LogCopilot: Automating Log Aggregation Analysis through Large Language Models
Pith reviewed 2026-06-27 04:16 UTC · model grok-4.3
The pith
LogCopilot automates log analysis by generating LogQL queries from natural language using large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
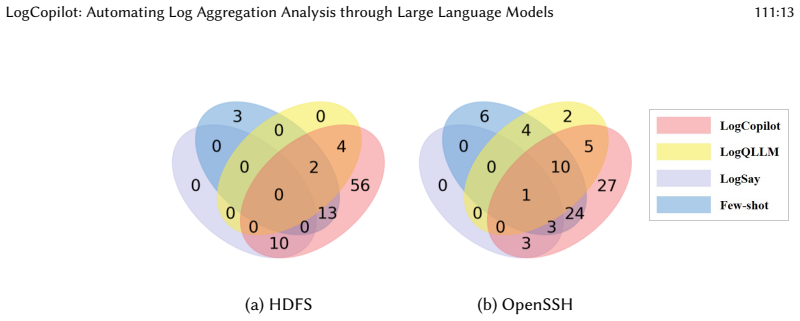
LogCopilot accepts natural language log analysis instructions and accomplishes automated log analysis through knowledge retrieval and tool calling by constructing a hierarchical knowledge base to represent key knowledge in logs and generating and executing LogQL queries. Evaluation on four log datasets shows an average accuracy of 76.8 percent while outperforming baselines, and the system proves effective at LogQL query generation.
What carries the argument
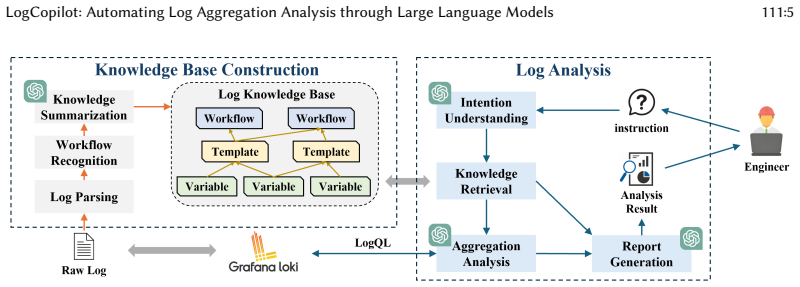
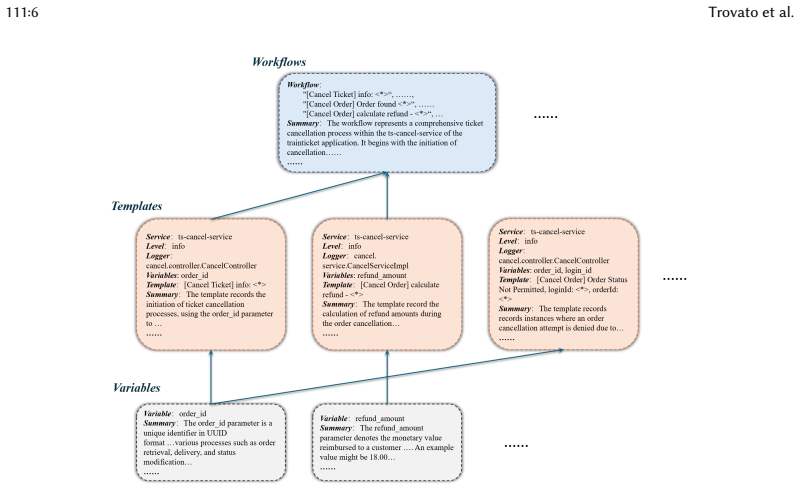
Hierarchical knowledge base that organizes log information to support large language model retrieval and LogQL query generation.
If this is right
- Engineers spend less time writing and debugging complex LogQL queries for log aggregation systems.
- Log analysis tasks can be completed by users without deep knowledge of the query language syntax.
- The framework supports a range of tasks including debugging, testing, and fault diagnosis through automated means.
- Query generation effectiveness is demonstrated separately from overall task accuracy.
