From Traditional Automation to Embodied Wireless Intelligence: Vision-Language-Action Empowered Physics-Aware Communication Networks
Pith reviewed 2026-06-27 05:16 UTC · model grok-4.3
The pith
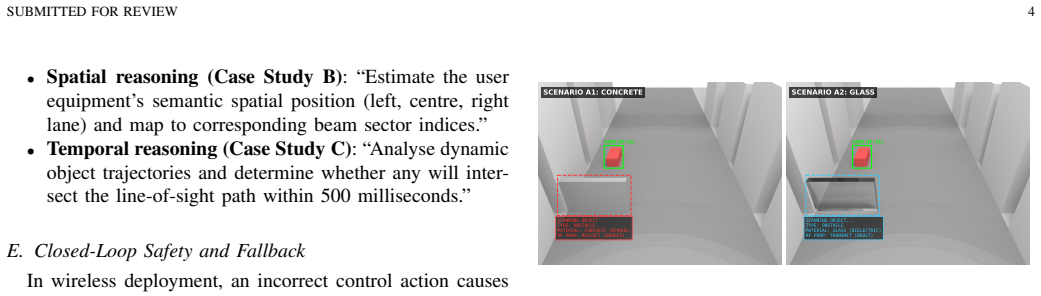
A single Vision-Language-Action pipeline lets base stations perform zero-shot material and event reasoning about radio environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
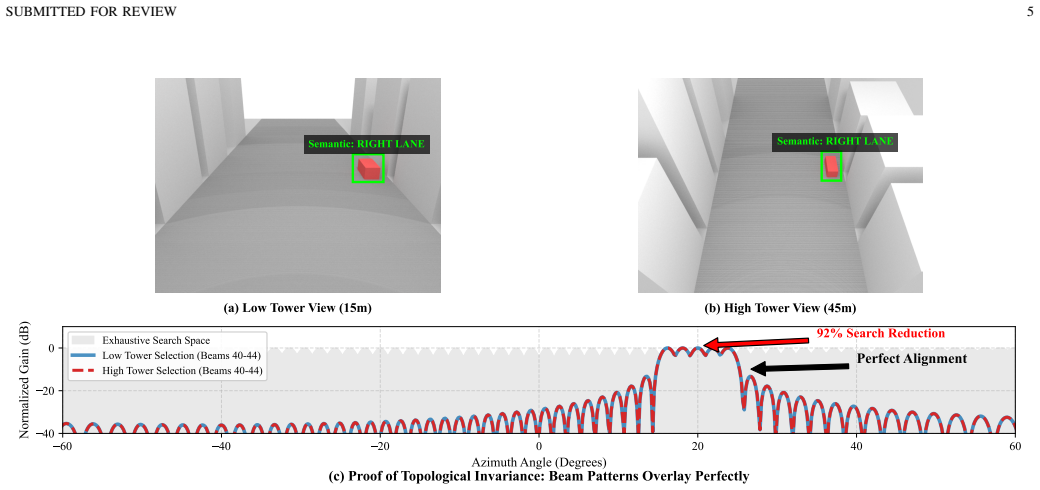
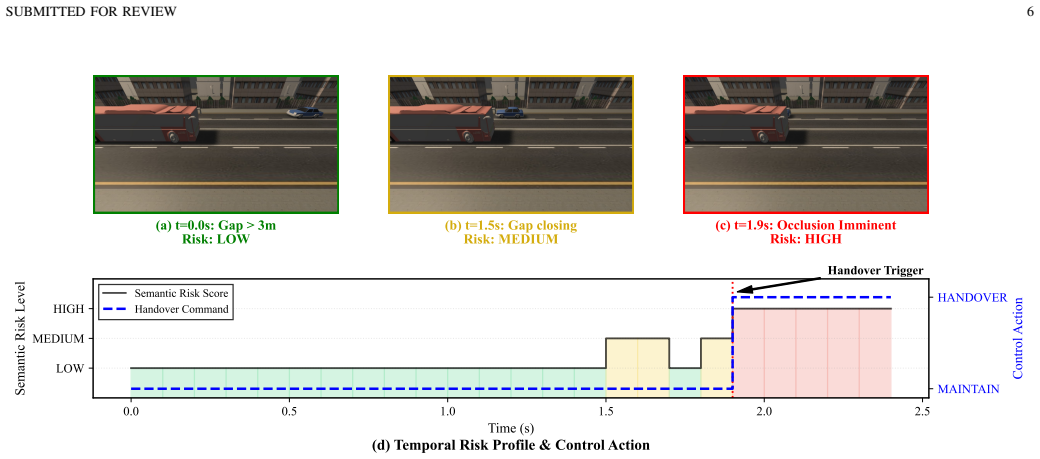
The eBS uses a VLA pipeline in which a Semantic Planner driven by a frontier VLM produces structured action directives on human timescales while a Tactical Controller performs real-time adaptation, achieving zero-shot material reasoning, cross-viewpoint generalization, and prediction of dynamic events that affect radio propagation.
