World Tracing: Generative Pixel-Aligned Geometry Beyond the Visible
Pith reviewed 2026-06-27 06:54 UTC · model grok-4.3
The pith
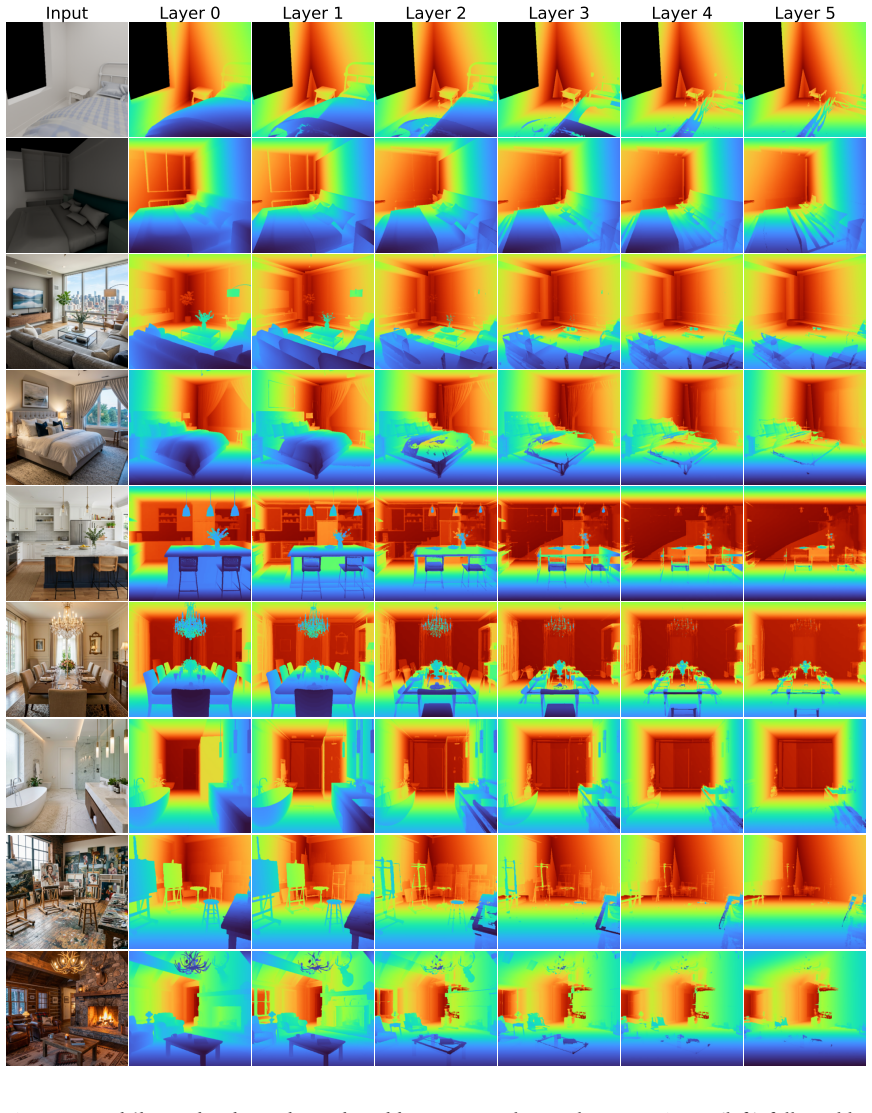
World Tracing predicts ordered stacks of camera-space 3D points per pixel to reconstruct visible surfaces and generate occluded geometry while remaining pixel-aligned.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
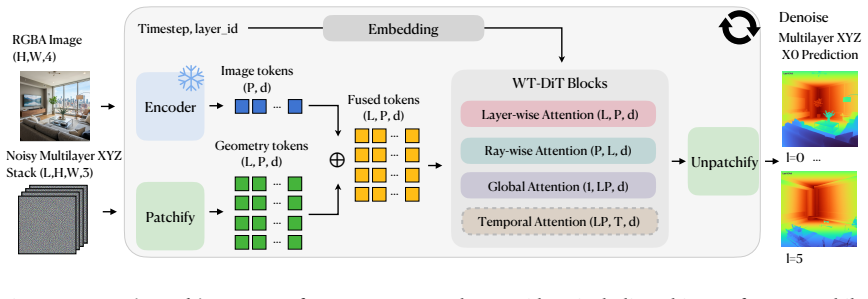
World Tracing is a generative pixel-aligned geometry representation that predicts an ordered stack of camera-space 3D points for each input pixel, where the first layer represents the visible surface and subsequent layers represent front-to-back intersections with occluded surfaces. The representation is instantiated as a world-tracing diffusion transformer (WT-DiT) that treats multiple geometry layers as separate denoising tokens coupled through factorized and global attention, trained with pixel-space flow matching and a mixed noise schedule.
