FastContext: Training Efficient Repository Explorer for Coding Agents
Pith reviewed 2026-06-27 05:18 UTC · model grok-4.3
The pith
A dedicated exploration subagent for coding agents raises task resolution by up to 5.5 percent while cutting token use by up to 60 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FastContext is a dedicated exploration subagent powered by specialized models spanning 4B to 30B parameters. These models are bootstrapped from strong reference-model trajectories and refined with task-grounded rewards that encourage broad first-turn search, multi-turn evidence gathering, and precise citation of file paths and line ranges. When invoked on demand, the subagent returns concise context instead of polluting the solver's history. Integration into Mini-SWE-Agent produces up to 5.5 percent higher resolution rates and up to 60 percent lower token consumption across SWE-bench Multilingual, SWE-bench Pro, and SWE-QA, with only marginal added overhead.
What carries the argument
The FastContext subagent, which separates repository exploration from task solving by returning focused file paths and line ranges from specialized models trained on reference trajectories and task-grounded rewards.
If this is right
- End-to-end resolution rates rise by up to 5.5 percent on SWE-bench Multilingual, SWE-bench Pro, and SWE-QA.
- Token consumption inside the main coding agent drops by up to 60 percent.
- The added overhead from the exploration subagent remains marginal.
- Repository exploration can be performed effectively by models kept separate from the solver model.
Where Pith is reading between the lines
- The same separation of exploration and solving could be tested in agent frameworks that do not use the Mini-SWE-Agent scaffolding.
- Task-grounded reward signals may allow the exploration models to be updated for new benchmarks without repeating the full bootstrapping step.
- Smaller models in the 4B-7B range might still deliver most of the token savings if the reward refinement step is kept.
- Dynamic invocation of the subagent based on detected search difficulty could further reduce average token cost.
Load-bearing premise
The specialized exploration models will reliably surface the minimal relevant context without omitting information the solver model needs to succeed.
What would settle it
A controlled test in which the solver model is given only the FastContext output on tasks where the full reference trajectory succeeds, and the solver then fails at a markedly higher rate.
Figures

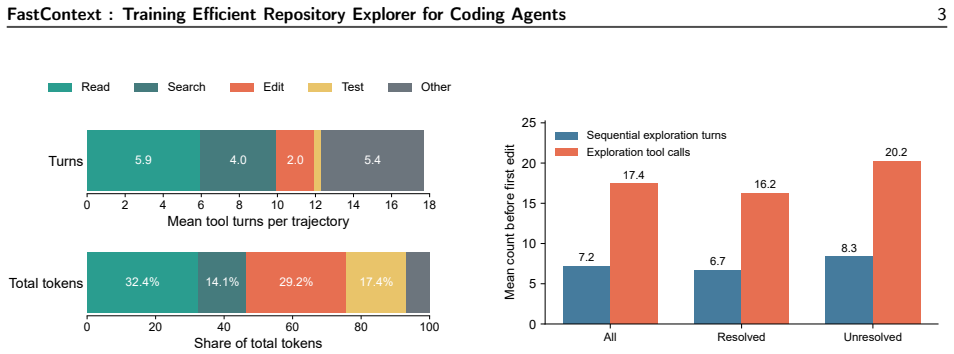



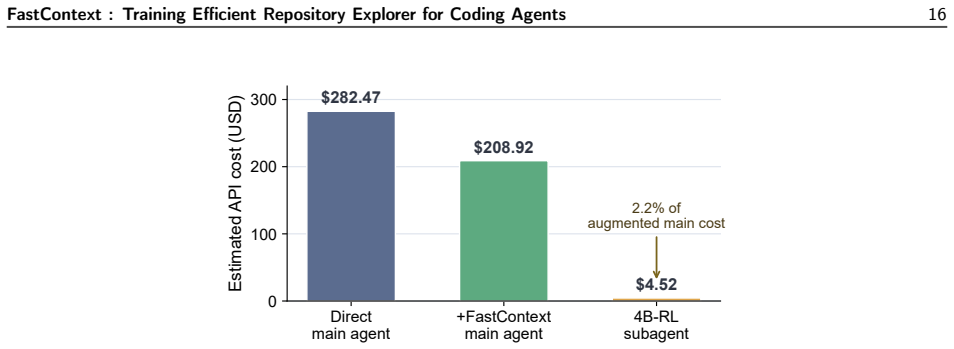
read the original abstract
Large Language Model (LLM) coding agents have achieved strong results on software engineering tasks, yet repository exploration remains a major bottleneck: locating relevant code consumes substantial token budget and pollutes the agent's context with irrelevant snippets. In most agents, the same model explores the repository and solves the task, leaving exploratory reads and searches in the solver's history. We present FastContext, a dedicated exploration subagent that separates repository exploration from solving. Invoked on demand, FastContext issues parallel tool calls and returns concise file paths and line ranges as focused context. FastContext is powered by specialized exploration models spanning 4B--30B parameters. We bootstrap them from strong reference-model trajectories and refine them with