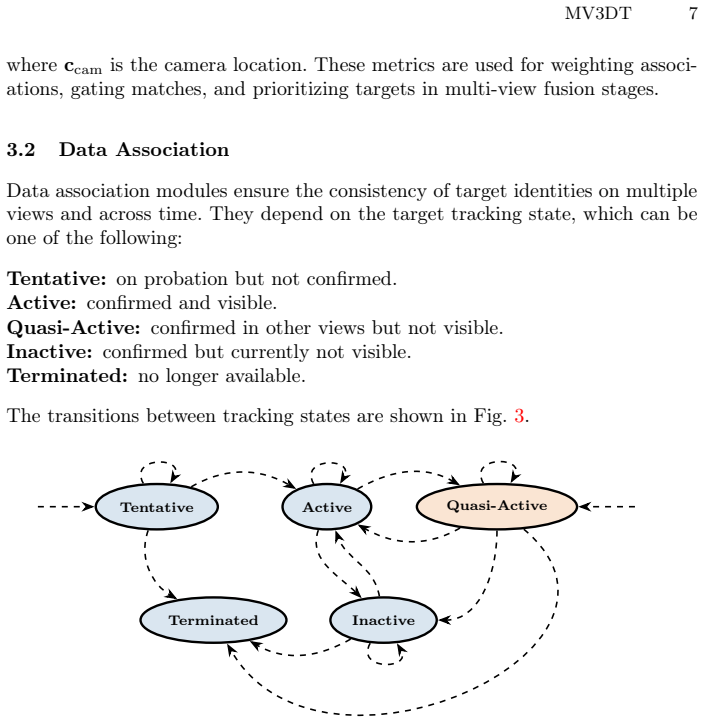
Fully Distributed Multi-View 3D Tracking in Real-Time
Pith reviewed 2026-06-27 07:23 UTC · model grok-4.3
The pith
MV3DT performs real-time 3D multi-view tracking through peer-to-peer messaging without any central server.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MV3DT achieves accurate identity propagation and occlusion recovery through peer-to-peer coordination in a fully distributed setup. Each node executes a lightweight modular pipeline comprising monocular 3D perception, distributed multi-view association, and collaborative fusion via lightweight messaging. On the WILDTRACK benchmark it reaches 94.3 percent IDF1 and 93.3 percent MOTA, sustains 30 frames per second across 100 cameras with less than 10 ms inter-camera latency and 2.2 percent communication overhead, and operates in a zero-shot regime given only camera calibrations.
What carries the argument
The modular pipeline of monocular 3D perception, distributed multi-view association, and collaborative fusion via lightweight messaging that enables peer-to-peer identity propagation and occlusion recovery.
If this is right
- Tracking accuracy remains competitive with centralized methods on standard benchmarks.
- Real-time operation at 30 FPS is sustained on networks of at least 100 cameras.
- Communication overhead stays below 3 percent even at large scale.
- The system deploys directly in new scenes given only camera calibrations.
- No central aggregation point is required for identity consistency or occlusion handling.
Where Pith is reading between the lines
- Large camera networks could be built with lower hardware and bandwidth costs because no high-capacity central server is needed.
- Privacy may improve because raw video never leaves individual camera nodes.
- The same messaging pattern could be tested on other distributed sensor fusion tasks such as multi-robot mapping.
- Temporary node failures might be tolerated better than in centralized designs if identity recovery mechanisms are robust.
Load-bearing premise
Peer-to-peer coordination via lightweight messaging can reliably achieve identity propagation and occlusion recovery across the network without requiring central aggregation.
What would settle it
Run the system on a 100-camera network where one node experiences a 500 ms communication delay and measure whether track identities are lost or correctly recovered compared with a centralized baseline.