What carries the argument
The ordered stack of camera-space 3D points per pixel, with the diffusion transformer treating geometry layers as separate denoising tokens coupled by factorized and global attention.
If this is right
- Outperforms both depth predictors and image-to-3D generators on visible-surface reconstruction and complete geometry generation across object, scene, and dynamic benchmarks.
- Preserves 2D-to-3D correspondence, supporting text-driven 3D scene editing.
- Enables geometry-conditioned novel-view video synthesis.
- Allows training-free integration with textured-mesh generators.
Where Pith is reading between the lines
- The per-pixel stack format could be extended to video sequences by adding a temporal dimension to the attention mechanism, allowing consistent completion across frames.
- Because each point remains tied to an input pixel, the representation may reduce drift in single-view SLAM systems when occluded surfaces are needed for loop closure.
- The separation of visible and occluded layers suggests a natural way to condition downstream tasks such as semantic segmentation on only the visible layer while still having access to full scene geometry.
Load-bearing premise
A single diffusion transformer with factorized and global attention, trained under a mixed noise schedule, can simultaneously achieve accurate visible-surface reconstruction and plausible occluded-geometry generation without layer collapse or misalignment artifacts.
What would settle it
On a held-out multi-view benchmark, the first-layer points deviate from ground-truth visible depth by more than a few pixels on average, or the later layers fail to produce intersections consistent with hidden surfaces observed from other viewpoints.
Figures



read the original abstract
Image-to-3D methods often trade off faithfulness and completeness: depth estimators are anchored to input pixels but stop at the visible surface, while image-to-3D models generate complete shapes that are often misaligned with the input. We introduce World Tracing, a generative pixel-aligned geometry representation that predicts 3D points aligned with observed pixels while completing geometry beyond the visible surface. For each input pixel, World Tracing predicts an ordered stack of camera-space 3D points, where the first layer represents the visible surface and subsequent layers represent front-to-back intersections with occluded surfaces. We instantiate this representation with a world-tracing diffusion transformer, WT-DiT, which treats multiple geometry layers as separate denoising tokens coupled through factorized and global attention. WT-DiT is trained with pixel-space flow matching and a mixed noise schedule that balances visible-surface reconstruction with occluded-geometry generation. World Tracing achieves strong performance on visible-surface reconstruction and complete geometry generation across object, scene, and dynamic benchmarks, outperforming both depth predictors and image-to-3D generators. It also preserves 2D-to-3D correspondence, enabling text-driven 3D scene editing, geometry-conditioned novel-view video synthesis, and training-free integration with textured-mesh generators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces World Tracing, a generative pixel-aligned geometry representation that, for each input pixel, predicts an ordered stack of camera-space 3D points where layer 1 is the visible surface and later layers are front-to-back occluded intersections. The representation is realized via a world-tracing diffusion transformer (WT-DiT) that treats geometry layers as separate denoising tokens coupled by factorized and global attention; the model is trained with pixel-space flow matching under a mixed noise schedule intended to balance visible-surface reconstruction and occluded-geometry generation. The manuscript claims that this approach achieves strong performance on visible-surface reconstruction and complete geometry generation across object, scene, and dynamic benchmarks, outperforming both depth predictors and image-to-3D generators while preserving 2D-to-3D correspondence for downstream tasks such as text-driven editing and geometry-conditioned novel-view synthesis.
