VEPHand: View-Efficient Photometric Hand Performance Capture at Scale
Pith reviewed 2026-06-27 03:48 UTC · model grok-4.3
The pith
A mask-free neural pipeline with physics-inspired registration reconstructs detailed hand geometry and appearance from roughly 20 unmasked views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an end-to-end pipeline using scene parameterization and scenario-specific density regularization for mask-free extraction, together with a physics-inspired framework that optimizes intrinsic volumetric offsets inside a canonical tetrahedral mesh along with pose parameters, produces accurate hand geometry, plausible deformations, and robust registration under severe articulation and self-contact when input consists of only about 20 unmasked views.
What carries the argument
Scene parameterization with scenario-specific density regularization for reconstruction, combined with optimization of intrinsic volumetric offsets within a personalized hand model's canonical tetrahedral mesh for registration.
If this is right
- The method handles single hands, two-hand interactions, and hand-object manipulations within the same automated pipeline.
- It produces state-of-the-art reconstruction fidelity specifically in view-efficient and unmasked settings.
- Registration remains accurate and deformation capture remains fine-grained even when input noise is present.
- The pipeline scales to more than 12,000 sequences, enabling creation of a large-scale synthetic 2D/3D hand dataset for downstream training.
Where Pith is reading between the lines
- The tetrahedral-mesh offset representation may allow direct coupling to existing physics simulators for further animation refinement.
- The mask-free property could reduce preprocessing time in existing multi-view studios that currently rely on chroma-key or segmentation.
- Deriving a large synthetic dataset from the captured sequences suggests the method could bootstrap improved learning-based hand trackers without manual annotation.
- Lowering the required view count from dozens to roughly twenty may make high-fidelity capture accessible to smaller labs or consumer-grade camera arrays.
Load-bearing premise
Scenario-specific density regularization together with optimization of volumetric offsets inside a canonical tetrahedral mesh will separate hand surfaces from background clutter and yield accurate, plausible geometry from limited-view unmasked images.
What would settle it
A quantitative comparison on sequences with independent ground-truth 3D scans that shows surface-to-surface errors exceeding typical mesh resolution or visible interpenetration artifacts during documented self-contact frames would falsify the robustness claim.
Figures


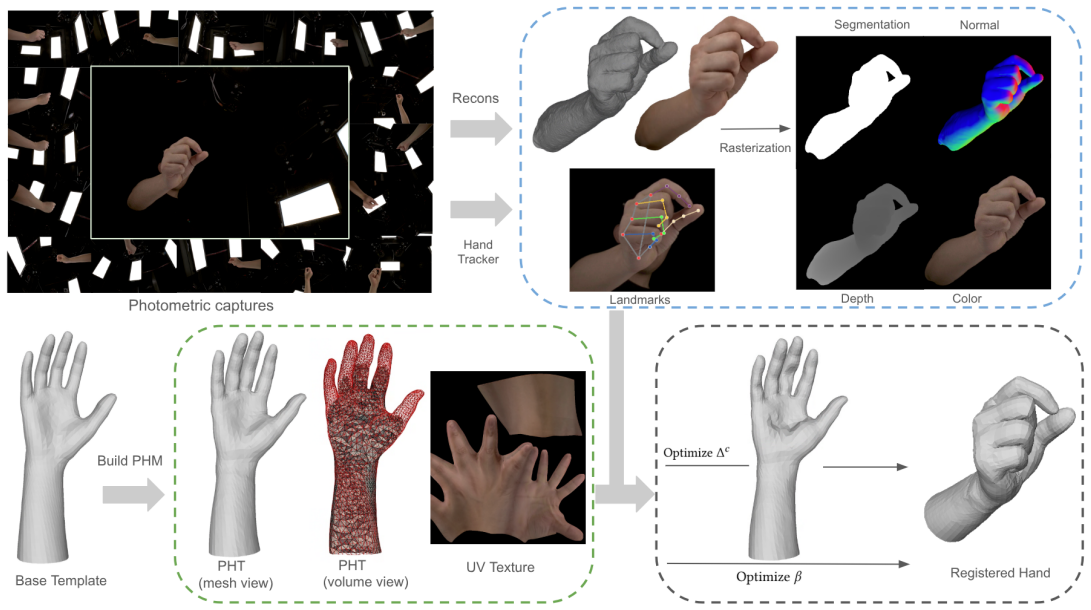
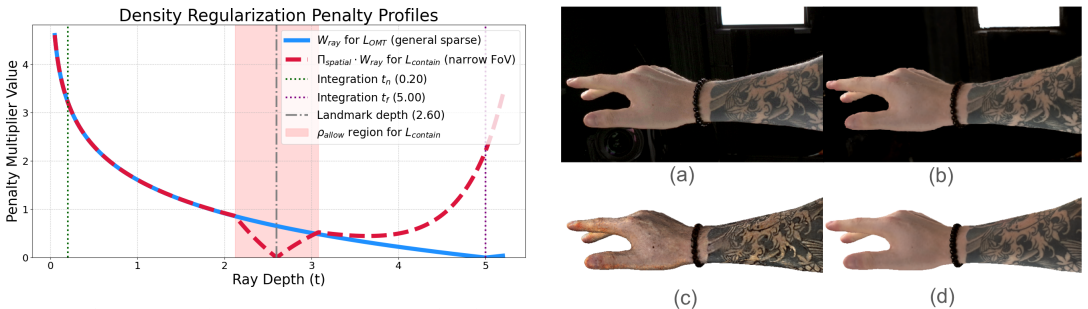

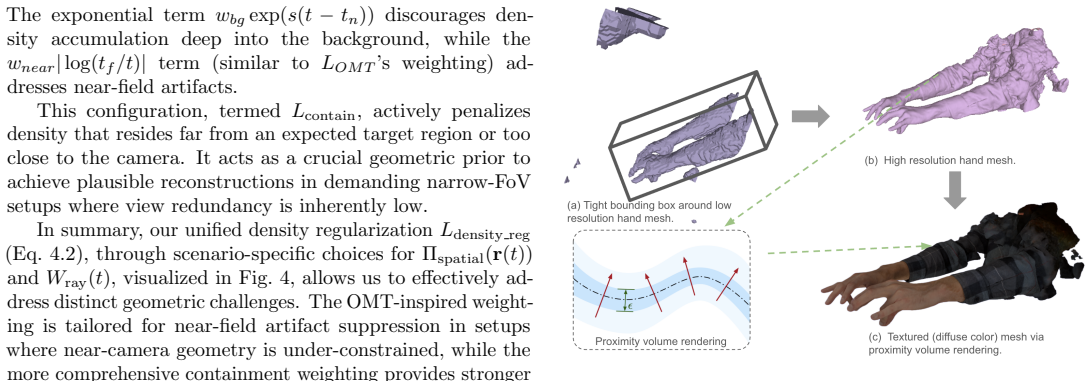










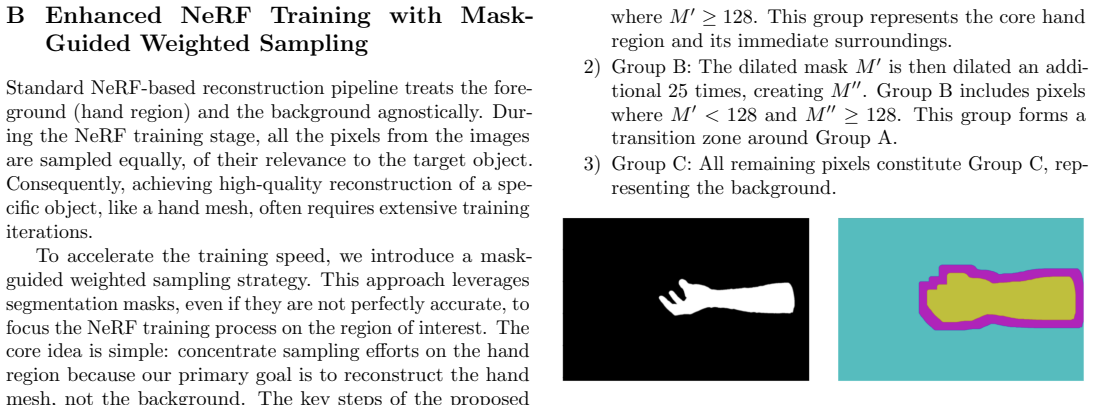
