SILAGE: Memory-Efficient, Full-Gradient-Free Nonconvex Optimization for Nested Finite Sums
Pith reviewed 2026-06-27 03:38 UTC · model grok-4.3
The pith
SILAGE optimizes nonconvex nested finite sums with O(n) memory and no periodic full-gradient refreshes over all samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
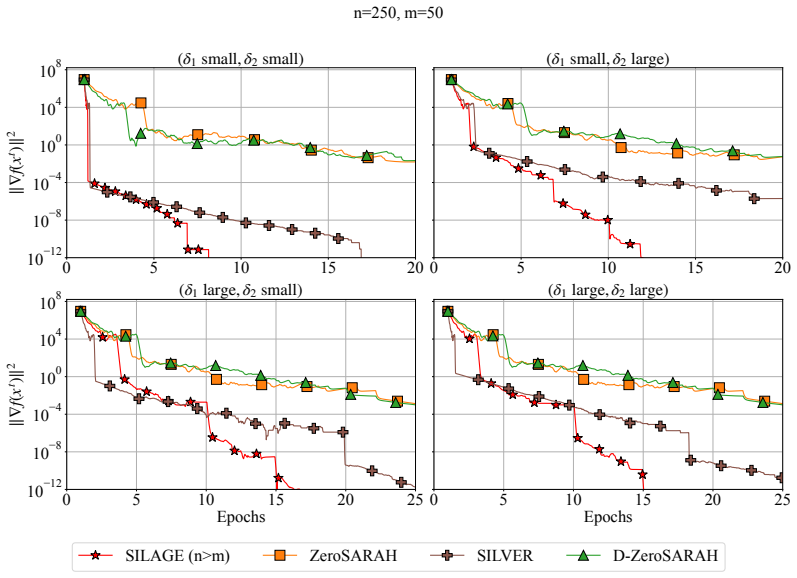
SILAGE eliminates periodic global full-gradient refreshes over all nm components while requiring only O(n) memory; its complexity natively adapts to the underlying data geometry via nested functional similarities characterized by across-group heterogeneity δ1 and within-group heterogeneity δ2 rather than relying on pessimistic worst-case Lipschitz constants.
What carries the argument
The SILAGE variance-reduced recursion that exploits the double-sum partition to maintain a single local group gradient estimator per iteration together with the pair of heterogeneity parameters δ1 and δ2 that replace global Lipschitz constants in the convergence bound.
If this is right
- Convergence rates improve over PAGE and SILVER whenever the data's nested similarities are stronger than the worst-case Lipschitz bound.
- Only one local group gradient evaluation is needed per iteration instead of a global refresh.
- Memory scales linearly with the number of groups n rather than the total number of samples nm.
- The analysis supplies explicit dependence on δ1 and δ2 that recovers standard rates when those quantities approach the global Lipschitz constant.
Where Pith is reading between the lines
- The same nested-heterogeneity idea could be tested on streaming or federated data where groups arrive sequentially or reside on separate nodes.
- If δ1 and δ2 can be estimated cheaply during training, the method might automatically switch between local and global refresh strategies.
- The approach suggests examining other nested stochastic problems, such as nested expectations in reinforcement learning, for analogous memory-convergence trade-offs.
Load-bearing premise
The data must exhibit measurable nested functional similarities captured by across-group heterogeneity δ1 and within-group heterogeneity δ2 so that complexity bounds can adapt without defaulting to worst-case Lipschitz constants.
What would settle it
An experiment on a partitioned dataset where measured δ1 and δ2 are large, showing that SILAGE still requires either O(nm) memory or periodic nm-component gradient refreshes to match the stated convergence rate, would falsify the claimed advantage.