Where Pith is reading between the lines
- The approach may apply to other query languages used in monitoring and logging tools.
- Improvements in language model capabilities could further increase the accuracy of generated queries.
- Integration into development workflows could enable more frequent and proactive log-based diagnostics.
Load-bearing premise
The hierarchical knowledge base accurately captures the key information from logs without significant loss or distortion of their meaning.
What would settle it
If LogCopilot applied to additional log datasets yields accuracy below that of the baseline approaches, the effectiveness claim would not hold.
Figures






read the original abstract
Logs record the runtime behavior of software and are widely used in various tasks such as debugging, testing, and fault diagnosis. With the increase in system size and complexity, log analysis has gradually become a challenging task. Current industrial systems typically use log aggregation systems such as Grafana Loki and ELK to simplify the log collection and analysis process. Engineers write queries using the DSL query language provided by these systems can complete a variety of log analysis tasks. However, writing these queries is often time-consuming and labor-intensive, as it requires engineers to have a thorough understanding of the DSL syntax and the detailed information contained in the logs. To address these challenges, this paper proposes LogCopilot, an automated log aggregation analysis framework based on large language models (LLMs). LogCopilot accepts natural language log analysis instructions and accomplishes automated log analysis through knowledge retrieval and tool calling. LogCopilot constructs a hierarchical knowledge base to represent and provide key knowledge in logs. And it achieves automated log aggregation analysis by generating and executing LogQL queries. The evaluation based on four log datasets confirm the effectiveness of LogCopilot, which achieves an average accuracy of 76.8% and outperforms baseline approaches. Moreover, experiment results shows that LogCopilot is effective in LogQL query generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LogCopilot, an LLM-based framework that accepts natural-language log analysis instructions, constructs a hierarchical knowledge base from logs to capture key information, and automates analysis by generating and executing LogQL queries via knowledge retrieval and tool calling. Evaluation on four log datasets is reported to yield 76.8% average accuracy, outperforming baselines, with additional results on LogQL query generation effectiveness.
Significance. If the empirical results and pipeline hold under rigorous validation, the work addresses a practical industrial need for reducing manual DSL query writing in log aggregation systems such as Grafana Loki and ELK. The combination of hierarchical KB construction with LLM-based query generation could streamline debugging and fault diagnosis workflows, provided the KB preserves log semantics reliably.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation description: the central claim of 76.8% average accuracy and outperformance rests on an unevaluated assumption that the hierarchical knowledge base accurately extracts and preserves log semantics (entity bindings, timestamp formats, structural details) without distortion. No ablation, semantic-preservation metric, human fidelity check, or comparison of KB vs. raw-log LLM performance is described, leaving open the possibility that success derives from LLM pretraining rather than the claimed pipeline.
- [Abstract] Abstract: the reported accuracy figure and baseline comparisons lack any description of experimental design, dataset characteristics (size, log formats, query complexity), baseline definitions, error bars, or how accuracy was measured for both analysis tasks and LogQL generation. This renders the quantitative claims unverifiable from the provided information.
minor comments (2)
- [Abstract] Abstract: 'experiment results shows' should be 'experiment results show'.
- [Abstract] The abstract states that LogCopilot 'constructs a hierarchical knowledge base to represent and provide key knowledge in logs' but does not specify the construction algorithm, hierarchy depth, or storage mechanism; this notation should be clarified in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the manuscript content and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation description: the central claim of 76.8% average accuracy and outperformance rests on an unevaluated assumption that the hierarchical knowledge base accurately extracts and preserves log semantics (entity bindings, timestamp formats, structural details) without distortion. No ablation, semantic-preservation metric, human fidelity check, or comparison of KB vs. raw-log LLM performance is described, leaving open the possibility that success derives from LLM pretraining rather than the claimed pipeline.
