RoboProcessBench: Benchmarking Process-Aware Understanding in Vision-Language Robotic Manipulation
Pith reviewed 2026-06-27 06:24 UTC · model grok-4.3
The pith
Vision-language models lack robust understanding of how robotic manipulations progress physically and temporally.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
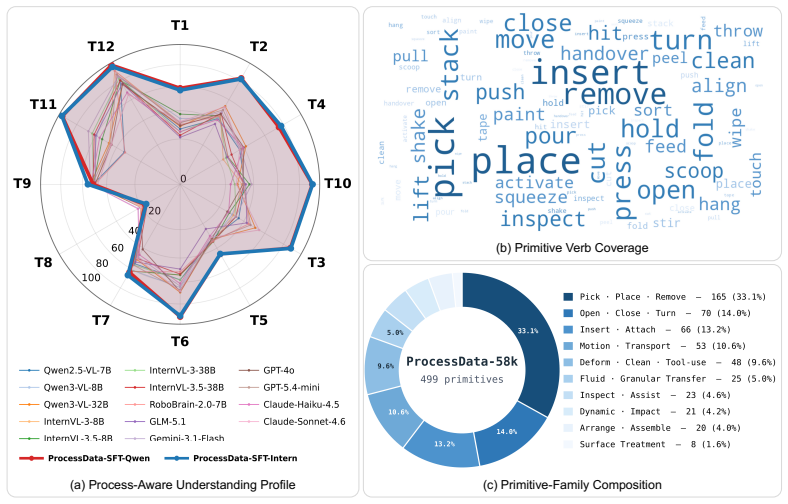
RoboProcessBench decomposes process-aware understanding into static monitoring and dynamic reasoning, instantiated as 12 diagnostic question families. Built from physically grounded execution traces across 260 manipulation tasks, the ProcessData corpus of roughly 58k question-answer pairs is split for post-training and evaluation. Extensive testing reveals broad limitations in current vision-language models on ProcessData-Eval, while post-training Qwen2.5-VL-7B and InternVL-3-8B on ProcessData-SFT yields consistent improvements on local state, motion, progress, and primitive-aware cues. The work positions the benchmark as both an evaluation tool and a source of learnable supervision for deve
What carries the argument
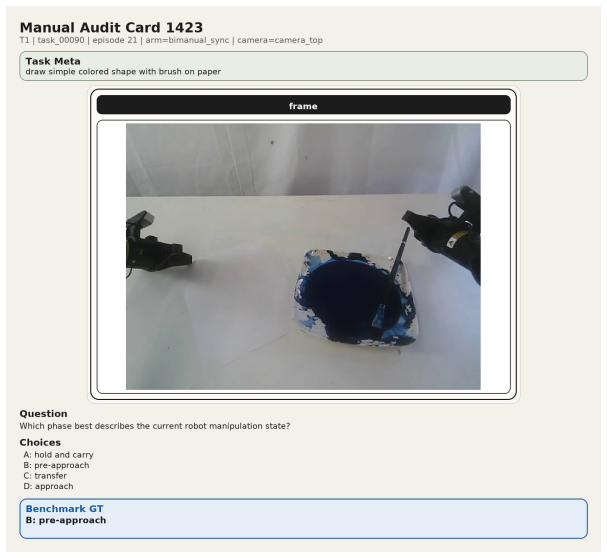
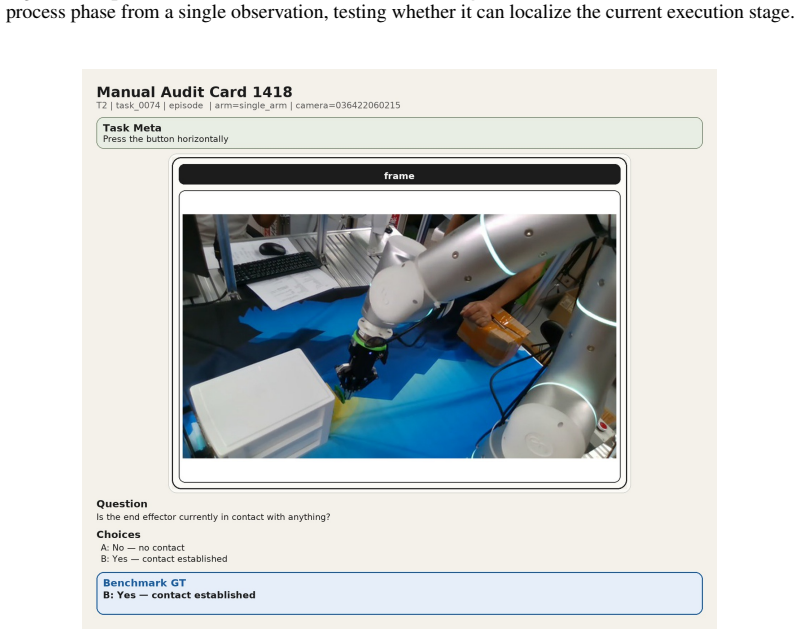
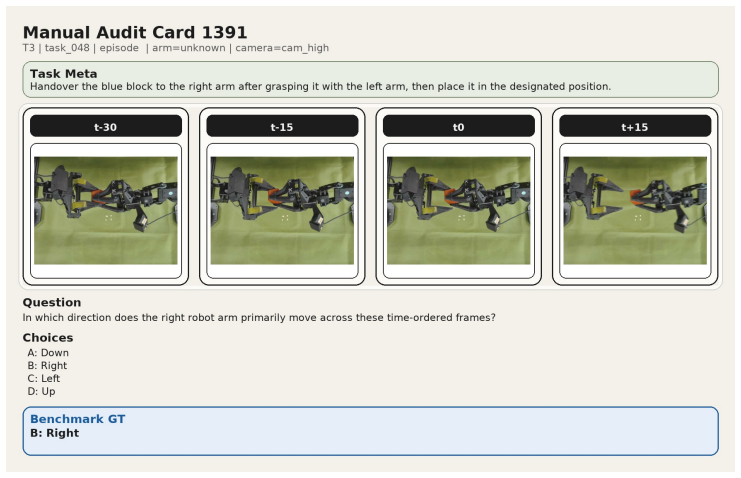
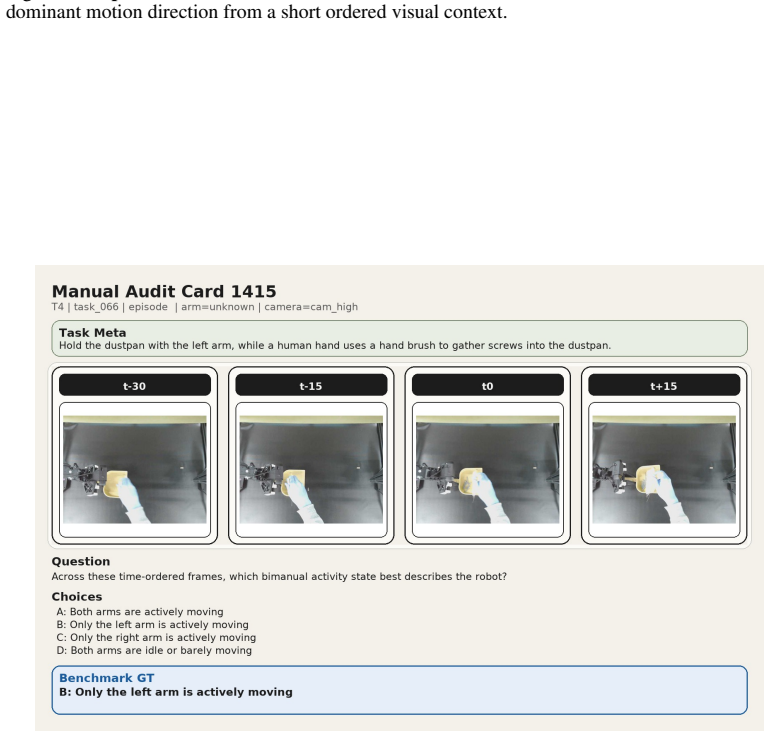
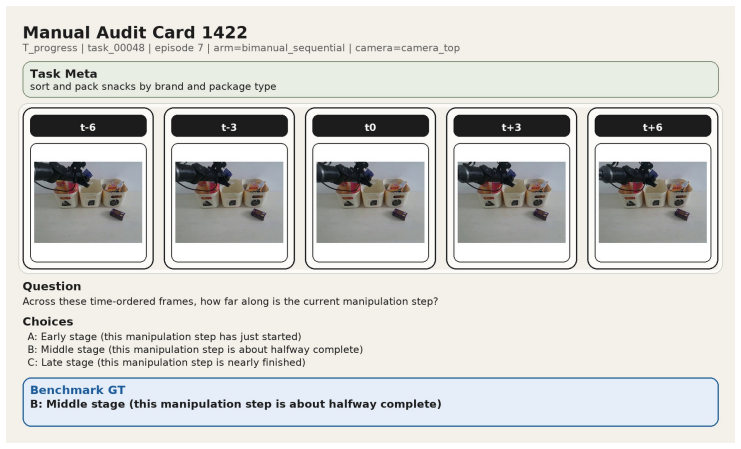
The 12 diagnostic question families covering phase, contact, motion, coordination, primitive-local progress, temporal order, outcome, and primitive-level transitions, derived from the ProcessData corpus of execution traces.
If this is right
- Models used as visual critics or failure detectors in manipulation will continue to miss intermediate errors unless trained on process-level signals.
- ProcessData-SFT can serve as a direct supervision source to improve existing vision-language models on local state and motion cues.
- The benchmark enables systematic comparison of models on specific dimensions such as temporal order and primitive transitions.
