Models Take Notes at Prefill: KV Cache Can Be Editable and Composable
Pith reviewed 2026-06-27 03:34 UTC · model grok-4.3
The pith
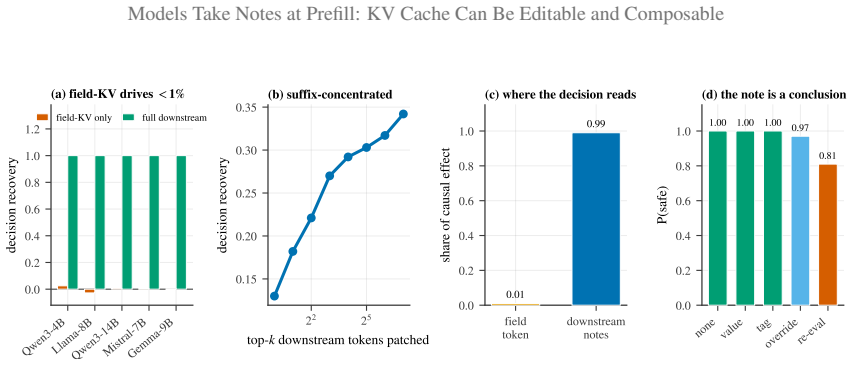
KV caches record field-conditioned conclusions at prefill, so the original field's vectors drive under 1% of later decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
At prefill the model has already written the field-conditioned conclusion onto downstream notes; the field's own key/value drives under 1% of the decision. Read as a notebook of memoized conclusions, the KV cache is therefore editable by amending the notes and composable by RoPE-repositioning and splicing the notes into new contexts.
What carries the argument
Downstream KV-cache entries that hold the conclusions memoized during prefill; these entries, not the original field's vectors, determine the model's output.
If this is right
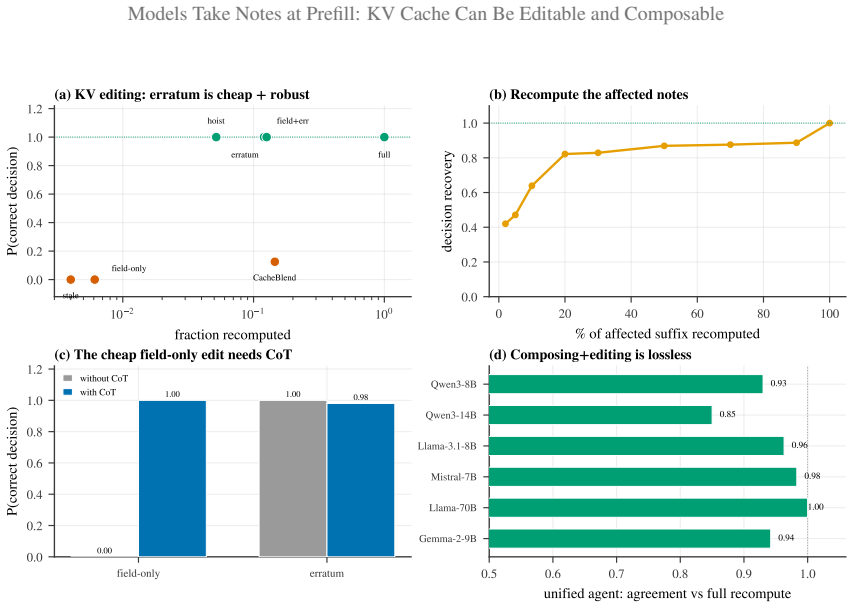
- With chain-of-thought, editing the field alone recovers the original decision at accuracy 1.00 while using roughly 1 percent of the original compute.
