Recursive Agent Harnesses
Pith reviewed 2026-06-27 06:39 UTC · model grok-4.3
The pith
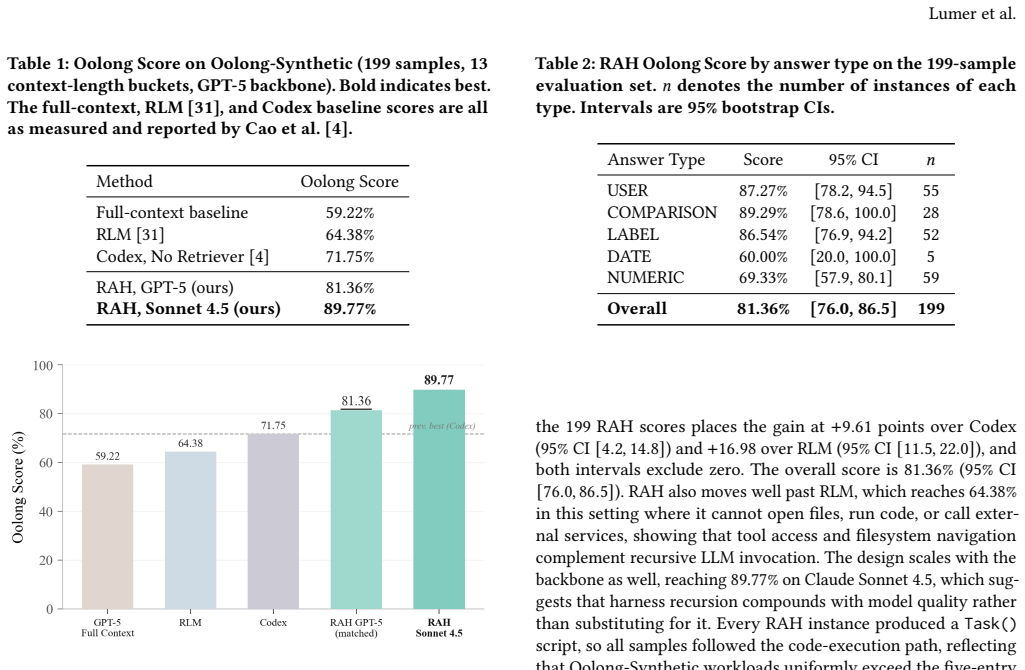
Recursive agent harnesses raise a fixed GPT-5 coding baseline from 71.75 percent to 81.36 percent on long-context tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
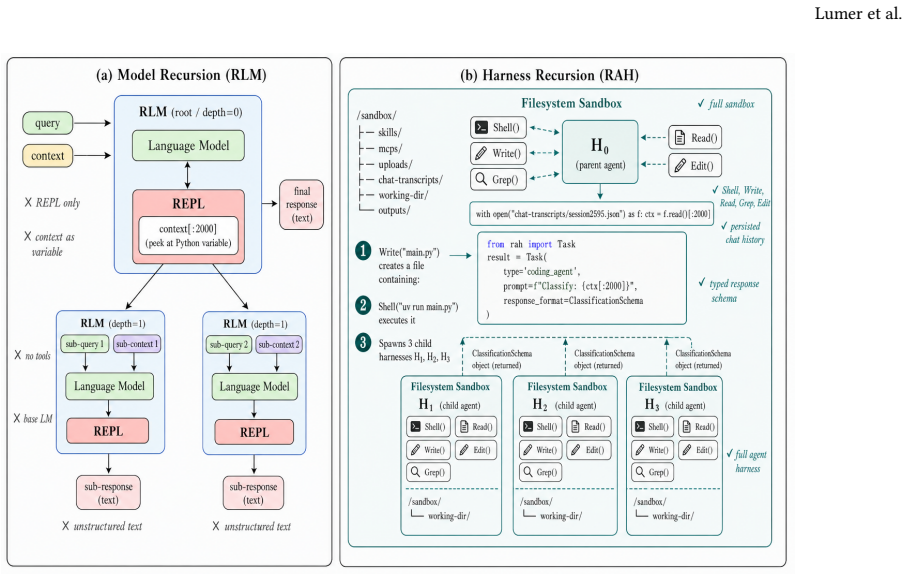
We name and study the pattern between recursive language models and production coding agents that spawn subagents, where the recursive unit is a full agent harness with tools. We call this the Recursive Agent Harness and frame it as harness recursion. A parent agent generates and runs an executable script that spawns subagent harnesses in parallel for fine-grained workloads and uses structured function calls for small subtasks. With the backbone held fixed at GPT-5 to match published baselines, RAH improves the Codex coding-agent baseline from 71.75 percent to 81.36 percent on Oolong-Synthetic, a gain attributable to the harness rather than the model.
