SUP-MCRL: Subject-aware Unified Pseudo-feature Coded Multimodal Contrastive Representation Learning for EEG Visual Decoding
Pith reviewed 2026-06-27 03:04 UTC · model grok-4.3
The pith
Structured alignment supervision via semantic attention and pseudo-feature coding overcomes geometric-only limitations in EEG decoding of natural images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
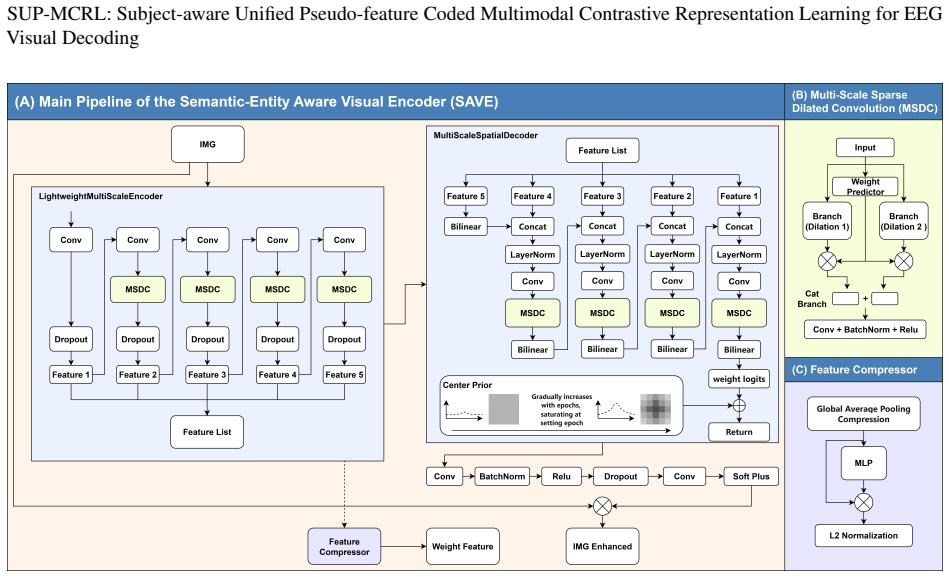
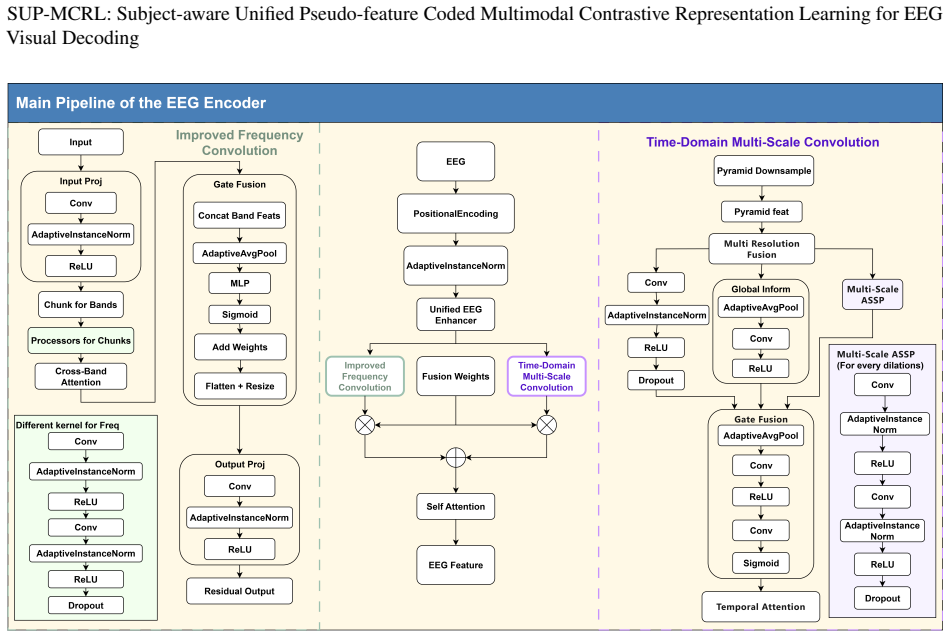
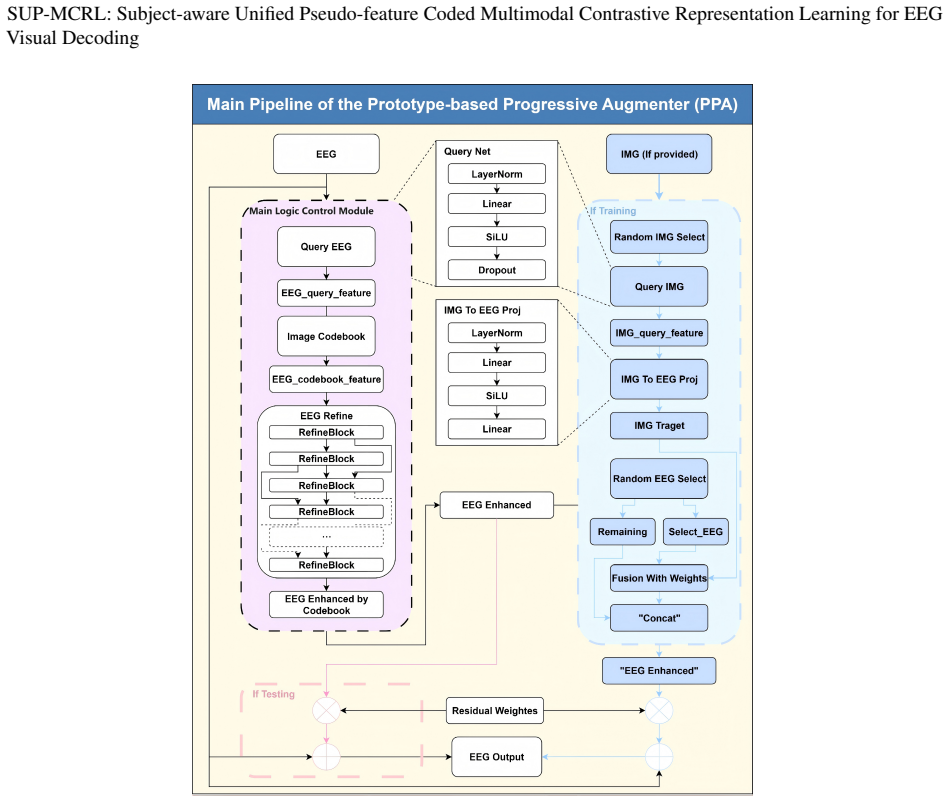
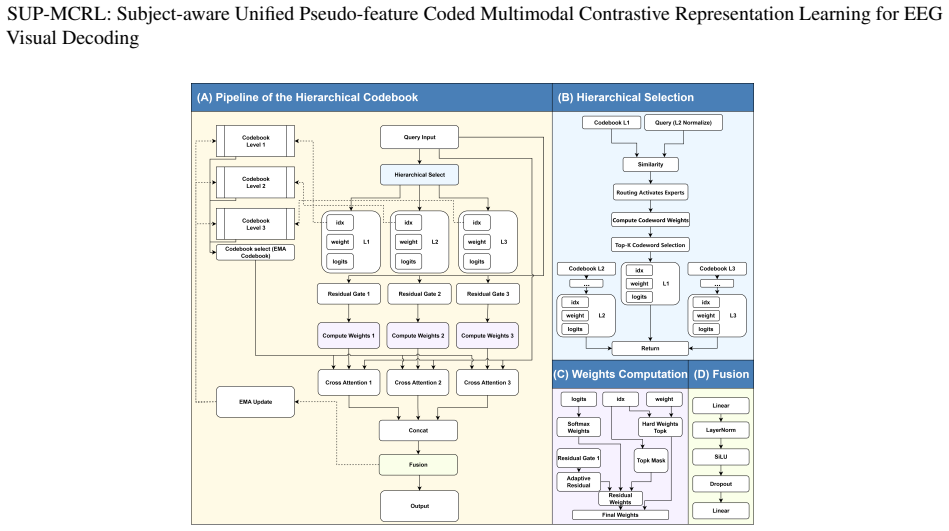
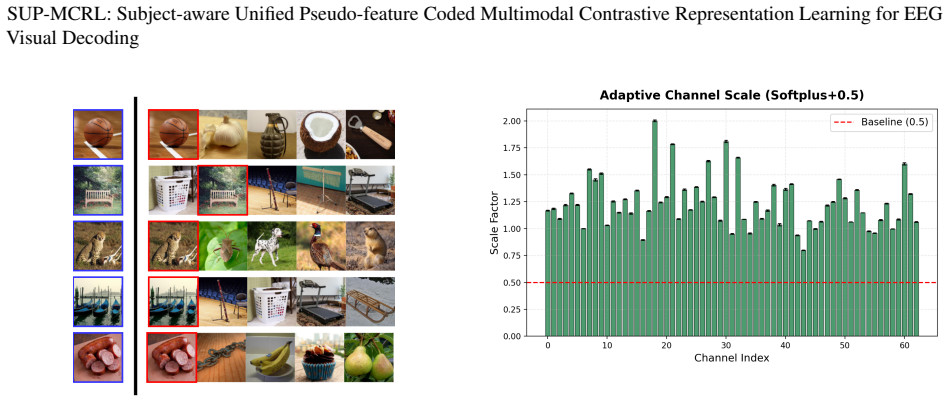
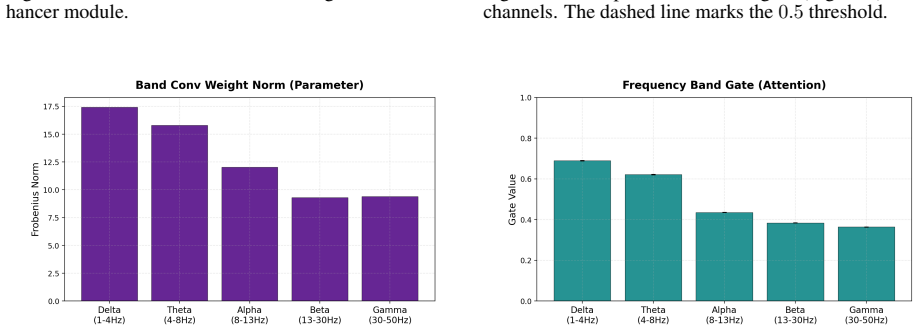
The paper claims that a unified multimodal contrastive framework called SUP-MCRL, built around a Semantic-entity Aware