Reasoning for Mobile User Experience with Multimodal LLMs: Task, Benchmark, and Approach
Pith reviewed 2026-06-27 07:10 UTC · model grok-4.3
The pith
UI-UX, trained with reward routing and asymmetric transition rewards, reaches 0.7963 accuracy on UXBench for diagnosing UX issues in UI screenshots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
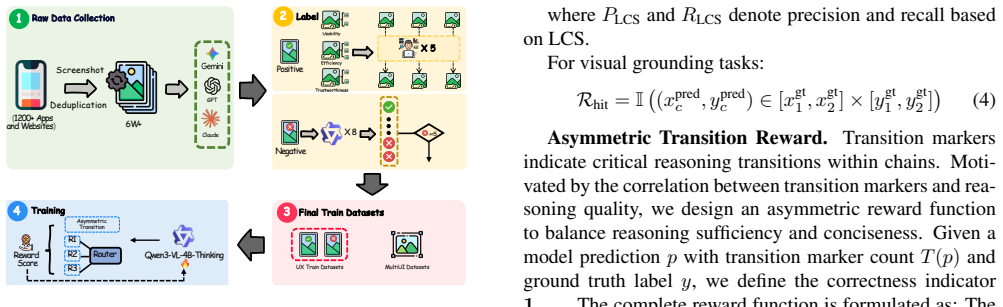
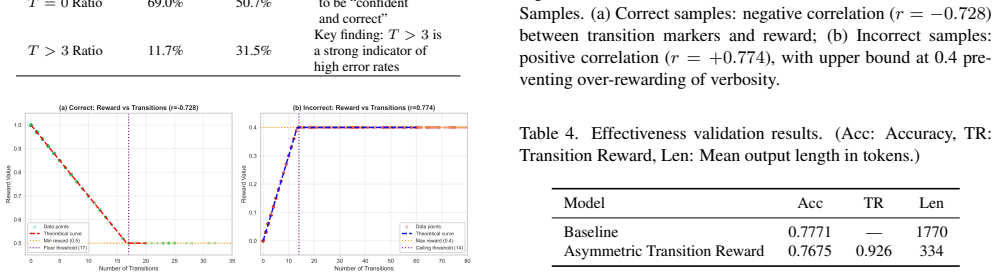
UI-UX reaches 0.7963 accuracy on UXBench, surpassing Claude-4.5-Sonnet at 0.6550, by using a reward routing mechanism that dynamically balances perceptual understanding and logical reasoning during inference together with an asymmetric transition reward that suppresses redundant or insufficient reasoning steps in the reinforcement-learning stage on the Qwen3-VL foundation model.
What carries the argument
The reward routing mechanism and asymmetric transition reward applied during reinforcement learning of the UI-UX model.
If this is right
- Multimodal models can achieve substantially higher accuracy on UI reasoning tasks when trained with reinforcement learning that explicitly balances perception and step-by-step logic.
- A fixed collection of eight tasks on real screenshots can serve as a reproducible yardstick for comparing MLLMs on user-experience diagnosis.
- The resulting model generalizes across layout, hierarchy, and consistency subtasks while keeping inference latency low enough for practical use.
- Current leading MLLMs remain limited in their ability to perform the fine-grained visual and logical checks needed for UX evaluation.
Where Pith is reading between the lines
- The same reward-routing pattern could be applied to other visual domains that mix perception with multi-step reasoning, such as diagram analysis or scientific figure interpretation.
- If the benchmark tasks correlate with real user complaints, the method could support automated UX checks inside design or development pipelines.
- Testing the trained model on non-mobile interfaces would reveal whether the learned mechanisms are specific to mobile layouts or more general.
- Low-latency deployment makes it feasible to embed the model directly into live app-testing or real-time design feedback tools.
Load-bearing premise
The eight tasks in UXBench supply a valid and unbiased measure of MLLMs' capacity for fine-grained UX issue diagnosis across layout, hierarchy, and consistency without additional human validation.
What would settle it
If independent human UX experts systematically disagree with the ground-truth labels on the same set of UI screenshots, or if models that score high on UXBench still produce interfaces that users rate poorly in live tests, the benchmark's validity as a proxy would be falsified.