Authors: We agree that explicit validation of the KB's semantic fidelity would strengthen the claims. Section 3.2 details the hierarchical KB construction process, and Section 4 reports that the full pipeline outperforms baselines. However, the manuscript does not include dedicated ablations on KB versus raw-log performance or semantic-preservation metrics. We will add an ablation study and a human fidelity evaluation on sampled logs in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the reported accuracy figure and baseline comparisons lack any description of experimental design, dataset characteristics (size, log formats, query complexity), baseline definitions, error bars, or how accuracy was measured for both analysis tasks and LogQL generation. This renders the quantitative claims unverifiable from the provided information.
Authors: The abstract is concise by design, but Sections 4.1 and 4.2 of the full manuscript describe the four datasets (including sizes and formats), experimental protocol, baseline definitions, accuracy metrics (result equivalence for analysis tasks and execution correctness for LogQL), and results. We will expand the abstract with a brief overview of the evaluation methodology and dataset summary to improve immediate verifiability while respecting length constraints. revision: partial
Circularity Check
No circularity: empirical framework evaluation with no derivation chain
full rationale
The paper proposes LogCopilot as an LLM-based framework that builds a hierarchical knowledge base from logs and generates/executes LogQL queries, with effectiveness shown via empirical accuracy of 76.8% on four datasets outperforming baselines. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central result is an experimental measurement rather than a reduction to inputs by construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A hierarchical knowledge base can be constructed that faithfully represents key log information for downstream LLM query generation.
invented entities (1)
-
Hierarchical knowledge base for logs
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Prafulla Bafna, Dhanya Pramod, and Anagha Vaidya. 2016. Document clustering: TF-IDF approach. In2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT). IEEE, 61–66
2016
-
[2]
Zhuangbin Chen, Junsong Pu, and Zibin Zheng. 2025. Tracezip: Efficient Distributed Tracing via Trace Compression. Proc. ACM Softw. Eng.2, ISSTA (2025), 411–433. doi:10.1145/3728888
-
[3]
Guojun Chu, Jingyu Wang, Tao Sun, Qi Qi, Haifeng Sun, Zirui Zhuang, and Jianxin Liao. 2025. LogNotion: Highlighting Massive Logs to Assist Human Reading and Decision Making.IEEE Trans. Serv. Comput.18, 2 (2025), 940–953. doi:10.1109/TSC.2025.3528327
-
[4]
Datadog. 2025. Datadog. Retrieved May 26, 2025. https://www.datadoghq.com/
2025
-
[5]
Min Du, Feifei Li, Guineng Zheng, and Vivek Srikumar. 2017. DeepLog: Anomaly Detection and Diagnosis from System Logs through Deep Learning. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS 2017, Dallas, TX, USA, October 30 - November 03, 2017. ACM, 1285–1298. doi:10.1145/3133956.3134015
-
[6]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson
-
[7]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
From Local to Global: A Graph RAG Approach to Query-Focused Summarization.CoRRabs/2404.16130 (2024). doi:10.48550/ARXIV.2404.16130
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.16130 2024
-
[8]
Grafana. 2025. Grafana Loki. Retrieved May 26, 2025. https://grafana.com/oss/loki/
2025
-
[9]
Grafana. 2025. LogQL. Retrieved May 26, 2025. https://grafana.com/docs/loki/latest/query/
2025
-
[10]
Xiaofeng Guo, Xin Peng, Hanzhang Wang, Wanxue Li, Huai Jiang, Dan Ding, Tao Xie, and Liangfei Su. 2020. Graph- based trace analysis for microservice architecture understanding and problem diagnosis. InESEC/FSE ’20: 28th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, USA, November...