Significance. If the empirical results and ordering guarantees hold, the work provides a concrete mechanism for reconciling pixel faithfulness with geometric completeness, which has been a persistent tension in image-to-3D literature. The ordered multi-layer tokenization and mixed-schedule training constitute a technically interesting architectural choice that could be reusable beyond the specific benchmarks. The preservation of explicit 2D-to-3D correspondence is a practical strength that directly enables the listed editing and synthesis applications.
major comments (2)
- [Abstract] Abstract: the central claim of outperforming baselines on multiple benchmarks is stated without any quantitative metrics, tables, error bars, ablation results, or dataset specifications. Because the soundness of the performance claim is load-bearing for the paper's contribution, the absence of these numbers prevents evaluation of whether the ordered-stack representation actually delivers the advertised gains over depth estimators and image-to-3D generators.
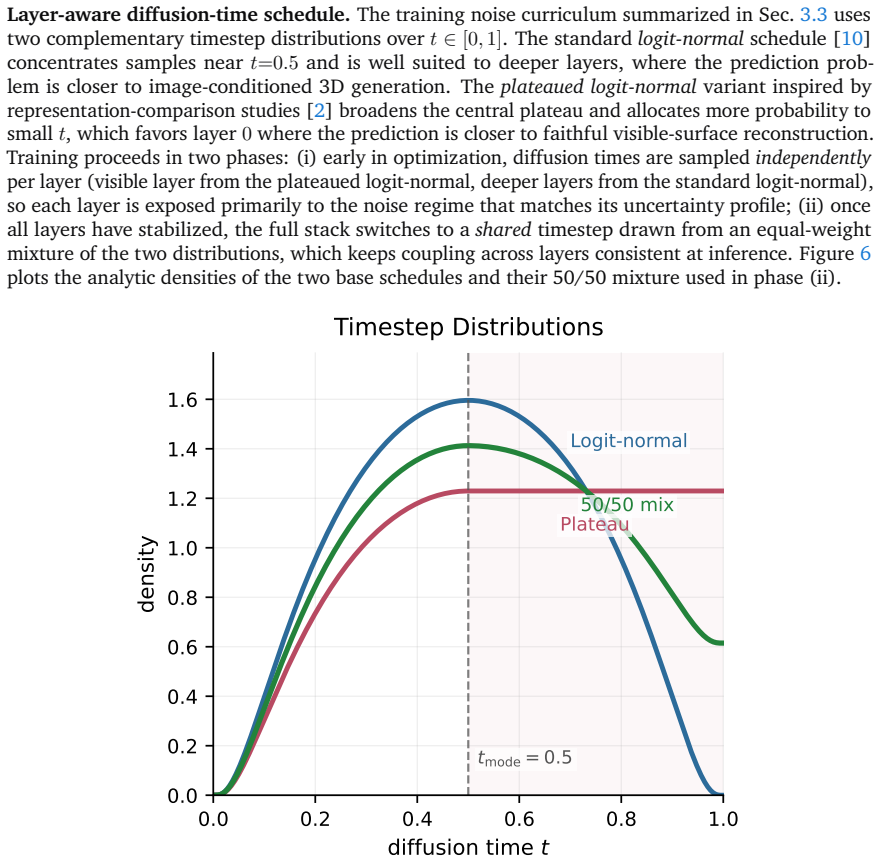
- [Method] Method (WT-DiT training description): the mixed noise schedule is presented as the sole mechanism that balances visible-surface accuracy with occluded-layer generation and enforces ordering. No additional loss term, ordering regularizer, or explicit supervision for layer correspondence is mentioned; if the schedule does not sufficiently differentiate noise levels across layers or if factorized attention fails to propagate pixel alignment, later layers can collapse or misalign, directly violating the ordered-stack representation that underpins all downstream claims.
minor comments (2)
- The phrase 'pixel-space flow matching' is used without a reference or brief definition; a short citation to the relevant flow-matching formulation would improve readability.
