Evaluating Pluralism in LLMs through Latent Perspectives
Pith reviewed 2026-06-27 06:35 UTC · model grok-4.3
The pith
LLM-generated text shows narrower distributions of latent perspectives than human text, especially missing rarer viewpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that while some LLMs and prompting techniques approach the spectrum of perspectives found in human book reviews, rarer perspectives remain disproportionately underrepresented, producing distributions that diverge from those in human text.
What carries the argument
The domain-agnostic multi-layered framework for unsupervised extraction of perspectives, which identifies viewpoints without labeled data and enables direct comparison between human and LLM text.
If this is right
- Rarer perspectives remain missing even under prompting techniques that aim for diversity.
- Overall perspective distributions in LLM text differ measurably from human text on opinionated domains.
- The framework supplies a quantitative signal that can be tracked when testing new alignment methods.
- Models that perform better on broad coverage still leave gaps on the tail of the perspective distribution.
Where Pith is reading between the lines
- The same gap could appear in other opinionated domains such as news or product feedback if the framework is applied there.
- Training-data filtering or reinforcement steps that reduce tail diversity offer one possible mechanism for the observed underrepresentation.
- Prompting alone may be insufficient; architectural or data-level changes might be needed to restore rarer perspectives.
Load-bearing premise
The unsupervised framework accurately and consistently extracts the same latent perspectives across texts so that human and LLM distributions can be compared fairly.
What would settle it
An independent analysis of the same book-review corpus that finds identical perspective distributions between human text and LLM outputs would falsify the reported divergence.
Figures

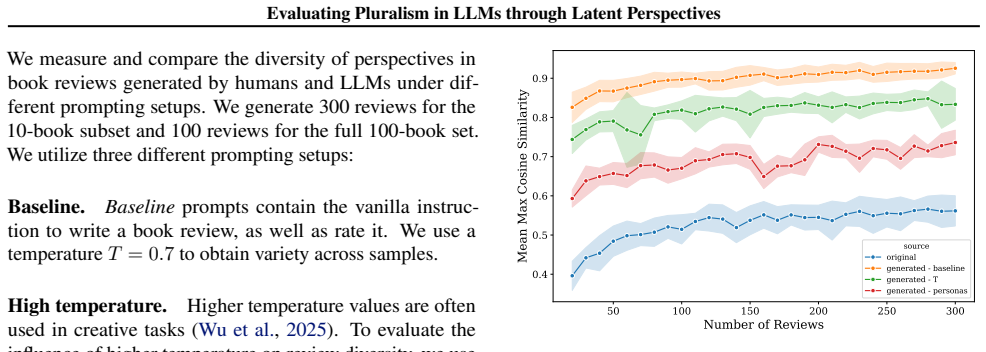
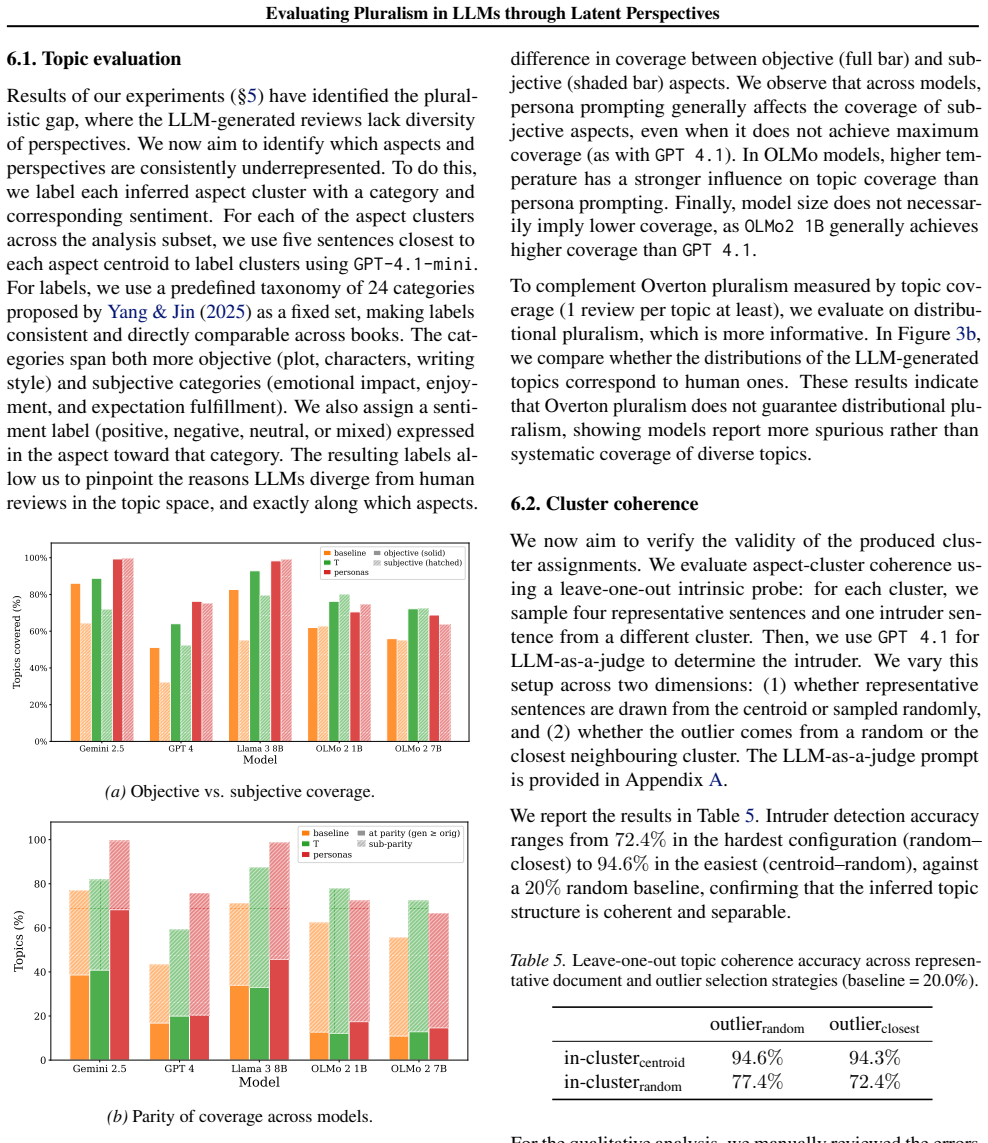
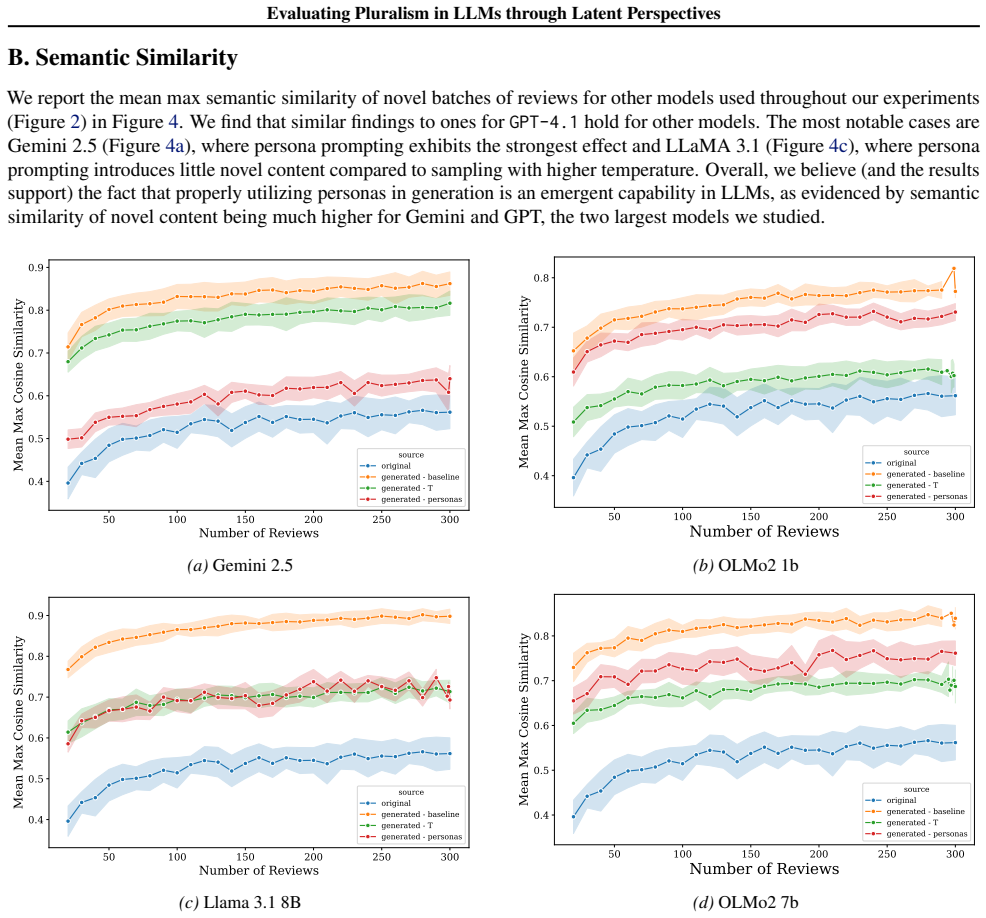
read the original abstract
