Dynamic Resource Management in Production HPC Clusters
Pith reviewed 2026-06-27 05:51 UTC · model grok-4.3
The pith
A malleability framework lets HPC applications resize MPI jobs at runtime on production clusters without code changes or scheduler tweaks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
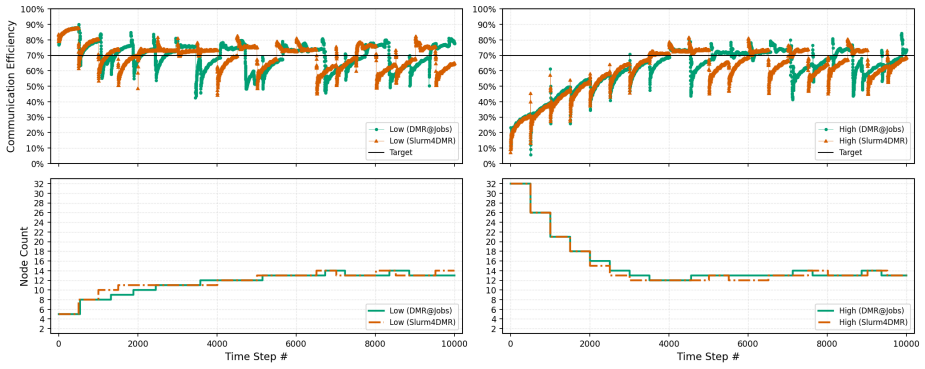
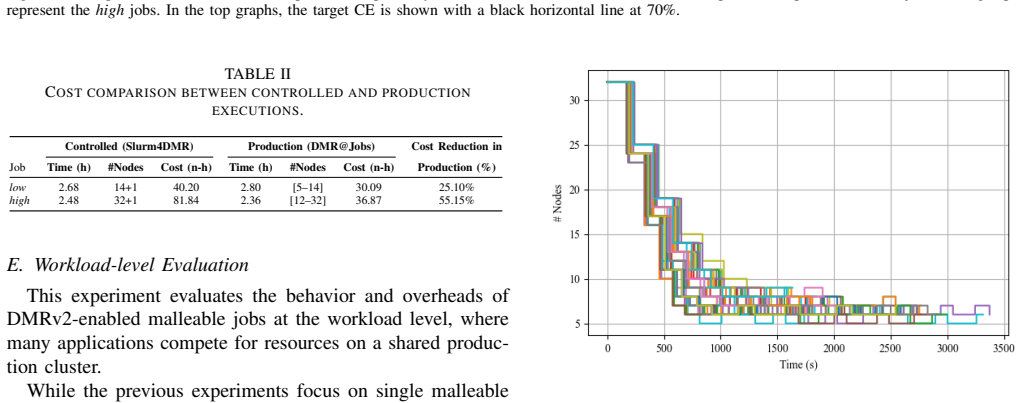
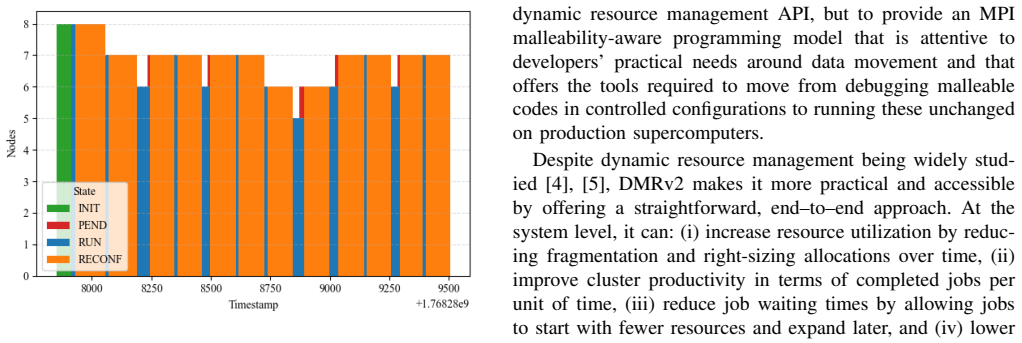
The DMR framework supplies a non-invasive MPI malleability methodology that works with current HPC software stacks and vanilla resource managers. When the API is added to two production-scale scientific applications, the resulting jobs run on three TOP500 systems with performance comparable to static allocations while consuming substantially fewer node-hours for identical workloads.
