RepSelect: Robust LLM Unlearning via Representation Selectivity
Pith reviewed 2026-06-27 03:31 UTC · model grok-4.3
The pith
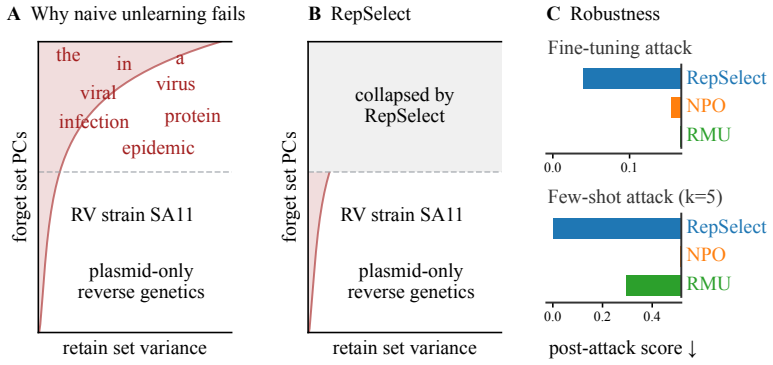
RepSelect isolates forget-set-specific representations in LLMs by collapsing top principal components of weight gradients, achieving deep unlearning resistant to fine-tuning and prompting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
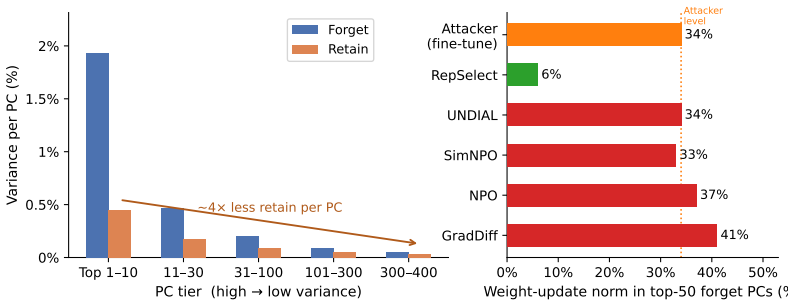
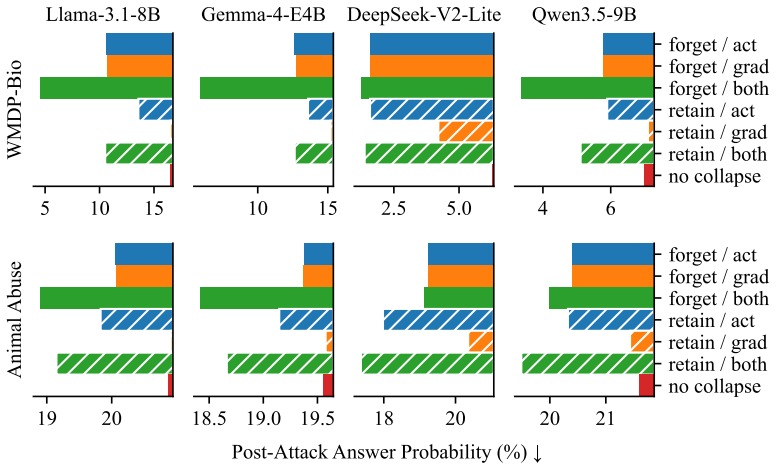
By collapsing the top principal components of weight gradients before each update, RepSelect isolates forget-set-specific representations, enabling robust unlearning that maintains general capabilities and resists reversal by fine-tuning or few-shot prompting. Evaluations on biohazardous knowledge and abusive tendencies across Llama 3, Qwen 3.5, Gemma 4, and DeepSeek V2 Lite models show 4-50x greater reduction in post-relearning answer accuracy compared to baselines including GradDiff, NPO, SimNPO, RMU, and UNDIAL, along with near-perfect robustness to few-shot prompting attacks.
What carries the argument
Representation Selectivity, implemented by collapsing top principal components of weight gradients before each update to isolate forget-set-specific representations while sparing shared ones.
If this is right
- Unlearning remains effective even after subsequent fine-tuning on retain data.
- General capabilities on unrelated tasks stay intact after the unlearning process.
- The method applies across both dense and Mixture-of-Experts model architectures.
- Few-shot prompting attacks fail to restore forgotten knowledge at high rates.
- The reduction in relearning accuracy exceeds that of prior methods by a factor of 4 to 50.
Where Pith is reading between the lines
- The gradient-component approach may extend to selective editing tasks beyond unlearning, such as targeted value adjustment.
- If the root-cause analysis of shared subspaces holds, similar selectivity could improve other safety interventions that currently suffer from reversibility.
- Scalability tests on models larger than those evaluated could reveal whether the principal-component collapse remains effective at higher parameter counts.
