Understanding helpfulness and harmless tension in reward models
Pith reviewed 2026-06-27 07:04 UTC · model grok-4.3
The pith
Reward models trained on both helpfulness and harmlessness underperform those trained on either goal alone because shared neurons create interference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
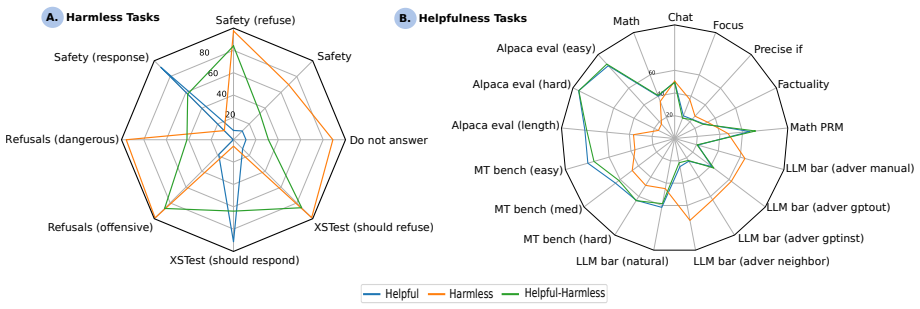
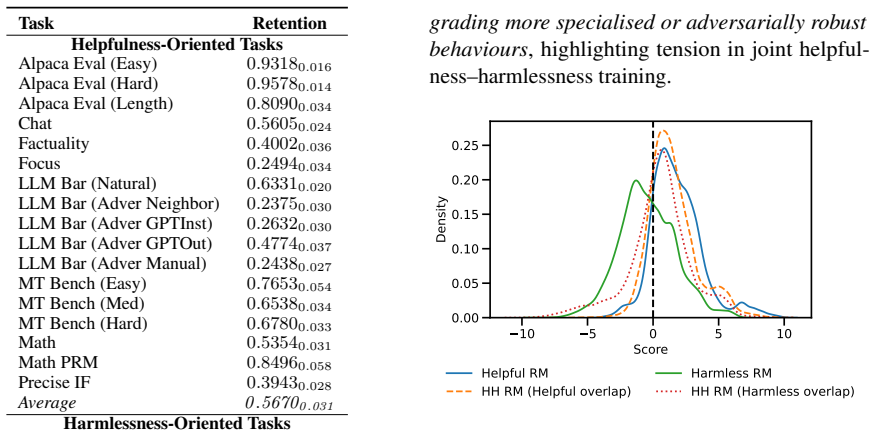
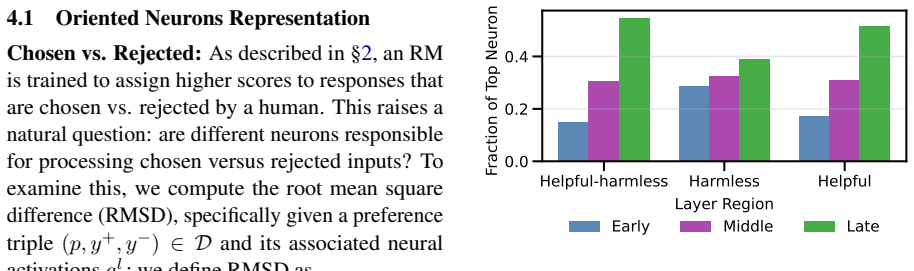
Mixed-objective reward models underperform single-objective models because neurons associated with helpfulness and harmlessness overlap substantially; these shared neurons causally support their own objective while harming the opposing one, producing measurable interference that single-objective training avoids.
What carries the argument
Activation-based neuron identification combined with targeted ablation, used to isolate and test the causal contribution of objective-specific and shared neurons to model outputs.
If this is right
- Neurons tied to one objective reliably impair the other when both are trained together.
- Shared neurons between the two objectives drive most of the observed behavioral conflict.
- Single-objective training sidesteps the interference that mixed training encounters.
- Alignment tension in reward models arises inside the network rather than solely from conflicting human preferences.
Where Pith is reading between the lines
- Methods that explicitly separate or suppress shared neurons could reduce the performance cost of multi-objective training.
- The same activation-ablation approach might be applied to other pairs of alignment goals to test whether overlap is a general source of tension.
- If shared neurons prove central, training procedures that encourage neuron specialization could improve controllability of reward models.
Load-bearing premise
That the activation patterns and ablations correctly isolate the neurons whose removal explains the measured performance gaps between mixed and single-objective training.
What would settle it
Re-train the mixed model after ablating the identified shared neurons and check whether the performance gap to the single-objective models shrinks or disappears while overall capability remains intact.