read the original abstract
Robust, high-fidelity 3D hand capture, while fundamental to digital human creation, remains challenging with practical multi-view systems that balance rich photometry with the geometric ambiguities of reconstruction arising from limited viewpoint density. This paper presents an end-to-end pipeline for dynamic hand performance capture and registration, specifically designed for view-efficient setups ($\sim$20 views). We address key challenges with two primary innovations. First, to overcome reconstruction difficulties like limited view overlap and background clutter, our mask-free neural method robustly extracts detailed hand geometry and appearance from unmasked images using scene parameterization and scenario-specific density regularization. Second, addressing registration challenges such as accurately capturing non-linear skin deformations and ensuring plausible results during severe self-contact, we propose a physics-inspired framework. It aligns reconstructions to a personalized hand model by optimizing intrinsic volumetric offsets within its canonical tetrahedral mesh, alongside pose parameters. This approach, supported by robust losses and optimization, captures fine surface deformations, ensures plausible results under severe articulation and self-contact, and demonstrates strong tolerance to input noise. We demonstrate the scalability and robustness of our automated pipeline on an extensive dataset of over 12,000 sequences, from which we also derive a large-scale, high-quality synthetic 2D/3D hand dataset for training downstream tasks. This showcases its effectiveness for single hands, intricate two-hand interactions, and natural hand-object manipulations. Our method achieves state-of-the-art reconstruction fidelity in view-efficient, unmasked scenarios and highly accurate registration. Our project page are available at https://vephand.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents VEPHand, an end-to-end pipeline for dynamic hand performance capture and registration from ~20-view setups. It introduces a mask-free neural method that uses scene parameterization and scenario-specific density regularization to extract detailed hand geometry and appearance from unmasked images, addressing limited view overlap and background clutter. A second contribution is a physics-inspired registration framework that aligns reconstructions to a personalized hand model by optimizing intrinsic volumetric offsets inside a canonical tetrahedral mesh together with pose parameters; this is supported by robust losses to capture fine surface deformations under severe articulation and self-contact. The pipeline is demonstrated on an extensive dataset of over 12,000 sequences, from which a large-scale synthetic 2D/3D hand dataset is derived, with claims of state-of-the-art reconstruction fidelity in view-efficient unmasked scenarios and highly accurate registration for single hands, two-hand interactions, and hand-object manipulations.