Visual Encoder that extracts semantic content via learned spatial attention, a Unified EEG Enhancer that applies multi-scale atrous convolutions and inter-band attention for cross-subject robustness, and a Prototype-based Progressive Augmenter that maintains an EMA-updated pseudo-feature pool, produces subject-aware representations that achieve markedly higher zero-shot accuracy on natural-image EEG decoding than models limited to geometric alignment.
What carries the argument
The three collaborative mechanisms SAVE, UEE, and PPA inside SUP-MCRL that together supply structured alignment supervision beyond pure geometric distance optimization.
If this is right
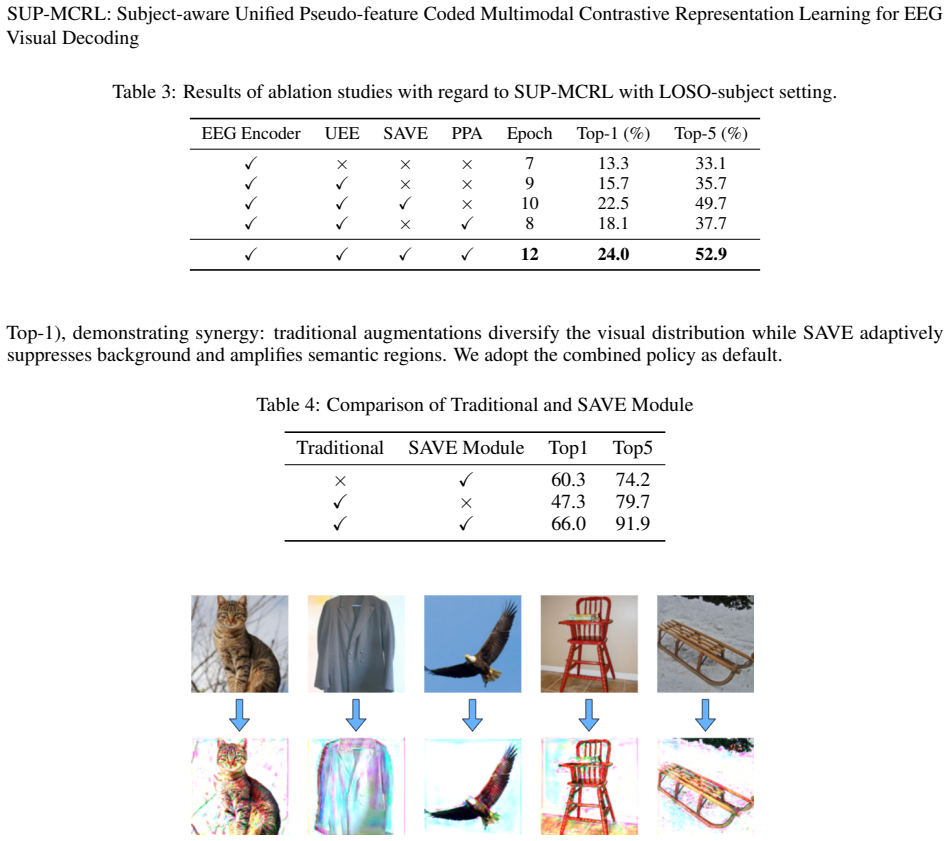
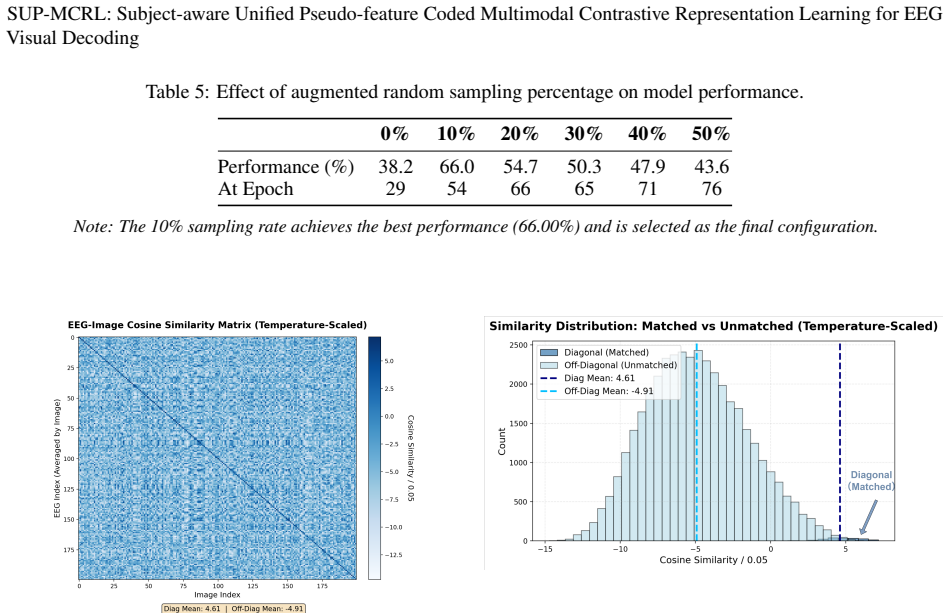