Figures

read the original abstract
Empirical risk minimization on massive datasets naturally exhibits a nested double finite-sum structure, where $N=nm$ total samples are logically or physically partitioned into $n$ blocks of size $m$ (e.g., in pooled data silos, out-of-core learning, or deliberate stratification). While variance-reduced methods achieve optimal oracle complexities for nonconvex objectives, they suffer from severe scaling bottlenecks in this centralized regime. Recursive estimators, such as PAGE, require periodic global full-gradient refreshes over all $nm$ samples, which are computationally expensive. Conversely, single-loop methods, such as SILVER, avoid such refreshes but require an impractical $\mathcal{O}(nm)$ memory footprint to store a control variate for every sample. In this paper, we propose SILAGE, a variance-reduced algorithm that addresses this trade-off. By actively exploiting the double-sum structure, SILAGE eliminates periodic global full-gradient refreshes over all $nm$ components (evaluating at most one local group gradient per iteration) while requiring only $\mathcal{O}(n)$ memory. Furthermore, we provide a tight convergence analysis that avoids pessimistic worst-case Lipschitz constants. Instead, SILAGE's complexity natively adapts to the underlying data geometry via nested functional similarities: across-group ($\delta_1$) and within-group ($\delta_2$) heterogeneity. Our results improve existing state-of-the-art bounds in several practically relevant regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SILAGE, a variance-reduced algorithm for nonconvex optimization over nested finite sums (N=nm samples partitioned into n groups of m). It claims to eliminate periodic global full-gradient refreshes over all nm components by evaluating at most one local group gradient per iteration, while using only O(n) memory. The method provides a tight convergence analysis whose complexity adapts to the data geometry via across-group heterogeneity δ1 and within-group heterogeneity δ2, rather than worst-case Lipschitz constants, and improves on PAGE and SILVER in several regimes.
Significance. If the central claims hold, the result offers a practical advance for large-scale nested ERM (e.g., pooled silos or stratified data) by resolving the memory-computation trade-off between recursive estimators and single-loop methods. The geometry-adaptive analysis is a notable strength, as it avoids pessimistic constants when the nested similarities are present.
major comments (2)
- [§4] §4, Theorem 1 (or equivalent convergence statement): the claimed O(·) complexity that adapts to δ1/δ2 must be shown to reduce to the standard nonconvex rate when δ1=δ2=1 (worst-case heterogeneity); the current abstract description leaves open whether the bound remains valid or requires additional assumptions on the similarity measures.
- [§3.2] Algorithm 1 and §3.2: the memory claim of O(n) is load-bearing for the contribution relative to SILVER; the update rules for the control variates must be verified to store only one vector per group without implicit O(m) storage per iteration.
minor comments (2)
- [Introduction] Define δ1 and δ2 with a concrete example or inequality immediately after the abstract to make the adaptive claim accessible.
- [Table 1] Add a table comparing oracle complexity, memory, and refresh frequency against PAGE and SILVER under different (δ1,δ2) regimes.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4, Theorem 1 (or equivalent convergence statement): the claimed O(·) complexity that adapts to δ1/δ2 must be shown to reduce to the standard nonconvex rate when δ1=δ2=1 (worst-case heterogeneity); the current abstract description leaves open whether the bound remains valid or requires additional assumptions on the similarity measures.
Authors: We agree that an explicit reduction check improves clarity. In the revision we will add a remark immediately after Theorem 1 showing that δ1=δ2=1 recovers the standard nonconvex rate O(ε^{-4}) (ignoring logs) under exactly the same assumptions already stated in the theorem; no extra conditions on the similarity measures are needed. The parameters satisfy δ1,δ2≥1 by definition, so the bound is valid for all admissible instances. revision: yes
-
Referee: [§3.2] Algorithm 1 and §3.2: the memory claim of O(n) is load-bearing for the contribution relative to SILVER; the update rules for the control variates must be verified to store only one vector per group without implicit O(m) storage per iteration.
Authors: The algorithm stores precisely one control-variate vector per group (n vectors total). The update rules in Algorithm 1 replace the group-level control variate with a convex combination involving only the newly sampled local gradient; no per-sample vectors are retained. We will insert a clarifying sentence in §3.2 and a parenthetical note in the algorithm caption confirming that memory remains strictly O(n) independent of m. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces SILAGE as a new variance-reduced method for nested finite-sum nonconvex optimization, claiming O(n) memory, no periodic full-gradient refreshes over nm samples, and convergence bounds that adapt to data geometry via δ1 (across-group) and δ2 (within-group) heterogeneity. The abstract and description present the algorithm construction and analysis as independent developments that improve on PAGE and SILVER without any quoted step reducing a claimed prediction or bound to a fitted input, self-definition, or self-citation chain by construction. No load-bearing derivation is shown to be equivalent to its inputs; the central claims remain self-contained against the stated goals and assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard assumptions on smoothness, bounded variance, and nonconvexity for stochastic optimization hold.
