BALTO: Balanced Token-Level Policy Optimization for Hallucination Mitigation
Pith reviewed 2026-06-27 04:03 UTC · model grok-4.3
The pith
BALTO uses balanced token-level credit assignment to reduce hallucinations in LLMs while preserving response informativeness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
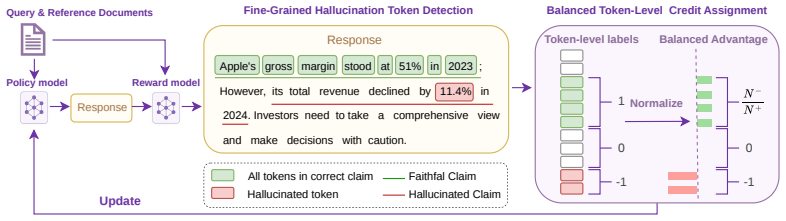
BALTO extracts factual claims from model outputs, verifies each claim against the reference context, projects the resulting judgments to token-level labels, and applies a balanced token-level credit assignment that redistributes probability mass from unsupported content to faithful content; theoretical analysis establishes that this design improves training stability and optimization efficiency over response-level rewards for hallucination mitigation.
What carries the argument
The balanced token-level credit assignment mechanism that redistributes probability mass from unsupported content toward faithful content instead of suppressing entire responses.
If this is right
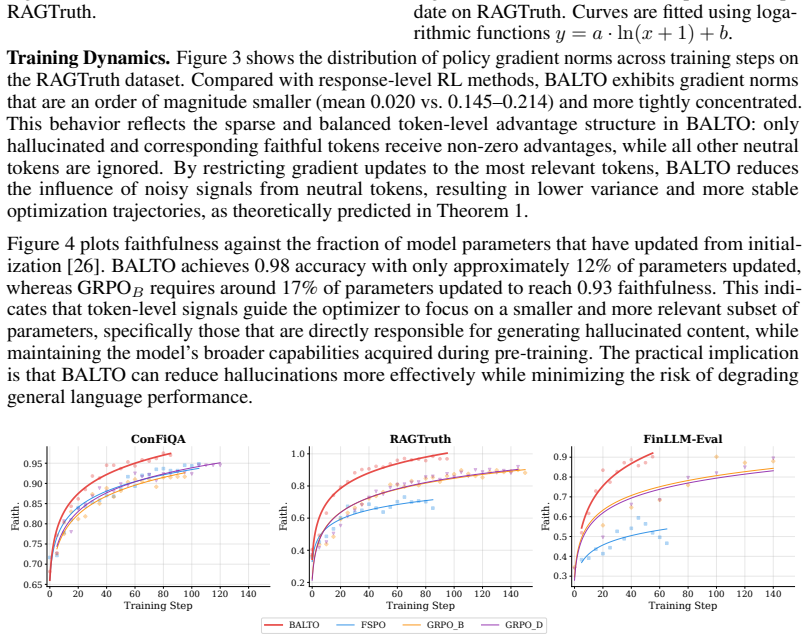
- BALTO attains the highest faithfulness across all six model-benchmark settings tested.
- It consistently exceeds existing post-training baselines on Q-Score.
- It exhibits a stronger faithfulness-informativeness trade-off than prior methods.
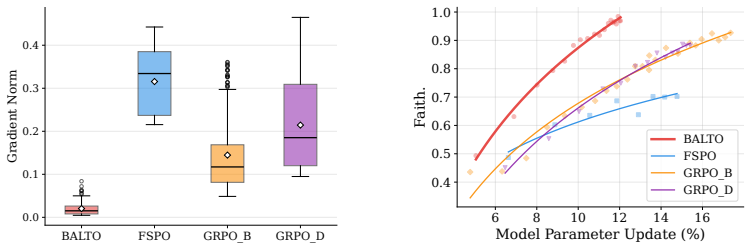
- Training stability and optimization efficiency improve for hallucination mitigation tasks.
- Response-level rewards are shown to suffer from granularity mismatch that token-level balancing avoids.
Where Pith is reading between the lines
- The same projection and balancing steps could be tested on multi-turn or open-ended generation tasks where evidence is only partially available.
- If the token labels remain unbiased across domains, the framework might reduce reliance on human preference data for general alignment objectives.
- Applying BALTO to models that already use retrieval-augmented generation could isolate whether the gains come mainly from the credit mechanism or from the claim extraction step.