- The framework reaches 66.0 percent top-1 and 91.9 percent top-5 intra-subject accuracy on THINGS-EEG natural images.
- Leave-one-subject-out performance reaches 24.0 percent top-1 and 52.9 percent top-5, showing better cross-subject generalization.
- Accounting for semantic consistency and inter-subject variability reduces spurious zero-shot matches compared with geometric-only contrastive models.
- The same structured supervision approach yields consistent gains across both intra-subject and leave-one-subject-out protocols.
Where Pith is reading between the lines
- The pseudo-feature pool mechanism might stabilize contrastive training in other modalities where representation collapse is common.
- If the gains hold, the same attention and enhancement blocks could be tested on EEG decoding of non-visual stimuli.
- Online updating of the pseudo-feature pool suggests a possible path toward real-time adaptation in deployed brain-computer interfaces.
- The emphasis on subject-aware robustness points to value in combining this method with few-shot personalization techniques.
Load-bearing premise
The accuracy gains come chiefly from the three proposed mechanisms rather than from other details of training, data handling, or evaluation on the THINGS-EEG dataset.
What would settle it
A controlled re-run of a baseline multimodal contrastive model on identical THINGS-EEG splits and protocol, without SAVE, UEE, or PPA, that reaches comparable intra-subject and LOSO top-1 and top-5 accuracies.