Significance. If the empirical claims hold, the work would advance practical photometric hand capture by enabling high-fidelity results with far fewer views than typical multi-view systems and without masks. The combination of density regularization for mask-free extraction and physics-inspired volumetric offsets for plausible deformation handling under self-contact addresses load-bearing practical challenges. The scale of the 12,000-sequence dataset and the derived synthetic benchmark constitute a concrete resource for downstream tasks. These elements together could support more accessible digital human pipelines.
major comments (2)
- [Abstract] Abstract: the claim of 'state-of-the-art reconstruction fidelity' and 'highly accurate registration' is asserted without any quantitative error metrics, baseline comparisons, or ablation results visible in the provided text; the central SOTA assertion therefore lacks the supporting evidence required to evaluate it.
- [Abstract] The assumption that scenario-specific density regularization plus optimization of intrinsic volumetric offsets will avoid artifacts from background clutter or self-contact is load-bearing for the mask-free and registration claims, yet no concrete test (e.g., failure-case analysis or quantitative comparison against masked baselines) is referenced.
minor comments (1)
- [Abstract] Abstract: 'Our project page are available' contains a subject-verb agreement error and should read 'is available'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract would benefit from explicit quantitative support for the stated claims and will revise it to reference key metrics and experiments from the manuscript body. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'state-of-the-art reconstruction fidelity' and 'highly accurate registration' is asserted without any quantitative error metrics, baseline comparisons, or ablation results visible in the provided text; the central SOTA assertion therefore lacks the supporting evidence required to evaluate it.
Authors: We agree that the abstract, as written, does not contain quantitative metrics or explicit references to baselines and ablations. The manuscript body contains these evaluations. We will revise the abstract to incorporate representative quantitative error metrics, note the baselines compared, and reference the ablation studies, thereby grounding the SOTA claims with evidence directly in the abstract. revision: yes
-
Referee: [Abstract] The assumption that scenario-specific density regularization plus optimization of intrinsic volumetric offsets will avoid artifacts from background clutter or self-contact is load-bearing for the mask-free and registration claims, yet no concrete test (e.g., failure-case analysis or quantitative comparison against masked baselines) is referenced.