-
[11]
Pinjia He, Jieming Zhu, Zibin Zheng, and Michael R. Lyu. 2017. Drain: An Online Log Parsing Approach with Fixed Depth Tree. In2017 IEEE International Conference on Web Services, ICWS 2017. IEEE, 33–40. doi:10.1109/ICWS.2017.13
-
[12]
Shilin He, Pinjia He, Zhuangbin Chen, Tianyi Yang, Yuxin Su, and Michael R. Lyu. 2022. A Survey on Automated Log Analysis for Reliability Engineering.ACM Comput. Surv.54, 6 (2022), 130:1–130:37. doi:10.1145/3460345
-
[13]
Shilin He, Xu Zhang, Pinjia He, Yong Xu, Liqun Li, Yu Kang, Minghua Ma, Yining Wei, Yingnong Dang, Saravanakumar Rajmohan, and Qingwei Lin. [n. d.]. An empirical study of log analysis at Microsoft. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE
-
[15]
Shilin He, Xu Zhang, Pinjia He, Yong Xu, Liqun Li, Yu Kang, Minghua Ma, Yining Wei, Yingnong Dang, Saravanakumar Rajmohan, and Qingwei Lin. 2022. An empirical study of log analysis at Microsoft. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE
2022
-
[16]
ACM, 1465–1476. doi:10.1145/3540250.3558963
-
[17]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. [n. d.]. LoRA: Low-Rank Adaptation of Large Language Models. InThe Tenth International Conference on Learning Representations, ICLR 2022. https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[18]
Yintong Huo, Yuxin Su, Cheryl Lee, and Michael R. Lyu. 2023. SemParser: A Semantic Parser for Log Analytics. In45th IEEE/ACM International Conference on Software Engineering, ICSE 2023. IEEE, 881–893. doi:10.1109/ICSE48619.2023.00082
-
[19]
Xinrui Jiang, Yicheng Pan, Meng Ma, and Ping Wang. 2023. Look Deep into the Microservice System Anomaly through Very Sparse Logs. InProceedings of the ACM Web Conference 2023, WWW 2023. ACM, 2970–2978. doi:10.1145/3543507. 3583338
-
[20]
Zhihan Jiang, Jinyang Liu, Zhuangbin Chen, Yichen Li, Junjie Huang, Yintong Huo, Pinjia He, Jiazhen Gu, and Michael R. Lyu. 2024. LILAC: Log Parsing using LLMs with Adaptive Parsing Cache.Proc. ACM Softw. Eng.1, FSE (2024), 137–160. doi:10.1145/3643733
-
[21]
Zhihan Jiang, Jinyang Liu, Junjie Huang, Yichen Li, Yintong Huo, Jiazhen Gu, Zhuangbin Chen, Jieming Zhu, and Michael R. Lyu. 2024. A Large-Scale Evaluation for Log Parsing Techniques: How Far Are We?. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024. ACM, 223–234. J. ACM, Vol. 37, No. 4, Article 1...
-
[22]
George Katsogiannis-Meimarakis and Georgia Koutrika. 2023. A survey on deep learning approaches for text-to-SQL. VLDB J.32, 4 (2023), 905–936. doi:10.1007/S00778-022-00776-8
-
[23]
Hyeonji Kim, Byeong-Hoon So, Wook-Shin Han, and Hongrae Lee. 2020. Natural language to SQL: Where are we today?Proc. VLDB Endow.13, 10 (2020), 1737–1750. doi:10.14778/3401960.3401970
-
[24]
Cheryl Lee, Tianyi Yang, Zhuangbin Chen, Yuxin Su, and Michael R. Lyu. 2023. Eadro: An End-to-End Troubleshooting Framework for Microservices on Multi-source Data. In45th IEEE/ACM International Conference on Software Engineering, ICSE 2023. IEEE, 1750–1762. doi:10.1109/ICSE48619.2023.00150
-
[25]
Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, and Nan Tang. 2024. The Dawn of Natural Language to SQL: Are We Fully Ready? [Experiment, Analysis & Benchmark ].Proc. VLDB Endow.17, 11 (2024), 3318–3331. doi:10.14778/ 3681954.3682003
arXiv 2024
-
[26]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin Chen-Chuan Chang, Fei Huang, Reynold Cheng, and Yongbin Li. [n. d.]. Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs. In Annual Conference on N...