Figures


read the original abstract
Reward models are a key component of reinforcement learning from human feedback (RLHF), aligning language models toward both helpful and harmless behaviour. However, the internal mechanisms underlying these objectives and their conflicts remain poorly understood. We study alignment tension in reward models trained under helpfulness-only, harmlessness-only, and mixed-objective settings. We find that mixed-objective models often underperform single-objective models, indicating interference between objectives. Using activation-based methods, we identify neurons associated with each objective and study their functional roles via targeted ablations. We find that these neurons causally support their corresponding objectives while often negatively affecting the opposing one. We find that a substantial proportion of neurons are shared between helpfulness and harmlessness, and that these shared neurons exert a disproportionate influence on model behaviour, contributing to alignment tension. Additionally, our results provide insights and mechanistic interpretation into how alignment objectives are represented in reward models and why multi-objective alignment remains challenging, motivating future work on disentangled and controllable alignment methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines reward models trained under helpfulness-only, harmlessness-only, and mixed-objective regimes in RLHF. It reports that mixed-objective models underperform single-objective models, uses activation-based methods to identify objective-associated neurons, performs targeted ablations showing these neurons support their target objective while often harming the opposing one, and finds that a substantial fraction of neurons are shared across objectives with disproportionate behavioral influence, thereby contributing to alignment tension.
Significance. If the causal claims hold after appropriate controls, the work supplies concrete mechanistic evidence for objective interference inside reward models and identifies shared neurons as a key locus of tension. This could inform the design of disentangled alignment methods. The use of ablation to test functional roles is a positive feature, though the absence of matched controls limits the strength of the attribution.
major comments (2)
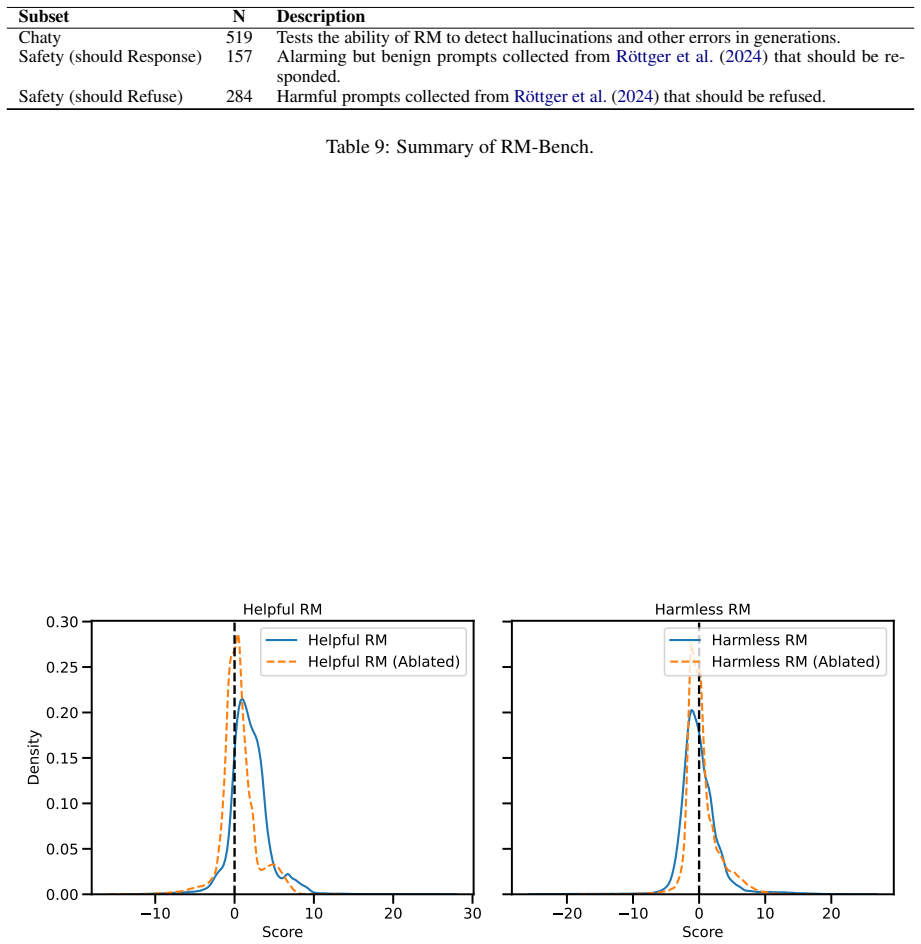
- [Ablation experiments (results section)] The central claim that shared neurons drive the observed performance gap between mixed- and single-objective models rests on activation-based neuron identification followed by targeted ablations. The manuscript does not report control ablations on neurons matched for activation strength or sparsity but unselected by the helpfulness/harmlessness criteria, nor does it quantify the residual mixed-objective gap after ablating only non-shared neurons. Without these controls the attribution remains correlational.