The growing need to represent diverse perspectives has increased interest in pluralistic LLM generation. Although difficult to operationalize, identifying perspectives expressed in text would provide clear guidance on pluralistic alignment and more clearly articulate the pluralistic gap in LLM generation. While models have been shown to reduce the diversity of training data and generate homogeneously, this has been demonstrated primarily on multiple-choice questionnaires or using high-level characteristics of free-form text. In this paper, we introduce and implement a domain-agnostic multi-layered framework for unsupervised extraction of perspectives suitable for identifying the pluralistic gap in LLM-generated text. We evaluate our framework on book reviews, a highly opinionated dataset representing diverse perspectives, and compare various prompts and models. Our results show that while some models and prompting techniques come close to covering a broad spectrum of perspectives, rarer perspectives remain disproportionately underrepresented, resulting in distributions that diverge from human text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a domain-agnostic multi-layered unsupervised framework for extracting latent perspectives from text. Applied to book reviews, it compares perspective distributions in human-written versus LLM-generated text under various models and prompts, concluding that LLMs underrepresent rarer perspectives and produce distributions that diverge from human text.
Significance. If the framework reliably recovers comparable perspective spaces, the approach would provide a text-based, unsupervised alternative to questionnaire-style pluralism evaluations and could guide targeted alignment interventions for underrepresented viewpoints.
major comments (3)
- [Methods] Methods (framework description): the manuscript presents the multi-layered unsupervised extraction process but reports no human-annotated gold labels, inter-rater reliability metrics, or stability ablations across layers; without these, it is impossible to establish that the discovered perspectives are stable, meaningful, and comparable between human and LLM corpora rather than artifacts of the procedure interacting with stylistic differences.
- [Results] Results (distribution comparison): the headline claim that LLM distributions diverge because rarer perspectives are underrepresented rests on the assumption that the same underlying perspective space is recovered in both corpora; the absence of any cross-validation or error analysis leaves open the possibility that observed divergence arises from method-specific sensitivities rather than genuine pluralism gaps.
