Different Layers, Different Manifolds: Module-Wise Weight-Space Geometry in Transformer Optimization
Pith reviewed 2026-06-27 07:26 UTC · model grok-4.3
The pith
Attention layers favor Stiefel geometry while MLP layers favor DGram geometry for stable transformer optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
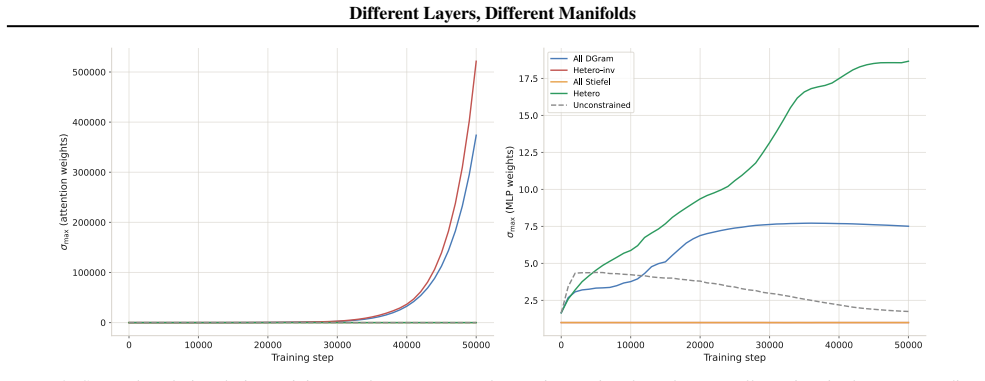
Constraining attention layers with Stiefel geometry while assigning DGram geometry to MLP layers gives the best performance among the tested configurations, whereas the inverted assignment and all-DGram configuration become unstable under the shared hyperparameter setting. This failure traces to singular value growth in DGram-constrained attention weights, which amplifies attention logits and induces softmax saturation.
What carries the argument
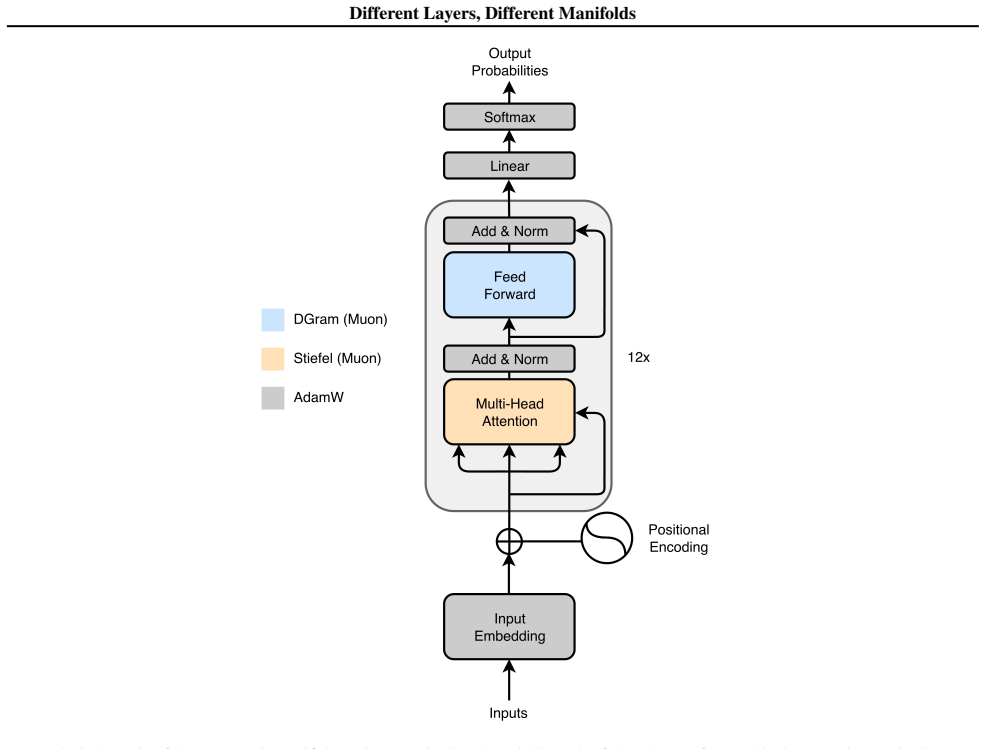
Module-wise assignment of Stiefel and DGram manifold constraints inside the Manifold Muon optimizer.