What carries the argument
Recursive Agent Harness (RAH), the executable recursive unit consisting of a full agent with filesystem tools, code execution, and planning that a parent agent spawns via generated scripts.
If this is right
- The harness structure itself, not model scale, accounts for the measured improvement on long-context coding tasks.
- Parallel spawning of sub-harnesses enables fine-grained division of long-context workloads.
- Structured function calls inside the harness handle small subtasks without full agent overhead.
- The same harness design scales to stronger backbones, reaching 89.77 percent with Claude Sonnet 4.5.
Where Pith is reading between the lines
- The approach could be tested on non-coding long-context benchmarks to check whether harness recursion generalizes beyond code generation.
- Different recursion depths or hybrid model-plus-harness recursion patterns remain open for direct comparison under the same fixed-backbone protocol.
Load-bearing premise
The controlled evaluation with fixed backbone and chosen baseline fully isolates the contribution of the recursive harness structure from differences in prompting, tool access, or other implementation details.
What would settle it
A controlled re-run of the Codex baseline that exactly matches the RAH prompting, tool set, and script-generation format, after which the performance gap disappears.
Figures
read the original abstract
Recursive language models (RLMs) showed that recursion over model calls is an effective strategy for long-context reasoning, and production coding agents have begun to write code that spawns subagents at scale, most recently in Anthropic's dynamic workflows. We name and study the pattern between these two lines of work, where the recursive unit is a full agent harness with filesystem tools, code execution, and planning rather than a model call with no tools. We call this the Recursive Agent Harness (RAH) and frame it as harness recursion, the code-first extension to the model recursion of RLMs. A parent agent generates and runs an executable script that spawns subagent harnesses in parallel for fine-grained workloads and uses structured function calls for small subtasks. We provide a controlled evaluation on long-context reasoning. With the backbone held fixed at GPT-5 to match the published Codex and RLM baselines, RAH improves the Codex coding-agent baseline from 71.75% to 81.36% on Oolong-Synthetic (199 samples, 13 context-length buckets up to 4M tokens), a gain attributable to the harness rather than the model. With a stronger backbone, Claude Sonnet 4.5, the same design reaches 89.77%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Recursive Agent Harnesses (RAH) as a code-first extension of recursive language models, in which a parent agent generates executable scripts that spawn parallel subagent harnesses equipped with filesystem tools, code execution, and structured function calls. With the model backbone fixed at GPT-5, the paper reports that RAH raises performance on the Oolong-Synthetic benchmark (199 samples, 13 context-length buckets up to 4 M tokens) from the Codex coding-agent baseline of 71.75 % to 81.36 %, attributing the 9.61 pp gain to the harness recursion rather than the underlying model; a stronger backbone (Claude Sonnet 4.5) reaches 89.77 %.
Significance. If the controlled evaluation is reproducible, the work usefully bridges recursive language models and production-scale coding agents by demonstrating that recursion at the level of full agent harnesses can improve long-context reasoning performance. The explicit use of a fixed backbone to match published baselines is a methodological strength that supports attribution claims.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation section: the claim that the 9.61 pp gain on Oolong-Synthetic is 'attributable to the harness rather than the model' is load-bearing for the central contribution, yet the manuscript supplies no details on variance across runs, exact reproduction of the Codex baseline code, data-exclusion rules, or statistical tests. Without these, the isolation of the recursive-harness effect cannot be verified.
- [Evaluation methodology] Evaluation methodology: the controlled comparison with fixed GPT-5 backbone assumes that all non-recursive implementation details (system prompts, tool schemas, filesystem access, parallel-execution handling, and context management) are identical between RAH and the Codex baseline. The text does not state that such equivalence was explicitly verified or that the baseline was re-run inside the authors' harness framework.
minor comments (2)
- [Abstract] The abstract mentions '13 context-length buckets' but does not indicate how bucket boundaries or sample distribution are defined; a brief table or sentence would improve clarity.
- [Introduction] The paper cites prior RLM and Anthropic workflow work but could add a short related-work paragraph distinguishing harness recursion from model-level recursion more explicitly.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater methodological transparency in our controlled evaluation. We address each major comment below and commit to revisions that strengthen the verifiability of the attribution claim without altering the core experimental design.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation section: the claim that the 9.61 pp gain on Oolong-Synthetic is 'attributable to the harness rather than the model' is load-bearing for the central contribution, yet the manuscript supplies no details on variance across runs, exact reproduction of the Codex baseline code, data-exclusion rules, or statistical tests. Without these, the isolation of the recursive-harness effect cannot be verified.