2023
-
[27]
Xinyu Liu, Shuyu Shen, Boyan Li, Peixian Ma, Runzhi Jiang, Yuyu Luo, Yuxin Zhang, Ju Fan, Guoliang Li, and Nan Tang
-
[28]
A Survey of NL2SQL with Large Language Models: Where are we, and where are we going?CoRRabs/2408.05109 (2024). doi:10.48550/ARXIV.2408.05109
-
[29]
Yudong Liu, Xu Zhang, Shilin He, Hongyu Zhang, Liqun Li, Yu Kang, Yong Xu, Minghua Ma, Qingwei Lin, Yingnong Dang, Saravan Rajmohan, and Dongmei Zhang. 2022. UniParser: A Unified Log Parser for Heterogeneous Log Data. In WWW ’22: The ACM Web Conference 2022. ACM, 1893–1901. doi:10.1145/3485447.3511993
-
[30]
Steven Locke, Heng Li, Tse-Hsun Peter Chen, Weiyi Shang, and Wei Liu. 2022. LogAssist: Assisting Log Analysis Through Log Summarization.IEEE Trans. Software Eng.48, 9 (2022), 3227–3241. doi:10.1109/TSE.2021.3083715
-
[31]
LogCopilot. 2026. LogCopilot. Retrieved May 26, 2026. https://github.com/FudanSELab/LogCopilot
2026
-
[32]
James MacQueen. 1967. Some methods for classification and analysis of multivariate observations. InProceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics, Vol. 5. University of California press, 281–298
1967
-
[33]
Pin Ni, Ramin Okhrati, Steven Guan, and Victor Chang. 2024. Knowledge Graph and Deep Learning-based Text-to- GraphQL Model for Intelligent Medical Consultation Chatbot.Inf. Syst. Frontiers26, 1 (2024), 137–156. doi:10.1007/ S10796-022-10295-0
2024
-
[34]
OpenAI. 2024. GPT-4o. Retrieved May 26, 2025. https://platform.openai.com/docs/models/gpt-4o
2024
-
[35]
OpenAI. 2024. OpenAI Cookbook. Retrieved May 26, 2025. https://cookbook.openai.com/
2024
-
[36]
OpenAI. 2025. text-embedding-3-large. Retrieved May 26, 2025. https://platform.openai.com/docs/models/text- embedding-3-large
2025
-
[37]
Xin Peng, Chenxi Zhang, Zhongyuan Zhao, Akasaka Isami, Xiaofeng Guo, and Yunna Cui. 2022. Trace analysis based microservice architecture measurement. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022. ACM, 1589–1599. doi:10.1145/3540250. 3558951
-
[38]
Mohammadreza Pourreza, Hailong Li, Ruoxi Sun, Yeounoh Chung, Shayan Talaei, Gaurav Tarlok Kakkar, Yu Gan, Amin Saberi, Fatma Ozcan, and Sercan Ö. Arik. 2025. CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL. InThe Thirteenth International Conference on Learning Representations, ICLR 2025. https://openreview.net/f...
2025
-
[39]
Mohammadreza Pourreza and Davood Rafiei. 2023. DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Alice Oh, Tristan Naumann, Amir Globerson, Kate Saen...
2023
-
[40]
Prometheus. 2025. Prometheus. Retrieved May 26, 2025. https://prometheus.io/
2025
-
[41]
Jiaxing Qi, Zhongzhi Luan, Shaohan Huang, Carol J. Fung, and Hailong Yang. 2024. LogSay: An Efficient Comprehension System for Log Numerical Reasoning.IEEE Trans. Computers73, 7 (2024), 1809–1821. doi:10.1109/TC.2024.3386068
-
[42]
Rui Ren, Jingbang Yang, Linxiao Yang, Xinyue Gu, and Liang Sun. 2024. SLIM: a Scalable and Interpretable Light-weight Fault Localization Algorithm for Imbalanced Data in Microservice. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE 2024. ACM, 27–39. doi:10.1145/3691620.3694984
-
[43]
Tonghui Ren, Yuankai Fan, Zhenying He, Ren Huang, Jiaqi Dai, Can Huang, Yinan Jing, Kai Zhang, Yifan Yang, and X. Sean Wang. 2024. PURPLE: Making a Large Language Model a Better SQL Writer. In40th IEEE International Conference on Data Engineering, ICDE 2024. IEEE, 15–28. doi:10.1109/ICDE60146.2024.00009 J. ACM, Vol. 37, No. 4, Article 111. Publication dat...