Figures





read the original abstract
Non-invasive brain-computer interfaces exhibit significant performance degradation when moving from controlled laboratory stimuli to real-world natural images. This degradation occurs because conventional multimodal contrastive representation learning models focus exclusively on optimizing geometric distance alignment, thereby failing to account for semantic consistency and inter-subject variability in neural representation and selective attention. As a result, these models are prone to producing spurious zero-shot matches. To address these limitations, we propose SUP-MCRL, a unified framework integrating three collaborative mechanisms: (1) a Semantic-entity Aware Visual Encoder (SAVE) that learns spatial attention to extract semantic content without relying on pre-trained saliency models; (2) a Unified EEG Enhancer (UEE) that employs multi-scale atrous convolutions and inter-band attention for adaptive cross-subject robustness; and (3) a Prototype-based Progressive Augmenter (PPA) that maintains an EMA-updated pseudo-feature pool to prevent representation collapse. Zero-shot experiments on the THINGS-EEG achieve 66.0%/91.9% (Top-1/Top-5) intra-subject and 24.0%/52.9% LOSO accuracy, significantly surpassing state-of-the-art methods and demonstrating that structured alignment supervision is key to overcoming the limitations of cross-modal decoding. Code is available at https://github.com/NZWANG/SUP-MCRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SUP-MCRL, a multimodal contrastive representation learning framework for EEG-based visual decoding of natural images. It integrates three mechanisms—Semantic-entity Aware Visual Encoder (SAVE) for semantic spatial attention, Unified EEG Enhancer (UEE) using multi-scale atrous convolutions and inter-band attention, and Prototype-based Progressive Augmenter (PPA) with EMA-updated pseudo-feature pools—to address limitations in geometric alignment, semantic consistency, and inter-subject variability. Zero-shot experiments on THINGS-EEG report intra-subject accuracies of 66.0% Top-1 / 91.9% Top-5 and LOSO accuracies of 24.0% Top-1 / 52.9% Top-5, claiming these significantly surpass prior state-of-the-art methods due to the structured alignment supervision.
Significance. If the reported gains prove robustly attributable to SAVE, UEE, and PPA rather than implementation details, the work could meaningfully advance non-invasive BCI by improving cross-modal decoding for real-world stimuli. Public code release at the cited GitHub repository is a clear strength that aids reproducibility and allows independent verification of the central claims.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments: The central claim attributes the 66.0%/91.9% intra-subject and 24.0%/52.9% LOSO gains (and SOTA superiority) specifically to the three proposed mechanisms providing structured alignment supervision. No ablation studies isolating the contribution of SAVE, UEE, or PPA (e.g., variants with each component removed) are described, leaving open the possibility that gains arise from unstated factors such as optimizer choices, loss scaling, data augmentation, or subject-split details on THINGS-EEG.
- [Results] Results: The reported accuracy numbers are presented without error bars, standard deviations across multiple runs, or statistical significance tests against baselines. This undermines the load-bearing claim that the results 'significantly surpass state-of-the-art methods,' as it is impossible to assess whether observed differences exceed expected variability.
minor comments (1)
- [Abstract] The abstract states that code is available, which is helpful; the full manuscript should expand the methods section with complete training protocol, hyperparameter values, exact data splits, and evaluation details to support reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the manuscript. We address each major point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments: The central claim attributes the 66.0%/91.9% intra-subject and 24.0%/52.9% LOSO gains (and SOTA superiority) specifically to the three proposed mechanisms providing structured alignment supervision. No ablation studies isolating the contribution of SAVE, UEE, or PPA (e.g., variants with each component removed) are described, leaving open the possibility that gains arise from unstated factors such as optimizer choices, loss scaling, data augmentation, or subject-split details on THINGS-EEG.
Authors: We agree that ablation studies are required to isolate the contributions of SAVE, UEE, and PPA. The revised manuscript will add a dedicated ablation section with experiments that remove each component individually (and in combinations) while keeping all other implementation details fixed. Results will be reported on the same THINGS-EEG splits to quantify the performance drop attributable to each mechanism. revision: yes
-
Referee: [Results] Results: The reported accuracy numbers are presented without error bars, standard deviations across multiple runs, or statistical significance tests against baselines. This undermines the load-bearing claim that the results 'significantly surpass state-of-the-art methods,' as it is impossible to assess whether observed differences exceed expected variability.