What carries the argument
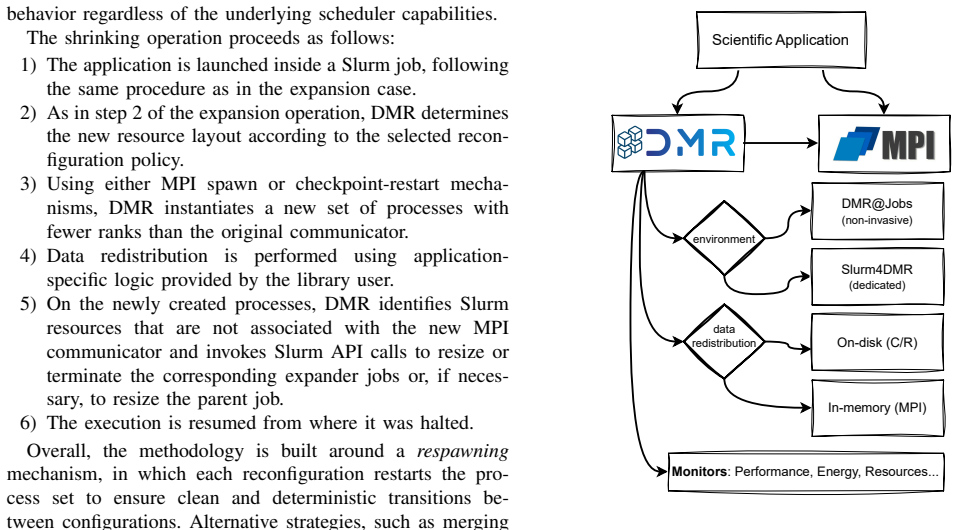
The Dynamic Management of Resources (DMR) framework and its API, which supplies the mechanism for runtime MPI process resizing without intrusive application changes or scheduler modifications.
If this is right
- Malleability becomes usable on production systems that employ standard resource managers.
- Node-hour consumption drops for workloads whose demand varies over time.
- The barrier to adopting dynamic resource management in HPC is lowered.
- Existing applications can exploit malleability without scheduler modifications.
Where Pith is reading between the lines
- Applications with phases of high and low parallelism could automatically match resources to instantaneous need.
- Similar lightweight APIs might be developed for other parallel programming models beyond MPI.
- Production schedulers could eventually incorporate malleability signals to improve overall cluster utilization.
- Energy and power budgets on large systems could be managed more precisely by shrinking allocations during low-demand periods.
Load-bearing premise
The DMR API can be added to existing large-scale scientific applications without requiring major code changes.
What would settle it
An integration attempt on a third production application that demands extensive code rewrites or produces noticeably slower runtimes than the static baseline under the same production configuration.
Figures



read the original abstract
Many large-scale scientific applications exhibit time-varying behavior, yet production HPC clusters still rely on rigid, fixed-size allocations, and most dynamic techniques remain confined to laboratory prototypes. This work presents a practical MPI malleability methodology that integrates with state-of-the-art high-performance computing (HPC) software stacks and operational practices. The methodology is implemented in the Dynamic Management of Resources (DMR) framework and is designed to ease adoption by existing applications without requiring intrusive code changes or scheduler modifications. We evaluate our approach by integrating the DMR API into two large-scale scientific applications and deploying them on three TOP500 supercomputers under realistic production configurations. Our non-invasive malleability solution achieves performance comparable to static baselines in controlled environments while substantially reducing node-hour consumption for identical workloads. These results show that malleability can be effectively exploited on production systems using vanilla resource managers, lowering the barrier to adoption of dynamic resource management in HPC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the Dynamic Management of Resources (DMR) framework implementing a practical MPI malleability methodology for production HPC clusters. It integrates with existing software stacks and schedulers without requiring intrusive application changes or scheduler modifications, evaluates the approach by integrating the DMR API into two large-scale scientific applications deployed on three TOP500 systems under realistic production configurations, and claims that the non-invasive solution achieves performance comparable to static baselines while substantially reducing node-hour consumption for identical workloads.