- [Evaluation] Evaluation setup: no statistical tests, confidence intervals, or sensitivity analyses are described for the reported distributional differences, so the strength of evidence for the pluralistic gap cannot be assessed.
minor comments (2)
- [Abstract/Introduction] The abstract and introduction would benefit from a concise statement of the number of layers, the precise clustering or embedding steps, and the domain-agnostic claim's scope.
- [Figures/Tables] Figure captions and table headers should explicitly define the perspective categories or distance metrics used in the comparisons.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below and indicate where revisions will be made to strengthen the validation of the framework.
read point-by-point responses
-
Referee: [Methods] Methods (framework description): the manuscript presents the multi-layered unsupervised extraction process but reports no human-annotated gold labels, inter-rater reliability metrics, or stability ablations across layers; without these, it is impossible to establish that the discovered perspectives are stable, meaningful, and comparable between human and LLM corpora rather than artifacts of the procedure interacting with stylistic differences.
Authors: We agree that further validation is needed to confirm the stability and meaningfulness of the extracted perspectives. As the framework is explicitly unsupervised and domain-agnostic, constructing comprehensive human-annotated gold labels for latent perspectives is inherently difficult and not aligned with the method's design. However, we will add stability ablations across layers and inter-rater reliability metrics (where feasible via qualitative review) in the revised manuscript to demonstrate robustness and comparability between corpora. revision: partial
-
Referee: [Results] Results (distribution comparison): the headline claim that LLM distributions diverge because rarer perspectives are underrepresented rests on the assumption that the same underlying perspective space is recovered in both corpora; the absence of any cross-validation or error analysis leaves open the possibility that observed divergence arises from method-specific sensitivities rather than genuine pluralism gaps.