- [Abstract] The abstract lists three application scenarios (text-driven editing, novel-view video synthesis, training-free mesh integration) but does not indicate whether these are demonstrated with qualitative figures or quantitative metrics in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional clarity and quantitative support would strengthen the manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of outperforming baselines on multiple benchmarks is stated without any quantitative metrics, tables, error bars, ablation results, or dataset specifications. Because the soundness of the performance claim is load-bearing for the paper's contribution, the absence of these numbers prevents evaluation of whether the ordered-stack representation actually delivers the advertised gains over depth estimators and image-to-3D generators.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The main body contains the supporting tables, error bars, ablations, and dataset specifications. We will revise the abstract to incorporate representative metrics (with references to the relevant tables) so that the performance claims are more directly evaluable from the abstract alone. revision: yes
-
Referee: [Method] Method (WT-DiT training description): the mixed noise schedule is presented as the sole mechanism that balances visible-surface accuracy with occluded-layer generation and enforces ordering. No additional loss term, ordering regularizer, or explicit supervision for layer correspondence is mentioned; if the schedule does not sufficiently differentiate noise levels across layers or if factorized attention fails to propagate pixel alignment, later layers can collapse or misalign, directly violating the ordered-stack representation that underpins all downstream claims.
Authors: The mixed noise schedule is the primary mechanism described for balancing the two objectives while the factorized and global attention layers are intended to maintain pixel alignment and inter-layer consistency. No explicit ordering regularizer or additional loss term is present in the current manuscript. We will expand Section 3 to provide a more detailed derivation of how the schedule differentiates noise levels across layers, include an ablation on ordering stability when the schedule is ablated, and explicitly discuss the role of attention in preventing layer collapse. This will make the training procedure more transparent and address the potential failure modes raised. revision: yes
Circularity Check
No circularity: new representation and training procedure are self-contained
full rationale
The paper defines World Tracing as an ordered per-pixel stack of camera-space points and instantiates it via a new WT-DiT architecture trained end-to-end with pixel-space flow matching under a mixed noise schedule on external datasets. No equations, loss terms, or architectural choices are shown to reduce by construction to quantities fitted from the authors' prior work; the ordering, alignment, and completion objectives are enforced by the training procedure itself rather than presupposed. The abstract and described method contain no self-citation load-bearing steps that justify the central claims, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ARKitScenes: A diverse real-world dataset for 3D indoor scene understanding using mobile RGB-D data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, and Elad Shulman. ARKitScenes: A diverse real-world dataset for 3D indoor scene understanding using mobile RGB-D data. InNeurIPS Datasets and Benchmarks Track, 2021
2021
-
[2]
FLUX.2: Analyzing and enhancing the latent space of FLUX – representation comparison.https://bfl.ai/techblog/representation-comparison/, 2025
Black Forest Labs. FLUX.2: Analyzing and enhancing the latent space of FLUX – representation comparison.https://bfl.ai/techblog/representation-comparison/, 2025
2025
-
[3]
Wei Cao, Hao Zhang, Fengrui Tian, Yulun Wu, Yingying Li, Shenlong Wang, Ning Yu, and Yaoyao Liu. FreeOrbit4D: Training-free arbitrary camera redirection for monocular videos via geometry-complete 4D reconstruction.arXiv preprint arXiv:2601.18993, 2026