Significance. If the non-invasive integration claims and quantitative performance/resource results hold, the work would be significant for bridging the gap between laboratory prototypes and production HPC, as it demonstrates malleability using vanilla resource managers and could reduce barriers to adoption for time-varying scientific applications.
major comments (2)
- [Abstract] Abstract: the central claims of 'performance comparable to static baselines' and 'substantially reducing node-hour consumption' are asserted without any quantitative metrics, error bars, specific numbers, or details on evaluation methods, which is load-bearing because the headline result cannot be assessed for magnitude or statistical validity from the provided information.
- [Evaluation] Evaluation (deployment on two applications and three TOP500 systems): the non-invasiveness of DMR API integration is asserted as requiring no intrusive code changes under realistic production configurations, yet no concrete evidence (e.g., lines of code modified, specific API additions, or scheduler interaction details) is supplied; this directly undermines the workload-equivalence precondition for the performance and node-hour claims.
minor comments (1)
- The term 'non-invasive' and 'intrusive code changes' should be defined more precisely (e.g., with quantitative thresholds) to allow readers to judge integration effort consistently.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight opportunities to strengthen the abstract and provide more explicit evidence for our integration claims. We address each point below and will incorporate revisions to improve clarity and substantiation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'performance comparable to static baselines' and 'substantially reducing node-hour consumption' are asserted without any quantitative metrics, error bars, specific numbers, or details on evaluation methods, which is load-bearing because the headline result cannot be assessed for magnitude or statistical validity from the provided information.
Authors: We agree that the abstract would benefit from including representative quantitative results to make the central claims more self-contained. While the Evaluation section of the manuscript reports the detailed performance metrics (including comparisons to static baselines with variability measures across runs) and node-hour reductions on the three TOP500 systems, we will revise the abstract to incorporate key highlights from those results along with a concise reference to the evaluation methodology. revision: yes
-
Referee: [Evaluation] Evaluation (deployment on two applications and three TOP500 systems): the non-invasiveness of DMR API integration is asserted as requiring no intrusive code changes under realistic production configurations, yet no concrete evidence (e.g., lines of code modified, specific API additions, or scheduler interaction details) is supplied; this directly undermines the workload-equivalence precondition for the performance and node-hour claims.
Authors: The manuscript describes the DMR framework as designed for non-intrusive integration with existing applications and vanilla schedulers. To directly address the request for concrete evidence, we will revise the Evaluation section to add explicit details on the integration process, including the extent of code modifications for each application, the specific API elements introduced, and confirmation that no scheduler changes were required. This will better document the workload-equivalence basis for the reported results. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivations or self-referential reductions
full rationale
The paper describes an implemented DMR framework for MPI malleability, its integration into two applications, and deployment results on three TOP500 systems. All load-bearing claims are empirical performance and resource-consumption measurements under production configurations. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The non-invasiveness assertion is presented as an observed outcome of the integration effort rather than a definitional or fitted result. This matches the default expectation for an empirical systems paper whose central results rest on external machine measurements rather than internal construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Exascale workload characterization and architecture implications,
P. Balaprakash, D. Buntinas, A. Chan, A. Guha, R. Gupta, S. H. K. Narayanan, A. A. Chien, P. Hovland, and B. Norris, “Exascale workload characterization and architecture implications,” in2013 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2013, pp. 120–121. [Online]. Available: https://doi.org/10.1109/ISPASS.2013.6557153
-
[2]
Invasive computing: An overview,
J. Teich, J. Henkel, A. Herkersdorf, D. Schmitt-Landsiedel, W. Schr ¨oder- Preikschat, and G. Snelting, “Invasive computing: An overview,” Multiprocessor System-on-Chip: Hardware Design and Tool Integration, pp. 241–268, 2011. [Online]. Available: https://doi.org/10.1007/978-1 -4419-6460-1 11
-
[3]
Packing schemes for gang scheduling,
D. G. Feitelson, “Packing schemes for gang scheduling,” inJob Scheduling Strategies for Parallel Processing, 1996, pp. 89–110. [Online]. Available: https://doi.org/10.1007/BFb0022289
-
[4]
A Survey on Malleability Solutions for High-Performance Distributed Computing,
J. I. Aliaga, M. Castillo, S. Iserte, I. Mart ´ın-´Alvarez, and R. Mayo, “A Survey on Malleability Solutions for High-Performance Distributed Computing,”Applied Science, vol. 12, pp. 1–32, May 2022. [Online]. Available: https://doi.org/10.3390/app12105231
-
[5]
Malleability in modern HPC systems: Current experiences, challenges, and future opportunities,
A. Tarraf, M. Schreiber, A. Cascajo, J.-B. Besnard, M.-A. Vef, D. Huber, S. Happ, A. Brinkmann, D. E. Singh, H.-C. Hoppe, A. Miranda, A. J. Pe ˜na, R. Machado, M. G. Gasulla, M. Schulz, P. Carpenter, S. Pickartz, T. Rotaru, S. Iserte, V . Lopez, J. Ejarque, H. Sirwani, and F. Wolf, “Malleability in modern HPC systems: Current experiences, challenges, and ...