-
[44]
Dhole, Ishan Sharma, Avani Wildani, José Cambronero, and Andreas Züfle
Vishwanath Seshagiri, Siddharth Balyan, Vaastav Anand, Kaustubh D. Dhole, Ishan Sharma, Avani Wildani, José Cambronero, and Andreas Züfle. 2024. Chatting with Logs: An exploratory study on Finetuning LLMs for LogQL. CoRRabs/2412.03612 (2024). arXiv:2412.03612 doi:10.48550/ARXIV.2412.03612
-
[45]
Shiwen Shan, Yintong Huo, Yuxin Su, Yichen Li, Dan Li, and Zibin Zheng. 2024. Face It Yourselves: An LLM-Based Two-Stage Strategy to Localize Configuration Errors via Logs. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024. ACM, 13–25. doi:10.1145/3650212.3652106
-
[46]
Liang Shi, Zhengju Tang, and Zhi Yang. 2024. A Survey on Employing Large Language Models for Text-to-SQL Tasks. CoRRabs/2407.15186 (2024). arXiv:2407.15186 doi:10.48550/ARXIV.2407.15186
-
[47]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. [n. d.]. Reflexion: language agents with verbal reinforcement learning. InAnnual Conference on Neural Information Processing Systems 2023, NeurIPS 2023
2023
-
[48]
Jacopo Soldani and Antonio Brogi. 2023. Anomaly Detection and Failure Root Cause Analysis in (Micro) Service-Based Cloud Applications: A Survey.ACM Comput. Surv.55, 3 (2023), 59:1–59:39. doi:10.1145/3501297
-
[49]
Elastic Stack. 2025. Elasticsearch. Retrieved May 26, 2025. https://www.elastic.co/cn/elasticsearch
2025
-
[50]
Elastic Stack. 2025. ELK. Retrieved May 26, 2025. https://www.elastic.co/cn/elastic-stack
2025
-
[51]
Ziheng Wang, Farzad Niknia, Shanshan Liu, Pedro Reviriego, Paolo Montuschi, and Fabrizio Lombardi. 2023. Tolerance of Siamese Networks (SNs) to Memory Errors: Analysis and Design.IEEE Trans. Computers72, 4 (2023), 1136–1149. doi:10.1109/TC.2022.3186628
-
[52]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. [n. d.]. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. ([n. d.])
-
[53]
Xiaoxue Wu, Wei Zheng, Xin Xia, and David Lo. 2022. Data Quality Matters: A Case Study on Data Label Correctness for Security Bug Report Prediction.IEEE Trans. Software Eng.48, 7 (2022), 2541–2556. doi:10.1109/TSE.2021.3063727
-
[54]
Shuaiyu Xie, Jian Wang, Maodong Li, Peiran Chen, Jifeng Xuan, and Bing Li. 2025. TracePicker: Optimization-Based Trace Sampling for Microservice-Based Systems.Proc. ACM Softw. Eng.2, FSE (2025), 1802–1823. doi:10.1145/3729351
-
[55]
Junjielong Xu, Ziang Cui, Yuan Zhao, Xu Zhang, Shilin He, Pinjia He, Liqun Li, Yu Kang, Qingwei Lin, Yingnong Dang, Saravan Rajmohan, and Dongmei Zhang. 2024. UniLog: Automatic Logging via LLM and In-Context Learning. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024. ACM, 14:1–14:12. doi:10.1145/3597503.3623326
-
[56]
Junjielong Xu, Ruichun Yang, Yintong Huo, Chengyu Zhang, and Pinjia He. 2024. DivLog: Log Parsing with Prompt Enhanced In-Context Learning. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024. ACM, 199:1–199:12. doi:10.1145/3597503.3639155
-
[57]
Ke Xv, Shikai Guo, Hui Li, Chenchen Li, Rong Chen, Xiaochen Li, and He Jiang. 2025. Making Fault Localization in Online Service Systems More Actionable and Interpretable.ACM Trans. Softw. Eng. Methodol.34, 6 (2025), 165:1–165:26
2025
-
[58]