Authors: The manuscript presents experiments that test robustness to background clutter and self-contact via both qualitative results and quantitative metrics, including comparisons that support the mask-free approach. We will revise the abstract to reference these specific experiments and results. We can also add a concise pointer to failure-case analysis if space permits in the revised abstract. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and provided text describe a pipeline with two main innovations: mask-free neural extraction via scene parameterization and scenario-specific density regularization, plus a physics-inspired registration framework optimizing volumetric offsets in a canonical tetrahedral mesh. No equations, parameter-fitting procedures, self-citations, or derivation steps are shown that would reduce any claimed result or prediction to the inputs by construction. The method is presented as directly addressing reconstruction and registration challenges without self-definitional loops, fitted inputs called predictions, or load-bearing self-citations. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
intrinsic volumetric offsets
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Pushing the envelope for rgb-based dense 3d hand pose estimation via neural rendering
Seungryul Baek, Kwang In Kim, and Tae-Kyun Kim. Pushing the envelope for rgb-based dense 3d hand pose estimation via neural rendering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1067–1076, 2019
2019
-
[2]
Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields
Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. InProceedings of the IEEE/CVF international conference on computer vision, pages 5855–5864, 2021
2021
-
[3]
Mip-nerf 360: Unbounded anti-aliased neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5470–5479, 2022
2022
-
[4]
Method for registration of 3-d shapes
Paul J Besl and Neil D McKay. Method for registration of 3-d shapes. InSensor fusion IV: control paradigms and data structures, volume 1611, pages 586–606. Spie, 1992
1992
-
[5]
Faust: Dataset and evaluation for 3d mesh registration
Federica Bogo, Javier Romero, Matthew Loper, and Michael J Black. Faust: Dataset and evaluation for 3d mesh registration. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3794– 3801, 2014
2014
-
[6]
Instant multi-view head capture through learnable registration
Timo Bolkart, Tianye Li, and Michael J Black. Instant multi-view head capture through learnable registration. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 768–779, 2023
2023
-
[7]
Cambridge university press, 1997
Javier Bonet and Richard D Wood.Nonlinear contin- uum mechanics for finite element analysis. Cambridge university press, 1997. 17
1997
-
[8]
3d hand shape and pose from images in the wild
Adnane Boukhayma, Rodrigo de Bem, and Philip HS Torr. 3d hand shape and pose from images in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10843–10852, 2019
2019
-
[9]
Mvhm: A large-scale multi-view hand mesh benchmark for accurate 3d hand pose estimation
Liangjian Chen, Shih-Yao Lin, Yusheng Xie, Yen-Yu Lin, and Xiaohui Xie. Mvhm: A large-scale multi-view hand mesh benchmark for accurate 3d hand pose estimation. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 836–845, 2021
2021
-
[10]
Dense hand-object (ho) graspnet with full grasping taxonomy and dynamics
Woojin Cho, Jihyun Lee, Minjae Yi, Minje Kim, Taeyun Woo, Donghwan Kim, Taewook Ha, Hyokeun Lee, Je- Hwan Ryu, Woontack Woo, et al. Dense hand-object (ho) graspnet with full grasping taxonomy and dynamics. InEuropean Conference on Computer Vision, pages 284–
-
[11]
Differentiable surface rendering via non-differentiable sampling
Forrester Cole, Kyle Genova, Avneesh Sud, Daniel Vlasic, and Zhoutong Zhang. Differentiable surface rendering via non-differentiable sampling. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 6088–6097, 2021
2021
-
[12]
Yilan Dong, Haohe Liu, Qing Wang, Jiahao Yang, Wen- qing Wang, Gregory Slabaugh, and Shanxin Yuan. Hand- splat: Embedding-driven gaussian splatting for high- fidelity hand rendering.arXiv preprint arXiv:2503.14736, 2025
arXiv 2025
-
[13]
Re- constructing individual hand models from motion capture data.Journal of Computational Design and Engineering, 1(1):1–12, 2014
Yui Endo, Mitsunori Tada, and Masaaki Mochimaru. Re- constructing individual hand models from motion capture data.Journal of Computational Design and Engineering, 1(1):1–12, 2014
2014
-
[14]
Instantsplat: Sparse-view gaussian splatting in seconds.arXiv preprint arXiv:2403.20309, 2024