Figures



read the original abstract
Multi-camera tracking with overlapping fields of view typically relies on centralized fusion, which creates computational bottlenecks that prevent deployment at scale. We present MV3DT, a fully distributed framework for real-time multi-view 3D tracking that achieves accurate identity propagation and occlusion recovery through peer-to-peer coordination, eliminating the need for central aggregation. Each camera node executes a lightweight modular pipeline comprising monocular 3D perception, distributed multi-view association, and collaborative fusion via lightweight messaging. MV3DT achieves 94.3% IDF1 and 93.3% MOTA on WILDTRACK, competitive with state-of-the-art centralized methods, while demonstrating superior scalability by sustaining 30 FPS on 100 cameras with less than 10 ms inter-camera latency and only 2.2% communication overhead. MV3DT operates in a zero-shot regime given camera calibrations, requiring no scene-specific learning and making it directly deployable in new environments. These results establish MV3DT as a practical solution for real-time multi-view tracking in large-scale overlapping camera networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MV3DT, a fully distributed framework for real-time multi-view 3D tracking. Each camera node runs a modular pipeline with monocular 3D perception, distributed multi-view association, and collaborative fusion using lightweight messaging. It claims to achieve 94.3% IDF1 and 93.3% MOTA on the WILDTRACK dataset, competitive with centralized methods, while scaling to 100 cameras at 30 FPS with less than 10 ms latency and 2.2% communication overhead, operating zero-shot with only camera calibrations.
Significance. If the distributed coordination mechanism reliably maintains global consistency, this would represent a significant advance in scalable multi-camera tracking by eliminating central aggregation bottlenecks. The reported performance metrics and scalability results, including low overhead, would make it a practical solution for large-scale deployments in new environments without scene-specific training.
major comments (1)
- [Abstract] Abstract: The description of the 'distributed multi-view association' module claims it enables 'accurate identity propagation and occlusion recovery through peer-to-peer coordination' without central aggregation, but provides no details on the specific protocol for resolving cross-camera identity conflicts or ensuring no duplicate tracks. This mechanism is load-bearing for both the accuracy claims on WILDTRACK and the scaling to 100 cameras at 30 FPS.
minor comments (1)
- Confirm the exact dataset name (WILDTRACK vs. Wildtrack) and include its standard citation in the abstract if not already present.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We address it point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The description of the 'distributed multi-view association' module claims it enables 'accurate identity propagation and occlusion recovery through peer-to-peer coordination' without central aggregation, but provides no details on the specific protocol for resolving cross-camera identity conflicts or ensuring no duplicate tracks. This mechanism is load-bearing for both the accuracy claims on WILDTRACK and the scaling to 100 cameras at 30 FPS.
Authors: We agree the abstract is high-level and would benefit from a concise description of the protocol. The full manuscript (Section 3.3) specifies a lightweight peer-to-peer protocol: each node broadcasts local track proposals with unique IDs and confidence scores; conflicts are resolved via a distributed majority-vote mechanism over a fixed-size message window, with duplicate suppression enforced by ID uniqueness and timestamp ordering. This ensures no central aggregation while maintaining consistency. We will revise the abstract to include a one-sentence outline of this protocol. revision: yes
Circularity Check
No circularity; claims rest on external dataset evaluation
full rationale
The paper presents an empirical framework evaluated on the external WILDTRACK benchmark (7 cameras) with reported IDF1/MOTA metrics, plus separate scalability simulations to 100 cameras. No equations or derivations reduce to fitted parameters renamed as predictions, no self-citation chains justify core claims, and the zero-shot modular pipeline is described without self-definitional loops. Performance numbers derive from standard tracking metrics on held-out data rather than internal normalization or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neurocomputing (2023) 1, 2, 4
Amosa, T.I., Sebastian, P., Izhar, L.I., Ibrahim, O., Ayinla, L.S., Bahashwan, A.A., Bala, A., Samaila, Y.A.: Multi-camera multi-object tracking: a review of current trends and future advances. Neurocomputing (2023) 1, 2, 4
2023
-
[2]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Aung, S., Park, H., Jung, H., Cho, J.: Enhancing multi-view pedestrian detection through generalized 3d feature pulling. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 1196–1205 (2024) 5
2024
-
[3]