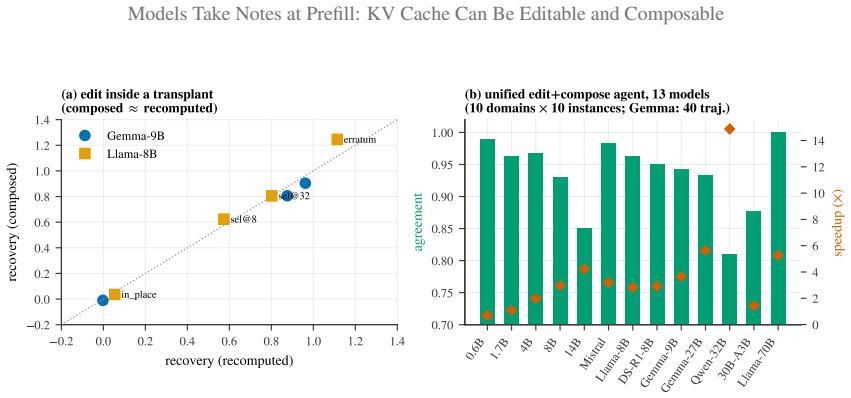
- Precompiled notes can be spliced into arbitrary contexts at O(L) cost and produce logits whose cosine similarity to full recompute lies between 0.90 and 0.999 across twelve models.
- A single edit-plus-compose agent stays decision-identical to recompute while reducing time-to-first-token by up to 14.9 times.
- The method preserves 98.5 percent prefix-cache hit rate in production vLLM workloads and cuts p90 time-to-first-token by 53-398 times.
- The same edit-and-compose behavior holds under quantization, Mixture-of-Experts routing, multimodal inputs, and several attention variants after small adapters.
Where Pith is reading between the lines
- Systems could maintain libraries of reusable prefilled modules that are spliced on demand rather than recomputed.
- Error correction and fact updating could be performed by appending short errata instead of regenerating entire contexts.
- The same notebook view may apply to other per-token state caches once the causal isolation experiments are repeated for those architectures.
Load-bearing premise
The causal interventions across four model families correctly isolate that the downstream cache entries carry the decision and that RoPE-repositioned splices remain indistinguishable from full recompute.
What would settle it
A controlled edit of only the downstream notes that leaves the model output unchanged, or a RoPE-repositioned splice whose logits show cosine similarity below 0.90 to the corresponding full recompute.
Figures



















read the original abstract
Prefix caching reuses prefill only across an exactly shared prefix, so one changed field invalidates the entire downstream cache. Yet overwriting the field's own key/value vectors and reusing the rest leaves the model acting on the old value. The reason, established causally across four model families: at prefill the model has already written the field-conditioned conclusion onto downstream notes; the field's own key/value drives under 1% of the decision. Read as a notebook of memoized conclusions, two capabilities follow. (1) It is editable. A salient erratum amends the notes; and with chain-of-thought, editing the field alone recovers the decision (1.00 at 8B, ~1% compute), while without CoT it is ignored. (2) It is composable. The notes are position-portable, so a precompiled skill can be RoPE-repositioned and spliced into any context, indistinguishable from full recompute (logit cosine 0.90-0.999, twelve models) at O(L) rather than O(L^2) time-to-first-token. A unified edit+compose agent stays decision-identical to recompute at up to 14.9x lower latency. The approach applies to any per-token attention KV cache, validated across scale, quantization, Mixture-of-Experts, and multimodal caches, and extends to several attention variants through small adapters. Because the erratum is append-only, it composes with production prefix caching: in an online vLLM benchmark it keeps the prefix cache-aligned (98.5% hit-rate), cutting p90 time-to-first-token by 53-398x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that during prefill, transformer models write field-conditioned conclusions into downstream KV cache positions such that the original field's own key/value vectors drive under 1% of the final decision. This 'notebook' view enables two capabilities: (1) editability, where overwriting a field's KV and using chain-of-thought recovers the decision at 1.00 (8B scale, ~1% compute) while non-CoT ignores the edit; (2) composability, where RoPE-repositioned splices of precompiled notes are indistinguishable from full recompute (logit cosine 0.90-0.999 across twelve models) at O(L) rather than O(L^2) cost. The approach is validated across scale, quantization, MoE, multimodal caches, attention variants, and an online vLLM benchmark showing 53-398x p90 TTFT reduction at 98.5% prefix-cache hit rate.
Significance. If the causal isolation holds, the result offers a practical route to editable and composable KV caches that composes with existing prefix caching, delivering large latency gains while preserving decision fidelity. The cross-family empirical validation and production benchmark are concrete strengths.
major comments (2)
- [Abstract / causal-experiments section] Abstract and causal-experiments section: the claim that downstream notes carry the decision (original KV <1%) and that RoPE-repositioned splices remain equivalent to recompute rests on interventions across four model families, yet no error bars, exclusion criteria, or explicit controls for side effects on attention patterns or intermediate activations are reported; logit cosine alone may not rule out such confounds, which is load-bearing for the notebook interpretation.
