on Machine Learning
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neu- ral networks. In: International Conference on Machine Learning. pp. 1321–1330. PMLR (2017)
2017
-
[18]
IEEE Transactions on Circuits and Systems for Video Technology34(7), 6238–6252 (2024)
Guo, D., Li, K., Hu, B., Zhang, Y., Wang, M.: Benchmarking micro-action recog- nition: Dataset, methods, and applications. IEEE Transactions on Circuits and Systems for Video Technology34(7), 6238–6252 (2024)
2024
-
[19]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Guo, D., Li, X., Li, K., Chen, H., Hu, J., Zhao, G., Yang, Y., Wang, M.: MAC 2024: Micro-action analysis grand challenge. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 11304–11305 (2024)
2024
-
[20]
IEEE Transactions on Circuits and Systems for Video Technology32(10), 7120–7132 (2022)
Hao, Y., Wang, S., Cao, P., Gao, X., Xu, T., Wu, J., He, X.: Attention in attention: Modeling context correlation for efficient video classification. IEEE Transactions on Circuits and Systems for Video Technology32(10), 7120–7132 (2022)
2022
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hao, Y., Zhang, H., Ngo, C.W., He, X.: Group contextualization for video recog- nition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 928–938 (2022)
2022
-
[22]
In: Proceedings of the MiGA Workshop at IJCAI (2025)
Hu, X., Pu, C., Li, Y., Xie, K., Qiguang, M.: Enhancing micro-gesture classification via global-aware importance estimation in vision transformer. In: Proceedings of the MiGA Workshop at IJCAI (2025)
2025
-
[23]
In: Proceedings of the MiGA Workshop at IJCAI (2023)
Huang, H., Guo, X., Peng, W., Xia, Z.: Micro-gesture classification based on ensem- ble hypergraph convolution transformer. In: Proceedings of the MiGA Workshop at IJCAI (2023)
2023
-
[24]
In: Proceedings of the MiGA Workshop at IJCAI (2024)
Huang, H., Wang, Y., Kerui, L., Xia, Z.: Multi-modal micro-gesture classifica- tion via multiscale heterogeneous ensemble network. In: Proceedings of the MiGA Workshop at IJCAI (2024)
2024
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Joze, H.R.V., Shaban, A., Iuzzolino, M.L., Koishida, K.: MMTM: Multimodal transfer module for CNN fusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13289–13299 (2020)
2020
-
[26]
In: International Conference on Learning Representations (2020)
Kang, B., Xie, S., Rohrbach, M., Yan, Z., Gordo, A., Feng, J., Kalantidis, Y.: De- coupling representation and classifier for long-tailed recognition. In: International Conference on Learning Representations (2020)
2020
-
[27]
In: Workshop on Challenges in Representation Learning, ICML
Lee, D.H.: Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In: Workshop on Challenges in Representation Learning, ICML. vol. 3, p. 896 (2013) Multi-Modal Framework for Micro-Gesture Recognition 13
2013
-
[28]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lee, J., Lee, M., Lee, D., Lee, S.: Hierarchically decoupled graph convolutional network for skeleton-based action recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10444–10453 (2023)
2023
-
[29]
In: International Conference on Machine Learning
Li, J., Qiu, R., Chen, S., et al.: Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation. In: International Conference on Machine Learning. pp. 6028–6039. PMLR (2020)
2020
-
[30]
arXiv preprint arXiv:2603.26586 (2026)
Li, K., Gu, J., Wang, F., Wu, Z., Fan, H., Guo, D.: MA-Bench: Towards fine-grained micro-action understanding. arXiv preprint arXiv:2603.26586 (2026)
-
[31]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, K., Guo, D., Chen, G., Fan, C., Xu, J., Wu, Z., Fan, H., Wang, M.: Prototypical calibrating ambiguous samples for micro-action recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 4815–4823 (2025)
2025
-
[32]
In: Proceedings of the 31st ACM International Conference on Multimedia
Li, K., Guo, D., Chen, G., Liu, F., Wang, M.: Data augmentation for human behavior analysis in multi-person conversations. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 9516–9520 (2023)
2023
-
[33]
arXiv preprint arXiv:2307.10624 (2023)
Li, K., Guo, D., Chen, G., Peng, X., Wang, M.: Joint skeletal and semantic embed- ding loss for micro-gesture classification. arXiv preprint arXiv:2307.10624 (2023)
-
[34]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Li, K., Guo, D., Li, X., Chen, H., Liu, P., Wang, F., Hu, J., Zhao, G., Wang, M.: MAC 2025: The 2nd micro-action analysis grand challenge. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 14216–14221 (2025)