- Measuring the variance of token-level rewards before and after balancing would provide a direct check on the claimed stability improvement.
Load-bearing premise
The projection from claim-level verification judgments to token-level labels can be performed without introducing systematic bias or requiring extra fitted parameters that depend on the target faithfulness metric.
What would settle it
A new model-benchmark pair in which BALTO does not achieve the highest faithfulness score or underperforms existing baselines on Q-Score.
Figures

read the original abstract
Hallucinations remain a major obstacle to deploying large language models (LLMs) in knowledge-intensive settings, where generated responses must be faithfully grounded in provided evidence. Reinforcement learning (RL) is a promising direction for hallucination mitigation, but response-level faithfulness rewards suffer from a granularity mismatch: localized hallucinations can cause supported content to receive spurious penalties. Although recent work introduces fine-grained feedback such as claim-level verification and token-level rewards, unbalanced credit assignment can still induce length, verbosity, or optimization-noise biases. We propose BALTO, a Balanced Token-level Policy Optimization framework for hallucination mitigation. BALTO extracts checkable factual claims, verifies them against the reference context, and projects claim-level judgments to token-level labels. A balanced token-level credit assignment mechanism is introduced into the framework. This design redistributes probability mass from unsupported content toward faithful content, rather than suppressing the entire response. We systematically analyze the limitations of response-level rewards from a theoretical standpoint, and prove BALTO's advantages in training stability and optimization efficiency for hallucination mitigation. Experiments on ConFiQA, RAGTruth, and FinLLM-Eval show that BALTO achieves the highest faithfulness across all six model--benchmark settings and consistently outperforms existing post-training baselines in Q-Score, demonstrating a stronger faithfulness--informativeness trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BALTO, a token-level RL framework for mitigating hallucinations in LLMs. It extracts verifiable claims from responses, verifies them against reference context, projects the judgments to token-level labels, and applies a balanced credit-assignment mechanism that redistributes probability mass from unsupported to supported tokens. The authors provide a theoretical analysis of response-level reward limitations and prove BALTO's advantages in training stability and optimization efficiency; experiments on ConFiQA, RAGTruth, and FinLLM-Eval across six model-benchmark pairs report highest faithfulness and improved Q-Score over post-training baselines.
Significance. If the central claims hold, BALTO would represent a meaningful advance in fine-grained RL for hallucination mitigation by addressing granularity mismatch without suppressing entire responses. The theoretical stability analysis and consistent outperformance on faithfulness-informativeness trade-off would be notable strengths for knowledge-intensive applications.
major comments (2)
- [Abstract / §3] Abstract and §3 (method): the projection from claim-level verification judgments to token-level labels is load-bearing for both the theoretical guarantees and the reported experimental gains, yet the manuscript provides no analysis showing this projection is free of systematic bias (length, position, or verifier-dependent correlations) or additional fitted parameters whose tuning depends on the downstream Q-Score metric. The stability proof assumes clean token labels and therefore does not address this upstream step.
- [§4] §4 (experiments): the claim that BALTO achieves the highest faithfulness across all six settings and a stronger trade-off rests on the projection step; without ablations isolating the projection rule from the balanced credit-assignment mechanism, it is unclear whether the reported superiority is attributable to the proposed method or to the label-generation procedure itself.
minor comments (2)
- [§3] Notation for the balanced credit-assignment term should be defined explicitly with an equation number rather than described only in prose.
- [§4] Dataset statistics (number of claims per response, verification accuracy of the claim extractor) are needed to assess the reliability of the token-label pipeline.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our paper. We address each major comment below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method): the projection from claim-level verification judgments to token-level labels is load-bearing for both the theoretical guarantees and the reported experimental gains, yet the manuscript provides no analysis showing this projection is free of systematic bias (length, position, or verifier-dependent correlations) or additional fitted parameters whose tuning depends on the downstream Q-Score metric. The stability proof assumes clean token labels and therefore does not address this upstream step.