- [Composability results] Composability results (logit cosine 0.90-0.999): the manuscript must demonstrate that the splicing procedure leaves attention masks, layer norms, and non-KV activations unchanged; without those controls the equivalence to full recompute cannot be taken as evidence that only the memoized notes matter.
minor comments (2)
- [Abstract] Abstract states recovery '1.00 at 8B' and 'under 1%' without defining the exact decision metric or baseline comparison used for the percentage.
- [vLLM benchmark] The vLLM benchmark reports 98.5% hit-rate and 53-398x TTFT reduction; clarify whether these figures include the overhead of the edit/compose agent or are measured end-to-end.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that strengthening the presentation of causal evidence and composability controls will improve the manuscript and will incorporate the requested additions in revision.
read point-by-point responses
-
Referee: [Abstract / causal-experiments section] Abstract and causal-experiments section: the claim that downstream notes carry the decision (original KV <1%) and that RoPE-repositioned splices remain equivalent to recompute rests on interventions across four model families, yet no error bars, exclusion criteria, or explicit controls for side effects on attention patterns or intermediate activations are reported; logit cosine alone may not rule out such confounds, which is load-bearing for the notebook interpretation.
Authors: We agree that error bars, explicit exclusion criteria, and controls for side effects on attention patterns and intermediate activations would strengthen the causal claims. The current results show consistent behavior across four model families and multiple scales, which we view as mitigating model-specific confounds, but this does not substitute for the requested statistical and control analyses. In the revised manuscript we will add error bars from repeated trials where applicable, clarify model and task exclusion criteria, and include direct comparisons of attention patterns and selected intermediate activations before and after interventions. revision: yes
-
Referee: [Composability results] Composability results (logit cosine 0.90-0.999): the manuscript must demonstrate that the splicing procedure leaves attention masks, layer norms, and non-KV activations unchanged; without those controls the equivalence to full recompute cannot be taken as evidence that only the memoized notes matter.
Authors: The splicing procedure replaces only the KV entries for the repositioned segments while preserving overall sequence length, token positions for non-spliced content, and the original attention mask structure; layer norms are likewise untouched because they operate on the same hidden states. Non-KV activations are recomputed identically to a full forward pass. We will add explicit verification in the revision by reporting attention mask equality, layer-norm statistics, and selected non-KV activation comparisons between spliced and full-recompute runs to confirm invariance. revision: yes
Circularity Check
No circularity; claims rest on empirical causal interventions, not derivations or self-referential fits
full rationale
The paper presents no derivation chain, equations, or fitted parameters that reduce to inputs by construction. Central claims (downstream notes carrying decisions, editability, composability via RoPE splicing) are justified by reported measurements: causal experiments across four model families showing <1% contribution from original KV, logit cosine 0.90-0.999 for splices vs recompute, and latency benchmarks. No self-citation load-bearing, no ansatz smuggled via citation, no uniqueness theorems, and no renaming of known results as new derivations. The approach is self-contained against external benchmarks (multiple models, quantization, MoE, multimodal) with falsifiable empirical tests. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan.τ2-bench: Eval- uating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI. DeepSeek-V2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
DeepSeek-AI. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024. 19 Models Take Notes at Prefill: KV Cache Can Be Editable and Composable
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI. DeepSeek-V3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
DeepSeek-V4 technical report, 2026.https://huggingface.co/ deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
DeepSeek-AI. DeepSeek-V4 technical report, 2026.https://huggingface.co/ deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
2026
-
[6]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Prompt cache: Modular attention reuse for low-latency inference
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt cache: Modular attention reuse for low-latency inference. InProceedings of Machine Learning and Systems (MLSys), 2024
2024
-
[8]
Aaron Grattafiori et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InConference on Language Modeling (COLM), 2024
2024
-
[10]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022
2022
-
[11]
EPIC: Efficient position-independent caching for serving large language models
Junhao Hu, Wenrui Huang, Weidong Wang, Haoyi Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, and Tao Xie. EPIC: Efficient position-independent caching for serving large language models. InProceedings of the 42nd International Con- ference on Machine Learning (ICML), 2025