Figures


read the original abstract
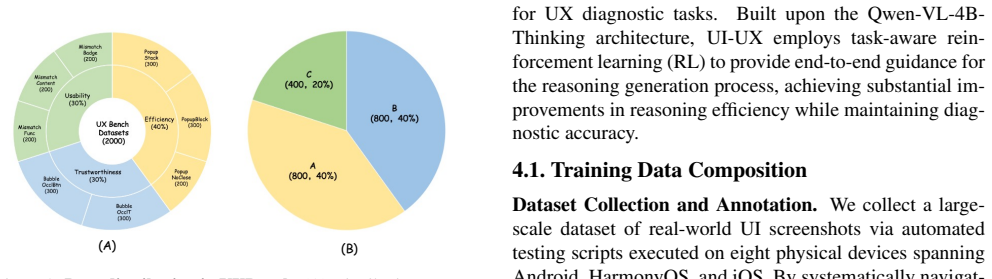
User experience (UX) centered on usability, perceived consistency, and functional clarity is fundamental to real-world user interfaces (UI). The application of multimodal large language models (MLLMs) in the field of user interfaces is evolving rapidly, such as visual element grounding, graphical user interface (GUI) agents, and design-to-code generation. However, research efforts on evaluating UX based on UI screenshots are still immature. To address this, we propose UXBench, a novel multimodal benchmark consisting of 2,000 VQA data samples designed to assess MLLMs' ability to perform UI-based reasoning. UXBench includes 8 tasks based on real-world UI screenshots that require fine-grained diagnosis of UX issues across layout relationships, visual hierarchy, and content consistency. Our extensive evaluation of mainstream MLLMs shows that they remain fundamentally limited in their capacity for UI-based reasoning. The results underscore the need for further advancements in this area. To bridge this gap, we propose UI-UX, an MLLM based on Qwen3-VL-4B-Thinking foundation model and enhanced via reinforcement learning with two key innovations: a reward routing mechanism that dynamically balances perceptual understanding and logical reasoning during inference, and an asymmetric transition reward that suppresses redundant or insufficient reasoning steps. Experiments demonstrate that UI-UX achieves state-of-the-art (SOTA) performance on UXBench, attaining an accuracy of 0.7963 -- surpassing Claude-4.5-Sonnet's 0.6550 -- while exhibiting strong generalization across diverse UI tasks and maintaining low inference latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UXBench, a multimodal benchmark of 2,000 VQA samples across 8 tasks derived from real-world UI screenshots to assess MLLMs on fine-grained UX reasoning (layout relationships, visual hierarchy, content consistency). It reports that mainstream MLLMs remain limited on these tasks and introduces UI-UX, an RL-enhanced model based on Qwen3-VL-4B-Thinking that uses a reward routing mechanism and asymmetric transition reward to achieve 0.7963 accuracy on UXBench, outperforming Claude-4.5-Sonnet (0.6550).
Significance. If the benchmark labels prove reliable and the evaluation avoids circularity, the work would supply a new resource for UI/UX reasoning evaluation and demonstrate targeted RL techniques for balancing perceptual and logical capabilities in MLLMs, with relevance to GUI agents and design automation.
major comments (2)
- [Abstract] Abstract: the central SOTA claim (0.7963 vs. 0.6550) rests on UXBench ground-truth labels constituting reliable measures of fine-grained UX diagnosis, yet the abstract supplies no information on label provenance, inter-annotator agreement, expert review, or external grounding. This absence makes both absolute accuracy and model ranking difficult to interpret.
- [Model and Experiments] Model description and experiments: UI-UX is trained via RL whose reward is defined on the same UXBench tasks used for final evaluation; without explicit confirmation of data splits, training-set overlap, or held-out test construction, the reported accuracy risks reducing to performance on fitted evaluation data rather than independent generalization.
minor comments (1)
- [Abstract] The abstract asserts 'strong generalization across diverse UI tasks' without reference to cross-task or cross-domain splits; adding a brief statement on how generalization was measured would improve clarity.
Simulated Author's Rebuttal
We thank the referee for highlighting issues of interpretability in the abstract and potential circularity in the evaluation. We address both points below and will revise the manuscript to improve transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central SOTA claim (0.7963 vs. 0.6550) rests on UXBench ground-truth labels constituting reliable measures of fine-grained UX diagnosis, yet the abstract supplies no information on label provenance, inter-annotator agreement, expert review, or external grounding. This absence makes both absolute accuracy and model ranking difficult to interpret.