Zhiwen Fan, Wenyan Cong, Kairun Wen, Kevin Wang, Jian Zhang, Xinghao Ding, Danfei Xu, Boris Ivanovic, Marco Pavone, Georgios Pavlakos, et al. Instantsplat: Sparse-view gaussian splatting in seconds.arXiv preprint arXiv:2403.20309, 2024
arXiv 2024
-
[15]
Arctic: A dataset for dexterous biman- ual hand-object manipulation
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kaufmann, Michael J Black, and Ot- mar Hilliges. Arctic: A dataset for dexterous biman- ual hand-object manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 12943–12954, 2023
2023
-
[16]
Hold: Category-agnostic 3d reconstruc- tion of interacting hands and objects from video
Zicong Fan, Maria Parelli, Maria Eleni Kadoglou, Xu Chen, Muhammed Kocabas, Michael J Black, and Otmar Hilliges. Hold: Category-agnostic 3d reconstruc- tion of interacting hands and objects from video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 494–504, 2024
2024
-
[17]
Zicong Fan, Edoardo Remelli, David Dimond, Fadime Sener, Liuhao Ge, Bugra Tekin, Cem Keskin, and Shreyas Hampali. Palm: A dataset and baseline for learning multi- subject hand prior.arXiv preprint arXiv:2511.05403, 2025
arXiv 2025
-
[18]
Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Commu- nications of the ACM, 24(6):381–395, 1981
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Commu- nications of the ACM, 24(6):381–395, 1981
1981
-
[19]
Plenoxels: Radiance fields without neural networks
Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5501–5510, 2022
2022
-
[20]
K- planes: Explicit radiance fields in space, time, and ap- pearance
Sara Fridovich-Keil, Giacomo Meanti, Frederik Rahbæk Warburg, Benjamin Recht, and Angjoo Kanazawa. K- planes: Explicit radiance fields in space, time, and ap- pearance. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 12479–12488, 2023
2023
-
[21]
Gigahands: A massive annotated dataset of bimanual hand activities
Rao Fu, Dingxi Zhang, Alex Jiang, Wanjia Fu, Austin Funk, Daniel Ritchie, and Srinath Sridhar. Gigahands: A massive annotated dataset of bimanual hand activities. arXiv preprint arXiv:2412.04244, 2024
arXiv 2024
-
[22]
Matcha gaussians: Atlas of charts for high-quality geometry and photorealism from sparse views
Antoine Gu´ edon, Tomoki Ichikawa, Kohei Yamashita, and Ko Nishino. Matcha gaussians: Atlas of charts for high-quality geometry and photorealism from sparse views. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6001–6011, 2025
2025
-
[23]
Honnotate: A method for 3d annota- tion of hand and object poses
Shreyas Hampali, Mahdi Rad, Markus Oberweger, and Vincent Lepetit. Honnotate: A method for 3d annota- tion of hand and object poses. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3196–3206, 2020
2020
-
[24]
Tetgen, a delaunay-based quality tetrahedral mesh generator.ACM Trans
Si Hang. Tetgen, a delaunay-based quality tetrahedral mesh generator.ACM Trans. Math. Softw, 41(2):11, 2015
2015
-
[25]
2d gaussian splatting for geometri- cally accurate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometri- cally accurate radiance fields. InACM SIGGRAPH 2024 conference papers, pages 1–11, 2024
2024
-
[26]
Re- constructing hand-held objects from monocular video
Di Huang, Xiaopeng Ji, Xingyi He, Jiaming Sun, Tong He, Qing Shuai, Wanli Ouyang, and Xiaowei Zhou. Re- constructing hand-held objects from monocular video. InSIGGRAPH Asia 2022 Conference Papers, pages 1–9, 2022
2022
-
[27]
Phrit: Parametric hand representation with implicit template
Zhisheng Huang, Yujin Chen, Di Kang, Jinlu Zhang, and Zhigang Tu. Phrit: Parametric hand representation with implicit template. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14974–14984, 2023. 18
2023
-
[28]
Grasp in gaussians: Fast monocular recon- struction of dynamic hand-object interactions.arXiv e-prints, pages arXiv–2604, 2026
Ayce Idil Aytekin, Xu Chen, Zhengyang Shen, Thabo Beeler, Helge Rhodin, Rishabh Dabral, and Christian Theobalt. Grasp in gaussians: Fast monocular recon- struction of dynamic hand-object interactions.arXiv e-prints, pages arXiv–2604, 2026
2026
-
[29]
Panoptic studio: A massively multiview system for social motion capture
Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh. Panoptic studio: A massively multiview system for social motion capture. InProceedings of the IEEE international conference on computer vision, pages 3334–3342, 2015
2015
-
[30]
Total capture: A 3d deformation model for tracking faces, hands, and bodies
Hanbyul Joo, Tomas Simon, and Yaser Sheikh. Total capture: A 3d deformation model for tracking faces, hands, and bodies. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8320– 8329, 2018
2018
-
[31]
Harp: Personalized hand recon- struction from a monocular rgb video