-
[6]
Slurm: Simple linux utility for resource management,
A. B. Yoo, M. A. Jette, and M. Grondona, “Slurm: Simple linux utility for resource management,” inJob Scheduling Strategies for Parallel Processing, 2003, pp. 44–60. [Online]. Available: https://doi.org/10.1007/10968987 3
-
[7]
High-throughput computation through efficient resource management,
S. Iserte, “High-throughput computation through efficient resource management,” Ph.D. Thesis, Universitat Jaume I (UJI), Spain, Nov
-
[8]
Available: http://dx.doi.org/10.6035/14101.2018.176272
[Online]. Available: http://dx.doi.org/10.6035/14101.2018.176272
-
[9]
Architecting malleable mpi applications for priority-driven adaptive scheduling,
P. Lemarinier, K. Hasanov, S. Venugopal, and K. Katrinis, “Architecting malleable mpi applications for priority-driven adaptive scheduling,” inProceedings of the 23rd European MPI Users’ Group Meeting, ser. EuroMPI ’16, New York, NY , USA, 2016, p. 74–81. [Online]. Available: https://doi.org/10.1145/2966884.2966907
-
[10]
Autonomic malleability in iterative mpi applications,
A. C. Sena, F. S. Ribeiro, V . E. Rebello, A. P. Nascimento, and C. Boeres, “Autonomic malleability in iterative mpi applications,” in 2013 25th International Symposium on Computer Architecture and High Performance Computing, 2013, pp. 192–199. [Online]. Available: https://doi.org/10.1109/SBAC-PAD.2013.4
-
[11]
R. Sudarsan and C. J. Ribbens, “Reshape: A framework for dynamic resizing and scheduling of homogeneous applications in a parallel environment,” in2007 International Conference on Parallel Processing (ICPP 2007), 2007, pp. 44–44. [Online]. Available: https://doi.org/10.1109/ICPP.2007.73
-
[12]
Dynamic malleability in iterative mpi applications,
K. E. Maghraoui, T. Desell, B. K. Szyma ´nski, and C. A. Varela, “Dynamic malleability in iterative mpi applications,”Seventh IEEE International Symposium on Cluster Computing and the Grid (CCGrid ’07), pp. 591–598, 2007. [Online]. Available: https: //api.semanticscholar.org/CorpusID:2784887
2007
-
[13]
Towards realizing the potential of malleable jobs,
A. Gupta, B. Acun, O. Sarood, and L. V . Kal ´e, “Towards realizing the potential of malleable jobs,” in2014 21st International Conference on High Performance Computing (HiPC), 2014, pp. 1–10. [Online]. Available: https://doi.org/10.1109/HiPC.2014.7116905
-
[14]
G. Mart ´ın, M.-C. Marinescu, D. E. Singh, and J. Carretero, “Flex-mpi: an mpi extension for supporting dynamic load balancing on heterogeneous non-dedicated systems,” inProceedings of the 19th International Conference on Parallel Processing, ser. Euro-Par’13, 2013, p. 138–149. [Online]. Available: https://doi.org/10.1007/978-3-642-40047-6 16
-
[15]
Infrastructure and api extensions for elastic execution of mpi applications,
I. Compr ´es, A. Mo-Hellenbrand, M. Gerndt, and H.-J. Bungartz, “Infrastructure and api extensions for elastic execution of mpi applications,” inProceedings of the 23rd European MPI Users’ Group Meeting, ser. EuroMPI ’16, 2016, p. 82–97. [Online]. Available: https://doi.org/10.1145/2966884.2966917
-
[16]
Extending SLURM for dynamic resource-aware adaptive batch scheduling,
M. Chadha, J. John, and M. Gerndt, “Extending SLURM for dynamic resource-aware adaptive batch scheduling,” inIEEE 27th International Conference on High Performance Computing, Data, and Analytics (HiPC), 2020, pp. 223–232. [Online]. Available: https://doi.org/10.1109/HiPC50609.2020.00036
-
[17]
Dynamic resource management for elastic scientific workflows using PMIx,