Authors: We acknowledge that the absence of variability measures and statistical tests weakens the strength of the superiority claims. In the revision we will rerun all experiments across multiple random seeds, report mean accuracies with standard deviations and error bars, and include statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values) against the reproduced baselines. revision: yes
Circularity Check
No significant circularity: claims rest on experimental results
full rationale
The paper presents its core claims as empirical outcomes: zero-shot accuracies of 66.0%/91.9% intra-subject and 24.0%/52.9% LOSO on the public THINGS-EEG dataset, attributed to the three proposed mechanisms (SAVE, UEE, PPA). No equations, fitted parameters, or self-citations are shown in the provided text that reduce these measured accuracies to inputs by construction. The derivation chain consists of architectural descriptions followed by benchmark evaluation, which is self-contained against external data and does not exhibit self-definitional, fitted-prediction, or load-bearing self-citation patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yueyang Li, Weiming Zeng, Wenhao Dong, Di Han, Lei Chen, Hongyu Chen, Zijian Kang, Shengyu Gong, Hongjie Yan, Wai Ting Siok, and Nizhuan Wang. A tale of single-channel electroencephalography: Devices, datasets, signal processing, applications, and future directions.IEEE Transactions on Instrumentation and Measurement, 74:1–20, 2025
2025
-
[2]
Fudong Zhang, Bo Chai, Yujie Wu, Wai Ting Siok, and Nizhuan Wang. Linguistics and human brain: A perspective of computational neuroscience.arXiv preprint arXiv:2602.08275, 2026
Pith/arXiv arXiv 2026
-
[3]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine ...
2021
-
[4]
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 17612–17625. Curran Associates, Inc., 2022
2022
-
[5]
Mitigate the gap: Improving cross-modal alignment in clip
Sedigheh Eslami and Gerard de Melo. Mitigate the gap: Improving cross-modal alignment in clip. InThe Thirteenth International Conference on Learning Representations, 2025. 19 SUP-MCRL: Subject-aware Unified Pseudo-feature Coded Multimodal Contrastive Representation Learning for EEG Visual Decoding
2025
-
[6]
Causality-inspired brain-visual contrastive learning for zero-shot visual decoding.Knowledge-Based Systems, 346:116182, 2026
Yi Xiao, Xuyi Qiao, Yu-Xuan Zhang, and Xianchuan Yu. Causality-inspired brain-visual contrastive learning for zero-shot visual decoding.Knowledge-Based Systems, 346:116182, 2026
2026
-
[7]
A large and rich eeg dataset for modeling human visual object recognition.NeuroImage, 264:119754, 2022
Alessandro T Gifford, Kshitij Dwivedi, Gemma Roig, and Radoslaw M Cichy. A large and rich eeg dataset for modeling human visual object recognition.NeuroImage, 264:119754, 2022
2022
-
[8]
Neural-mcrl: Neural multimodal contrastive representation learning for eeg-based visual decoding
Yueyang Li, Zijian Kang, Shengyu Gong, Wenhao Dong, Weiming Zeng, Hongjie Yan, Wai Ting Siok, and Nizhuan Wang. Neural-mcrl: Neural multimodal contrastive representation learning for eeg-based visual decoding. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6, 2025
2025
-
[9]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[10]
Changde Du, Kaicheng Fu, Jinpeng Li, and Huiguang He. Decoding visual neural representations by multimodal learning of brain-visual-linguistic features.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9):10760–10777, 2023
2023
-
[11]
Decoding natural images from eeg for object recognition
Yonghao Song, Bingchuan Liu, Xiang Li, Nanlin Shi, Yijun Wang, and Xiaorong Gao. Decoding natural images from eeg for object recognition. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors, International Conference on Learning Representations, volume 2024, pages 47648–47665, 2024
2024
-
[12]
Neuro-3d: Towards 3d visual decoding from eeg signals