Authors: We agree the abstract should briefly indicate label reliability to support the SOTA claim. The full manuscript (Section 3) describes that all 2,000 samples were annotated by UX experts following a standardized protocol, with inter-annotator agreement of 87% and expert review for edge cases. We will revise the abstract to include a short clause on expert annotation and reported agreement metrics. revision: yes
-
Referee: [Model and Experiments] Model description and experiments: UI-UX is trained via RL whose reward is defined on the same UXBench tasks used for final evaluation; without explicit confirmation of data splits, training-set overlap, or held-out test construction, the reported accuracy risks reducing to performance on fitted evaluation data rather than independent generalization.
Authors: The experiments section already specifies a 70/30 train/test split of UXBench with no overlap between RL training data and the held-out test set used for the reported 0.7963 accuracy. The reward is computed only on the training split. We will add an explicit statement confirming the split construction and absence of leakage to eliminate ambiguity. revision: yes
Circularity Check
No circularity: empirical results on self-proposed benchmark with no definitional reduction
full rationale
The paper proposes UXBench (new 2000-sample VQA benchmark with 8 tasks) and UI-UX (Qwen3-VL-4B-Thinking enhanced by RL with reward routing and asymmetric transition reward), then reports empirical accuracy (0.7963) on UXBench. No equations, self-definitional relations, or fitted-input-called-prediction steps are present in the provided text. The RL enhancement and benchmark evaluation are described as separate contributions without any quoted reduction showing that the reported accuracy equals a training fit by construction. No self-citation load-bearing or uniqueness theorems appear. The central claim is an empirical comparison against external models on the new benchmark and is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning with custom reward mechanisms can improve MLLM reasoning on UI screenshots
Reference graph
Works this paper leans on
-
[1]
The role of large lan- guage models in ui/ux design: A systematic literature review,
Ammar Ahmed and Ali Shariq Imran. The role of large lan- guage models in ui/ux design: A systematic literature review,
-
[2]
Claude 3.7 sonnet and claude code.https: / / www
Anthropic. Claude 3.7 sonnet and claude code.https: / / www . anthropic . com / news / claude - 3 - 7 - sonnet, 2025. Accessed: 2025-02-25. 7
2025
-
[3]
Introducing claude 4.https : / / www
Anthropic. Introducing claude 4.https : / / www . anthropic.com/news/claude-4, 2025. Accessed: 2025-05-23. 7
2025
-
[4]
Introducing claude 4.5.https : / / www
Anthropic. Introducing claude 4.5.https : / / www . anthropic . com / news / claude - sonnet - 4 - 5,
-
[5]
Accessed: 2025-09-30. 7
2025
-
[6]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023. 2
Pith/arXiv arXiv 2023
-
[7]
Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
Pith/arXiv arXiv 2025
-
[8]
From leader to laggard: An analysis of blackberry’s ui/ux missteps and the decline of a tech giant.Milestone Transactions on Futuristic Engineer- ing, 1(1):1–12, 2023
P Bharath, DB Damodhar, et al. From leader to laggard: An analysis of blackberry’s ui/ux missteps and the decline of a tech giant.Milestone Transactions on Futuristic Engineer- ing, 1(1):1–12, 2023. 1
2023
-
[9]
Eric Brangier, Josefina Gil Urrutia, V ´eronique Senderowicz, and Laurent Cessat. Beyond ”usability and user experience” , towards an integrative heuristic inspection: from accessibil- ity to persuasiveness in the ux evaluation a case study on an insurance prospecting tablet application, 2018. 3
2018
-
[10]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024. 3
2024
-
[11]
Chenhui Cui, Tao Li, Junjie Wang, Chunyang Chen, Dave Towey, and Rubing Huang. Large language models for mo- bile gui text input generation: An empirical study.arXiv preprint arXiv:2404.08948, 2024. 2
Pith/arXiv arXiv 2024
-
[12]
Rico: A mobile app dataset for building data- driven design applications
Biplab Deka, Zifeng Huang, Chad Franzen, Joshua Hib- schman, Daniel Afergan, Yang Li, Jeffrey Nichols, and Ran- jitha Kumar. Rico: A mobile app dataset for building data- driven design applications. InProceedings of the 30th annual ACM symposium on user interface software and technology, pages 845–854, 2017. 2
2017
-
[13]
Mobile-bench: An evaluation benchmark for llm- based mobile agents
Shihan Deng, Weikai Xu, Hongda Sun, Wei Liu, Tao Tan, Liujianfeng Liujianfeng, Ang Li, Jian Luan, Bin Wang, Rui Yan, et al. Mobile-bench: An evaluation benchmark for llm- based mobile agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8813–8831, 2024. 1
2024
-
[14]
To- wards generating ui design feedback with llms
Peitong Duan, Jeremy Warner, and Bjoern Hartmann. To- wards generating ui design feedback with llms. InAdjunct Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1–3, 2023. 1