In: 2016 IEEE International Conference on Image Processing (ICIP) (2016) 4, 9
Bewley, A., Ge, Z., Ott, L., Ramos, F., Upcroft, B.: Simple online and real-time tracking. In: 2016 IEEE International Conference on Image Processing (ICIP) (2016) 4, 9
2016
-
[4]
Image and Vision Computing (2006) 2, 3
Black, J., Ellis, T.: Multi camera image tracking. Image and Vision Computing (2006) 2, 3
2006
-
[5]
In: European Conference on Computer Vision (2020) 4
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European Conference on Computer Vision (2020) 4
2020
-
[6]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018) 12
Chavdarova, T., Baqué, P., Bouquet, S., Maksai, A., Jose, C., Bagautdinov, T., Lettry, L., Fua, P., Van Gool, L., Fleuret, F.: WILDTRACK: A multi-camera HD dataset for dense unscripted pedestrian detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018) 12
2018
-
[7]
IEEE Transactions on Multimedia (2011) 4
Chen, K.W., Lai, C.C., Lee, P.J., Chen, C.S., Hung, Y.P.: Adaptive learning for target tracking and true linking discovering across multiple non-overlapping cam- eras. IEEE Transactions on Multimedia (2011) 4
2011
-
[8]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Daryani, A.E., Bhutta, M., Hernandez, B., Medeiros, H.: Camuvid: Calibration- free multi-view detection. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1220–1229 (2025) 5
2025
-
[9]
arXiv preprint arXiv:2408.06604 (2024) 5
Dong, Z., Zhang, Y., Huang, X., Ji, H., Shi, Z., Zhan, X., Chen, J.: Mv-detr: Multi-modality indoor object detection by multi-view detecton transformers. arXiv preprint arXiv:2408.06604 (2024) 5
-
[10]
In: IEEE Winter Conference on Applications of Computer Vision (2023) 12
Engilberge, M., Liu, W., Fua, P.: Multi-view tracking using weakly supervised hu- man motion prediction. In: IEEE Winter Conference on Applications of Computer Vision (2023) 12
2023
-
[11]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Engilberge, M., Shi, H., Wang, Z., Fua, P.: Two-level data augmentation for cali- brated multi-view detection. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 128–136 (2023) 5
2023
-
[12]
arXiv preprint arXiv:2507.08494 (2025) 4, 12, 13
Engilberge, M., Vrkic, I., Grosche, F.W., Pilet, J., Turetken, E., Fua, P.: One graph to track them all: Dynamic gnns for single-and multi-view tracking. arXiv preprint arXiv:2507.08494 (2025) 4, 12, 13
-
[13]
Foundation, E.: Eclipse mosquitto.https://mosquitto.org/(2026), message bro- ker for MQTT 11
2026
-
[14]
Multimedia Tools and Applications78, 10773–10793 (2019) 1, 2
Iguernaissi, R., Merad, D., Aziz, K., Drap, P.: People tracking in multi-camera systems: a review. Multimedia Tools and Applications78, 10773–10793 (2019) 1, 2
2019
-
[15]
In: Pro- ceedings of the 26th ACM International Conference on Multimedia (2018) 4
Jiang, N., Bai, S., Xu, Y., Xing, C., Zhou, Z., Wu, W.: Online inter-camera trajec- tory association exploiting person re-identification and camera topology. In: Pro- ceedings of the 26th ACM International Conference on Multimedia (2018) 4
2018
-
[16]
Procedia Computer Science (2022) 4
Jiang, P., Ergu, D., Liu, F., Cai, Y., Ma, B.: A review of YOLO algorithm devel- opments. Procedia Computer Science (2022) 4
2022
-
[17]
ASME Journal of Basic Engineering (1960) 10 16 B
Kalman, R.E.: A new approach to linear filtering and prediction problems. ASME Journal of Basic Engineering (1960) 10 16 B. Hernandez et al
1960
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, J., Shin, W., Park, H., Baek, J.: Addressing the occlusion problem in multi-camera people tracking with human pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5463– 5469 (2023) 2
2023
-
[19]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2000) 3, 4
Lee, L., Romano, R., Stein, G.: Monitoring activities from multiple video streams: Establishing a common coordinate frame. IEEE Transactions on Pattern Analysis and Machine Intelligence (2000) 3, 4
2000
-
[20]
In: European Conference on Computer Vision
Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Qiao, Y., Dai, J.: BEV- Former: Learning bird’s-eye-view representation from multi-camera images via spa- tiotemporal transformers. In: European Conference on Computer Vision. pp. 1–18. Springer (2022) 4
2022
-
[21]
IEEE Journal of Selected Topics in Signal Processing (2008) 3, 5
Medeiros, H., Park, J., Kak, A.: Distributed object tracking using a cluster-based Kalman filter in wireless camera networks. IEEE Journal of Selected Topics in Signal Processing (2008) 3, 5
2008
-
[22]
In: Proceedings of the 1998 Image Understanding Workshop, Morgan- Kaufman, San Francisco (1998) 3
Mikic, I., Santini, S., Jain, R.: Video processing and integration from multiple cameras. In: Proceedings of the 1998 Image Understanding Workshop, Morgan- Kaufman, San Francisco (1998) 3
1998
-
[23]
org/(2019) 11
MQTT.org: MQTT - The Standard for IoT Messaging — mqtt.org.https://mqtt. org/(2019) 11
2019
-
[24]
Naphade, M., Anastasiu, D.C., Sharma, A., Jagrlamudi, V., Jeon, H., Liu, K., Chang, M.C., Lyu, S., Gao, Z.: The NVIDIA AI City Challenge. In: 2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (Smart- World/SCA...