- Future robotic systems relying on vision-language models for online monitoring will require explicit process-aware training to achieve reliable performance.
Where Pith is reading between the lines
- If process understanding remains weak, safety-critical decisions such as early intervention during execution may stay unreliable even when final-task accuracy looks acceptable.
- The split between ProcessData-SFT and ProcessData-Eval suggests a practical path for iterative improvement: generate more execution traces, add questions, and retrain.
- Because the tasks are physically grounded, performance gaps on the benchmark are likely to translate to real-world robot deployments rather than remaining purely academic.
Load-bearing premise
The 12 question families and the 260-task corpus are assumed to capture the full range of process-aware understanding needed for robotic manipulation without major gaps or biases.
What would settle it
A controlled experiment in which a model trained on ProcessData-SFT shows no improvement over its base version when deployed as a critic or reward signal on a held-out set of real robot executions that were not part of the original 260 tasks.
Figures








read the original abstract
Vision-language models (VLMs) are increasingly explored as visual critics, reward generators, and failure detectors in robotic manipulation. These roles implicitly require models to judge not only final task success, but also how a manipulation execution is physically and temporally progressing. However, existing evaluations fail to test whether VLMs possess fine-grained process understanding. To address this gap, we present RoboProcessBench, a benchmark for process-aware understanding in vision-language robotic manipulation. RoboProcessBench decomposes such capability into two complementary dimensions, \emph{static monitoring} and \emph{dynamic reasoning}, instantiated as 12 diagnostic question families covering phase, contact, motion, coordination, primitive-local progress, temporal order, outcome, and primitive-level transitions. Built from physically grounded execution traces, the curated benchmark corpus ProcessData contains \textasciitilde 58k question-answer pairs across 260 manipulation tasks, which is further split into ProcessData-SFT and ProcessData-Eval for post-training and evaluation purposes. Extensive evaluation of various VLMs on ProcessData-Eval reveals broad limitations across 12 diagnostic task families, suggesting current models still lack robust process-aware understanding of manipulation executions. But with ProcessData-SFT, the post-trained \textit{Qwen2.5-VL-7B} and \textit{InternVL-3-8B} exhibit consistent gains on local state, motion, progress, and primitive-aware cues. These results demonstrate that RoboProcessBench serves as both an evaluation benchmark and a learnable supervision source for developing VLMs capable of monitoring and evaluating robotic manipulation processes. Project webpage: \href{https://processbench-2026.github.io/RoboProcessBench-Web/}{https://processbench-2026.github.io}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoboProcessBench, a benchmark decomposing process-aware understanding in VLMs for robotic manipulation into static monitoring and dynamic reasoning via 12 diagnostic question families (phase, contact, motion, coordination, primitive-local progress, temporal order, outcome, primitive-level transitions). It constructs ProcessData with ~58k QA pairs from 260 physically grounded tasks, splits it into ProcessData-SFT and ProcessData-Eval, evaluates multiple VLMs showing broad limitations on the Eval set, and demonstrates consistent post-SFT gains for Qwen2.5-VL-7B and InternVL-3-8B on local state, motion, progress, and primitive-aware cues.