Authors: We appreciate the referee pointing out the importance of validating the projection step. The projection is a direct, parameter-free mapping: each token receives the label of the claim it belongs to, or neutral if not part of any claim. No additional parameters are fitted, and it does not depend on the Q-Score. However, we agree that explicit checks for systematic biases (e.g., longer claims affecting more tokens, position biases) are absent from the current version. We will add an analysis section with empirical statistics on label distributions across the datasets and correlation checks with length and position. For the stability proof, it indeed assumes the token labels as input and analyzes the balanced credit assignment; we will update the text to explicitly state this scope and note that the projection is a preprocessing step. revision: yes
-
Referee: [§4] §4 (experiments): the claim that BALTO achieves the highest faithfulness across all six settings and a stronger trade-off rests on the projection step; without ablations isolating the projection rule from the balanced credit-assignment mechanism, it is unclear whether the reported superiority is attributable to the proposed method or to the label-generation procedure itself.
Authors: We acknowledge that isolating the contribution of the balanced credit-assignment from the projection would provide clearer attribution. The projection is a necessary component to enable token-level rewards, but the key innovation is the balanced redistribution mechanism. To address this, we will include additional ablation experiments in the revised manuscript, such as comparing the balanced mechanism against a standard token-level RL using the same projection, and variants with different projection rules if applicable. This will help demonstrate that the gains come from the proposed balanced assignment. revision: yes
Circularity Check
No circularity in derivation chain; projection and proof presented as independent steps
full rationale
The paper introduces a claim-to-token projection and balanced credit assignment as novel mechanisms, followed by a theoretical analysis of response-level reward limitations and a stability proof for BALTO. No equations, fitted parameters, or self-citations are visible that reduce the claimed faithfulness gains or stability advantages back to the input labels or prior author work by construction. The central claims rest on the described pipeline and external benchmarks rather than self-referential definitions or renamings.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large language models hallucination: A comprehensive survey.Computer Science Review, 61:100970, 2026
Aisha Alansari and Hamzah Luqman. Large language models hallucination: A comprehensive survey.Computer Science Review, 61:100970, 2026
2026
-
[2]
Patrice Béchard and Orlando Marquez Ayala. Reducing hallucination in structured outputs via retrieval-augmented generation.arXiv preprint arXiv:2404.08189, 2024
arXiv 2024
-
[3]
Context-dpo: Aligning language models for context-faithfulness
Baolong Bi, Shaohan Huang, Yiwei Wang, Tianchi Yang, Zihan Zhang, Haizhen Huang, Lingrui Mei, Junfeng Fang, Zehao Li, Furu Wei, et al. Context-dpo: Aligning language models for context-faithfulness. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10280–10300, 2025
2025
-
[4]
Alex J Chan, Hao Sun, Samuel Holt, and Mihaela Van Der Schaar. Dense reward for free in reinforcement learning from human feedback.arXiv preprint arXiv:2402.00782, 2024
arXiv 2024
-
[5]
Hongzhan Chen, Tao Yang, Shiping Gao, Ruijun Chen, Xiaojun Quan, Hongtao Tian, and Ting Yao. Discriminative policy optimization for token-level reward models.arXiv preprint arXiv:2505.23363, 2025
arXiv 2025
-
[6]
Research: Learning to reason with search for llms via reinforcement learning
M Chen, L Sun, T Li, H Sun, Y Zhou, C Zhu, H Wang, JZ Pan, W Zhang, H Chen, et al. Research: Learning to reason with search for llms via reinforcement learning. arxiv 2025.arXiv preprint arXiv:2503.19470
Pith/arXiv arXiv 2025
-
[7]
Learning to reason for factuality.arXiv preprint arXiv:2508.05618, 2025
Xilun Chen, Ilia Kulikov, Vincent-Pierre Berges, Barlas O˘guz, Rulin Shao, Gargi Ghosh, Jason Weston, and Wen-tau Yih. Learning to reason for factuality.arXiv preprint arXiv:2508.05618, 2025