2017
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023) 1
Naphade, M., Wang, S., Anastasiu, D.C., Tang, Z., Chang, M.C., Yao, Y., Zheng, L., Rahman, M.S., Arya, M.S., Sharma, A., et al.: The 7th AI city challenge. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023) 1
2023
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023) 4
Nguyen, Q.Q.V., Le, H.D.A., Chau, T.T.T., Luu, D.T., Chung, N.M., Ha, S.V.U.: Multi-camera people tracking with mixture of realistic and synthetic knowledge. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023) 4
2023
-
[27]
com/deepstream-sdk(2026) 11
NVIDIA Corporation: NVIDIA deepstream SDK.https://developer.nvidia. com/deepstream-sdk(2026) 11
2026
-
[28]
com/orgs/nvidia/teams/tao/models/peoplenet(2026), deployable quantized ONNX v2.6.3 11
NVIDIA Corporation: NVIDIA TAO peoplenet.https://catalog.ngc.nvidia. com/orgs/nvidia/teams/tao/models/peoplenet(2026), deployable quantized ONNX v2.6.3 11
2026
-
[29]
NVIDIA Corporation: NVIDIA TAO peoplenet transformer.https://catalog. ngc . nvidia . com / orgs / nvidia / teams / tao / models / peoplenet _ transformer (2026), deployable v1.1 11
2026
-
[30]
NVIDIA Corporation: NVIDIA TAO toolkit.https://developer.nvidia.com/ tao-toolkit(2026) 11
2026
-
[31]
IEEE Access (2020) 1, 4
Olagoke, A.S., Ibrahim, H., Teoh, S.S.: Literature survey on multi-camera system and its application. IEEE Access (2020) 1, 4
2020
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2019) 5 MV3DT 17
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3D hands, face, and body from a single image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2019) 5 MV3DT 17
2019
-
[33]
Machine Vision and Applications (2017) 2, 3, 4
Previtali, F., Bloisi, D.D., Iocchi, L.: A distributed approach for real-time multi- camera multiple object tracking. Machine Vision and Applications (2017) 2, 3, 4
2017
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Quach, K.G., Nguyen, P., Le, H., Truong, T.D., Duong, C.N., Tran, M.T., Luu, K.: DyGLIP: A dynamic graph model with link prediction for accurate multi- camera multiple object tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13784–13793 (2021) 4
2021
-
[35]
In: Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (2016) 4
Redmon, J.: You only look once: Unified, real-time object detection. In: Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (2016) 4
2016
-
[36]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2017) 4
Redmon, J., Farhadi, A.: YOLO9000: better, faster, stronger. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2017) 4
2017
-
[37]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018) 4
Ristani, E., Tomasi, C.: Features for multi-target multi-camera tracking and re- identification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018) 4
2018
-
[38]
IEEE Transactions on Systems, Man, and Cybernetics: Systems (2022) 4
Siddique, A., Medeiros, H.: Tracking passengers and baggage items using multiple overhead cameras at security checkpoints. IEEE Transactions on Systems, Man, and Cybernetics: Systems (2022) 4
2022
-
[39]
In: Proceedings
Stein, G.P.: Tracking from multiple view points: Self-calibration of space and time. In: Proceedings. 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (1999) 3
1999
-
[40]
IEEE Signal Processing Magazine (2011) 3
Taj, M., Cavallaro, A.: Distributed and decentralized multicamera tracking. IEEE Signal Processing Magazine (2011) 3
2011
-
[41]
Tang, Z., Wang, S., Anastasiu, D.C., Chang, M.C., Sharma, A., Kong, Q., Ko- bori, N., Gochoo, M., Batnasan, G., Otgonbold, M.E., Alnajjar, F., Hsieh, J.W., Kornuta, T., Li, X., Zhao, Y., Zhang, H., Radhakrishnan, S., Jain, A., Kumar, R., Murali, V.N., Wang, Y., Pusegaonkar, S.S., Wang, Y., Biswas, S., Wu, X., Zheng, Z., Chakraborty, P., Chellappa, R.: The...