- domain assumption Data possesses nested structure allowing definition of across-group (δ1) and within-group (δ2) heterogeneity measures.
Reference graph
Works this paper leans on
-
[1]
Beznosikov and A
A. Beznosikov and A. Gasnikov. Compression and data similarity: Combination of two techniques for communication-efficient solving of distributed variational inequalities. InInter- national Conference on Optimization and Applications, pages 151–162. Springer, 2022
2022
- [2]
-
[3]
L. Bottou. Stochastic gradient descent tricks. In G. Montavon, G. B. Orr, and K.-R. Müller, editors,Neural Networks: Tricks of the Trade, pages 421–436. Springer Berlin Heidelberg, Berlin, Heidelberg, 2nd edition, 2012
2012
-
[4]
Brown et al
T. Brown et al. Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc., 2020
1901
-
[5]
R. Caruana. Multitask learning.Machine learning, 28(1):41–75, 1997
1997
-
[6]
E. M. Chayti and S. P. Karimireddy. Optimization with access to auxiliary information.Trans- actions on Machine Learning Research, 2024
2024
- [7]
-
[8]
Condat and P
L. Condat and P. Richtárik. MURANA: A generic framework for stochastic variance-reduced optimization. InProc. of the conference Mathematical and Scientific Machine Learning (MSML), PMLR 190, 2022
2022
-
[9]
Defazio, F
A. Defazio, F. Bach, and S. Lacoste-Julien. SAGA: A fast incremental gradient method with support for non-strongly convex composite objectives. InAdvances in neural information processing systems, pages 1646–1654, 2014
2014
-
[10]
Demidovich, G
Y . Demidovich, G. Malinovsky, I. Sokolov, and P. Richtárik. A guide through the zoo of biased sgd.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[11]
Evgeniou and M
T. Evgeniou and M. Pontil. Regularized multi–task learning. InProceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 109–117, 2004. 15
2004
-
[12]
C. Fang, C. J. Li, Z. Lin, and T. Zhang. SPIDER: Near-optimal non-convex optimization via stochastic path-integrated differential estimator.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[13]
I. Fatkhullin, I. Sokolov, E. Gorbunov, Z. Li, and P. Richtárik. EF21 with bells & whistles: Practical algorithmic extensions of modern error feedback. preprint arXiv:2110.03294, 2021
-
[14]
Goodfellow, Y
I. Goodfellow, Y . Bengio, and A. Courville.Deep learning. MIT press, 2016
2016
-
[15]
S. Horváth, M. Sanjabi, L. Xiao, P. Richtárik, and M. Rabbat. FedShuffle: Recipes for better use of local work in federated learning.arXiv preprint arXiv:2204.13169, 2022
-
[16]
Johnson and T
R. Johnson and T. Zhang. Accelerating stochastic gradient descent using predictive variance reduction.Advances in neural information processing systems, 26:315–323, 2013
2013
- [17]
-
[18]
Khaled and C
A. Khaled and C. Jin. Faster federated optimization under second-order similarity. InProc. of International Conference on Learning Representations (ICLR), 2023
2023
-
[19]
Federated Optimization: Distributed Machine Learning for On-Device Intelligence
J. Koneˇcný, H. B. McMahan, D. Ramage, and P. Richtárik. Federated optimization: distributed machine learning for on-device intelligence. arXiv:1610.02527, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Kovalev, S