Pith/arXiv arXiv 2026
-
[4]
Jiahao Chang, Chongjie Ye, Yushuang Wu, Yuantao Chen, Yidan Zhang, Zhongjin Luo, Chenghong Li, Yihao Zhi, and Xiaoguang Han. ReconViaGen: Towards accurate multi-view 3D object reconstruction via generation.arXiv preprint arXiv:2510.23306, 2025
arXiv 2025
-
[5]
Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. ScanNet: Richly-annotated 3D reconstructions of indoor scenes. InCVPR, 2017
2017
-
[6]
Objaverse-XL: A universe of 10m+ 3d objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram Voleti, Samir Yitzhak Gadre, et al. Objaverse-XL: A universe of 10m+ 3d objects. InNeurIPS, 2023
2023
-
[7]
Objaverse: Auniverseofannotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt,KianaEhsani,AniruddhaKembhavi,andAliFarhadi. Objaverse: Auniverseofannotated 3d objects. InCVPR, 2023
2023
-
[8]
McHugh, and Vincent Vanhoucke
Laura Downs, Anthony Francis, Nathan Koenig, Brandon Kinman, Ryan Hickman, Krista Rey- mann, Thomas B. McHugh, and Vincent Vanhoucke. Google Scanned Objects: A high-quality dataset of 3d scanned household items. InICRA, 2022
2022
-
[9]
Depth map prediction from a single image using a multi-scale deep network
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network. InNeurIPS, 2014
2014
-
[10]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InICML, 2024
2024
-
[11]
Interactive order-independent transparency.White paper , nVIDIA, 2(6):7, 2001
Cass Everitt. Interactive order-independent transparency.White paper , nVIDIA, 2(6):7, 2001
2001
-
[12]
3D-FRONT: 3d furnished rooms with layouts and semantics
Huan Fu, Bowen Cai, Lin Gao, Lingxiao Zhang, Jiaming Wang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Binqiang Zhao, and Hao Zhang. 3D-FRONT: 3d furnished rooms with layouts and semantics. InICCV, 2021
2021
-
[13]
3D-FUTURE: 3D furniture shape with texture.IJCV, 2021
Huan Fu, Rongfei Jia, Lin Gao, Mingming Gong, Binqiang Zhao, Steve Maybank, and Dacheng Tao. 3D-FUTURE: 3D furniture shape with texture.IJCV, 2021
2021
-
[14]
GeoWizard: Unleashing the diffusion priors for 3d geometry estimation from a single image.ECCV, 2024
Xiao Fu, Wei Yin, Mu Hu, Kaixuan Wang, Yuexin Ma, Ping Tan, Shaojie Shen, Dahua Lin, and Xiaoxiao Long. GeoWizard: Unleashing the diffusion priors for 3d geometry estimation from a single image.ECCV, 2024
2024
-
[15]
Lotus: Diffusion-based visual foundation model for high-quality dense prediction.ICLR, 2025
Jing He, Haodong Li, Wei Yin, Yixun Liang, Leheng Li, Kaiqiang Zhou, Hongbo Zhang, Bingbing Liu, and Ying-Cong Chen. Lotus: Diffusion-based visual foundation model for high-quality dense prediction.ICLR, 2025
2025
-
[16]
LRM: Large reconstruction model for single image to 3d.ICLR, 2024
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. LRM: Large reconstruction model for single image to 3d.ICLR, 2024. 13
2024
-
[17]
X-ray: A sequential 3d representation for generation, 2024
Tao Hu, Wenhang Ge, Yuyang Zhao, and Gim Hee Lee. X-ray: A sequential 3d representation for generation, 2024. URLhttps://arxiv.org/abs/2404.14329
arXiv 2024
-
[18]
StructLDM: Structured latent diffusion for 3d human generation.ECCV, 2024
Tao Hu, Fangzhou Hong, and Ziwei Liu. StructLDM: Structured latent diffusion for 3d human generation.ECCV, 2024
2024
-
[19]
Consistent4D: Consistent 360° dynamic object generation from monocular video.ICLR, 2024
Yanqin Jiang, Li Zhang, Jin Gao, Weiming Hu, and Yao Yao. Consistent4D: Consistent 360° dynamic object generation from monocular video.ICLR, 2024
2024
-
[20]
VACE: All-in-one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. VACE: All-in-one video creation and editing. InICCV, 2025
2025
-
[21]
Peek-a- boo: Occlusion reasoning in indoor scenes with plane representations.CVPR, 2020
Ziyu Jiang, Buyu Liu, Samuel Schulter, Zhangyang Wang, and Manmohan Chandraker. Peek-a- boo: Occlusion reasoning in indoor scenes with plane representations.CVPR, 2020
2020
-
[22]
DualPM: Dual Posed-Canonical point maps for 3D shape and pose reconstruction