arXiv 2025
-
[8]
Jie Cheng, Gang Xiong, Ruixi Qiao, Lijun Li, Chao Guo, Junle Wang, Yisheng Lv, and Fei-Yue Wang. Stop summation: Min-form credit assignment is all process reward model needs for reasoning.arXiv preprint arXiv:2504.15275, 2025
arXiv 2025
-
[9]
Decoding by contrasting layers improves factuality in large language models (dola).arXiv Preprint, pages 1–8, 2024
YS Chuang et al. Decoding by contrasting layers improves factuality in large language models (dola).arXiv Preprint, pages 1–8, 2024
2024
-
[10]
Large legal fictions: Profiling legal hallucinations in large language models.Journal of Legal Analysis, 16(1):64–93, 2024
Matthew Dahl, Varun Magesh, Mirac Suzgun, and Daniel E Ho. Large legal fictions: Profiling legal hallucinations in large language models.Journal of Legal Analysis, 16(1):64–93, 2024
2024
-
[11]
Retrieve only when it needs: Adaptive retrieval augmentation for hallucination mitigation in large language models
Hanxing Ding, Liang Pang, Zihao Wei, Huawei Shen, and Xueqi Cheng. Retrieve only when it needs: Adaptive retrieval augmentation for hallucination mitigation in large language models. arXiv e-prints, pages arXiv–2402, 2024
2024
-
[12]
Chengfeng Dou, Fan Yang, Fei Li, Jiyuan Jia, Qiang Ju, Shuai Wang, Tianpeng Li, Xiangrong Zeng, Yijie Zhou, Hongda Zhang, et al. Baichuan-m3: Modeling clinical inquiry for reliable medical decision-making.arXiv preprint arXiv:2602.06570, 2026
arXiv 2026
-
[13]
Tao He, Rongchuan Mu, Lizi Liao, Yixin Cao, Ming Liu, and Bing Qin. Good learners think their thinking: Generative prm makes large reasoning model more efficient math learner.arXiv preprint arXiv:2507.23317, 2025
arXiv 2025
-
[14]
Minda Hu, Bowei He, Yufei Wang, Liangyou Li, Chen Ma, and Irwin King. Mitigating large language model hallucination with faithful finetuning.arXiv preprint arXiv:2406.11267, 2024. 10
arXiv 2024
-
[15]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM computing surveys, 55(12):1–38, 2023
2023
-
[16]
Ai-generated news articles based on large language models
Kai Jiang, Qilai Zhang, Dongsheng Guo, Dengrong Huang, Sijia Zhang, Zizhong Wei, Fanggang Ning, and Rui Li. Ai-generated news articles based on large language models. InProceedings of the 2023 International Conference on Artificial Intelligence, Systems and Network Security, pages 82–87, 2023
2023
-
[17]
Haoqiang Kang and Xiao-Yang Liu. Deficiency of large language models in finance: An empirical examination of hallucination.arXiv preprint arXiv:2311.15548, 2023
arXiv 2023
-
[18]
Yubin Kim, Hyewon Jeong, Shan Chen, Shuyue Stella Li, Chanwoo Park, Mingyu Lu, Kumail Alhamoud, Jimin Mun, Cristina Grau, Minseok Jung, et al. Medical hallucinations in foundation models and their impact on healthcare.arXiv preprint arXiv:2503.05777, 2025
arXiv 2025
-
[19]
Know the unknown: An uncertainty-sensitive method for llm instruction tuning
Jiaqi Li, Yixuan Tang, and Yi Yang. Know the unknown: An uncertainty-sensitive method for llm instruction tuning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 2972–2989, 2025
2025
-
[20]
Knowledge-level consistency reinforcement learning: Dual-fact alignment for long-form factuality, 2026
Junliang Li, Yucheng Wang, Yan Chen, Yu Ran, Ruiqing Zhang, Jing Liu, Hua Wu, and Haifeng Wang. Knowledge-level consistency reinforcement learning: Dual-fact alignment for long-form factuality, 2026. URLhttps://openreview.net/forum?id=Q04RwdeN9z
2026
-
[21]
Reasoning models hallucinate more: Factuality-aware reinforcement learning for large reasoning models
Junyi Li and Hwee Tou Ng. Reasoning models hallucinate more: Factuality-aware reinforcement learning for large reasoning models. InThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2026. URLhttps://openreview.net/forum?id=Igq7Dyc3OL
2026
-
[22]
finllm-eval: Evaluation methods for the logical, factual, and data accuracy of large models in the financial domain.https://www.github.com/Tencent/finLLM-Eval, 2025
Lichang Liang, Shaohui Wu, Yunlong Zhang, Yeyang Tang, and Fanyang Lu. finllm-eval: Evaluation methods for the logical, factual, and data accuracy of large models in the financial domain.https://www.github.com/Tencent/finLLM-Eval, 2025
2025
-
[23]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
2023
-
[24]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
Pith/arXiv arXiv 2025
-
[25]