task-grounded rewards for broad first-turn search, multi-turn evidence gathering, and precise citation generation. Across SWE-bench Multilingual, SWE-bench Pro, and SWE-QA, integrating FastContext into Mini-SWE-Agent improves end-to-end resolution rates up to 5.5% while reducing coding-agent token consumption up to 60%, with marginal overhead. These results show that repository exploration can be separated from solving and handled effectively by specialized models. Code and data: https://github.com/microsoft/fastcontext
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FastContext, a dedicated exploration subagent that decouples repository exploration from task solving in LLM coding agents. Specialized models (4B–30B parameters) are bootstrapped from reference trajectories and refined via task-grounded rewards targeting broad first-turn search, multi-turn evidence gathering, and precise citation. When integrated into Mini-SWE-Agent, the approach yields up to 5.5% higher end-to-end resolution rates and up to 60% lower token consumption on SWE-bench Multilingual, SWE-bench Pro, and SWE-QA, with marginal overhead. Code and data are released at https://github.com/microsoft/fastcontext.
Significance. If the empirical results hold under scrutiny, the work supplies concrete evidence that specialized, smaller exploration models can improve both accuracy and efficiency in repository-scale coding agents. The public release of code, data, and training details is a clear strength that enables direct reproduction and extension.
major comments (3)
- [Abstract and experimental section] Abstract and experimental section: the headline gains (5.5% resolution rate, 60% token reduction) are reported as point estimates with no error bars, no mention of run-to-run variance, and no ablation tables showing the contribution of each reward component or model size; without these, it is impossible to judge whether the improvements are robust or sensitive to post-hoc choices.
- [§3.2 (Reward design)] §3.2 (Reward design): the task-grounded rewards are specified only for breadth, multi-turn gathering, and citation precision; no term or post-training analysis is described that explicitly penalizes omission of files/lines later required by the solver, which is the load-bearing assumption behind the claim that FastContext returns both minimal and complete context.
- [Evaluation protocol] Evaluation protocol: the manuscript does not report how many tasks were excluded, the exact definition of “resolution rate,” or whether the same solver model and prompt were held fixed across the baseline and FastContext conditions; these details are required to interpret the 5.5% delta.
minor comments (2)
- [Abstract] The phrase “up to 5.5%” and “up to 60%” should be accompanied by the exact benchmark and configuration that produced each maximum.
- [Results figures] Table captions and axis labels in the results figures should explicitly state the number of tasks and the statistical test used (if any).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and experimental section] Abstract and experimental section: the headline gains (5.5% resolution rate, 60% token reduction) are reported as point estimates with no error bars, no mention of run-to-run variance, and no ablation tables showing the contribution of each reward component or model size; without these, it is impossible to judge whether the improvements are robust or sensitive to post-hoc choices.