Korrawe Karunratanakul, Sergey Prokudin, Otmar Hilliges, and Siyu Tang. Harp: Personalized hand recon- struction from a monocular rgb video. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12802–12813, 2023
2023
-
[32]
3d gaussian splatting for real- time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk¨ uhler, and George Drettakis. 3d gaussian splatting for real- time radiance field rendering.ACM Trans. Graph., 42 (4):139–1, 2023
2023
-
[33]
Interacting attention graph for single image two-hand reconstruction
Mengcheng Li, Liang An, Hongwen Zhang, Lianpeng Wu, Feng Chen, Tao Yu, and Yebin Liu. Interacting attention graph for single image two-hand reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2761–2770, 2022
2022
-
[34]
Nimble: a non-rigid hand model with bones and muscles.ACM Transactions on Graphics (TOG), 41(4): 1–16, 2022
Yuwei Li, Longwen Zhang, Zesong Qiu, Yingwenqi Jiang, Nianyi Li, Yuexin Ma, Yuyao Zhang, Lan Xu, and Jingyi Yu. Nimble: a non-rigid hand model with bones and muscles.ACM Transactions on Graphics (TOG), 41(4): 1–16, 2022
2022
-
[35]
Neuralangelo: High-fidelity neural surface recon- struction
Zhaoshuo Li, Thomas M¨ uller, Alex Evans, Russell H Tay- lor, Mathias Unberath, Ming-Yu Liu, and Chen-Hsuan Lin. Neuralangelo: High-fidelity neural surface recon- struction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8456– 8465, 2023
2023
-
[36]
End-to-end human pose and mesh reconstruction with transformers
Kevin Lin, Lijuan Wang, and Zicheng Liu. End-to-end human pose and mesh reconstruction with transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1954–1963, 2021
1954
-
[37]
Taco: Benchmarking generalizable bimanual tool-action-object understand- ing
Yun Liu, Haolin Yang, Xu Si, Ling Liu, Zipeng Li, Yuxi- ang Zhang, Yebin Liu, and Li Yi. Taco: Benchmarking generalizable bimanual tool-action-object understand- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21740– 21751, 2024
2024
-
[38]
Hoi4d: A 4d egocentric dataset for category- level human-object interaction
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. Hoi4d: A 4d egocentric dataset for category- level human-object interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21013–21022, 2022
2022
-
[39]
Stephen Lombardi, Tomas Simon, Jason Saragih, Gabriel Schwartz, Andreas Lehrmann, and Yaser Sheikh. Neural volumes: Learning dynamic renderable volumes from images.arXiv preprint arXiv:1906.07751, 2019
arXiv 1906
-
[40]
Marching cubes: A high resolution 3d surface construction algorithm
William E Lorensen and Harvey E Cline. Marching cubes: A high resolution 3d surface construction algorithm. In Seminal graphics: pioneering efforts that shaped the field, pages 347–353. 1998
1998
-
[41]
Mediapipe: A framework for building perception pipelines.arXiv preprint arXiv:1906.08172, 2019
Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris McClanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo-Ling Chang, Ming Guang Yong, Juhyun Lee, et al. Mediapipe: A framework for building perception pipelines.arXiv preprint arXiv:1906.08172, 2019
Pith/arXiv arXiv 1906
-
[42]
3d interacting hand pose estimation by hand de-occlusion and removal
Hao Meng, Sheng Jin, Wentao Liu, Chen Qian, Mengxi- ang Lin, Wanli Ouyang, and Ping Luo. 3d interacting hand pose estimation by hand de-occlusion and removal. InEuropean Conference on Computer Vision, pages 380–
-
[43]
Discrete differential-geometry operators for triangulated 2-manifolds
Mark Meyer, Mathieu Desbrun, Peter Schr¨ oder, and Alan H Barr. Discrete differential-geometry operators for triangulated 2-manifolds. InVisualization and math- ematics III, pages 35–57. Springer, 2003
2003
-
[44]
Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1): 99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1): 99–106, 2021
2021
-
[45]
Deephandmesh: A weakly-supervised deep encoder- decoder framework for high-fidelity hand mesh modeling
Gyeongsik Moon, Takaaki Shiratori, and Kyoung Mu Lee. Deephandmesh: A weakly-supervised deep encoder- decoder framework for high-fidelity hand mesh modeling. InEuropean Conference on Computer Vision, pages 440–
-
[46]
Interhand2
Gyeongsik Moon, Shoou-I Yu, He Wen, Takaaki Shiratori, and Kyoung Mu Lee. Interhand2. 6m: A dataset and baseline for 3d interacting hand pose estimation from a single rgb image. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XX 16, pages 548–564. Springer, 2020
2020
-
[47]
Authentic hand avatar from a phone scan via universal hand model
Gyeongsik Moon, Weipeng Xu, Rohan Joshi, Chenglei Wu, and Takaaki Shiratori. Authentic hand avatar from a phone scan via universal hand model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2029–2038, 2024. 19