Authors: We agree that the manuscript would benefit from explicit documentation of these elements to support reproducibility. The reported 71.75% Codex baseline is taken directly from the published results to enforce the fixed GPT-5 backbone control, consistent with standard practice when matching prior work. In revision we will: (1) add a dedicated reproducibility subsection describing the baseline matching protocol, (2) specify any data-exclusion rules applied to the 199-sample Oolong-Synthetic set, (3) report that results reflect single runs aligned with the original baseline publications, and (4) include variance or statistical test results if additional runs were conducted during development (or explicitly note their absence as a limitation). revision: yes
-
Referee: [Evaluation methodology] Evaluation methodology: the controlled comparison with fixed GPT-5 backbone assumes that all non-recursive implementation details (system prompts, tool schemas, filesystem access, parallel-execution handling, and context management) are identical between RAH and the Codex baseline. The text does not state that such equivalence was explicitly verified or that the baseline was re-run inside the authors' harness framework.
Authors: The evaluation deliberately uses the published Codex numbers rather than re-implementing the baseline inside the RAH framework, because the central control variable is the model backbone itself. This isolates the contribution of harness recursion (executable script spawning of subagents) while holding the underlying model fixed. We will revise the evaluation methodology section to state this design choice explicitly, describe how non-recursive components were aligned with published descriptions to the extent possible, and clarify that full re-implementation of the baseline within our harness was not performed as it would confound the fixed-backbone comparison. revision: yes
Circularity Check
No circularity: empirical result with fixed backbone
full rationale
The paper's central claim is a measured empirical improvement (71.75% to 81.36%) on Oolong-Synthetic with GPT-5 backbone held fixed to match baselines. No derivation, equations, fitted parameters, or self-citations are invoked to produce this number; the gain is presented as the direct output of the controlled experiment. No load-bearing step reduces by construction to the inputs, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Long-context reasoning tasks benefit from parallel decomposition into subagent harnesses spawned via executable code.
invented entities (1)
-
Recursive Agent Harness (RAH)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anonymous. 2026. AGENTHIVE: A Composable Multi-Agent Framework with First-Class Delegation. ACL ARR 2026 January submission. openre- view.net/forum?id=BYiwNYYixO. Authors are anonymous (double-blind). Re- place with deanonymized authors upon publication
2026
-
[2]
Anthropic. 2026. Orchestrate Subagents at Scale with Dynamic Workflows. https: //code.claude.com/docs/en/workflows. Claude Code documentation, research preview. Accessed 2026-06-06
2026
-
[3]
Amanda Bertsch, Adithya Pratapa, Teruko Mitamura, Graham Neubig, and Matthew R. Gormley. 2025. Oolong: Evaluating Long Context Reasoning and Ag- gregation Capabilities.arXiv preprint arXiv:2511.02817(2025). arXiv:2511.02817
arXiv 2025
-
[4]
Weili Cao, Xunjian Yin, Bhuwan Dhingra, and Shuyan Zhou. 2026. Coding Agents are Effective Long-Context Processors.arXiv preprint arXiv:2603.20432 (2026). arXiv:2603.20432
arXiv 2026
-
[5]
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chen Qian, Chi-Min Chan, Yujia Qin, Yaxi Lu, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. 2024. AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors. InInternational Conference on Learning Representations. arXiv:2308.10848
Pith/arXiv arXiv 2024
-
[6]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?. InInternational Conference on Learning Representa- tions. arXiv:2310.06770
Pith/arXiv arXiv 2024
-
[7]
Mahoney, Kurt Keutzer, and Amir Gholami
Sehoon Kim, Suhong Moon, Ryan Tabrizi, Nicholas Lee, Michael W. Mahoney, Kurt Keutzer, and Amir Gholami. 2024. An LLM Compiler for Parallel Function Calling. InInternational Conference on Machine Learning. arXiv:2312.04511
arXiv 2024
-
[8]
LangChain. 2022. LangChain. https://www.langchain.com/
2022
-
[9]
Daniel Freeman, Sara de Jong, Arthur Gretton, and Mandar Joshi
Jinhyuk Lee, Anthony Ing, Zhuyun Dai, Sharan Narang, Kelvin Guu, Benjamin Pitchford, Maxwell Chang, Steven Wan, Ryutaro Tanno, C. Daniel Freeman, Sara de Jong, Arthur Gretton, and Mandar Joshi. 2024. Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?. InProceedings of the 62nd Annual Meeting of the Association for Computational Lingui...
arXiv 2024
-
[10]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173. arXiv:2307.03172
Pith/arXiv arXiv 2024
-
[11]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianhao Fu, Yuxiao Liu, Zihan Yao, Rui Zhang, Jie Jia, Jie Tang, Yuxiao Liu, and Yuxiao Dong. 2024. AgentBench: Evaluating LLMs as Agents. InInternational Conferenc...