Authors: We agree that point estimates without variance measures or ablations limit assessment of robustness. In the revised manuscript we will add error bars from multiple independent runs, report run-to-run variance, and include ablation tables isolating each reward component (breadth, multi-turn gathering, citation precision) as well as model-size effects in the experimental section. revision: yes
-
Referee: [§3.2 (Reward design)] §3.2 (Reward design): the task-grounded rewards are specified only for breadth, multi-turn gathering, and citation precision; no term or post-training analysis is described that explicitly penalizes omission of files/lines later required by the solver, which is the load-bearing assumption behind the claim that FastContext returns both minimal and complete context.
Authors: The existing rewards target broad initial search and precise citations to balance coverage and relevance. We acknowledge the lack of an explicit omission penalty or supporting analysis. The revised manuscript will add a post-training analysis quantifying overlap between FastContext outputs and files/lines used by the solver on successful tasks to substantiate the completeness claim. revision: partial
-
Referee: [Evaluation protocol] Evaluation protocol: the manuscript does not report how many tasks were excluded, the exact definition of “resolution rate,” or whether the same solver model and prompt were held fixed across the baseline and FastContext conditions; these details are required to interpret the 5.5% delta.
Authors: We will revise the evaluation protocol section to state the number of excluded tasks, give the precise definition of resolution rate, and confirm that the solver model and prompts remained identical across baseline and FastContext conditions. revision: yes
Circularity Check
No circularity: empirical benchmark gains independent of training definitions
full rationale
The paper describes an empirical pipeline—bootstrapping exploration models from reference trajectories, refining via task-grounded rewards, then measuring end-to-end resolution and token savings on external suites (SWE-bench Multilingual, SWE-bench Pro, SWE-QA). No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation of the headline claims. The 5.5 % and 60 % figures are reported experimental outcomes, not quantities constructed from the reward definitions themselves.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2601.22129. GitHub. About GitHub Copilot CLI, 2026. URL https://docs.github.com/en/copilot/concepts/agents/ copilot-cli/about-copilot-cli. Zhonghao Jiang, Xiaoxue Ren, Meng Yan, Wei Jiang, Yong Li, and Zhongxin Liu. Issue localization via llm-driven iterative code graph searching, 2025. URLhttps://arxiv.org/abs/2503.22424. Carlos ...
-
[2]
URLhttps://arxiv.org/abs/2303.12570. FastContext : Training Efficient Repository Explorer for Coding Agents13 Shaoqiu Zhang, Yuhang Wang, Jialiang Liang, Yuling Shi, Wenhao Zeng, Maoquan Wang, Shilin He, Ningyuan Xu, Siyu Ye, Kai Cai, and Xiaodong Gu. Swe-explore: Benchmarking how coding agents explore repositories, 2026. URLhttps://arxiv.org/abs/2606.072...
-
[3]
Core logic to modify
This case illustrates the intended path: FastContext supplies a small set of actionable file-line evidence, allowing the main agent to move quickly from localization to reproduction and editing. Saving budget even when the baseline already succeeds.In sharkdp__bat-2201, both systems eventually fix a precedence bug where short paging flags such as -P and -...
2045
-
[5]
fix by deletion
**No-regression sanity check.** In the SAME reproducer (or as a sibling script run alongside it), include at least one assertion that exercises a closely-related, previously-working behavior in the SAME code path you touched. Example: if you removed a branch, assert that the case the branch was supposed to handle still works. This guards against "fix by d...
-
[6]
If you cannot list 2, you have not investigated enough – keep digging
**Alternative root causes ruled out.** Briefly list 2 alternative root-cause hypotheses you considered and a one-line rejection reason for each. If you cannot list 2, you have not investigated enough – keep digging. Additional rule for delete-only patches (no`+`lines, only`-`lines): - In addition to checks 1–3, run at least one EXISTING test (not authored...
-
[14]
**Verify your fix works by running your reproducer again.** FastContext : Training Efficient Repository Explorer for Coding Agents21 - If the reproducer now passes: do an edge-case sanity check, then submit. - If the reproducer still fails: emit`[ESCALATE] reproducer still failing after edit; switching to deep mode.`Then iterate edit/build/test until it p...