2023
-
[15]
Zheng Lian, Haoyu Chen, Lan Chen, Haiyang Sun, Licai Sun, Yong Ren, Zebang Cheng, Bin Liu, Rui Liu, Xiaojiang Peng, et al. Affectgpt: A new dataset, model, and benchmark for emotion understanding with multimodal large language models.arXiv preprint arXiv:2501.16566, 2025. 1
arXiv 2025
-
[16]
Showui: One vision-language-action model for gui visual agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weixian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gui visual agent. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19498– 19508, 2025. 1
2025
-
[17]
Improved baselines with visual instruction tuning, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2024. 3
2024
-
[18]
Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024. 7
2024
-
[19]
Harnessing webpage uis for text-rich visual understand- ing.arXiv preprint arXiv:2410.13824, 2024
Junpeng Liu, Tianyue Ou, Yifan Song, Yuxiao Qu, Wai Lam, Chenyan Xiong, Wenhu Chen, Graham Neubig, and Xiang Yue. Harnessing webpage uis for text-rich visual understand- ing.arXiv preprint arXiv:2410.13824, 2024. 4
arXiv 2024
-
[20]
Visualwebbench: How far have multimodal llms evolved in web page under- standing and grounding?, 2024
Junpeng Liu, Yifan Song, Bill Yuchen Lin, Wai Lam, Gra- ham Neubig, Yuanzhi Li, and Xiang Yue. Visualwebbench: How far have multimodal llms evolved in web page under- standing and grounding?, 2024. 1, 2
2024
-
[21]
Nighthawk: Fully automated localizing ui display issues via visual understanding.IEEE Transac- tions on Software Engineering, 49(1):403–418, 2022
Zhe Liu, Chunyang Chen, Junjie Wang, Yuekai Huang, Jun Hu, and Qing Wang. Nighthawk: Fully automated localizing ui display issues via visual understanding.IEEE Transac- tions on Software Engineering, 49(1):403–418, 2022. 3
2022
-
[22]
Guiodyssey: A comprehensive dataset for cross-app gui navigation on mobile devices
Quanfeng Lu, Wenqi Shao, Zitao Liu, Lingxiao Du, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, and Ping Luo. Guiodyssey: A comprehensive dataset for cross-app gui navigation on mobile devices. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 22404–22414, 2025. 1
2025
-
[23]
Ui layout generation with llms guided by ui grammar, 2023
Yuwen Lu, Ziang Tong, Qinyi Zhao, Chengzhi Zhang, and Toby Jia-Jun Li. Ui layout generation with llms guided by ui grammar, 2023. 1
2023
-
[24]
Grpo-λ: Credit assignment improves llm reasoning, 2025
Prasanna Parthasarathi, Mathieu Reymond, Boxing Chen, Yufei Cui, and Sarath Chandar. Grpo-λ: Credit assignment improves llm reasoning, 2025. 3
2025
-
[25]
Qwen3-vl: Sharper vision, deeper thought, broader action.https : / / qwen
Qwen. Qwen3-vl: Sharper vision, deeper thought, broader action.https : / / qwen . ai / blog ? id = 99f0335c4ad9ff6153e517418d48535ab6d8afef& from = research . latest - advancements - list,
-
[26]
Accessed: 2025-09-23. 7
2025
-
[27]
Guardian: A runtime framework for llm-based ui exploration
Dezhi Ran, Hao Wang, Zihe Song, Mengzhou Wu, Yuan Cao, Ying Zhang, Wei Yang, and Tao Xie. Guardian: A runtime framework for llm-based ui exploration. InProceed- ings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, pages 958–970, 2024. 1
2024
-
[28]
Visual cot: Unleashing chain-of-thought reasoning in multi-modal language models.CoRR, 2024
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuo- fan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Unleashing chain-of-thought reasoning in multi-modal language models.CoRR, 2024. 3
2024
-
[29]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. 2
2024
-
[30]
Owleyes-online: a fully automated platform for de- tecting and localizing ui display issues
Yuhui Su, Zhe Liu, Chunyang Chen, Junjie Wang, and Qing Wang. Owleyes-online: a fully automated platform for de- tecting and localizing ui display issues. InProceedings of the 29th ACM joint meeting on european software engineering conference and symposium on the foundations of software engineering, pages 1500–1504, 2021. 3
2021
-
[31]
The metamorphosis: Automatic detection of scaling issues for mobile apps
Yuhui Su, Chunyang Chen, Junjie Wang, Zhe Liu, Dandan Wang, Shoubin Li, and Qing Wang. The metamorphosis: Automatic detection of scaling issues for mobile apps. In Proceedings of the 37th IEEE/ACM International Confer- ence on Automated Software Engineering, pages 1–12, 2022. 3
2022
-
[32]
Dialoguemllm: Transform- ing multimodal emotion recognition in conversation through instruction-tuned mllm.IEEE Access, 2025
Yuanyuan Sun and Ting Zhou. Dialoguemllm: Transform- ing multimodal emotion recognition in conversation through instruction-tuned mllm.IEEE Access, 2025. 1
2025
-
[33]
Glm-4.5v and glm-4.1v-thinking: Towards versatile multi- modal reasoning with scalable reinforcement learning, 2025
V Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Bin Chen, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiale Zhu, Jiali Chen, J...