If this is right
- Uniform manifold constraints across attention and MLP blocks can produce instability.
- Stiefel geometry on attention layers prevents singular-value blowup and keeps training stable.
- DGram geometry on MLP layers supports effective optimization when attention uses Stiefel.
- Symmetry-aware optimization for transformers should be chosen per module type rather than applied uniformly.
Where Pith is reading between the lines
- Similar module-specific geometry preferences may appear in other transformer variants or larger models.
- An optimizer that learns or selects the manifold per layer could outperform fixed assignments.
- The same asymmetry might affect fine-tuning or other downstream tasks beyond pretraining.
Load-bearing premise
The shared hyperparameter setting is fair for comparison and any instability comes specifically from singular-value growth in DGram-constrained attention weights.
What would settle it
Training the all-DGram configuration with per-module hyperparameter sweeps and checking whether singular values still grow and cause softmax saturation.
Figures

read the original abstract
Weight-space geometry plays a central role in neural network optimization, yet manifold constraints are often applied uniformly across all weight matrices. In this work, we ask whether different transformer modules prefer different manifold geometries. We study Manifold Muon for GPT-2 pretraining and compare layer-wise assignments of Stiefel and DGram constraints across attention and MLP blocks. Our results show a clear asymmetry: constraining attention layers with Stiefel geometry while assigning DGram geometry to MLP layers gives the best performance among the tested configurations, whereas the inverted assignment and all-DGram configuration become unstable under the shared hyperparameter setting. We trace this failure to singular value growth in DGram-constrained attention weights, which can amplify attention logits and induce softmax saturation. These findings suggest that symmetry-aware and geometry-aware optimization for transformers should be module-specific rather than uniform.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that different transformer modules prefer different manifold geometries during optimization. Using Manifold Muon for GPT-2 pretraining, it compares layer-wise assignments of Stiefel and DGram constraints to attention and MLP blocks. The results indicate an asymmetry: Stiefel on attention layers combined with DGram on MLP layers yields the best performance, while the inverted assignment and all-DGram configurations become unstable under a shared hyperparameter setting. The instability is traced to singular-value growth in DGram-constrained attention weights, which amplifies attention logits and induces softmax saturation. The work concludes that symmetry-aware and geometry-aware optimization should be module-specific rather than uniform.
Significance. If the reported performance ordering and mechanistic attribution hold under controlled comparisons, the result would establish that uniform manifold constraints are suboptimal for transformers and that module-specific geometry choices can improve stability and final performance. The explicit link between singular-value growth and softmax saturation supplies a concrete, testable mechanism that could inform the design of future constrained optimizers.
major comments (2)
- [Abstract] Abstract and results: the central claim of a clear performance ordering and instability under the shared hyperparameter setting is stated without quantitative metrics, error bars, statistical tests, or details on how singular values were measured, so the ordering cannot be verified from the given text.
- [Results / Experimental Setup] Experimental comparison: the claim that inverted and all-DGram configurations are intrinsically unstable due to singular-value growth in attention weights rests on a single shared hyperparameter regime; no ablation is reported on learning-rate sensitivity or initialization scale for the DGram-attention case, leaving open the possibility that modest hyperparameter adjustment could stabilize those configurations without harming the best one.