Zhanqiang Guo, Jiamin Wu, Yonghao Song, Jiahui Bu, Weijian Mai, Qihao Zheng, Wanli Ouyang, and Chunfeng Song. Neuro-3d: Towards 3d visual decoding from eeg signals. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23870–23880, 2025
2025
-
[13]
Eeg-driven natural image reconstruc- tion with regional semantic awareness.Pattern Recognition, 172:112589, 2026
Xin Xiang, Wenhui Zhou, Haonan Zhu, Yunrui Li, Guojun Dai, and Lili Lin. Eeg-driven natural image reconstruc- tion with regional semantic awareness.Pattern Recognition, 172:112589, 2026
2026
-
[14]
Emanuele Balloni, Emanuele Frontoni, Chiara Matti, Marina Paolanti, Roberto Pierdicca, and Emiliano Santarnec- chi. Eeg2vision: A multimodal eeg-based framework for 2d visual reconstruction in cognitive neuroscience.arXiv preprint arXiv:2604.08063, 2026
Pith/arXiv arXiv 2026
-
[15]
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Haoyang Qin, and Quanying Liu. Visual decoding and reconstruction via eeg embeddings with guided diffusion.arXiv preprint arXiv:2403.07721, 2024
arXiv 2024
-
[16]
Neurobridge: Bio-inspired self-supervised eeg-to-image decoding via cognitive priors and bidirectional semantic alignment
Wenjiang Zhang, Sifeng Wang, Yuwei Su, Xinyu Li, Chen Zhang, and Suyu Zhong. Neurobridge: Bio-inspired self-supervised eeg-to-image decoding via cognitive priors and bidirectional semantic alignment. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18028–18036, 2026
2026
-
[17]
Damind: Zero-shot visual cross-domain alignment and representation for eeg decoding.IEEE Transactions on Image Processing, 35:3214–3227, 2026
Haodong Jing, Yongqiang Ma, Panqi Yang, Haoyu Li, Shuai Huang, Badong Chen, and Nanning Zheng. Damind: Zero-shot visual cross-domain alignment and representation for eeg decoding.IEEE Transactions on Image Processing, 35:3214–3227, 2026
2026
-
[18]
Mindsae: Advancing semantic perception for m/eeg-based visual decoding via unified multimodal alignment framework.Biomedical Signal Processing and Control, 123:110390, 2026
Chengjian Xu, Yonghao Song, Qiong Wang, and Qingqing Zheng. Mindsae: Advancing semantic perception for m/eeg-based visual decoding via unified multimodal alignment framework.Biomedical Signal Processing and Control, 123:110390, 2026
2026
-
[19]
Need: Cross-subject and cross-task generalization for video and image reconstruction from eeg signals
Shuai Huang, Huan Luo, Haodong Jing, Qixian Zhang, Litao Chang, Yating Feng, Xiao Lin, Chendong Qin, Han Chen, Shuwen Jia, Siyi Sun, and Yongxiong Wang. Need: Cross-subject and cross-task generalization for video and image reconstruction from eeg signals. In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Advances ...
2025
-
[20]
Wei Li, Penglu Zhao, Cheng Xu, Yingting Hou, Wenhao Jiang, and Aiguo Song. Deep learning for eeg-based visual classification and reconstruction: Panorama, trends, challenges and opportunities.IEEE Transactions on Biomedical Engineering, 72(11):3374–3390, 2025
2025
-
[21]
Interpretable cross-modal alignment network for eeg visual decoding with algorithm unrolling.IEEE Transactions on Neural Networks and Learning Systems, 36(11):19894–19908, 2025
Daowen Xiong, Liangliang Hu, Jiahao Jin, Yikang Ding, Congming Tan, Jing Zhang, and Yin Tian. Interpretable cross-modal alignment network for eeg visual decoding with algorithm unrolling.IEEE Transactions on Neural Networks and Learning Systems, 36(11):19894–19908, 2025
2025
-
[22]
Jiahe Meng, Weiming Zeng, Yueyang Li, Bo Chai, Hongjie Yan, Zhiguo Zhang, Wai Ting Siok, and Nizhuan Wang. Stambridge: Spectral-temporal amplitude-aware mid-feature bridge for eeg visual decoding.arXiv preprint arXiv:2605.23137, 2026
Pith/arXiv arXiv 2026
-
[23]
Seeeeg: Semantic-aware eeg-based multi-modal retrieval-augmented generation for high-fidelity visual brain decoding
Jun-Mo Kim, Woohyeok Choi, Sang-Jun Park, Keun-Soo Heo, Young-Han Son, Ji-Hye Oh, Dong-Hee Shin, and Tae-Eui Kam. Seeeeg: Semantic-aware eeg-based multi-modal retrieval-augmented generation for high-fidelity visual brain decoding. In2025 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), pages 4883–4892, 2025. 20 SUP-MCRL: Subject-awa...