2025
-
[35]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, K., Liu, P., Guo, D., Wang, F., Wu, Z., Fan, H., Wang, M.: MMAD: Multi-label micro-action detection in videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13225–13236 (2025)
2025
-
[36]
In: International Conference on Learning Representations (2022)
Li, K., Wang, Y., Gao, P., Song, G., Liu, Y., Li, H., Qiao, Y.: UniFormer: Unifying convolution and self-attention for visual recognition. In: International Conference on Learning Representations (2022)
2022
-
[37]
In: Proceedings of the IEEE International Conference on Computer Vision
Lin, T.Y., Goyal, P., Girshick, R., He, K., Doll´ ar, P.: Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 2980–2988 (2017)
2017
-
[38]
arXiv preprint arXiv:2503.15978 (2025)
Liu, P., Dong, G., Guo, D., Li, K., Li, F., Yang, X., Wang, M., Ying, X.: A survey on fMRI-based brain decoding for reconstructing multimodal stimuli. arXiv preprint arXiv:2503.15978 (2025)
-
[39]
arXiv preprint arXiv:2507.09512 (2025)
Liu, P., Li, K., Wang, F., Wei, Y., She, J., Guo, D.: Online micro-gesture recog- nition using data augmentation and spatial-temporal attention. arXiv preprint arXiv:2507.09512 (2025)
-
[40]
arXiv preprint arXiv:2407.04490 (2024)
Liu, P., Wang, F., Li, K., Chen, G., Wei, Y., Tang, S., Wu, Z., Guo, D.: Micro-gesture online recognition using learnable query points. arXiv preprint arXiv:2407.04490 (2024)
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, X., Shi, H., Chen, H., Yu, Z., Li, X., Zhao, G.: iMiGUE: An identity-free video dataset for micro-gesture understanding and emotion analysis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10631–10642 (2021)
2021
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Z., Ning, J., Cao, Y., Wei, Y., Zhang, Z., Lin, S., Hu, H.: Video Swin Trans- former. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3202–3211 (2022)
2022
-
[43]
In: International Conference on Learning Representations (2017)
Loshchilov, I., Hutter, F.: SGDR: Stochastic gradient descent with warm restarts. In: International Conference on Learning Representations (2017)
2017
-
[44]
In: International Conference on Learning Representations (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019)
2019
-
[45]
In: Chinese 14 H
Shang, T., Hao, Y., Pei, M., Li, K., Ben, H., Wang, S.: Cross-modal feature en- hancement and contrastive alignment for micro-gesture recognition. In: Chinese 14 H. Zhanget al. Conference on Pattern Recognition and Computer Vision (PRCV). pp. 203–217. Springer (2025)
2025
-
[46]
In: Advances in Neural Information Processing Systems
Sohn, K., Berthelot, D., Carlini, N., Zhang, Z., Zhang, H., Raffel, C., Cubuk, E.D., Kurakin, A., Xie, C.L.: FixMatch: Simplifying semi-supervised learning with con- sistency and confidence. In: Advances in Neural Information Processing Systems. vol. 33, pp. 596–608 (2020)
2020
-
[47]
In: Advances in Neural Information Processing Systems
Tong, Z., Song, Y., Wang, J., Wang, L.: VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. In: Advances in Neural Information Processing Systems. vol. 35, pp. 10078–10093 (2022)
2022
-
[48]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., Paluri, M.: A closer look at spatiotemporal convolutions for action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6450–6459 (2018)
2018
-
[49]
In: Proceedings of the MiGA Workshop at IJCAI (2025)
Xu, H., Cheng, L., Wang, Y., Tang, S., Zhong, Z.: Towards fine-grained emotion understanding via skeleton-based micro-gesture recognition. In: Proceedings of the MiGA Workshop at IJCAI (2025)
2025
-
[50]
In: Proceedings of the AAAI Conference on Ar- tificial Intelligence
Yan, S., Xiong, Y., Lin, D.: Spatial temporal graph convolutional networks for skeleton-based action recognition. In: Proceedings of the AAAI Conference on Ar- tificial Intelligence. vol. 32 (2018)
2018
-
[51]
PloS one9(1), e86041 (2014)
Yan, W.J., Li, X., Wang, S.J., Zhao, G., Liu, Y.J., Chen, Y.H., Xia, X.: CASME II: A database for spontaneous macro-expression and micro-expression spotting and recognition. PloS one9(1), e86041 (2014)
2014
-
[52]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhou, B., Cui, Q., Wei, X.S., Chen, Z.M.: BBN: Bilateral-branch network with cumulative learning for long-tailed visual recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9719– 9728 (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.