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Teepe, T., Wolters, P., Gilg, J., Herzog, F., Rigoll, G.: Lifting multi-view detection and tracking to the bird’s eye view. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 667–676 (2024) 4, 12
2024
-
[43]
In: Advances in Neural Information Processing Systems (2024) 4
Wang, A., Chen, H., Liu, L., Chen, K., Lin, Z., Han, J., Ding, G.: YOLOv10: Real- time end-to-end object detection. In: Advances in Neural Information Processing Systems (2024) 4
2024
-
[44]
arXiv preprint arXiv:2402.13616 (2024) 4
Wang, C.Y., Yeh, I.H., Liao, H.Y.M.: YOLOv9: Learning what you want to learn using programmable gradient information. arXiv preprint arXiv:2402.13616 (2024) 4
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024) 1, 12
Wang, S., Anastasiu, D.C., Tang, Z., Chang, M.C., Yao, Y., Zheng, L., Rahman, M.S., Arya, M.S., Sharma, A., Chakraborty, P., et al.: The 8th AI City Challenge. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024) 1, 12
2024
-
[46]
arXiv e-prints pp
Wang, Y., Meinhardt, T., Cetintas, O., Yang, C.Y., Satish Pusegaonkar, S., Mis- saoui,B.,Biswas,S.,Tang,Z.,Leal-Taixé,L.:Bev-sushi:Multi-targetmulti-camera 3d detection and tracking in bird’s-eye view. arXiv e-prints pp. arXiv–2412 (2024) 4, 14
2024
-
[47]
The University of Nebraska-Lincoln (2013) 5 18 B
Wang, Y.: Distributed multi-object tracking with multi-camera systems composed of overlapping and non-overlapping cameras. The University of Nebraska-Lincoln (2013) 5 18 B. Hernandez et al
2013
-
[48]
In: 2017 IEEE International Conference on Image Processing (ICIP) (2017) 7, 9
Wojke, N., Bewley, A., Paulus, D.: Simple online and realtime tracking with a deep association metric. In: 2017 IEEE International Conference on Image Processing (ICIP) (2017) 7, 9
2017
-
[49]
In: CVPR Workshop
Xie, Z., Ni, Z., Yang, W., Zhang, Y., Chen, Y., Zhang, Y., Ma, X.: A robust online multi-camera people tracking system with geometric consistency and state-aware re-id correction. In: CVPR Workshop. Seattle, WA, USA (2024) 14
2024
-
[50]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yamane, T., Masumura, R., Suzuki, S., Orihashi, S.: Mvtrajecter: Multi-view pedestrian tracking with trajectory motion cost and trajectory appearance cost. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13270–13280 (2025) 4, 12
2025
-
[51]
Scientific Reports (2022) 2, 3, 4
Yang, S., Ding, F., Li, P., Hu, S.: Distributed multi-camera multi-target association for real-time tracking. Scientific Reports (2022) 2, 3, 4
2022
-
[52]
Computer Vision and Image Understanding249, 104203 (2024) 4
Yang, Y., Xu, M., Ralph, J.F., Ling, Y., Pan, X.: An end-to-end tracking frame- work via multi-view and temporal feature aggregation. Computer Vision and Image Understanding249, 104203 (2024) 4
2024
-
[53]
IEEE Transactions on Image Processing (2010) 3
Yoder,J.,Medeiros,H.,Park,J.,Kak,A.C.:Cluster-baseddistributedfacetracking in camera networks. IEEE Transactions on Image Processing (2010) 3
2010
-
[54]
In: CVPR Workshop
Yoshida, R., Okubo, J., Fujii, J., Amakata, M., Yamashita, T.: Overlap suppression clustering for offline multi-camera people tracking. In: CVPR Workshop. Seattle, WA, USA (2024) 14
2024
-
[55]
In: European Conference on Computer Vision (2022) 8
Zhang, Y., Sun, P., Jiang, Y., Yu, D., Weng, F., Yuan, Z., Luo, P., Liu, W., Wang, X.: Bytetrack: Multi-object tracking by associating every detection box. In: European Conference on Computer Vision (2022) 8
2022
-
[56]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhao, Y., Lv, W., Xu, S., Wei, J., Wang, G., Dang, Q., Liu, Y., Chen, J.: RT- DETR: DETRs beat YOLOs on real-time object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16788– 16797 (2024) 4
2024
-
[57]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2023) 4
Zong, Z., Song, G., Liu, Y.: DETRs with collaborative hybrid assignments training. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2023) 4
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.