What carries the argument
The embodied intelligent empowered base station (eBS) with its two-tier asynchronous VLA architecture that couples a frontier VLM-based Semantic Planner to a real-time Tactical Controller.
If this is right
- A single model handles material identification, viewpoint shifts, and dynamic prediction without any task-specific retraining.
- Network actions can be generated from visual perception of the physical environment rather than from performance metrics alone.
- Proactive adaptation becomes possible by anticipating signal degradation before it occurs.
- The same pipeline can be applied across different base-station deployments without per-site customization.
Where Pith is reading between the lines
- If the VLM can reason about radio physics from images, the same pipeline might later incorporate additional sensors such as depth cameras to build richer 3D propagation models.
- Multiple base stations could share VLA-derived scene descriptions to coordinate coverage in overlapping areas.
- Real RF measurement feedback could be added as a verification loop to correct or refine the VLM's initial predictions during live operation.
Load-bearing premise
Frontier vision-language models already contain enough built-in causal knowledge of radio-wave physics and material interactions to generate reliable network actions from images alone.
What would settle it
Run the VLA pipeline on live base-station camera feeds, apply its generated actions, and check whether signal quality or outage rates measurably improve over conventional automation under the same physical conditions.
Figures

read the original abstract
Wireless network automation has progressed from rule-based self-organising networks (SON) to data-driven optimisation, yet existing systems remain fundamentally disembodied, optimising performance indicators without perceiving the physical environment that governs radio propagation. We propose the embodied intelligent empowered base station (eBS), a paradigm that adopts a Vision-Language-Action (VLA) pipeline to transform base stations into autonomous agents capable of situated perception, causal physical reasoning, and physics-aware action generation. The eBS employs a two-tier asynchronous architecture: a Semantic Planner powered by a frontier Vision-Language Model (VLM) generates structured action directives on human timescales, whilst a Tactical Controller executes real-time adaptation. Case studies demonstrate that a single VLA pipeline, without task-specific training, can perform zero-shot material reasoning, generalise across viewpoints, and predict dynamic events before signal degradation occurs, illustrating a paradigm shift from traditional rule-following network automation to embodied intelligence empowered future wireless networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the embodied intelligent empowered base station (eBS) paradigm, which integrates a Vision-Language-Action (VLA) pipeline into wireless base stations. This enables situated perception of the physical environment, causal reasoning about radio propagation and materials, and generation of physics-aware actions. It introduces a two-tier asynchronous architecture with a Semantic Planner (frontier VLM on human timescales) and Tactical Controller (real-time adaptation), claiming via case studies that a single untrained VLA pipeline achieves zero-shot material reasoning, viewpoint generalization, and preemptive prediction of dynamic events.