-
[21]
command":
At least one tool call with your command **CRITICAL REQUIREMENTS:** - Your response SHOULD include reasoning text explaining what you’re doing - Your response MUST include AT LEAST ONE bash tool call. Whenever you have multiple INDEPENDENT operations, issue them as PARALLEL tool calls in ONE response – this is significantly faster and cheaper than running...
-
[22]
**Bug-reproducing assertion ran AND passes.** Your reproducer demonstrates the original symptom, fails before the fix, and passes after
-
[23]
fix by deletion
**No-regression sanity check.** In the SAME reproducer (or as a sibling script run alongside it), include at least one assertion that exercises a closely-related, previously-working behavior in the SAME code path you touched. Example: if you removed a branch, assert that the case the branch was supposed to handle still works. This guards against "fix by d...
-
[24]
If you cannot list 2, you have not investigated enough – keep digging
**Alternative root causes ruled out.** Briefly list 2 alternative root-cause hypotheses you considered and a one-line rejection reason for each. If you cannot list 2, you have not investigated enough – keep digging. Additional rule for delete-only patches (no`+`lines, only`-`lines): - In addition to checks 1–3, run at least one EXISTING test (not authored...
-
[27]
<symbol>
**Locate relevant code (skip fastcontext when the PR already names the file/symbol):** - If the PR description already names a file path or symbol, jump straight to a narrow read with`sed -n`(or a`grep -n "<symbol>" path/to/known/file | head -n 80`). - Otherwise, call`fastcontext -q "<detailed description>" –format concise`to get a listing of relevant ranges
-
[28]
For`grep`/`rg`without`-c`/`-l`, pipe through`| head -n 80`
**Read narrowly, batch in parallel, never re-read:** From whatever listing you obtained, pick the 1–2 ranges most directly tied to the issue and use `sed -n ’A,Bp’`with`B - A <= 80`(about 30–80 lines around the relevant symbol). For`grep`/`rg`without`-c`/`-l`, pipe through`| head -n 80`. If you suspect you need 2+ ranges, issue them ALL as parallel tool c...
-
[29]
"`(if you started with fastcontext) or a focused`grep -n
**Fill in gaps if needed:** If your direct grep or fastcontext results don’t fully cover a specific aspect (e.g. a related utility function, a config value), prefer a sharper`fastcontext -q "..."`(if you started with fastcontext) or a focused`grep -n "<symbol>" path/to/specific/file | head -n 80`(if you started direct). Avoid broad repository-wide searches
-
[30]
If the PR includes a reproducer snippet, run it; otherwise write the smallest possible standalone repro
**Create a script to reproduce the issue** – this is the verification anchor. If the PR includes a reproducer snippet, run it; otherwise write the smallest possible standalone repro
-
[31]
**Edit the source code to resolve the issue.**
-
[32]
**Verify your fix works by running your reproducer again.** - If the reproducer now passes: do an edge-case sanity check, then submit. - If the reproducer still fails: emit`[ESCALATE] reproducer still failing after edit; switching to deep mode.`Then iterate edit/build/test until it passes, allowing wider reads (up to 200 lines) and re-reads with stated reasons
-
[33]
## Command Execution Rules You are operating in an environment where
**Test edge cases** to ensure your fix is robust. ## Command Execution Rules You are operating in an environment where
-
[39]
command":
At least one tool call with your command **CRITICAL REQUIREMENTS:** - Your response SHOULD include reasoning text explaining what you’re doing - Your response MUST include AT LEAST ONE bash tool call. Whenever you have multiple INDEPENDENT operations, issue them as PARALLEL tool calls in ONE response – this is significantly faster and cheaper than running...