Simulated Author's Rebuttal
We thank the referee for the thoughtful feedback on our work regarding module-wise manifold constraints in transformer optimization. We provide point-by-point responses to the major comments and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: the central claim of a clear performance ordering and instability under the shared hyperparameter setting is stated without quantitative metrics, error bars, statistical tests, or details on how singular values were measured, so the ordering cannot be verified from the given text.
Authors: The abstract is intentionally concise and does not include detailed metrics. The full paper presents the performance ordering with quantitative results, including error bars from multiple random seeds and statistical comparisons in the results section. Details on singular value measurement are provided in the experimental methodology. We will revise the abstract to incorporate key quantitative metrics supporting the claims and ensure the singular value analysis is clearly described. revision: yes
-
Referee: [Results / Experimental Setup] Experimental comparison: the claim that inverted and all-DGram configurations are intrinsically unstable due to singular-value growth in attention weights rests on a single shared hyperparameter regime; no ablation is reported on learning-rate sensitivity or initialization scale for the DGram-attention case, leaving open the possibility that modest hyperparameter adjustment could stabilize those configurations without harming the best one.
Authors: We would like to clarify that the manuscript states the configurations 'become unstable under the shared hyperparameter setting,' not that they are intrinsically unstable. The use of a shared hyperparameter regime is deliberate to compare the configurations on equal footing. To further address the concern about sensitivity, we will include additional experiments ablating the learning rate and initialization scale for the DGram-constrained attention layers in the revised manuscript. revision: yes
Circularity Check
No circularity; purely empirical comparison with no derivations or self-referential predictions
full rationale
The paper reports experimental results comparing Stiefel and DGram manifold constraints assigned to attention vs. MLP layers in GPT-2 pretraining. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content. Claims rest on observed performance and instability under a shared hyperparameter regime, which is an empirical observation rather than a reduction to inputs by construction. The skeptic concern about hyperparameter fairness is a methodological question, not evidence of circularity in any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , url =
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
2024
-
[2]
Thinking Machines Lab: Connectionism , year =
Jeremy Bernstein , title =. Thinking Machines Lab: Connectionism , year =
-
[3]
2025 , howpublished =
Keigwin, Ben and Pai, Dhruv and Chen, Nathan , title =. 2025 , howpublished =
2025
-
[4]
2025 , url =
Franz Louis Cesista , title =. 2025 , url =
2025
-
[5]
Muon is Scalable for LLM Training
Muon is scalable for llm training , author=. arXiv preprint arXiv:2502.16982 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
International Conference on Learning Representations , year =
Ilya Loshchilov and Frank Hutter , title =. International Conference on Learning Representations , year =
-
[7]
Advances in Neural Information Processing Systems , year=
Attention Is All You Need , author=. Advances in Neural Information Processing Systems , year=
-
[8]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Orthogonal weight normalization: Solution to optimization over multiple dependent stiefel manifolds in deep neural networks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Feedback gradient descent: Efficient and stable optimization with orthogonality for DNNs , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[11]
arXiv preprint arXiv:2601.21487 , year=
Manifold constrained steepest descent , author=. arXiv preprint arXiv:2601.21487 , year=
-
[12]
International Conference on Learning Representations , year=
The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks , author=. International Conference on Learning Representations , year=
-
[13]
International Conference on Learning Representations , year=
Git Re-Basin: Merging Models modulo Permutation Symmetries , author=. International Conference on Learning Representations , year=
-
[14]
2022 , howpublished =
Karpathy, Andrej , title =. 2022 , howpublished =
2022
-
[15]
OpenWebText Corpus , author=
-
[16]
arXiv preprint arXiv:2601.23000 , year=
Mano: Restriking Manifold Optimization for LLM Training , author=. arXiv preprint arXiv:2601.23000 , year=
-
[17]
Muon optimizes under spectral norm constraints.arXiv preprint arXiv:2506.15054, 2025
Muon optimizes under spectral norm constraints , author=. arXiv preprint arXiv:2506.15054 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.