2025
-
[34]
Screen2words: Automatic mobile ui summarization with multimodal learning, 2021
Bryan Wang, Gang Li, Xin Zhou, Zhourong Chen, Tovi Grossman, and Yang Li. Screen2words: Automatic mobile ui summarization with multimodal learning, 2021. 1, 2
2021
-
[35]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Jun- yang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2
Pith/arXiv arXiv 2024
-
[36]
Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Sheng- long Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 3, 7
Pith/arXiv arXiv 2025
-
[37]
Factors influencing the perceived usabil- ity of mobile applications, 2025
Pawel Weichbroth. Factors influencing the perceived usabil- ity of mobile applications, 2025. 3
2025
-
[38]
Beyond token length: Step pruner for efficient and accurate reasoning in large language models, 2025
Canhui Wu, Qiong Cao, Chang Li, Zhenfang Wang, Chao Xue, Yuwei Fan, Wei Xi, and Xiaodong He. Beyond token length: Step pruner for efficient and accurate reasoning in large language models, 2025. 3
2025
-
[39]
Mimo-vl technical report, 2025
LLM-Core-Team Xiaomi. Mimo-vl technical report, 2025. 7
2025
-
[40]
Uisgpt: Automated mobile ui design smell detection with large language models.Elec- tronics, 13(16):3127, 2024
Bo Yang and Shanping Li. Uisgpt: Automated mobile ui design smell detection with large language models.Elec- tronics, 13(16):3127, 2024. 3
2024
-
[41]
Ui-ug: A unified mllm for ui understanding and generation, 2025
Hao Yang, Weijie Qiu, Ru Zhang, Zhou Fang, Ruichao Mao, Xiaoyu Lin, Maji Huang, Zhaosong Huang, Teng Guo, Shuoyang Liu, and Hai Rao. Ui-ug: A unified mllm for ui understanding and generation, 2025. 1, 2
2025
-
[42]
Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024. 7
Pith/arXiv arXiv 2024
-
[43]
Ferret-ui: Grounded mobile ui understanding with mul- timodal llms
Keen You, Haotian Zhang, Eldon Schoop, Floris Weers, Amanda Swearngin, Jeffrey Nichols, Yinfei Yang, and Zhe Gan. Ferret-ui: Grounded mobile ui understanding with mul- timodal llms. InEuropean Conference on Computer Vision, pages 240–255. Springer, 2024. 1
2024
-
[44]
Coree- val: Automatically building contamination-resilient datasets with real-world knowledge toward reliable llm evaluation
Jingqian Zhao, Bingbing Wang, Geng Tu, Yice Zhang, Qian- long Wang, Bin Liang, Jing Li, and Ruifeng Xu. Coree- val: Automatically building contamination-resilient datasets with real-world knowledge toward reliable llm evaluation. InProceedings of the 63rd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), page 22284...
2025
-
[45]
Siyan Zhao, Mingyi Hong, Yang Liu, Devamanyu Hazarika, and Kaixiang Lin. Do llms recognize your preferences? evaluating personalized preference following in llms.arXiv preprint arXiv:2502.09597, 2025. 1
arXiv 2025
-
[46]
Minigpt-4: Enhancing vision-language understanding with advanced large language models, 2023
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models, 2023. 3
2023
-
[47]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 3
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.