-
[41]
Provide one or more bash tool calls to explore the code ## Recommended Workflow
-
[42]
<detailed description of what to find>
**Use fastcontext to locate relevant code**: Start by running`fastcontext -q "<detailed description of what to find>" –format concise`to find the files and line ranges related to the question
-
[43]
Read the identified files to understand the code in depth
-
[44]
Explore related files as needed to build a complete picture
-
[45]
Search for additional context (tests, docs, related classes) that strengthens your answer
-
[46]
Write a comprehensive answer citing specific files, line numbers, class/function names ## Command Execution Rules You are operating in an environment where:
-
[48]
The system executes the command(s) in a subshell with the repo as the working directory
-
[52]
command":
At least one tool call with your command **CRITICAL REQUIREMENTS:** - Your response SHOULD include reasoning text explaining what you’re doing - Your response MUST include AT LEAST ONE bash tool call. You can make MULTIPLE tool calls in a single response when the commands are independent. - Directory or environment variable changes are not persistent. Eve...
-
[54]
Provide one or more bash tool calls to execute ## Important Boundaries - MODIFY: Regular source code files in /testbed (this is the working directory for all your subsequent commands) - DO NOT MODIFY: Tests, configuration files (pyproject.toml, setup.cfg, etc.) ## Recommended Workflow
-
[66]
command":
At least one tool call with your command **CRITICAL REQUIREMENTS:** - Your response SHOULD include reasoning text explaining what you’re doing - Your response MUST include AT LEAST ONE bash tool call. You can make MULTIPLE tool calls in a single response when the commands are independent (e.g., searching multiple files, reading different parts of the code...
-
[67]
Include a THOUGHT section explaining your reasoning and what you’re trying to accomplish FastContext : Training Efficient Repository Explorer for Coding Agents28
-
[68]
Provide one or more bash tool calls to execute ## Important Boundaries - MODIFY: Regular source code files in /app (this is the working directory for all your subsequent commands) - DO NOT MODIFY: Tests, configuration files (pyproject.toml, setup.cfg, etc.) ## Recommended Workflow
-
[69]
<detailed description of what to find>
**Use fastcontext to locate relevant code**: Start by running`fastcontext -q "<detailed description of what to find>" –format concise`to find the files and line ranges related to the issue
-
[70]
Read the identified files to understand the code
-
[71]
Create a script to reproduce the issue
-
[72]
Edit the source code to resolve the issue
-
[73]
Verify your fix works by running your script again
-
[74]
Test edge cases to ensure your fix is robust ## Command Execution Rules You are operating in an environment where
-
[79]
**Reasoning text** where you explain your analysis and plan
-
[80]
command":
At least one tool call with your command **CRITICAL REQUIREMENTS:** - Your response SHOULD include reasoning text explaining what you’re doing - Your response MUST include AT LEAST ONE bash tool call. You can make MULTIPLE tool calls in a single response when the commands are independent (e.g., searching multiple files, reading different parts of the code...
-
[81]
Include a THOUGHT section explaining your reasoning and what you’re trying to accomplish
-
[82]
Provide one or more bash tool calls to execute ## Recommended Workflow
-
[83]
<detailed description of what to find>
**Use fastcontext to locate relevant code**: Run`fastcontext -q "<detailed description of what to find>" –format concise`
-
[84]
Read the identified files to understand the implementation
-
[85]
Explore related files and components as needed
-
[86]
Formulate a comprehensive, accurate answer ## Command Execution Rules
-
[87]
You issue at least one command
-
[88]
The system executes the command(s) in a subshell
-
[89]
You see the result(s)
-
[90]
You write your next command(s) Each response should include:
-
[91]
**Reasoning text** where you explain your analysis
-
[92]
Calling`echo COMPLETE_TASK_AND_SUBMIT_FINAL_OUTPUT`alone submits an empty answer
At least one tool call with your command **CRITICAL REQUIREMENTS:** - Your response SHOULD include reasoning text - Your response MUST include AT LEAST ONE bash tool call - Directory or environment variable changes are not persistent – prefix commands with`cd /path && ...` ## Submission When you have a complete, well-supported answer, submit it with a SIN...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.