Ben Kaye, Tomas Jakab, Shangzhe Wu, Christian Rupprecht, and Andrea Vedaldi. DualPM: Dual Posed-Canonical point maps for 3D shape and pose reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6425–6435, June 2025
2025
-
[23]
Repurposing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Konrad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. In CVPR, 2024
2024
-
[24]
Modular primitives for high-performance differentiable rendering.ACM Trans
Samuli Laine, Janne Hellsten, Tero Karras, Yeongho Seol, Jaakko Lehtinen, and Timo Aila. Modular primitives for high-performance differentiable rendering.ACM Trans. Graph., 2020
2020
-
[25]
Grounding image matching in 3d with MASt3R
Vincent Leroy, Yohann Cabon, and Jerome Revaud. Grounding image matching in 3d with MASt3R. InECCV, 2024
2024
-
[26]
Rui Li, Biao Zhang, Zhenyu Li, Federico Tombari, and Peter Wonka. LaRI: Layered ray intersec- tions for single-view 3d geometric reasoning.arXiv preprint arXiv:2504.18424, 2025
Pith/arXiv arXiv 2025
-
[27]
Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
Pith/arXiv arXiv 2025
-
[28]
MegaDepth: Learning single-view depth prediction from Internet photos
Zhengqi Li and Noah Snavely. MegaDepth: Learning single-view depth prediction from Internet photos. InCVPR, 2018
2018
-
[29]
MegaSaM: Accurate, fast, and robust structure and motion from casual dynamic videos.CVPR, 2025
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holynski, and Noah Snavely. MegaSaM: Accurate, fast, and robust structure and motion from casual dynamic videos.CVPR, 2025
2025
-
[30]
SS4D: Native 4d generative model via structured spacetime latents.ACM Trans
Zhibing Li, Mengchen Zhang, Tong Wu, Jing Tan, Jiaqi Wang, and Dahua Lin. SS4D: Native 4d generative model via structured spacetime latents.ACM Trans. Graph., 2025
2025
-
[31]
Wonderland: Navigating 3D scenes from a single image.arXiv preprint arXiv:2412.12091, 2024
Hanwen Liang, Junli Cao, Vidit Goel, Guocheng Qian, Sergei Korolev, Demetri Terzopoulos, Konstantinos Plataniotis, Sergey Tulyakov, and Jian Ren. Wonderland: Navigating 3D scenes from a single image.arXiv preprint arXiv:2412.12091, 2024
arXiv 2024
-
[32]
PAD3R: Pose-aware dynamic 3D reconstruction from casual videos.SIGGRAPH Asia, 2025
Ting-Hsuan Liao, Haowen Liu, Yiran Xu, Songwei Ge, Gengshan Yang, and Jia-Bin Huang. PAD3R: Pose-aware dynamic 3D reconstruction from casual videos.SIGGRAPH Asia, 2025
2025
-
[33]
Magic3D: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3D: High-resolution text-to-3d content creation. InCVPR, 2023
2023
-
[34]
Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y. Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025. 14
Pith/arXiv arXiv 2025
-
[35]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InICLR, 2023
2023
-
[36]
One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion.CVPR, 2024
Minghua Liu, Ruoxi Shi, Linghao Chen, Zhuoyang Zhang, Chao Xu, Xinyue Wei, Hansheng Chen, Chong Zeng, Jiayuan Gu, and Hao Su. One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion.CVPR, 2024
2024
-
[37]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object. InICCV, 2023
2023
-
[38]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023
2023
-
[39]
Chen, Jiashi Feng, Yu-Wing Tai, Chi-Keung Tang, and Bingyi Kang
Xinhang Liu, Yuxi Xiao, Donny Y. Chen, Jiashi Feng, Yu-Wing Tai, Chi-Keung Tang, and Bingyi Kang. Trace anything: Representing any video in 4d via trajectory fields.ICLR, 2026
2026
-
[40]
SyncDreamer: Generating multiview-consistent images from a single-view image.ICLR, 2024
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. SyncDreamer: Generating multiview-consistent images from a single-view image.ICLR, 2024
2024
-
[41]
Wonder3D: Single image to 3d using cross-domain diffusion.CVPR, 2024
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, and Wenping Wang. Wonder3D: Single image to 3d using cross-domain diffusion.CVPR, 2024
2024
-
[42]
Transparency and antialiasing algorithms implemented with the virtual pixel maps technique.IEEE Computer graphics and Applications, 9(4):43–55, 1989