Significance. If the benchmark's 12 families and 260-task corpus provide a faithful probe of process-aware capabilities, the work supplies both an evaluation resource and a supervision source for training VLMs to monitor manipulation executions, filling a gap left by success-only metrics. The explicit split into SFT and Eval sets, plus reported gains after fine-tuning, are concrete strengths that could support iterative development of process-aware VLMs.
major comments (2)
- [Abstract / benchmark construction] Abstract and benchmark construction section: the central claim that 'current models still lack robust process-aware understanding' rests on ProcessData-Eval being a comprehensive and unbiased probe, yet no selection criteria, coverage statistics, or validation against underrepresented regimes (long-horizon, deformable objects, multi-agent) are supplied to justify that the 12 families exhaust the required process elements or avoid curation bias. Without this, the generalization from observed failures does not follow.
- [Evaluation results] Evaluation results paragraph: the reported 'consistent gains' on local state, motion, progress, and primitive-aware cues after SFT are presented without quantitative deltas, per-family breakdowns, or controls for whether gains reflect genuine process reasoning versus superficial cue exploitation; this weakens the claim that ProcessData-SFT serves as effective learnable supervision.
minor comments (1)
- [Abstract] The LaTeX artifact '\textasciitilde' appears in the abstract; replace with the proper symbol for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below and indicate where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract / benchmark construction] Abstract and benchmark construction section: the central claim that 'current models still lack robust process-aware understanding' rests on ProcessData-Eval being a comprehensive and unbiased probe, yet no selection criteria, coverage statistics, or validation against underrepresented regimes (long-horizon, deformable objects, multi-agent) are supplied to justify that the 12 families exhaust the required process elements or avoid curation bias. Without this, the generalization from observed failures does not follow.
Authors: We agree that additional details on benchmark construction would strengthen the justification for the central claim. The 12 families were derived from a decomposition of process-aware understanding into static monitoring and dynamic reasoning, informed by common elements in robotic manipulation executions (e.g., phase identification, contact states, motion primitives). The 260 tasks were drawn from physically grounded traces to ensure realism. However, the manuscript does not currently include explicit selection criteria, coverage statistics, or discussion of underrepresented regimes. In the revised manuscript, we will add a dedicated subsection in the benchmark construction section that details task selection criteria, provides coverage statistics across task types and question families, and includes an explicit limitations discussion addressing long-horizon tasks, deformable objects, and multi-agent scenarios. This will clarify the benchmark's scope and support the generalization more rigorously. revision: yes
-
Referee: [Evaluation results] Evaluation results paragraph: the reported 'consistent gains' on local state, motion, progress, and primitive-aware cues after SFT are presented without quantitative deltas, per-family breakdowns, or controls for whether gains reflect genuine process reasoning versus superficial cue exploitation; this weakens the claim that ProcessData-SFT serves as effective learnable supervision.