Pith/arXiv arXiv 2024
-
[12]
Elias Lumer, Anmol Gulati, Faheem Nizar, Dzmitry Hedroits, Atharva Mehta, Henry Hwangbo, Vamse Kumar Subbiah, Pradeep Honaganahalli Basavaraju, and James A Burke. 2026. Tool and agent selection for large language model agents in production: A survey. In2026 IEEE Conference on Artificial Intelligence (CAI). IEEE, 701–708
2026
-
[13]
Elias Lumer, Faheem Nizar, Akshaya Jangiti, Kevin Frank, Anmol Gulati, Man- dar Phadate, and Vamse Kumar Subbiah. 2026. Don’t Break the Cache: An Evaluation of Prompt Caching for Long-Horizon Agentic Tasks.arXiv preprint arXiv:2601.06007(2026)
arXiv 2026
-
[14]
Grégoire Mialon, Roberto Dessì, Maria Lomeli, Christoforos Nalmpantis, Ram Pasunuru, Roberta Raileanu, Baptiste Rozière, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Grave, Yann LeCun, and Thomas Scialom. 2023. Augmented Language Models: a Survey.Transactions on Machine Learning Research(2023). arXiv:2302.07842
Pith/arXiv arXiv 2023
-
[15]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. 2021. WebGPT: Browser-Assisted Question-Answering with Human Feedback.arXiv preprint...
Pith/arXiv arXiv 2021
-
[16]
Avanika Narayan, Dan Biderman, Sabri Eyuboglu, Avner May, Scott Linderman, James Zou, and Christopher Re. 2025. Minions: Cost-efficient Collaboration Between On-device and Cloud Language Models. arXiv:2502.15964 [cs.LG] https://arxiv.org/abs/2502.15964
arXiv 2025
-
[17]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems.arXiv preprint arXiv:2310.08560(2023)
Pith/arXiv arXiv 2023
-
[18]
Yujia Qin, Shihao Liang, Yining Ye, Kunliang Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun
-
[19]
InInternational Conference on Learning Representations
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-World APIs. InInternational Conference on Learning Representations. arXiv:2307.16789
-
[20]
Amartya Roy, Rasul Tutunov, Xiaotong Ji, Matthieu Zimmer, and Haitham Bou- Ammar. 2026. The Y-Combinator for LLMs: Solving Long-Context Rot with 𝜆-Calculus.arXiv preprint arXiv:2603.20105(2026). Submitted 20 Mar 2026
arXiv 2026
-
[21]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. InAdvances in Neural Information Processing Systems. arXiv:2302.04761
Pith/arXiv arXiv 2023
-
[22]
Sahil Sen, Akhil Kasturi, Elias Lumer, Anmol Gulati, and Vamse Kumar Subbiah
-
[23]
arXiv preprint arXiv:2605.15184(2026)
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search. arXiv preprint arXiv:2605.15184(2026). https://arxiv.org/abs/2605.15184
Pith/arXiv arXiv 2026
-
[24]
Sahil Sen, Elias Lumer, Anmol Gulati, and Vamse Kumar Subbiah. 2026. Chronos: Temporal-aware conversational agents with structured event retrieval for long- term memory.arXiv preprint arXiv:2603.16862(2026)
arXiv 2026
-
[25]
Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L
Theodore R. Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L. Griffiths
-
[26]
Cognitive Architectures for Language Agents.Transactions on Machine Learning Research(2024). arXiv:2309.02427
Pith/arXiv arXiv 2024
-
[27]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An Open-Ended Embodied Agent with Large Language Models.arXiv preprint arXiv:2305.16291(2023)
Pith/arXiv arXiv 2023
-
[28]
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. 2024. Executable Code Actions Elicit Better LLM Agents. arXiv:2402.01030 [cs.CL] https://arxiv.org/abs/2402.01030
arXiv 2024
-
[29]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems. arXiv:2201.11903
Pith/arXiv arXiv 2022
-
[30]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. 2023. AutoGen: Enabling Next- Gen LLM Applications via Multi-Agent Conversation. arXiv:2308.08155 [cs.AI] https://arxiv.org/abs/2308.08155
Pith/arXiv arXiv 2023
-
[31]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Inter- faces Enable Automated Software Engineering. InAdvances in Neural Information Processing Systems. arXiv:2405.15793
Pith/arXiv arXiv 2024
-
[32]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. InAdvances in Neural Information Processing Systems. arXiv:2305.10601
Pith/arXiv arXiv 2023
-
[33]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Mod- els. InInternational Conference on Learning Representations. arXiv:2210.03629
Pith/arXiv arXiv 2023
-
[34]
Alex L. Zhang, Tim Kraska, and Omar Khattab. 2026. Recursive Language Models. arXiv:2512.24601 [cs.AI] https://arxiv.org/abs/2512.24601 6 Lumer et al. A Parent Agent Prompt The parent agent runs a general-purpose harness prompt. It con- tains no task- or benchmark-specific instructions, and it does not tell the agent what to extract, how to score, or how ...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.