Abraham Mammen. Transparency and antialiasing algorithms implemented with the virtual pixel maps technique.IEEE Computer graphics and Applications, 9(4):43–55, 1989
1989
-
[43]
Luke Melas-Kyriazi, Christian Rupprecht, and Andrea Vedaldi. PC2: Projection-conditioned point cloud diffusion for single-image 3d reconstruction.arXiv preprint arXiv:2302.10668, 2023
arXiv 2023
-
[44]
Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without supervision.TMLR, 2024
2024
-
[45]
A benchmark dataset and evaluation methodology for video object segmentation
Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexan- der Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. InCVPR, 2016
2016
-
[46]
UniDepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. UniDepth: Universal monocular metric depth estimation. InCVPR, 2024
2024
-
[47]
Barron, and Ben Mildenhall
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. DreamFusion: Text-to-3d using 2d diffusion. InICLR, 2023
2023
-
[48]
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.TPAMI, 2022
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.TPAMI, 2022
2022
-
[49]
Susskind
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InICCV, 2021
2021
-
[50]
Mitra, and Tom Monnier
Remy Sabathier, David Novotny, Niloy J. Mitra, and Tom Monnier. ActionMesh: Animated 3d mesh generation with temporal 3d diffusion.CVPR, 2026
2026
-
[51]
Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization
Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, and Hao Li. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2304–2314, 2019
2019
-
[52]
Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization, 2020
Shunsuke Saito, Tomas Simon, Jason Saragih, and Hanbyul Joo. Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization, 2020. URLhttps://arxiv.org/ abs/2004.00452. 15
arXiv 2020
-
[53]
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J. Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, Aohan Lin, Jiawei Liu, Ziqi Ma, Anushka Sagar, Bowen Song, Xiaodong Wang, Jianing Yang, Bowen Zhang, Piotr Dollár, Georgia Gkioxari, Matt Feiszli, and Jitendra Malik. SAM 3D: 3dfy anything in images.arXiv prepr...
Pith/arXiv arXiv 2025
-
[54]
Schönberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger
Thomas Schöps, Johannes L. Schönberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger. A multi-view stereo benchmark with high-resolution images and multi-camera videos. InCVPR, 2017
2017
-
[55]
Using layered depth images for interactive rendering
Jonathan Shade. Using layered depth images for interactive rendering. InSIGGRAPH (tutorial), 1998
1998
-
[56]
Layered depth images
Jonathan Shade, Steven Gortler, Li-wei He, and Richard Szeliski. Layered depth images. In SIGGRAPH, 1998
1998
-
[57]
Zero123++: A single image to consistent multi-view diffusion base model.arXiv, 2023
Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xinyue Wei, Linghao Chen, Chong Zeng, and Hao Su. Zero123++: A single image to consistent multi-view diffusion base model.arXiv, 2023
2023
-
[58]
3d photography using context- aware layered depth inpainting.CVPR, 2020
Meng-Li Shih, Shih-Yang Su, Johannes Kopf, and Jia-Bin Huang. 3d photography using context- aware layered depth inpainting.CVPR, 2020
2020
-
[59]
Indoor segmentation and support inference from RGBD images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from RGBD images. InECCV, 2012
2012
-
[60]
LDM3D:Latentdiffusion model for 3d.arXiv preprint arXiv:2305.10853, 2023
Gabriela Ben Melech Stan, Diana Wofk, Scottie Fox, Alex Redden, Will Saxton, Jean Yu, Estelle Aflalo, Shao-YenTseng, FabioNonato, MatthiasMuller, andVasudevLal. LDM3D:Latentdiffusion model for 3d.arXiv preprint arXiv:2305.10853, 2023
arXiv 2023
-
[61]
Stefan Stojanov, Anh Thai, and James M. Rehg. Using shape to categorize: Low-shot learning with an explicit shape bias. InCVPR, 2021
2021
-
[62]
Scalabilityinperceptionforautonomous driving: Waymo Open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, JonathonShlens, ZhifengChen,andDragomirAnguelov. Scalabilityinperceptionforauto...