Authors: We acknowledge that more granular quantitative reporting would better support the claims about post-training gains. The manuscript reports consistent improvements in the specified categories after SFT on ProcessData-SFT, but does not currently include explicit numerical deltas or full per-family breakdowns in the summarized evaluation paragraph. In the revised version, we will expand the evaluation results section to include per-family accuracy tables with pre- and post-SFT values and deltas. We will also add a discussion of the improvements, including any available analyses that help distinguish process reasoning gains from cue exploitation (e.g., performance patterns across related question families). This will provide stronger evidence for the utility of ProcessData-SFT as supervision. revision: yes
Circularity Check
No circularity; new benchmark and empirical evaluations are independent of self-referential inputs
full rationale
The paper constructs RoboProcessBench from physically grounded execution traces across 260 tasks, defines 12 diagnostic families, splits into SFT/Eval sets, and reports direct VLM performance measurements plus post-training gains. No equations, fitted parameters renamed as predictions, self-citation chains, or definitional loops appear in the provided text. The central claims rest on the new corpus and standard evaluation protocols rather than reducing to prior self-referential quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
VLMPC: Vision-language model predictive control for robotic manipulation
Wentao Zhao, Jiaming Chen, Ziyu Meng, Donghui Mao, Ran Song, and Wei Zhang. VLMPC: Vision-language model predictive control for robotic manipulation. InRobotics: Science and Systems (RSS), 2024
2024
-
[2]
Shaopeng Zhai, Qi Zhang, Tianyi Zhang, Fuxian Huang, Haoran Zhang, Ming Zhou, Shengzhe Zhang, Litao Liu, Sixu Lin, and Jiangmiao Pang. A vision-language-action-critic model for robotic real-world reinforcement learning.arXiv preprint arXiv:2509.15937, 2025
arXiv 2025
-
[3]
Yuheng Ji, Yuyang Liu, Huajie Tan, Xuchuan Huang, Fanding Huang, Yijie Xu, et al. PRM- as-a-judge: A dense evaluation paradigm for fine-grained robotic auditing.arXiv preprint arXiv:2603.21669, 2026
arXiv 2026
-
[4]
Yanru Wu, Weiduo Yuan, Ang Qi, Vitor Guizilini, Jiageng Mao, and Yue Wang. Large reward models: Generalizable online robot reward generation with vision-language models.arXiv preprint arXiv:2603.16065, 2026
arXiv 2026
-
[5]
AHA: A vision-language-model for detecting and reasoning over failures in robotic manipulation
Jiafei Duan, Wilbert Pumacay, Nishanth Kumar, Yi Ru Wang, Shulin Tian, Wentao Yuan, Ranjay Krishna, Dieter Fox, Ajay Mandlekar, and Yijie Guo. AHA: A vision-language-model for detecting and reasoning over failures in robotic manipulation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[6]
Huajie Tan, Sixiang Chen, Yijie Xu, Zixiao Wang, Yuheng Ji, Cheng Chi, Yaoxu Lyu, Zhongxia Zhao, Xiansheng Chen, Peterson Co, Shaoxuan Xie, Guocai Yao, Pengwei Wang, Zhongyuan Wang, and Shanghang Zhang. Robo-Dopamine: General process reward modeling for high- precision robotic manipulation.arXiv preprint arXiv:2512.23703, 2025
arXiv 2025
-
[7]
Ramy ElMallah, Krish Chhajer, and Chi-Guhn Lee. Score the steps, not just the goal: VLM- based subgoal evaluation for robotic manipulation.arXiv preprint arXiv:2509.19524, 2025
arXiv 2025
-
[8]
Muttaqien, Koshi Maki- hara, Hanbit Oh, Keisuke Shirai, Floris Erich, Ryo Hanai, and Yukiyasu Domae
Tomohiro Motoda, Masaki Murooka, Ryoichi Nakajo, Muhammad A. Muttaqien, Koshi Maki- hara, Hanbit Oh, Keisuke Shirai, Floris Erich, Ryo Hanai, and Yukiyasu Domae. AIST bimanual manipulation dataset.https://aistairc.github.io/aist_bimanip_site/, 2025
2025
-
[9]