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100, 2023
2023
-
[26]
Sagnik Mukherjee, Lifan Yuan, Dilek Hakkani-Tur, and Hao Peng. Reinforcement learning finetunes small subnetworks in large language models.arXiv preprint arXiv:2505.11711, 2025
arXiv 2025
-
[27]
Entity-level factual consistency of abstractive text summarization
Feng Nan, Ramesh Nallapati, Zhiguo Wang, Cicero Nogueira dos Santos, Henghui Zhu, Dejiao Zhang, Kathleen McKeown, and Bing Xiang. Entity-level factual consistency of abstractive text summarization. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 2727–2733, 2021
2021
-
[28]
Ragtruth: A hallucination corpus for developing trustworthy retrieval- augmented language models
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, KaShun Shum, Randy Zhong, Juntong Song, and Tong Zhang. Ragtruth: A hallucination corpus for developing trustworthy retrieval- augmented language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10862–10878, 2024
2024
-
[29]
Understanding factuality in abstractive summarization with FRANK: A benchmark for factuality metrics
Artidoro Pagnoni, Vidhisha Balachandran, and Yulia Tsvetkov. Understanding factuality in abstractive summarization with FRANK: A benchmark for factuality metrics. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4812–4829, 2021. 11
2021
-
[30]
Baochang Ren, Shuofei Qiao, Da Zheng, Huajun Chen, and Ningyu Zhang. Knowrl: Exploring knowledgeable reinforcement learning for factuality.arXiv preprint arXiv:2506.19807, 2025
Pith/arXiv arXiv 2025
-
[31]
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. A systematic survey of prompt engineering in large language models: Techniques and applications.arXiv preprint arXiv:2402.07927, 1, 2024
Pith/arXiv arXiv 2024
-
[32]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[33]
Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
Pith/arXiv arXiv 2024
-
[34]
Anikait Singh, Sheryl Hsu, Kyle Hsu, Eric Mitchell, Stefano Ermon, Tatsunori Hashimoto, Archit Sharma, and Chelsea Finn. Fspo: Few-shot optimization of synthetic preferences personalizes to real users.arXiv preprint arXiv:2502.19312, 2025
Pith/arXiv arXiv 2025
-
[35]
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592, 2025
Pith/arXiv arXiv 2025
-
[36]
Wei Sun, Wen Yang, Pu Jian, Qianlong Du, Fuwei Cui, Shuo Ren, and Jiajun Zhang. Ktae: A model-free algorithm to key-tokens advantage estimation in mathematical reasoning.arXiv preprint arXiv:2505.16826, 2025
arXiv 2025
-
[37]
Mechanistic detection and mitigation of hallucination in large reasoning models
Zhongxiang Sun, Qipeng Wang, Haoyu Wang, Xiao Zhang, and Jun Xu. Mechanistic detection and mitigation of hallucination in large reasoning models. InThe Fourteenth International Conference on Learning Representations
-
[38]
Benchmarking llm faithfulness in rag with evolving leaderboards
Manveer Singh Tamber, Forrest Bao, Chenyu Xu, Ge Luo, Suleman Kazi, Minseok Bae, Miaoran Li, Ofer Mendelevitch, Renyi Qu, and Jimmy Lin. Benchmarking llm faithfulness in rag with evolving leaderboards. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 799–811, 2025
2025
-
[39]
Hongze Tan, Zihan Wang, Jianfei Pan, Jinghao Lin, Hao Wang, Yifan Wu, Tao Chen, Zhihang Zheng, Zhihao Tang, and Haihua Yang. Gtpo and grpo-s: Token and sequence-level reward shaping with policy entropy.arXiv preprint arXiv:2508.04349, 2025
arXiv 2025
-
[40]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
Pith/arXiv arXiv 2022
-
[41]
On-policy self-alignment with fine-grained knowledge feedback for hallucination mitigation
Xueru Wen, Jie Lou, Xinyu Lu, Yuqiu Ji, Xinyan Guan, Yaojie Lu, Hongyu Lin, Ben He, Xianpei Han, Debing Zhang, et al. On-policy self-alignment with fine-grained knowledge feedback for hallucination mitigation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 5215–5231, 2025
2025
-
[42]
Guofu Xie, Yunsheng Shi, Hongtao Tian, Ting Yao, and Xiao Zhang. Capo: Towards enhancing llm reasoning through generative credit assignment.arXiv preprint arXiv:2508.02298, 2025
arXiv 2025
-
[43]
Guangzhi Xiong, Eric Xie, Corey Williams, Myles Kim, Amir Hassan Shariatmadari, Sikun Guo, Stefan Bekiranov, and Aidong Zhang. Toward reliable scientific hypothesis generation: Evaluat- ing truthfulness and hallucination in large language models.arXiv preprint arXiv:2505.14599, 2025