Jian Yang, Zian Wang, Shuangwu Chen, Huasen He, Yunpeng Hou, and Xiaofeng Jiang. 2025. HG-PAD: Heterogeneous Graph Structure Learning Aided Performance Anomaly Diagnosis in Microservice Systems.IEEE Transactions on Services Computing(2025)
2025
-
[59]
Adams Wei Yu, David Dohan, Quoc Le, Thang Luong, Rui Zhao, and Kai Chen. 2018. Fast and accurate reading comprehension by combining self-attention and convolution. InInternational conference on learning representations, Vol. 2
2018
-
[60]
Boxi Yu, Jiayi Yao, Qiuai Fu, Zhiqing Zhong, Haotian Xie, Yaoliang Wu, Yuchi Ma, and Pinjia He. 2024. Deep Learning or Classical Machine Learning? An Empirical Study on Log-Based Anomaly Detection. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024. ACM, 35:1–35:13. doi:10.1145/3597503.3623308
-
[61]
Guangba Yu, Pengfei Chen, Yufeng Li, Hongyang Chen, Xiaoyun Li, and Zibin Zheng. 2023. Nezha: Interpretable Fine-Grained Root Causes Analysis for Microservices on Multi-modal Observability Data. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2023. ACM, 553–565...
-
[62]
Xiao Yu, Pallavi Joshi, Jianwu Xu, Guoliang Jin, Hui Zhang, and Guofei Jiang. [n. d.]. CloudSeer: Workflow Monitoring of Cloud Infrastructures via Interleaved Logs. InProceedings of the Twenty-First International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS 2016. 489–502. doi:10.1145/2872362.2872407
-
[63]
Chenxi Zhang, Xin Peng, Chaofeng Sha, Ke Zhang, Zhenqing Fu, Xiya Wu, Qingwei Lin, and Dongmei Zhang. 2022. DeepTraLog: Trace-Log Combined Microservice Anomaly Detection through Graph-based Deep Learning. In44th IEEE/ACM 44th International Conference on Software Engineering, ICSE 2022. ACM, 623–634. doi:10.1145/3510003.3510180
-
[64]
Xu Zhang, Yong Xu, Qingwei Lin, Bo Qiao, Hongyu Zhang, Yingnong Dang, Chunyu Xie, Xinsheng Yang, Qian Cheng, Ze Li, Junjie Chen, Xiaoting He, Randolph Yao, Jian-Guang Lou, Murali Chintalapati, Furao Shen, and Dongmei Zhang
-
[65]
Robust log-based anomaly detection on unstable log data. InProceedings of the ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSOFT FSE 2019. ACM, 807–817. doi:10.1145/3338906.3338931 J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018. 111:22 Trovato et al
-
[66]
Xiang Zhou, Xin Peng, Tao Xie, Jun Sun, Chao Ji, Wenhai Li, and Dan Ding. 2021. Fault Analysis and Debugging of Microservice Systems: Industrial Survey, Benchmark System, and Empirical Study.IEEE Trans. Software Eng.47, 2 (2021), 243–260. doi:10.1109/TSE.2018.2887384
-
[67]
Xiang Zhou, Xin Peng, Tao Xie, Jun Sun, Chao Ji, Dewei Liu, Qilin Xiang, and Chuan He. 2019. Latent error prediction and fault localization for microservice applications by learning from system trace logs. InProceedings of the ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSO...
-
[68]
Jieming Zhu, Shilin He, Pinjia He, Jinyang Liu, and Michael R. Lyu. 2023. Loghub: A Large Collection of System Log Datasets for AI-driven Log Analytics. In34th IEEE International Symposium on Software Reliability Engineering, ISSRE
2023
-
[69]
IEEE, 355–366. doi:10.1109/ISSRE59848.2023.00071 Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009 J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.