Significance. If the core claims were empirically validated, the work would articulate a potentially important shift from rule-based SON or KPI-driven optimization toward embodied agents that directly model the physical determinants of wireless channels. The two-tier separation of semantic planning from tactical control is a reasonable architectural choice, but the manuscript supplies no quantitative results, baselines, or error metrics to support the VLM's purported causal physics reasoning.
major comments (2)
- [Abstract] Abstract: The central claim that 'a single VLA pipeline, without task-specific training, can perform zero-shot material reasoning, generalise across viewpoints, and predict dynamic events before signal degradation occurs' is presented as demonstrated by case studies, yet the manuscript provides no quantitative results, comparison against ray-tracing simulators, channel sounders, or even qualitative error analysis. This absence directly undermines evaluation of the paradigm-shift assertion.
- [Abstract] Abstract (and implied case-study sections): The assumption that frontier VLMs possess reliable causal models of electromagnetic propagation (Fresnel zones, dielectric attenuation, multipath, Doppler) sufficient to generate action directives without domain-specific fine-tuning or RF sensor integration is load-bearing for the entire proposal but receives no supporting evidence or ablation in the text.
minor comments (2)
- [Abstract] The acronym 'eBS' is introduced without an explicit expansion on first use in the abstract; subsequent sections should define all novel terms at first appearance.
- The manuscript would benefit from a dedicated section contrasting the proposed two-tier architecture against existing semantic communication or multimodal network papers to clarify incremental novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical grounding of our claims. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'a single VLA pipeline, without task-specific training, can perform zero-shot material reasoning, generalise across viewpoints, and predict dynamic events before signal degradation occurs' is presented as demonstrated by case studies, yet the manuscript provides no quantitative results, comparison against ray-tracing simulators, channel sounders, or even qualitative error analysis. This absence directly undermines evaluation of the paradigm-shift assertion.
Authors: We agree that the manuscript relies on qualitative case studies without quantitative metrics, baselines, or error analysis, which limits the strength of the asserted capabilities. The case studies were intended as illustrative demonstrations rather than rigorous validation. In revision we will modify the abstract and relevant sections to state that the case studies 'illustrate potential' for these behaviors rather than claiming they 'demonstrate' them. We will also add an explicit Limitations and Future Work subsection that outlines planned quantitative evaluation against ray-tracing tools and channel measurements. revision: yes
-
Referee: [Abstract] Abstract (and implied case-study sections): The assumption that frontier VLMs possess reliable causal models of electromagnetic propagation (Fresnel zones, dielectric attenuation, multipath, Doppler) sufficient to generate action directives without domain-specific fine-tuning or RF sensor integration is load-bearing for the entire proposal but receives no supporting evidence or ablation in the text.
Authors: The proposal does extrapolate VLM reasoning observed in other domains to electromagnetic propagation without direct evidence or ablation studies specific to Fresnel zones, dielectric properties, or Doppler effects. We accept that this assumption is central and currently unsupported by targeted experiments in the manuscript. We will revise the abstract and introduction to present the causal-physics capability as a hypothesis rather than an established fact, and we will expand the discussion to address the current lack of RF-specific validation and the potential necessity of sensor integration or fine-tuning. revision: yes
Circularity Check
No circularity: conceptual proposal without derivations or fitted parameters
full rationale