2025
-
[12]
Editing models with task arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, et al. Editing models with task arithmetic. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[13]
Albert Q. Jiang et al. Mistral 7B.arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, et al. RAGCache: Efficient knowledge caching for retrieval-augmented generation.arXiv preprint arXiv:2404.12457, 2024
-
[15]
Inference- time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[16]
SnapKV: LLM knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, et al. SnapKV: LLM knows what you are looking for before generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[17]
On the biology of a large language model.Transformer Circuits Thread, Anthropic, 2025
Jack Lindsey et al. On the biology of a large language model.Transformer Circuits Thread, Anthropic, 2025
2025
-
[18]
CacheSlide: Unlocking cross position-aware KV cache reuse for accel- erating LLM serving
Yang Liu, Yunfei Gu, Liqiang Zhang, Chentao Wu, Guangtao Xue, Jie Li, Minyi Guo, Junhao Hu, and Jie Meng. CacheSlide: Unlocking cross position-aware KV cache reuse for accel- erating LLM serving. InProceedings of the 24th USENIX Conference on File and Storage Technologies (FAST), 2026. 20 Models Take Notes at Prefill: KV Cache Can Be Editable and Composable
2026
-
[19]
CacheGen: KV cache compression and streaming for fast large language model serving
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, et al. CacheGen: KV cache compression and streaming for fast large language model serving. InProceedings of ACM SIGCOMM, 2024
2024
-
[20]
Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, et al. Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[21]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. InProceed- ings of the Association for Computational Linguistics (ACL), 2024
2024
-
[22]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[23]
Mass- editing memory in a transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass- editing memory in a transformer. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[24]
RWKV: Reinventing RNNs for the transformer era
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, et al. RWKV: Reinventing RNNs for the transformer era. InFindings of the Association for Computational Linguistics: EMNLP 2023, 2023
2023
-
[25]
YaRN: Efficient context window extension of large language models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. YaRN: Efficient context window extension of large language models. InInternational Conference on Learning Repre- sentations (ICLR), 2024
2024
-
[26]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, et al. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[28]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568, 2024
2024
-
[29]
Quest: Query-aware sparsity for efficient long-context LLM inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: Query-aware sparsity for efficient long-context LLM inference. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[30]
Function vectors in large language models
Eric Todd, Millicent Li, Arnab Sen Sharma, Aaron Mueller, Byron C Wallace, and David Bau. Function vectors in large language models. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[31]
Investigating gender bias in lan- guage models using causal mediation analysis
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, et al. Investigating gender bias in lan- guage models using causal mediation analysis. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[32]
Interpretability in the wild: a circuit for indirect object identification in GPT-2 small
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In International Conference on Learning Representations (ICLR), 2023. 21 Models Take Notes at Prefill: KV Cache Can Be Editable and Composable
2023
-
[33]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representa- tions (ICLR), 2024
2024
-
[34]
KVLink: Accelerating large language models via efficient KV cache reuse
Jingbo Yang et al. KVLink: Accelerating large language models via efficient KV cache reuse. arXiv preprint arXiv:2502.16002, 2025
-
[35]
CacheBlend: Fast large language model serving for RAG with cached knowledge fusion
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. CacheBlend: Fast large language model serving for RAG with cached knowledge fusion. InProceedings of the European Conference on Computer Systems (EuroSys), 2025
2025
-
[36]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, et al. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[37]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
KVCache-centric memory for LLM agents, 2025
Yuan Zeng, Pengfei Zuo, Min Lyu, Xingkun Yang, Huatao Wu, Yinlong Xu, and Zhou Yu. KVCache-centric memory for LLM agents, 2025. Submitted to ICLR 2026; OpenReview, 18 September 2025
2025
-
[39]
H2O: Heavy- hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, et al. H2O: Heavy- hitter oracle for efficient generative inference of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[40]
Shiju Zhao, Junhao Hu, Rongxiao Huang, Jiaqi Zheng, and Guihai Chen. MPIC: Position- independent multimodal context caching system for efficient MLLM serving.arXiv preprint arXiv:2502.01960, 2025. 22 Models Take Notes at Prefill: KV Cache Can Be Editable and Composable Table 2: Model zoo. “role” indicates the experiments a model appears in. model family /...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.