Authors: We will incorporate cross-validation procedures and error analysis in the revised results section to directly test whether the same perspective space is recovered across human and LLM corpora. This addition will help rule out method-specific artifacts and provide stronger support for the observed distributional differences. revision: yes
-
Referee: [Evaluation] Evaluation setup: no statistical tests, confidence intervals, or sensitivity analyses are described for the reported distributional differences, so the strength of evidence for the pluralistic gap cannot be assessed.
Authors: We acknowledge this limitation in the current evaluation. In the revision, we will include appropriate statistical tests, confidence intervals, and sensitivity analyses for all reported distributional comparisons to allow readers to properly assess the strength of evidence regarding the pluralistic gap. revision: yes
Circularity Check
No significant circularity; empirical comparison stands independently
full rationale
The paper introduces an unsupervised multi-layered framework and applies it separately to human and LLM-generated book reviews to compare perspective distributions. No load-bearing step reduces the reported divergence result to a self-definition, a fitted parameter renamed as a prediction, or a self-citation chain. The framework is presented as a measurement tool whose output is then compared directly to human text; the central claim does not equate to its inputs by construction. This is the common case of a self-contained empirical evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Sorensen, Taylor and Moore, Jared and Fisher, Jillian and Gordon, Mitchell and Mireshghallah, Niloofar and Rytting, Christopher Michael and Ye, Andre and Jiang, Liwei and Lu, Ximing and Dziri, Nouha and Althoff, Tim and Choi, Yejin , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[2]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Toward a Perspectivist Turn in Ground Truthing for Predictive Computing , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2023 , month=. doi:10.1609/aaai.v37i6.25840 , number=
-
[3]
The Thirteenth International Conference on Learning Representations , year=
Generative Monoculture in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[4]
Mengting Wan and Julian J. McAuley , editor =. Item recommendation on monotonic behavior chains , booktitle =. 2018 , url =. doi:10.1145/3240323.3240369 , timestamp =
-
[5]
2025 , eprint=
The Pluralistic Moral Gap: Understanding Judgment and Value Differences between Humans and Large Language Models , author=. 2025 , eprint=
2025
-
[6]
Advances in Neural Information Processing Systems , volume=
Mauve: Measuring the gap between neural text and human text using divergence frontiers , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
2025 , eprint=
Mind the Gap: Conformative Decoding to Improve Output Diversity of Instruction-Tuned Large Language Models , author=. 2025 , eprint=
2025
-
[8]
Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R
Carlos E. Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R. Narasimhan , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[9]
Long Phan and Alice Gatti and Ziwen Han and Nathaniel Li and Josephina Hu and Hugh Zhang and Chen Bo Calvin Zhang and Mohamed Shaaban and John Ling and Sean Shi and Michael Choi and Anish Agrawal and Arnav Chopra and Adam Khoja and Ryan Kim and Richard Ren and Jason Hausenloy and Oliver Zhang and Mantas Mazeika and Summer Yue and Alexandr Wang and Dan Hen...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.14249 2025
-
[10]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond) , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[11]
Seeing Things from a Different Angle:Discovering Diverse Perspectives about Claims
Chen, Sihao and Khashabi, Daniel and Yin, Wenpeng and Callison-Burch, Chris and Roth, Dan. Seeing Things from a Different Angle:Discovering Diverse Perspectives about Claims. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 201...