arXiv 2025
-
[44]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[45]
Taoye Yin, Haoyuan Hu, Yaxin Fan, Xinhao Chen, Xinya Wu, Kai Deng, Kezun Zhang, and Feng Wang. Mitigating hallucination in financial retrieval-augmented generation via fine-grained knowledge verification.arXiv preprint arXiv:2602.05723, 2026. 12
arXiv 2026
-
[46]
Tlcr: Token-level continuous reward for fine-grained reinforcement learning from human feedback
Eunseop Yoon, Hee Suk Yoon, SooHwan Eom, Gunsoo Han, Daniel Nam, Daejin Jo, Kyoung- Woon On, Mark Hasegawa-Johnson, Sungwoong Kim, and Chang Yoo. Tlcr: Token-level continuous reward for fine-grained reinforcement learning from human feedback. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14969–14981, 2024
2024
-
[47]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
Pith/arXiv arXiv 2025
-
[48]
Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges
Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin. Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13643–13658, 2024
2024
-
[49]
Yuxin Zhang, Meihao Fan, Ju Fan, Mingyang Yi, Yuyu Luo, Jian Tan, and Guoliang Li. Reward- sql: Boosting text-to-sql via stepwise reasoning and process-supervised rewards.arXiv preprint arXiv:2505.04671, 2025
arXiv 2025
-
[50]
Enhancing zero-shot chain-of-thought reasoning in large language models through logic
Xufeng Zhao, Mengdi Li, Wenhao Lu, Cornelius Weber, Jae-Hee Lee, Kun Chu, and Stefan Wermter. Enhancing zero-shot chain-of-thought reasoning in large language models through logic. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 6144–6166, 2024
2024
-
[51]
TX t=1 Abal t ∇θ logπ θ(yt|x, y<t) # =E y∼πθ
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36:55006–55021, 2023. 13 A Related Work A.1 Hallucination In LLMs, hallucinations refer to syntactically fluent outputs that contain factual errors ...
2023
-
[52]
Response Text
**Extraction:** Extract all informational sentences from the "Response Text." - Extracted sentences typically contain specific data pointssuch as figures ( dates, times, and various other numerical values), entities (people, places, venues, etc.), and logical relationships (e.g., whether a cause-and-effect link holds true)
-
[53]
Reference Materials
**Localization:** Locate the corresponding paragraphs within the "Reference Materials."
-
[54]
**Comparison:** Compare the statements made in the response against the original wording found in the reference materials
-
[55]
**Verdict:** - **Correct:** The statement aligns perfectly with the content found in the reference materials. - **Incorrect:** A corresponding statement exists in the reference materials, but the response’s phrasing does not match it; *or* the statement cannot be found within the specified reference materials (i.e., it is fabricated/ hallucinated). 19
-
[56]
erroneous segment
**Error Localization:** For every incorrect item, further pinpoint the specific "erroneous segment" (‘error_spans‘) within the "Response Text" itself, to facilitate subsequent token-level penalties. - For each incorrect item, you must identify the minimal erroneous segment within the [Response Text] and output it to the ‘error_spans‘ list. - Each entry in...
-
[57]
**Precise Numerical Replacement (Primary Choice)**: Modify only the incorrect number (e.g., ‘17.96%‘ ‘12.08%‘)
-
[58]
**Precise Entity Replacement (Secondary Choice)**: If changing only the number results in a semantic contradiction (e.g., a subject mismatch), make minor adjustments to the local subject entity name or qualifier (e.g., ‘Bond D‘ ‘ Bond A‘)
-
[59]
**Local Refinement (Tertiary Choice)**: If simply replacing the number or entity leads to grammatical errors, semantic incoherence, or logical conflicts within the context, you are permitted to make minor additions, deletions, or stylistic tweaks to the specific sentenceor its immediate contextto ensure it reads smoothly
-
[60]
hallucination
**Full Sentence Deletion (Last Resort)**: If the erroneous information is a complete fabrication (a "hallucination") that cannot be factually corrected through simple editsor if correcting it would cause the logic of the entire paragraph to collapsedirectly delete the entire sentence containing the error . ## Step 3: Formatting Requirements - Preserve the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.