- [Abstract and methods] The abstract states that ablation results and shared-neuron proportions support the interference claim, yet full details on datasets, training hyperparameters, statistical controls, and exact neuron-selection thresholds are not visible. This makes it impossible to assess whether post-hoc selection or model choices affect the reported proportions and performance differences.
minor comments (2)
- [Methods] Notation for neuron activation metrics and sharing criteria should be defined explicitly with equations or pseudocode.
- [Figures] Figure legends should include the number of runs or seeds underlying reported means and error bars.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major point below, indicating planned revisions where the concerns are valid.
read point-by-point responses
-
Referee: [Ablation experiments (results section)] The central claim that shared neurons drive the observed performance gap between mixed- and single-objective models rests on activation-based neuron identification followed by targeted ablations. The manuscript does not report control ablations on neurons matched for activation strength or sparsity but unselected by the helpfulness/harmlessness criteria, nor does it quantify the residual mixed-objective gap after ablating only non-shared neurons. Without these controls the attribution remains correlational.
Authors: We agree that matched control ablations would strengthen causal attribution beyond the current targeted interventions. The existing ablations demonstrate directional effects consistent with objective-specific support and cross-objective interference. In revision we will add control ablations on neurons matched for activation strength and sparsity but unselected by the objective criteria, and we will report the residual mixed-objective performance gap after ablating only non-shared neurons. revision: yes
-
Referee: [Abstract and methods] The abstract states that ablation results and shared-neuron proportions support the interference claim, yet full details on datasets, training hyperparameters, statistical controls, and exact neuron-selection thresholds are not visible. This makes it impossible to assess whether post-hoc selection or model choices affect the reported proportions and performance differences.
Authors: The Methods section and appendix already contain the requested details on datasets, hyperparameters, statistical procedures, and neuron-selection thresholds. To improve accessibility we will revise the abstract to explicitly reference these sections and will add a dedicated methods subsection that consolidates all selection criteria and controls. revision: partial
Circularity Check
No significant circularity in empirical analysis
full rationale
The paper reports empirical results from training reward models under single- and mixed-objective settings, followed by activation-based neuron identification and targeted ablations. No mathematical derivations, first-principles predictions, or equations are presented whose outputs reduce to the inputs by construction. Central claims rest on experimental observations of performance gaps and ablation effects rather than self-definitional mappings, fitted parameters renamed as predictions, or load-bearing self-citation chains. The work is self-contained against external benchmarks via direct model training and intervention experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 28th international conference on intelligent user interfaces , pages=
The programmer’s assistant: Conversational interaction with a large language model for software development , author=. Proceedings of the 28th international conference on intelligent user interfaces , pages=
-
[2]
arXiv preprint arXiv:2307.04657 , year =
BeaverTails: Towards Improved Safety Alignment of LLM via a Human-Preference Dataset , author =. arXiv preprint arXiv:2307.04657 , year =
-
[3]
Ahmadian, Arash and Cremer, Chris and Gall. Back to Basics: Revisiting REINFORCE -Style Optimization for Learning from Human Feedback in LLM s. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.662
-
[4]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[5]
Ma, Zilin and Mei, Yiyang and Long, Yinru and Su, Zhaoyuan and Gajos, Krzysztof Z. , title =. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , articleno =. 2024 , isbn =. doi:10.1145/3613904.3642482 , abstract =
-
[6]
The 2023 Conference on Empirical Methods in Natural Language Processing , year=
Cross-Lingual Consistency of Factual Knowledge in Multilingual Language Models , author=. The 2023 Conference on Empirical Methods in Natural Language Processing , year=
2023
-
[7]
Tanwar, Eshaan and Chatterjee, Anwoy and Saxon, Michael and Albalak, Alon and Wang, William Yang and Chakraborty, Tanmoy. Do You Know About My Nation? Investigating Multilingual Language Models' Cultural Literacy Through Factual Knowledge. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.em...