Ziyu Wang, Chenyuan Liu, Yushun Xiang, Runhao Zhang, Qingbo Hao, Hongliang Lu, Houyu Chen, Zhizhong Feng, Kaiyue Zheng, Dehao Ye, et al. The great march 100: 100 detail-oriented tasks for evaluating embodied AI agents.arXiv preprint arXiv:2601.11421, 2026
arXiv 2026
-
[10]
RH20T-P: A primitive-level robotic dataset towards composable generalization agents
Zeren Chen, Zhelun Shi, Xiaoya Lu, Lehan He, Sucheng Qian, Zhenfei Yin, Wanli Ouyang, Jing Shao, Yu Qiao, Cewu Lu, and Lu Sheng. RH20T-P: A primitive-level robotic dataset towards composable generalization agents. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
2025
-
[11]
Daniel Sliwowski, Shail Jadav, Sergej Stanovcic, Jedrzej Orbik, Johannes Heidersberger, and Dongheui Lee. REASSEMBLE: A multimodal dataset for contact-rich robotic assembly and disassembly.arXiv preprint arXiv:2502.05086, 2025
arXiv 2025
-
[12]
Open X-Embodiment: Robotic learning datasets and RT-X models.arXiv preprint arXiv:2310.08864, 2023
Anthony Brohan et al. Open X-Embodiment: Robotic learning datasets and RT-X models.arXiv preprint arXiv:2310.08864, 2023
Pith/arXiv arXiv 2023
-
[13]
DROID: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Alexander Khazatsky et al. DROID: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[14]
Qingwen Bu et al. AgiBot World colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
Pith/arXiv arXiv 2025
-
[15]
Robo- MIND: Benchmark on multi-embodiment intelligence normative data for robot manipulation
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Yang, et al. Robo- MIND: Benchmark on multi-embodiment intelligence normative data for robot manipulation. arXiv preprint arXiv:2412.13877, 2024
Pith/arXiv arXiv 2024
-
[16]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310, 2023. 10
Pith/arXiv arXiv 2023
-
[17]
ClevrSkills: Compositional language and visual reasoning in robotics
Sanjay Haresh, Daniel Dijkman, Apratim Bhattacharyya, and Roland Memisevic. ClevrSkills: Compositional language and visual reasoning in robotics. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[18]
Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, and Xipeng Qiu. Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[19]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[20]
EmbodiedBench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, Heng Ji, Huan Zhang, and Tong Zhang. EmbodiedBench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents. InProceedings of the 42nd International Conference on Machine Learni...
2025
-
[21]
ManipBench: Benchmarking vision-language models for low-level robot manipulation
Enyu Zhao, Vedant Raval, Hejia Zhang, Jiageng Mao, Zeyu Shangguan, Stefanos Nikolaidis, Yue Wang, and Daniel Seita. ManipBench: Benchmarking vision-language models for low-level robot manipulation. InProceedings of The 9th Conference on Robot Learning (CoRL), 2025
2025
-
[22]
Kaiyuan Chen, Shuangyu Xie, Zehan Ma, Pannag R. Sanketi, and Ken Goldberg. Robo2VLM: Visual question answering from large-scale in-the-wild robot manipulation datasets.arXiv preprint arXiv:2505.15517, 2025
arXiv 2025
-
[23]
RoboBrain 2.0 technical report.arXiv preprint arXiv:2507.02029, 2025
BAAI RoboBrain Team, Mingyu Cao, Huajie Tan, Yuheng Ji, Minglan Lin, Zhiyu Li, Zhou Cao, Pengwei Wang, Enshen Zhou, Yi Han, et al. RoboBrain 2.0 technical report.arXiv preprint arXiv:2507.02029, 2025
arXiv 2025
-
[24]
Gen Luo, Ganlin Yang, Ziyang Gong, Guanzhou Chen, Haonan Duan, Erfei Cui, Ronglei Tong, Zhi Hou, Tianyi Zhang, Zhe Chen, Shenglong Ye, Lewei Lu, Jingbo Wang, Wenhai Wang, Jifeng Dai, Yu Qiao, Rongrong Ji, and Xizhou Zhu. Visual embodied brain: Let multimodal large language models see, think, and control in spaces.arXiv preprint arXiv:2506.00123, 2025
arXiv 2025
-
[25]