R. Bhattarai, H. Pritchard, and S. Ghafoor, “Dynamic resource management for elastic scientific workflows using PMIx,” inIEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), 2024. [Online]. Available: https://doi.ieeecomputersociety. org/10.1109/IPDPSW63119.2024.00131
-
[18]
Dynamic resource allocation for efficient parallel CFD simulations,
G. Houzeaux, R. M. Badia, R. Borrell, D. Dosimont, J. Ejarque, M. Garcia-Gasulla, and V . L ´opez, “Dynamic resource allocation for efficient parallel CFD simulations,”Computers & Fluids, vol. 245, p. 105577, Sep. 2022. [Online]. Available: https://doi.org/10.1016/j.comp fluid.2022.105577
-
[19]
Resource optimization with MPI process malleability for dynamic workloads in HPC clusters,
S. Iserte, I. Mart ´ın-´Alvarez, K. Rojek, J. I. Aliaga, M. Castillo, W. Folwarska, and A. J. Pe ˜na, “Resource optimization with MPI process malleability for dynamic workloads in HPC clusters,”Future Generation Computer Systems, p. 107949, 2025. [Online]. Available: https://doi.org/10.1016/j.future.2025.107949
-
[20]
Dynamic spawning of mpi processes applied to malleability,
I. Mart ´ın-´Alvarez, J. I. Aliaga, M. Castillo, S. Iserte, and R. Mayo, “Dynamic spawning of mpi processes applied to malleability,” International Journal of High Performance Computing Applications, vol. 38, no. 2, p. 69–93, Mar. 2024. [Online]. Available: https: //doi.org/10.1177/10943420231176527
-
[21]
Design Principles of Dynamic Resource Management for High- Performance Parallel Programming Models,
D. Huber, M. Schreiber, M. Schulz, H. Pritchard, and D. Holmes, “Design Principles of Dynamic Resource Management for High- Performance Parallel Programming Models,” 2024. [Online]. Available: https://arxiv.org/abs/2403.17107
arXiv 2024
-
[22]
DMR API: Improving cluster productivity by turning applications into malleable,
S. Iserte, R. Mayo, E. S. Quintana-Ort ´ı, V . Beltran, and A. J. Pe ˜na, “DMR API: Improving cluster productivity by turning applications into malleable,”Parallel Computing, vol. 78, pp. 54–66, 2018. [Online]. Available: https://doi.org/10.1016/j.parco.2018.07.006
-
[23]
Talp: A lightweight tool to unveil parallel efficiency of large-scale executions,
V . Lopez, G. Ramirez Miranda, and M. Garcia-Gasulla, “Talp: A lightweight tool to unveil parallel efficiency of large-scale executions,” inProceedings of the 2021 on Performance EngineeRing, Modelling, Analysis, and VisualizatiOn STrategy, ser. PERMA VOST ’21, 2021, p. 3–10. [Online]. Available: https://doi.org/10.1145/3452412.3462753
-
[24]
MPI Malleability Validation under Replayed Real-World HPC Conditions,
S. Iserte, M. Madon, G. Da Costa, J.-M. Pierson, and A. J. Pe ˜na, “MPI Malleability Validation under Replayed Real-World HPC Conditions,” Future Generation Computer Systems, p. 108305, Dec. 2025. [Online]. Available: https://doi.org/10.1016/j.future.2025.108305
-
[25]
Using an adaptive hpc runtime system to reconfigure the cache hierarchy,
E. Totoni, J. Torrellas, and L. V . Kale, “Using an adaptive hpc runtime system to reconfigure the cache hierarchy,” inSC ’14: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2014, pp. 1047–1058. [Online]. Available: https://doi.org/10.1109/SC.2014.90
-
[26]
Predicting output performance of a petascale supercomputer,
B. Xie, Y . Huang, J. S. Chase, J. Y . Choi, S. Klasky, J. Lofstead, and S. Oral, “Predicting output performance of a petascale supercomputer,” inProceedings of the 26th International Symposium on High- Performance Parallel and Distributed Computing, 2017, p. 181–192. [Online]. Available: https://doi.org/10.1145/3078597.3078614