-
[8]
2025 , url=
Yantao Liu and Zijun Yao and Rui Min and Yixin Cao and Lei Hou and Juanzi Li , booktitle=. 2025 , url=
2025
-
[9]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[10]
The Twelfth International Conference on Learning Representations , year=
Evaluating Large Language Models at Evaluating Instruction Following , author=. The Twelfth International Conference on Learning Representations , year=
-
[11]
R. XST est: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.301
-
[12]
Do-Not-Answer: Evaluating Safeguards in LLM s
Wang, Yuxia and Li, Haonan and Han, Xudong and Nakov, Preslav and Baldwin, Timothy. Do-Not-Answer: Evaluating Safeguards in LLM s. Findings of the Association for Computational Linguistics: EACL 2024. 2024. doi:10.18653/v1/2024.findings-eacl.61
-
[13]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[14]
Hashimoto , title =
Xuechen Li and Tianyi Zhang and Yann Dubois and Rohan Taori and Ishaan Gulrajani and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , month =
2023
-
[15]
2025 , eprint=
RewardBench 2: Advancing Reward Model Evaluation , author=. 2025 , eprint=
2025
-
[16]
Forty-second International Conference on Machine Learning , year=
Layer by Layer: Uncovering Hidden Representations in Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[17]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Demystifying the roles of llm layers in retrieval, knowledge, and reasoning , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[18]
Towards Understanding Safety Alignment: A Mechanistic Perspective from Safety Neurons , url =
Chen, Jianhui and Wang, Xiaozhi and Yao, Zijun and Bai, Yushi and Hou, Lei and Li, Juanzi , booktitle =. Towards Understanding Safety Alignment: A Mechanistic Perspective from Safety Neurons , url =
-
[19]
arXiv preprint arXiv:2507.00665 , year=
Safer: Probing safety in reward models with sparse autoencoder , author=. arXiv preprint arXiv:2507.00665 , year=
-
[20]
Advances in Neural Information Processing Systems , volume=
Rewarded soups: towards pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Interpretable reward model via sparse autoencoder , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[22]
2024 , eprint=
RewardBench: Evaluating Reward Models for Language Modeling , author=. 2024 , eprint=
2024
-
[23]
2025 , eprint=
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model , author=. 2025 , eprint=
2025
-
[24]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[25]
Jasmine Chiat Ling Ong and Liyuan Jin and Kabilan Elangovan and Gilbert Yong San Lim and Daniel Yan Zheng Lim and Gerald Gui Ren Sng and Yu He Ke and Joshua Yi Min Tung and Ryan Jian Zhong and Christopher Ming Yao Koh and Keane Zhi Hao Lee and Xiang Chen and Jack Kian Ch’ng and Aung Than and Ken Junyang Goh and Chuan Poh Lim and Tat Ming Ng and Nan Liu an...
-
[26]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Yang, Rui and Pan, Xiaoman and Luo, Feng and Qiu, Shuang and Zhong, Han and Yu, Dong and Chen, Jianshu , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[27]
Language Models are Unsupervised Multitask Learners , author=
-
[28]
Multi-Domain Explainability of Preferences
Calderon, Nitay and Ein-Dor, Liat and Reichart, Roi. Multi-Domain Explainability of Preferences. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.736
-
[29]
arXiv preprint arXiv:2502.02737 , year=
SmolLM2: When Smol Goes Big--Data-Centric Training of a Small Language Model , author=. arXiv preprint arXiv:2502.02737 , year=
-
[30]
arXiv preprint arXiv:2501.00656 , year=
2 OLMo 2 Furious , author=. arXiv preprint arXiv:2501.00656 , year=
-
[31]
International conference on machine learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[32]
Stefano Cirillo and Domenico Desiato and Giuseppe Polese and Giandomenico Solimando and Vijayan Sugumaran and Shanmugam Sundaramurthy , keywords =. Exploring the ability of emerging large language models to detect cyberbullying in social posts through new prompt-based classification approaches , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.ipm....