D. Kovalev, S. Horváth, and P. Richtárik. Don’t jump through hoops and remove those loops: SVRG and Katyusha are better without the outer loop. InProc. of Algorithmic Learning Theory (ALT), pages 451–467, 2020
2020
-
[21]
D. Kovalev, A. Beznosikov, E. Borodich, A. Gasnikov, and G. Scutari. Optimal gradient sliding and its application to distributed optimization under similarity.arXiv preprint arXiv:2205.15136, 2022
-
[22]
L. Lei, C. Ju, J. Chen, and M. I. Jordan. Non-convex finite-sum optimization via SCSG methods. Advances in Neural Information Processing Systems, 30, 2017
2017
-
[23]
B. Li, M. Ma, and G. B. Giannakis. On the convergence of SARAH and beyond. InProc. of 23rd Int. Conf. Artificial Intelligence and Statistics (AISTATS), volume PMLR 108, pages 223–233, 2020
2020
-
[24]
Z. Li. SSRGD: Simple stochastic recursive gradient descent for escaping saddle points.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[25]
Z. Li, H. Bao, X. Zhang, and P. Richtárik. PAGE: A simple and optimal probabilistic gradient estimator for nonconvex optimization. InProc. of 38th Int. Conf. Machine Learning (ICML), volume PMLR 139, pages 6286–6295, 2021
2021
- [26]
-
[27]
L. Liu, J. Zhang, S. Song, and K. B. Letaief. Client-edge-cloud hierarchical federated learning. InProc. of IEEE Int. Conf. Communications (ICC), pages 1–6, 2020
2020
-
[28]
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. Agüera y Arcas. Communication- efficient learning of deep networks from decentralized data. InProc. of Int. Conf. Artificial Intelligence and Statistics (AISTATS), PMLR 54, 2017
2017
-
[29]
Nesterov.Introductory lectures on convex optimization: a basic course
Y . Nesterov.Introductory lectures on convex optimization: a basic course. Kluwer Academic Publishers, 2004
2004
-
[30]
L. M. Nguyen, J. Liu, K. Scheinberg, and M. Takáˇc. SARAH: A novel method for machine learning problems using stochastic recursive gradient. InProc. of Int. Conf. Machine Learning (ICML), pages 2613–2621, 2017. 16
2017
-
[31]
K. Oko, S. Akiyama, D. Wu, T. Murata, and T. Suzuki. SILVER: Single-loop variance reduction and application to federated learning. InProc. of Int. Conf. Machine Learning (ICML), 2024
2024
-
[32]
Radford, J
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[33]
Richtárik, I
P. Richtárik, I. Sokolov, and I. Fatkhullin. EF21: A new, simpler, theoretically better, and practically faster error feedback. InProc. of 35th Conf. Neural Information Processing Systems (NeurIPS), 2021
2021
-
[34]
Richtárik, I
P. Richtárik, I. Sokolov, E. Gasanov, I. Fatkhullin, Z. Li, and E. Gorbunov. 3pc: Three point compressors for communication-efficient distributed training and a better theory for lazy aggregation. InInternational Conference on Machine Learning, pages 18596–18648. PMLR, 2022
2022
-
[35]
Sadiev, G
A. Sadiev, G. Malinovsky, E. Gorbunov, I. Sokolov, A. Khaled, K. P. Burlachenko, and P. Richtárik. Don’t compress gradients in random reshuffling: Compress gradient differences. InAdvances in Neural Information Processing Systems, 2024
2024
- [36]
-
[37]
Schmidt, N
M. Schmidt, N. Le Roux, and F. Bach. Minimizing finite sums with the stochastic average gradient.Mathematical Programming, 162:83–112, 2017
2017
-
[38]
Shalev-Shwartz and S