2029
-
[48]
Real-time hand tracking under occlusion from an egocentric rgb-d sensor
Franziska Mueller, Dushyant Mehta, Oleksandr Sot- nychenko, Srinath Sridhar, Dan Casas, and Christian Theobalt. Real-time hand tracking under occlusion from an egocentric rgb-d sensor. InProceedings of the IEEE international conference on computer vision, pages 1154– 1163, 2017
2017
-
[49]
Instant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022
Thomas M¨ uller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022
2022
-
[50]
Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction
Michael Oechsle, Songyou Peng, and Andreas Geiger. Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction. InProceedings of the IEEE/CVF international conference on computer vision, pages 5589–5599, 2021
2021
-
[51]
Sparse multi-view hand-object reconstruction for unseen environments
Yik Lung Pang, Changjae Oh, and Andrea Cavallaro. Sparse multi-view hand-object reconstruction for unseen environments. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 803–810, 2024
2024
-
[52]
Nerfies: Deformable neural radiance fields
Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Steven M Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 5865–5874, 2021
2021
-
[53]
Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin-Brualla, and Steven M Seitz. Hypern- erf: A higher-dimensional representation for topolog- ically varying neural radiance fields.arXiv preprint arXiv:2106.13228, 2021
arXiv 2021
-
[54]
Aarya Patel, Hamid Laga, and Ojaswa Sharma. Normal- guided detail-preserving neural implicit functions for high-fidelity 3d surface reconstruction.arXiv preprint arXiv:2406.04861, 2024
arXiv 2024
-
[55]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019
2019
-
[56]
Reconstructing hands in 3d with transformers
Georgios Pavlakos, Dandan Shan, Ilija Radosavovic, Angjoo Kanazawa, David Fouhey, and Jitendra Malik. Reconstructing hands in 3d with transformers. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9826–9836, 2024
2024
-
[57]
Manus: Markerless grasp capture using ar- ticulated 3d gaussians
Chandradeep Pokhariya, Ishaan Nikhil Shah, Angela Xing, Zekun Li, Kefan Chen, Avinash Sharma, and Sri- nath Sridhar. Manus: Markerless grasp capture using ar- ticulated 3d gaussians. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2197–2208, 2024
2024
-
[58]
Handy: Towards a high fidelity 3d hand shape and appearance model
Rolandos Alexandros Potamias, Stylianos Ploumpis, Stylianos Moschoglou, Vasileios Triantafyllou, and Ste- fanos Zafeiriou. Handy: Towards a high fidelity 3d hand shape and appearance model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4670–4680, 2023
2023
-
[59]
D-nerf: Neural radiance fields for dynamic scenes
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-nerf: Neural radiance fields for dynamic scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10318–10327, 2021
2021
-
[60]
Realtime and robust hand tracking from depth
Chen Qian, Xiao Sun, Yichen Wei, Xiaoou Tang, and Jian Sun. Realtime and robust hand tracking from depth. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1106–1113, 2014
2014
-
[61]
Html: A parametric hand texture model for 3d hand reconstruction and personalization
Neng Qian, Jiayi Wang, Franziska Mueller, Florian Bernard, Vladislav Golyanik, and Christian Theobalt. Html: A parametric hand texture model for 3d hand reconstruction and personalization. InComputer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XI 16, pages 54–
2020
-
[62]
Di Qiu, Yinda Zhang, Thabo Beeler, Vladimir Tankovich, Christian H¨ ane, Sean Fanello, Christoph Rhemann, and Sergio Orts Escolano. Chosen: Contrastive hypothesis selection for multi-view depth refinement.arXiv preprint arXiv:2404.02225, 2024
arXiv 2024
-
[63]
Hogsa: Bimanual hand-object interaction understanding with 3d gaussian splatting based data augmentation
Wentian Qu, Jiahe Li, Jian Cheng, Jian Shi, Chenyu Meng, Cuixia Ma, Hongan Wang, Xiaoming Deng, and Yinda Zhang. Hogsa: Bimanual hand-object interaction understanding with 3d gaussian splatting based data augmentation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 6639–6647, 2025
2025
-
[64]
Show3d: Capturing scenes of 3d hands and objects in the wild.arXiv preprint arXiv:2603.28760, 2026
Patrick Rim, Kevin Harris, Braden Copple, Shangchen Han, Xu Xie, Ivan Shugurov, Sizhe An, He Wen, Alex Wong, Tomas Hodan, et al. Show3d: Capturing scenes of 3d hands and objects in the wild.arXiv preprint arXiv:2603.28760, 2026
arXiv 2026
-
[65]