ConditionNET: Learning preconditions and effects for execution monitoring.IEEE Robotics and Automation Letters (RA-L), 2025
Daniel Sliwowski and Dongheui Lee. ConditionNET: Learning preconditions and effects for execution monitoring.IEEE Robotics and Automation Letters (RA-L), 2025
2025
-
[26]
Hongyu Yan, Qiwei Li, Jiaolong Yang, and Yadong Mu. ProgressVLA: Progress-guided diffusion policy for vision-language robotic manipulation.arXiv preprint arXiv:2603.27670, 2026
arXiv 2026
-
[27]
Tingjun Dai, Mingfei Han, Tingwen Du, Zhiheng Liu, Zhihui Li, Salman Khan, Jun Yu, and Xiaojun Chang. See, plan, rewind: Progress-aware vision-language-action models for robust robotic manipulation.arXiv preprint arXiv:2603.09292, 2026
Pith/arXiv arXiv 2026
-
[28]
Hao Li, Ziqin Wang, Zi-han Ding, Shuai Yang, Yilun Chen, Yang Tian, Xiaolin Hu, Tai Wang, Dahua Lin, Feng Zhao, Si Liu, and Jiangmiao Pang. RoboInter: A holistic intermediate representation suite towards robotic manipulation.arXiv preprint arXiv:2602.09973, 2026
arXiv 2026
-
[29]
Yangtao Chen, Zixuan Chen, Nga Teng Chan, Junting Chen, Junhui Yin, Jieqi Shi, Yang Gao, Yong-Lu Li, and Jing Huo. RoboHiMan: A hierarchical evaluation paradigm for compositional generalization in long-horizon manipulation.arXiv preprint arXiv:2510.13149, 2025
arXiv 2025
-
[30]
RoboEval: Where robotic manipulation meets structured and scalable evaluation
Yi Ru Wang, Carter Ung, Grant Tannert, Jiafei Duan, Josephine Li, Amy Le, Rishabh Oswal, Markus Grotz, Wilbert Pumacay, Yuquan Deng, Ranjay Krishna, Dieter Fox, and Siddhartha Srinivasa. RoboEval: Where robotic manipulation meets structured and scalable evaluation. arXiv preprint arXiv:2507.00435, 2025
Pith/arXiv arXiv 2025
-
[31]
Yibin Liu, Yaxing Lyu, Daqi Gao, Zhixuan Liang, Weiliang Tang, Shilong Mu, Xiaokang Yang, and Yao Mu. From passive observer to active critic: Reinforcement learning elicits process reasoning for robotic manipulation.arXiv preprint arXiv:2603.15600, 2026. 11
arXiv 2026
-
[32]
Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Tang, Zhenyu Wang, Peng Wang, Jinze Bai, et al. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[33]
Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025
Qwen Team. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[34]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Yue Cao, Yangzhou Liu, Zhaoyang Hou, Zizhen Zhu, Lewei Wang, Tao Xiong, Weike Chen, et al. InternVL3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
Pith/arXiv arXiv 2025
-
[35]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
Pith/arXiv arXiv 2025
-
[36]
GLM-5.1: Towards long-horizon tasks.https://z.ai/blog/glm-5.1, 2026
Z.AI. GLM-5.1: Towards long-horizon tasks.https://z.ai/blog/glm-5.1, 2026
2026
-
[37]
Gemini 3 Flash: Frontier intelligence built for speed
Google. Gemini 3 Flash: Frontier intelligence built for speed. https://blog.google/ products/gemini/gemini-3-flash/, 2025
2025
-
[38]
System card: GPT-4o
OpenAI. System card: GPT-4o. https://openai.com/index/gpt-4o-system-card/ , 2024
2024
-
[39]
Introducing GPT-5.4 mini and nano
OpenAI. Introducing GPT-5.4 mini and nano. https://openai.com/index/ introducing-gpt-5-4-mini-and-nano/, 2026
2026
-
[40]
System card: Claude Haiku 4.5
Anthropic. System card: Claude Haiku 4.5. https://assets.anthropic.com/m/ 99128ddd009bdcb/Claude-Haiku-4-5-System-Card.pdf, 2025
2025
-
[41]
System card: Claude Sonnet 4.6
Anthropic. System card: Claude Sonnet 4.6. https://www-cdn.anthropic.com/ 78073f739564e986ff3e28522761a7a0b4484f84.pdf, 2026. 12 A Benchmark Specification This appendix provides implementation-level details for RoboProcessBench. We keep the appendix compact and focus on the information needed to verify the benchmark definition, reproduce the evaluation pr...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.