-
[27]
J. Ekelund, S. Markidis, and I. Peng, “Boosting performance of iterative applications on gpus: Kernel batching with cuda graphs,” in33rd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing (PDP), 2025, pp. 70–77. [Online]. Available: https://doi.org/10.1109/PDP66500.2025.00019
-
[28]
Malleable computational fluid dynamics simulations,
S. Iserte, G. Houzeaux, P. Sand ˚as, A. J. Pe ˜na, and M. Garcia-Gasulla, “Malleable computational fluid dynamics simulations,” inProceedings of the 36th Parallel CFD International Conference, Merida, Yucatan, Mexico, Nov. 2025, [In-press]
2025
-
[29]
Alya: Multiphysics Engineering Simulation Towards Exascale,
M. V ´azquez, G. Houzeaux, S. Koric, A. Artigues, J. Aguado- Sierra, R. Ar ´ıs, D. Mira, H. Calmet, F. Cucchietti, H. Owen, A. Taha, E. D. Burness, J. M. Cela, and M. Valero, “Alya: Multiphysics Engineering Simulation Towards Exascale,”Journal of Computational Sciences, vol. 14, pp. 15–27, 2016. [Online]. Available: https://doi.org/10.1016/j.jocs.2015.12.007
-
[30]
A low-dissipation finite element scheme for scale resolving simulations of turbulent flows,
O. Lehmkuhl, G. Houzeaux, H. Owen, G. Chrysokentis, and I. Rodriguez, “A low-dissipation finite element scheme for scale resolving simulations of turbulent flows,”Journal of Computational Physics, vol. 390, pp. 51–65, 2019. [Online]. Available: https: //doi.org/10.1016/j.jcp.2019.04.004
-
[31]
Parallelization of 3d mpdata algorithm using many graphics processors,
K. Rojek and R. Wyrzykowski, “Parallelization of 3d mpdata algorithm using many graphics processors,” inParallel Computing Technologies, 2015, pp. 445–457. [Online]. Available: https://doi.org/10.1007/978-3 -319-21909-7 43
-
[32]
A study of the effect of process malleability in the energy efficiency on GPU-based clusters,
S. Iserte and K. Rojek, “A study of the effect of process malleability in the energy efficiency on GPU-based clusters,”Journal of Supercomputing, vol. 76, pp. 255–274, Oct. 2020. [Online]. Available: https://doi.org/10.1007/s11227-019-03034-x
-
[33]
Dynamic resource management in HPC systems using dynamic processes with PSets,
D. Huber, S. Iserte, M. Schreiber, P.-F. Dutot, O. Richard, A. J. Pe ˜na, K. Gaddameedi, and T. Neckel, “Dynamic resource management in HPC systems using dynamic processes with PSets,” inProceedings of the 32nd IEEE International Conference on High Performance Computing, Data, and Analytics (HiPC), Hyderabad, India, Dec. 2025. [Online]. Available: https:/...
-
[35]
A Layered Approach for Dynamic Resource Management in HPC,
H.-J. Bungartz, P.-F. Dutot, J. Fecht, K. Gaddameedi, D. Huber, S. Iserte, M. Minion, T. Neckel, A. Pe ˜na, O. Richard, M. Schreiber, M. Schulz, and V . Sch ¨uller, “A Layered Approach for Dynamic Resource Management in HPC,” inEuro-Par 2024: Parallel Processing Workshops: Euro-Par 2024 International Workshops, Madrid, Spain, August 26–30, 2024, Proceedin...
-
[36]
Y . Guo, K. Raffenetti, H. Zhou, P. Balaji, M. Si, A. Amer, S. Iwasaki, S. Seo, G. Congiu, R. Latham, L. Oden, T. Gillis, R. Zambre, K. Ouyang, C. Archer, W. Bland, J. Jose, S. Sur, H. Fujita, D. Durnov, M. Chuvelev, G. Zheng, A. Brooks, S. Thapaliya, T. Doodi, M. Garazan, S. Oyanagi, M. Snir, and R. Thakur, “Preparing mpich for exascale,”The Internationa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.