S. Shalev-Shwartz and S. Ben-David.Understanding machine learning: From theory to algorithms. Cambridge University Press, 2014
2014
-
[39]
Sokolov.Non-convex Stochastic Optimization With Biased Gradient Estimators
I. Sokolov.Non-convex Stochastic Optimization With Biased Gradient Estimators. PhD thesis, King Abdullah University of Science and Technology, 2022
2022
-
[40]
I. Sokolov and P. Richtárik. MARINA-P: Superior performance in non-smooth federated optimization with adaptive stepsizes.arXiv preprint arXiv:2412.17082, 2024
-
[41]
I. Sokolov, A. Sadiev, Y . Demidovich, F. S. Al-Qahtani, and P. Richtárik. Bernoulli-lora: A theoretical framework for randomized low-rank adaptation.arXiv preprint arXiv:2508.03820, 2025
-
[42]
Y . Tian, G. Scutari, T. Cao, and A. Gasnikov. Acceleration in distributed optimization under similarity. InInternational Conference on Artificial Intelligence and Statistics, pages 5721–5756. PMLR, 2022
2022
-
[43]
Tyurin and P
A. Tyurin and P. Richtárik. DASHA: Distributed nonconvex optimization with communication compression, optimal oracle complexity, and no client synchronization. InProc. of International Conference on Learning Representations (ICLR), 2023
2023
-
[44]
Tyurin, L
A. Tyurin, L. Sun, K. P. Burlachenko, and P. Richtárik. Sharper rates and flexible framework for nonconvex SGD with client and data sampling.Transactions on Machine Learning Research, 2023
2023
-
[45]
V . N. Vapnik and A. Y . Chervonenkis. On the uniform convergence of relative frequencies of events to their probabilities.Theory of Probability & Its Applications, 16(2):264–280, 1971
1971
-
[46]
Z. Wang, K. Ji, Y . Zhou, Y . Liang, and V . Tarokh. SpiderBoost and momentum: Faster stochastic variance reduction algorithms.Advances in Neural Information Processing Systems, 32, 2019
2019
- [47]
-
[48]
Zhang and L
Y . Zhang and L. Xiao. Communication-efficient distributed optimization of self-concordant empirical loss.Large-Scale and Distributed Optimization, pages 289–341, 2018
2018
-
[49]
H. Zhao, Z. Li, and P. Richtárik. FedPAGE: A fast local stochastic gradient method for communication-efficient federated learning. preprint arXiv:2108.04755, 2021. 17 Contents 1 Introduction 1 1.1 The centralized double-sum paradigm . . . . . . . . . . . . . . . . . . . . . . . . 1 1.2 Related work and contributions . . . . . . . . . . . . . . . . . . . ....
-
[50]
The probability of this event is the complement of Case 1: 1− 𝑝 𝑛
Recursive Update (Case 2):This occurs if 𝜃𝑡 = 0, or if 𝜃𝑡 = 1 but 𝑖𝑡 ̸=𝑖 . The probability of this event is the complement of Case 1: 1− 𝑝 𝑛 . In this case,𝑔 𝑡+1 𝑖 :=𝑔 𝑡 𝑖 +∇𝑓 𝑖,𝑗𝑡 𝑖 (𝑥𝑡+1)− ∇𝑓 𝑖,𝑗𝑡 𝑖 (𝑥𝑡). 24 Applying the law of total expectation over the random choices at iteration𝑡, we obtain: E [︁⃦⃦𝑔𝑡+1 𝑖 − ∇𝑓𝑖(𝑥𝑡+1) ⃦⃦2⃒⃒⃒ ℱ 𝑡 ]︁ = 𝑝 𝑛 ·0 + (︁ 1− 𝑝 𝑛...
-
[51]
outer” deviations are grouped inside one squared norm and the “inner
Anchor reset ( 𝑖=𝑖 𝑡).This event has probability Prob(𝑖=𝑖 𝑡) = 1 𝑛. In this case, 𝑔𝑡+1 𝑖 =∇𝑓 𝑖(𝑥𝑡+1), hence ⃦⃦𝑔𝑡+1 𝑖 − ∇𝑓𝑖(𝑥𝑡+1) ⃦⃦2 = 0. 2.Recursive update (𝑖∈Ω 𝑡).SinceΩ 𝑡 is sampled uniformly from[𝑛]∖ {𝑖 𝑡}, we have Prob(𝑖∈Ω 𝑡) =Prob(𝑖 𝑡 ̸=𝑖)Prob(𝑖∈Ω 𝑡 |𝑖 𝑡 ̸=𝑖) = 𝑛−1 𝑛 · 𝑏grp −1 𝑛−1 = 𝑏grp −1 𝑛 . In this case, 𝑔𝑡+1 𝑖 =𝑔 𝑡 𝑖 +∇𝑓 𝑖,𝑗𝑡 𝑖 (𝑥𝑡+1)− ∇𝑓 𝑖,𝑗𝑡 ...
2080
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.