The paper is a vision/proposal document introducing the eBS paradigm and VLA pipeline for wireless networks. It contains no equations, no parameter fitting, no self-citations used to justify uniqueness theorems, and no derivations that reduce to inputs by construction. Case studies are described at a high level as demonstrations of zero-shot capabilities but do not involve quantitative modeling or self-referential definitions. The central claims rest on external assumptions about VLM capabilities rather than internal circular logic. This is the normal case of a self-contained conceptual paper with score 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frontier VLMs can perform zero-shot causal physical reasoning about radio propagation and material interactions
invented entities (1)
-
embodied intelligent empowered base station (eBS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[2]
Code as policies: Language model programs for embodied control,
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” in2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 9493–9500
2023
-
[3]
A survey of machine learning techniques applied to self-organizing cellular net- works,
P. V . Klaine, M. A. Imran, O. Onireti, and R. D. Souza, “A survey of machine learning techniques applied to self-organizing cellular net- works,”IEEE Communications Surveys & Tutorials, vol. 19, no. 4, pp. 2392–2431, 2017
2017
-
[4]
Ai embodiment through 6G: Shaping the future of agi,
L. Bariah and M. Debbah, “Ai embodiment through 6G: Shaping the future of agi,”IEEE Wireless Communications, vol. 31, no. 5, pp. 174– 181, 2024
2024
-
[5]
J. Wang, B. Tang, J. Xiao, Q. Cui, X. Li, and T. Q. Quek, “When vision- language model (VLM) meets beam prediction: A multimodal con- trastive learning framework,”arXiv preprint arXiv:2508.00456, 2025
-
[6]
Multi-modal large models based beam pre- diction: An example empowered by DeepSeek,
Y . Zhao, L. Yu, L. Shi, J. Zhang, and G. Liu, “Multi-modal large models based beam prediction: An example empowered by DeepSeek,”arXiv preprint arXiv:2506.05921, 2025
-
[7]
J. Tong, W. Guo, J. Shao, Q. Wu, Z. Li, Z. Lin, and J. Zhang, “Wirelessagent: Large language model agents for intelligent wireless networks,”arXiv preprint arXiv:2505.01074, 2025
-
[8]
Large multi-modal models (LMMs) as universal foundation models for ai-native wireless systems,
S. Xu, C. K. Thomas, O. Hashash, N. Muralidhar, W. Saad, and N. Ramakrishnan, “Large multi-modal models (LMMs) as universal foundation models for ai-native wireless systems,”IEEE Network, 2024
2024
-
[9]
Z. Li, Z. Gao, X. Liu, Z. Wang, X. Zhou, L. Liu, Y . Wu, W. Feng, and Y . Huang, “Large model enabled embodied intelligence for 6G integrated perception, communication, and computation network,”arXiv preprint arXiv:2512.15109, 2025
-
[10]
Camera based mmWave beam prediction: Towards multi-candidate real-world scenarios,
G. Charan, M. Alrabeiah, T. Osman, and A. Alkhateeb, “Camera based mmWave beam prediction: Towards multi-candidate real-world scenarios,”IEEE Transactions on Vehicular Technology, 2024
2024
-
[11]
Sionna RT: Differentiable ray tracing for radio propagation modeling,
J. Hoydis, F. Aït Aoudia, S. Cammerer, M. Nimier-David, N. Binder, G. Marcus, and A. Keller, “Sionna RT: Differentiable ray tracing for radio propagation modeling,” inProc. IEEE Global Commun. Conf. (GLOBECOM) Workshops, 2023, pp. 317–321
2023
-
[12]
ViWi: A deep learning dataset framework for vision-aided wireless communications,
M. Alrabeiah, A. Hredzak, Z. Liu, and A. Alkhateeb, “ViWi: A deep learning dataset framework for vision-aided wireless communications,” in2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring). IEEE, 2020, pp. 1–5
2020
-
[13]
Vision-aided 6G wireless communications: Blockage prediction and proactive handoff,
G. Charan, M. Alrabeiah, and A. Alkhateeb, “Vision-aided 6G wireless communications: Blockage prediction and proactive handoff,”IEEE Transactions on Vehicular Technology, vol. 70, no. 10, pp. 10 193– 10 208, 2021
2021
-
[14]
DeepSense 6G: A large-scale real-world multi-modal sensing and communication dataset,
A. Alkhateeb, G. Charan, T. Osman, A. Hredzak, J. Morais, U. Demirhan, and N. Srinivas, “DeepSense 6G: A large-scale real-world multi-modal sensing and communication dataset,”IEEE Communica- tions Magazine, vol. 61, no. 9, pp. 122–128, 2023
2023
-
[15]
BeamLLM: Vision- empowered mmWave beam prediction with large language models,
C. Zheng, J. He, G. Cai, Z. Yu, and C. G. Kang, “BeamLLM: Vision- empowered mmWave beam prediction with large language models,” in 2025 IEEE 102nd Vehicular Technology Conference (VTC2025-Fall). IEEE, 2025, pp. 1–6. Genze Jiangis working toward the Ph.D. degree with the Department of Computer Science, Brunel University London, UK. Kezhi Wang(Senior Member...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.