Javier Romero, Dimitrios Tzionas, and Michael J Black. Embodied hands: Modeling and capturing hands and bodies together.arXiv preprint arXiv:2201.02610, 2022
arXiv 2022
-
[66]
Efficient variants of the icp algorithm
Szymon Rusinkiewicz and Marc Levoy. Efficient variants of the icp algorithm. InProceedings third international conference on 3-D digital imaging and modeling, pages 145–152. IEEE, 2001
2001
-
[67]
Structure-from-motion revisited
Johannes Lutz Sch¨ onberger and Jan-Michael Frahm. Structure-from-motion revisited. InConference on Com- puter Vision and Pattern Recognition (CVPR), 2016. 20
2016
-
[68]
Pixelwise view selection for unstructured multi-view stereo
Johannes Lutz Sch¨ onberger, Enliang Zheng, Marc Polle- feys, and Jan-Michael Frahm. Pixelwise view selection for unstructured multi-view stereo. InEuropean Conference on Computer Vision (ECCV), 2016
2016
-
[69]
Stable neo-hookean flesh simulation.ACM Transactions on Graphics (TOG), 37(2):1–15, 2018
Breannan Smith, Fernando De Goes, and Theodore Kim. Stable neo-hookean flesh simulation.ACM Transactions on Graphics (TOG), 37(2):1–15, 2018
2018
-
[70]
Constraining dense hand surface tracking with elasticity
Breannan Smith, Chenglei Wu, He Wen, Patrick Peluse, Yaser Sheikh, Jessica K Hodgins, and Takaaki Shiratori. Constraining dense hand surface tracking with elasticity. ACM Transactions on Graphics (ToG), 39(6):1–14, 2020
2020
-
[71]
As-rigid-as-possible sur- face modeling
Olga Sorkine and Marc Alexa. As-rigid-as-possible sur- face modeling. InSymposium on Geometry processing, volume 4, pages 109–116. Citeseer, 2007
2007
-
[72]
Real-time hand tracking using a sum of anisotropic gaussians model
Srinath Sridhar, Helge Rhodin, Hans-Peter Seidel, Antti Oulasvirta, and Christian Theobalt. Real-time hand tracking using a sum of anisotropic gaussians model. In2014 2nd International Conference on 3D Vision, volume 1, pages 319–326. IEEE, 2014
2014
-
[73]
Fast and robust hand tracking using detection-guided optimization
Srinath Sridhar, Franziska Mueller, Antti Oulasvirta, and Christian Theobalt. Fast and robust hand tracking using detection-guided optimization. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3221, 2015
2015
-
[74]
Depth-based hand pose estimation: methods, data, and challenges.International Journal of Computer Vision, 126:1180–1198, 2018
James Steven Supanˇ ciˇ c, Gregory Rogez, Yi Yang, Jamie Shotton, and Deva Ramanan. Depth-based hand pose estimation: methods, data, and challenges.International Journal of Computer Vision, 126:1180–1198, 2018
2018
-
[75]
Grab: A dataset of whole-body human grasping of objects
Omid Taheri, Nima Ghorbani, Michael J Black, and Dim- itrios Tzionas. Grab: A dataset of whole-body human grasping of objects. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IV 16, pages 581–600. Springer, 2020
2020
-
[76]
Sphere-meshes for real-time hand modeling and tracking
Anastasia Tkach, Mark Pauly, and Andrea Tagliasacchi. Sphere-meshes for real-time hand modeling and tracking. ACM Transactions on Graphics (ToG), 35(6):1–11, 2016
2016
-
[77]
Real-time continuous pose recovery of human hands using convolutional networks.ACM Transactions on Graphics (ToG), 33(5):1–10, 2014
Jonathan Tompson, Murphy Stein, Yann Lecun, and Ken Perlin. Real-time continuous pose recovery of human hands using convolutional networks.ACM Transactions on Graphics (ToG), 33(5):1–10, 2014
2014
-
[78]
Ref- nerf: Structured view-dependent appearance for neural radiance fields
Dor Verbin, Peter Hedman, Ben Mildenhall, Todd Zick- ler, Jonathan T Barron, and Pratul P Srinivasan. Ref- nerf: Structured view-dependent appearance for neural radiance fields. In2022 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 5481–5490. IEEE, 2022
2022
-
[79]
Unisdf: Unifying neural representations for high-fidelity 3d reconstruction of complex scenes with reflections.Advances in Neural Information Processing Systems, 37:3157–3184, 2024
Fangjinhua Wang, Marie-Julie Rakotosaona, Michael Niemeyer, Richard Szeliski, Marc Pollefeys, and Federico Tombari. Unisdf: Unifying neural representations for high-fidelity 3d reconstruction of complex scenes with reflections.Advances in Neural Information Processing Systems, 37:3157–3184, 2024
2024
-
[80]
Rgb2hands: real-time tracking of 3d hand interactions from monoc- ular rgb video.ACM Transactions on Graphics (ToG), 39(6):1–16, 2020
Jiayi Wang, Franziska Mueller, Florian Bernard, Suzanne Sorli, Oleksandr Sotnychenko, Neng Qian, Miguel A Otaduy, Dan Casas, and Christian Theobalt. Rgb2hands: real-time tracking of 3d hand interactions from monoc- ular rgb video.ACM Transactions on Graphics (ToG), 39(6):1–16, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.