2025
-
[24]
Eeg conformer: Convolutional transformer for eeg decoding and visualization.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 31:710–719, 2023
Yonghao Song, Qingqing Zheng, Bingchuan Liu, and Xiaorong Gao. Eeg conformer: Convolutional transformer for eeg decoding and visualization.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 31:710–719, 2023
2023
-
[25]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In2017 IEEE International Conference on Computer Vision (ICCV), pages 618–626, 2017
2017
-
[26]
Eeg-itnet: An explainable inception temporal convolutional network for motor imagery classification.IEEE Access, 10:36672–36685, 2022
Abbas Salami, Javier Andreu-Perez, and Helge Gillmeister. Eeg-itnet: An explainable inception temporal convolutional network for motor imagery classification.IEEE Access, 10:36672–36685, 2022
2022
-
[27]
Xiong Xiong, Li Su, Jinjie Guo, Tianyuan Song, Ying Wang, Jinguo Huang, and Guixia Kang. Enhancing motor imagery decoding in brain–computer interfaces using riemann tangent space mapping and cross frequency coupling.Biomedical Signal Processing and Control, 99:106797, 2025
2025
-
[28]
Dtp-net: Learning to reconstruct eeg signals in time-frequency domain by multi-scale feature reuse.IEEE Journal of Biomedical and Health Informatics, 28(5):2662–2673, 2024
Yan Pei, Jiahui Xu, Qianhao Chen, Chenhao Wang, Feng Yu, Lisan Zhang, and Wei Luo. Dtp-net: Learning to reconstruct eeg signals in time-frequency domain by multi-scale feature reuse.IEEE Journal of Biomedical and Health Informatics, 28(5):2662–2673, 2024
2024
-
[29]
O’Connor, and Kevin McGuinness
Eric Arazo, Diego Ortego, Paul Albert, Noel E. O’Connor, and Kevin McGuinness. Pseudo-labeling and confirmation bias in deep semi-supervised learning. In2020 International Joint Conference on Neural Networks (IJCNN), pages 1–8, 2020
2020
-
[30]
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks
Dong-Hyun Lee et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. InWorkshop on challenges in representation learning, ICML, volume 3, page 896. Atlanta, 2013
2013
-
[31]
Neurodecoder: A new framework for image decoding and reconstruction of eeg signals.IEEE Journal of Biomedical and Health Informatics, pages 1–14, 2026
Wenxuan Ma, Hongxin Zhang, Yexuan Li, and Mingyi Wei. Neurodecoder: A new framework for image decoding and reconstruction of eeg signals.IEEE Journal of Biomedical and Health Informatics, pages 1–14, 2026
2026
-
[32]
Representation learning with contrastive predictive coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[33]
Lel: Lipschitz continuity constrained ensemble learning for efficient eeg-based intrasubject emotion recognition.IEEE Sensors Journal, 26(9):13446–13456, 2026
Shengyu Gong, Yueyang Li, Zijian Kang, Bo Chai, Weiming Zeng, Hongjie Yan, Zhiguo Zhang, Wai Ting Siok, and Nizhuan Wang. Lel: Lipschitz continuity constrained ensemble learning for efficient eeg-based intrasubject emotion recognition.IEEE Sensors Journal, 26(9):13446–13456, 2026
2026
-
[34]
Mb2c: Multimodal bidirectional cycle consistency for learning robust visual neural representations
Yayun Wei, Lei Cao, Hao Li, and Yilin Dong. Mb2c: Multimodal bidirectional cycle consistency for learning robust visual neural representations. InProceedings of the 32nd ACM International Conference on Multimedia, MM ’24, page 8992–9000, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[35]
Hongzhou Chen, Lianghua He, Yihang Liu, Longzhen Yang, Shaohua Shang, and MengChu Zhou. Visual neural decoding via improved visual-eeg semantic consistency.arXiv preprint arXiv:2408.06788, 2024
arXiv 2024
-
[36]
Bridging the vision-brain gap with an uncertainty-aware blur prior
Haitao Wu, Qing Li, Changqing Zhang, Zhen He, and Xiaomin Ying. Bridging the vision-brain gap with an uncertainty-aware blur prior. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2246–2257, 2025
2025
-
[37]
Yueming Sun and Long Yang. Spatial-functional awareness transformer-based graph archetype contrastive learning for decoding visual neural representations from eeg.arXiv preprint arXiv:2509.24761, 2025. 21 SUP-MCRL: Subject-aware Unified Pseudo-feature Coded Multimodal Contrastive Representation Learning for EEG Visual Decoding Appendix Supplementary Mater...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.