-
[33]
Inclusive Leadership in the Age of AI : A Dataset and Comparative Study of LLM s vs
Singh, Vindhya and Schulte im Walde, Sabine and Keplinger, Ksenia. Inclusive Leadership in the Age of AI : A Dataset and Comparative Study of LLM s vs. Real-Life Leaders in Workplace Action Planning. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1075
-
[34]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Language Model Alignment with Elastic Reset , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[35]
Sight Beyond Text: Multi-Modal Training Enhances
Haoqin Tu and Bingchen Zhao and Chen Wei and Cihang Xie , journal=. Sight Beyond Text: Multi-Modal Training Enhances. 2024 , url=
2024
-
[36]
Yi Dong and Zhilin Wang and Makesh Narsimhan Sreedhar and Xianchao Wu and Oleksii Kuchaiev , booktitle=. Steer. 2023 , url=
2023
-
[37]
arXiv preprint arXiv:2112.00861 , year=
A general language assistant as a laboratory for alignment , author=. arXiv preprint arXiv:2112.00861 , year=
-
[38]
2024 , url=
Zhiqing Sun and Yikang Shen and Hongxin Zhang and Qinhong Zhou and Zhenfang Chen and David Daniel Cox and Yiming Yang and Chuang Gan , booktitle=. 2024 , url=
2024
-
[39]
arXiv preprint arXiv:2401.06080 , year=
Secrets of rlhf in large language models part ii: Reward modeling , author=. arXiv preprint arXiv:2401.06080 , year=
-
[40]
Forty-second International Conference on Machine Learning , year=
On the Robustness of Reward Models for Language Model Alignment , author=. Forty-second International Conference on Machine Learning , year=
-
[41]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
HelpSteer 2: Open-source dataset for training top-performing reward models , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[42]
2024 IEEE Frontiers in Education Conference (FIE) , pages=
Future you: a conversation with an AI-generated future self reduces anxiety, negative emotions, and increases future self-continuity , author=. 2024 IEEE Frontiers in Education Conference (FIE) , pages=. 2024 , organization=
2024
-
[43]
Exploring the role of large language models in the scientific method: From hypothesis to discovery
Zhang, Yanbo and Khan, Sumeer A. and Mahmud, Adnan and Yang, Huck and Lavin, Alexander and Levin, Michael and Frey, Jeremy and Dunnmon, Jared and Evans, James and Bundy, Alan and D. Exploring the role of large language models in the scientific method: from hypothesis to discovery , journal =. 2025 , volume =. doi:10.1038/s44387-025-00019-5 , url =
-
[44]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Yuan, Hongyi and Yuan, Zheng and Tan, Chuanqi and Wang, Wei and Huang, Songfang and Huang, Fei , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[45]
Findings of the Association for Computational Linguistics: EMNLP 2024 , month = nov, year =
Wang, Haoxiang and Xiong, Wei and Xie, Tengyang and Zhao, Han and Zhang, Tong. Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.620
-
[46]
The Thirteenth International Conference on Learning Representations , year=
Interpreting Language Reward Models via Contrastive Explanations , author=. The Thirteenth International Conference on Learning Representations , year=
-
[47]
The Thirteenth International Conference on Learning Representations , year=
On the Role of Attention Heads in Large Language Model Safety , author=. The Thirteenth International Conference on Learning Representations , year=
-
[48]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[49]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[50]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[51]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[52]
2025 , eprint=
OpenAI GPT-5 System Card , author=. 2025 , eprint=
2025
-
[53]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[54]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[55]
arXiv preprint arXiv:2204.05862 , year=
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
-
[56]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Kevin Ro Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , url=
2023
-
[57]
Transactions on Machine Learning Research , issn=
Finding Neurons in a Haystack: Case Studies with Sparse Probing , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[58]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[59]
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Singer, Yaron and Shieber, Stuart , booktitle =. Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
-
[60]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex J Andonian and Yonatan Belinkov , booktitle=. Locating and Editing Factual Associations in. 2022 , url=
2022
-
[61]
Ghandeharioun, A., Caciularu, A., Pearce, A., Dixon, L., and Geva, M
Geva, Mor and Schuster, Roei and Berant, Jonathan and Levy, Omer. Transformer Feed-Forward Layers Are Key-Value Memories. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.446
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[62]
and Leike, Jan and Brown, Tom B
Christiano, Paul F. and Leike, Jan and Brown, Tom B. and Martic, Miljan and Legg, Shane and Amodei, Dario , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[63]
and Lowe, Ryan and Voss, Chelsea and Radford, Alec and Amodei, Dario and Christiano, Paul , title =
Stiennon, Nisan and Ouyang, Long and Wu, Jeff and Ziegler, Daniel M. and Lowe, Ryan and Voss, Chelsea and Radford, Alec and Amodei, Dario and Christiano, Paul , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , isbn =
2020
-
[64]
2022 , eprint=
Constitutional AI: Harmlessness from AI Feedback , author=. 2022 , eprint=
2022
-
[65]
Chen, Tianyi , title =. Proceedings of the 2024 International Conference on Generative Artificial Intelligence and Information Security , pages =. 2024 , isbn =. doi:10.1145/3665348.3665383 , abstract =
-
[66]
The Colorful Future of LLM s: Evaluating and Improving LLM s as Emotional Supporters for Queer Youth
Lissak, Shir and Calderon, Nitay and Shenkman, Geva and Ophir, Yaakov and Fruchter, Eyal and Brunstein Klomek, Anat and Reichart, Roi. The Colorful Future of LLM s: Evaluating and Improving LLM s as Emotional Supporters for Queer Youth. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.