2020
-
[63]
DreamGaussian: Generative Gaussian splatting for efficient 3d content creation.arXiv, 2023
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. DreamGaussian: Generative Gaussian splatting for efficient 3d content creation.arXiv, 2023
2023
-
[64]
LGM: Large multi-view Gaussian model for high-resolution 3d content creation.arXiv, 2024
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. LGM: Large multi-view Gaussian model for high-resolution 3d content creation.arXiv, 2024
2024
-
[65]
Improving and generalizing flow-based generative models with minibatch optimal transport
Alexander Tong, Kilian Fatras, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector- Brooks, Guy Wolf, and Yoshua Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport. InTMLR, 2024
2024
-
[66]
Going deeper with image transformers
Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Hervé Jégou. Going deeper with image transformers. InICCV, 2021
2021
-
[67]
Truebones motions animation studios
Truebones Motions Animation Studios. Truebones motions animation studios. https:// truebones.com, 2024
2024
-
[68]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. InCVPR, 2025. 16
2025
-
[69]
MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision.CVPR, 2025
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision.CVPR, 2025
2025
-
[70]
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. MoGe-2: Accurate monocular geometry with metric scale and sharp details.arXiv preprint arXiv:2507.02546, 2025
Pith/arXiv arXiv 2025
-
[71]
DUSt3R: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. DUSt3R: Geometric 3d vision made easy. InCVPR, 2024
2024
-
[72]
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He.π3: Permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025
Pith/arXiv arXiv 2025
-
[73]
Argoverse 2: Next generation datasets for self-driving perception and forecasting
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandel- wal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, Deva Ramanan, Peter Carr, and James Hays. Argoverse 2: Next generation datasets for self-driving perception and forecasting. InNeurIPS Datasets and Benchmarks Track, 2021
2021
-
[74]
ZijieWu,ChaohuiYu,FanWang,andXiangBai. AnimateAnyMesh: Afeed-forward4Dfoundation model for text-driven universal mesh animation.arXiv preprint arXiv:2506.09982, 2025
arXiv 2025
-
[75]
Native and compact structured latents for 3D generation.Tech report, 2025
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, and Jiaolong Yang. Native and compact structured latents for 3D generation.Tech report, 2025
2025
-
[76]
Structured 3D latents for scalable and versatile 3D generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3D latents for scalable and versatile 3D generation. CVPR, 2025
2025
-
[77]
SpatialTrackerV2: 3d point tracking made easy.ICCV, 2025
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. SpatialTrackerV2: 3d point tracking made easy.ICCV, 2025
2025
-
[78]
Pixel-perfect visual geometry estimation.arXiv preprint arXiv:2601.05246, 2026
Gangwei Xu, Haotong Lin, Hongcheng Luo, Haiyang Sun, Bing Wang, Guang Chen, Sida Peng, Hangjun Ye, and Xin Yang. Pixel-perfect visual geometry estimation.arXiv preprint arXiv:2601.05246, 2026
arXiv 2026
-
[79]
InstantMesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. InstantMesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models. arXiv, 2024
2024
-
[80]
Weilong Yan, Haipeng Li, Hao Xu, Nianjin Ye, Yihao Ai, Shuaicheng Liu, and Jingyu Hu. LaS- Comp: Zero-shot 3D completion with latent-spatial consistency.arXiv preprint arXiv:2602.18735, 2026
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.