-
[12]
2025 , eprint=
2 OLMo 2 Furious , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
F2LLM Technical Report: Matching SOTA Embedding Performance with 6 Million Open-Source Data , author=. 2025 , eprint=
2025
-
[14]
arXiv preprint arXiv:2203.05794 , year=
BERTopic: Neural topic modeling with a class-based TF-IDF procedure , author=. arXiv preprint arXiv:2203.05794 , year=
-
[15]
2025 , eprint=
Scaling Synthetic Data Creation with 1,000,000,000 Personas , author=. 2025 , eprint=
2025
-
[16]
Campello, Ricardo J. G. B. and Moulavi, Davoud and Sander, Joerg. Density-Based Clustering Based on Hierarchical Density Estimates. Advances in Knowledge Discovery and Data Mining. 2013
2013
-
[17]
First Conference on Language Modeling , year=
Towards Measuring the Representation of Subjective Global Opinions in Language Models , author=. First Conference on Language Modeling , year=
-
[18]
2025 , eprint=
Steerable Pluralism: Pluralistic Alignment via Few-Shot Comparative Regression , author=. 2025 , eprint=
2025
-
[19]
Nature Machine Intelligence , volume=
Large language models that replace human participants can harmfully misportray and flatten identity groups , author=. Nature Machine Intelligence , volume=. 2025 , publisher=
2025
-
[20]
SPICA : Retrieving Scenarios for Pluralistic In-Context Alignment
Chen, Quan Ze and Feng, Kevin and Park, Chan Young and Zhang, Amy X. SPICA : Retrieving Scenarios for Pluralistic In-Context Alignment. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.41
-
[21]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , journal=. The
-
[22]
Voices in a Crowd: Searching for clusters of unique perspectives
Vitsakis, Nikolas and Parekh, Amit and Konstas, Ioannis. Voices in a Crowd: Searching for clusters of unique perspectives. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.696
-
[23]
Modeling Frames in Argumentation
Ajjour, Yamen and Alshomary, Milad and Wachsmuth, Henning and Stein, Benno. Modeling Frames in Argumentation. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1290
-
[24]
2024 , eprint=
DataComp-LM: In search of the next generation of training sets for language models , author=. 2024 , eprint=
2024
-
[25]
Classification and Clustering of Arguments with Contextualized Word Embeddings
Reimers, Nils and Schiller, Benjamin and Beck, Tilman and Daxenberger, Johannes and Stab, Christian and Gurevych, Iryna. Classification and Clustering of Arguments with Contextualized Word Embeddings. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1054
-
[26]
Frontiers in Artificial Intelligence , VOLUME=
Basile, Valerio and Caselli, Tommaso and Balahur, Alexandra and Ku, Lun-Wei , TITLE=. Frontiers in Artificial Intelligence , VOLUME=. 2022 , URL=. doi:10.3389/frai.2022.926435 , ISSN=
-
[27]
The Perspectivist Paradigm Shift: Assumptions and Challenges of Capturing Human Labels
Fleisig, Eve and Blodgett, Su Lin and Klein, Dan and Talat, Zeerak. The Perspectivist Paradigm Shift: Assumptions and Challenges of Capturing Human Labels. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.126
-
[28]
Are They Different? Affect, Feeling, Emotion, Sentiment, and Opinion Detection in Text , year=
Munezero, Myriam and Montero, Calkin Suero and Sutinen, Erkki and Pajunen, John , journal=. Are They Different? Affect, Feeling, Emotion, Sentiment, and Opinion Detection in Text , year=
-
[29]
Language Resources and Evaluation , volume =
Perspectivist approaches to natural language processing: a survey , author =. Language Resources and Evaluation , volume =. 2025 , doi =
2025
-
[30]
Perspective , author =. n.d. , howpublished =
-
[31]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[32]
arXiv preprint arXiv:1910.01108 , year=
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. arXiv preprint arXiv:1910.01108 , year=
Pith/arXiv arXiv 1910
-
[33]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[34]
What Matters in Evaluating Book-Length Stories? A Systematic Study of Long Story Evaluation
Yang, Dingyi and Jin, Qin. What Matters in Evaluating Book-Length Stories? A Systematic Study of Long Story Evaluation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.799
-
[35]
Smith and Hannaneh Hajishirzi , booktitle=
Evan Pete Walsh and Luca Soldaini and Dirk Groeneveld and Kyle Lo and Shane Arora and Akshita Bhagia and Yuling Gu and Shengyi Huang and Matt Jordan and Nathan Lambert and Dustin Schwenk and Oyvind Tafjord and Taira Anderson and David Atkinson and Faeze Brahman and Christopher Clark and Pradeep Dasigi and Nouha Dziri and Allyson Ettinger and Michal Guerqu...
2025
-
[36]
McInnes, Leland and Healy, John and Saul, Nathaniel and Großberger, Lukas , title =. 2018 , publisher =. doi:10.21105/joss.00861 , url =
-
[37]
Benchmarking Distributional Alignment of Large Language Models
Meister, Nicole and Guestrin, Carlos and Hashimoto, Tatsunori. Benchmarking Distributional Alignment of Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.2
-
[38]
Proceedings of the 40th International Conference on Machine Learning , pages=
Whose opinions do language models reflect? , author=. Proceedings of the 40th International Conference on Machine Learning , pages=
-
[39]
Coling 2004: Proceedings of the 20th international conference on computational linguistics , pages=
Determining the sentiment of opinions , author=. Coling 2004: Proceedings of the 20th international conference on computational linguistics , pages=
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.