Load-bearing premise
Collapsing top principal components of weight gradients isolates only forget-set-specific representations without disrupting general capabilities or allowing fine-tuning attackers to recover the forgotten information.
What would settle it
Fine-tuning an attacker model on the retain set after RepSelect unlearning recovers forget-set answer accuracy to levels matching a non-unlearned baseline, or general capability benchmarks drop substantially below baseline levels.
Figures










read the original abstract
Making large language models (LLMs) deeply forget specific knowledge and values without sacrificing general capabilities remains a central challenge in unlearning. Current methods are easily reversed by fine-tuning or few-shot prompting, suggesting their forgetting is only shallow. We identify the root cause. Existing methods target representations shared with both the retain set and the subspace recovered by a fine-tuning attacker, making unlearning both disruptive to general capabilities and easy to reverse. We propose RepSelect (Representation Selectivity), which isolates forget-set-specific representations by collapsing top principal components of weight gradients before each update, leaving general capabilities intact while limiting what fine-tuning can recover. We evaluate across two forget categories, biohazardous knowledge and abusive tendencies, and four model families spanning dense and Mixture-of-Experts architectures (Llama 3, Qwen 3.5, Gemma 4 E4B, DeepSeek V2 Lite). Compared to five popular baselines (GradDiff, NPO, SimNPO, RMU, UNDIAL), RepSelect achieves a 4-50x larger reduction in post-relearning answer accuracy than the strongest baseline, and is near-perfectly robust to few-shot prompting attacks. Targeting selective representations is thus an important step towards deep and robust LLM forgetting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing LLM unlearning methods fail due to targeting representations shared with retain sets and attacker-recoverable subspaces, leading to shallow forgetting. It proposes RepSelect, which isolates forget-set-specific representations by collapsing top principal components of weight gradients before each update. Evaluations on biohazardous knowledge and abusive tendencies across Llama 3, Qwen 3.5, Gemma 4 E4B, and DeepSeek V2 Lite show 4-50x larger post-relearning accuracy reductions than baselines (GradDiff, NPO, SimNPO, RMU, UNDIAL) and near-perfect robustness to few-shot prompting.
Significance. If the core assumption holds and the empirical gains are reproducible with proper controls, this would mark a meaningful step toward deep, robust unlearning that preserves general capabilities. The multi-architecture evaluation and direct comparison to five baselines are strengths; the work supplies falsifiable predictions via post-relearning and attack metrics.
major comments (3)
- [§3] §3 (root-cause analysis): The assertion that top PCs of weight gradients encode forget knowledge absent from retain gradients and attacker subspaces is not supported by explicit checks such as subspace overlap metrics, cosine similarity between forget/retain PCs, or explained variance on retain vs. forget sets. This assumption is load-bearing for both the motivation and the claim that collapsing them prevents recovery.
- [§4.2] §4.2 (experimental setup) and Table 2 (post-relearning results): The 4-50x reduction claim lacks reported details on the number of runs, random seeds, statistical significance tests, exact hyperparameter search for PC count, and per-baseline numbers with variance; without these, it is not possible to determine whether the headline gains are robust or driven by specific choices.
- [§4.3] §4.3 (robustness evaluation): The near-perfect robustness to few-shot prompting is presented without ablation on whether the collapsed directions overlap with prompting-induced recovery directions or on retain-set performance degradation after unlearning, leaving open whether general capabilities remain intact as claimed.
minor comments (2)
- [§3.1] Clarify in §3.1 whether weight gradients are computed per-layer or aggregated across the model, and provide the precise algorithm for selecting and collapsing the top-k PCs.
- [Figures/Tables] Ensure all figures include error bars or confidence intervals and that table captions explicitly define the metrics (e.g., answer accuracy post-relearning).
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below, indicating revisions where the manuscript will be strengthened with additional analyses and reporting.
read point-by-point responses
-
Referee: [§3] §3 (root-cause analysis): The assertion that top PCs of weight gradients encode forget knowledge absent from retain gradients and attacker subspaces is not supported by explicit checks such as subspace overlap metrics, cosine similarity between forget/retain PCs, or explained variance on retain vs. forget sets. This assumption is load-bearing for both the motivation and the claim that collapsing them prevents recovery.
Authors: We agree that explicit quantitative validation would strengthen the root-cause analysis in §3. While the empirical superiority of RepSelect over baselines provides indirect support for the distinctness of the targeted subspaces, we will add direct checks including subspace overlap metrics, cosine similarities between forget-set and retain-set principal components, and comparisons of explained variance on both sets. These will be incorporated into the revised manuscript to make the load-bearing assumption explicit and falsifiable. revision: yes
-
Referee: [§4.2] §4.2 (experimental setup) and Table 2 (post-relearning results): The 4-50x reduction claim lacks reported details on the number of runs, random seeds, statistical significance tests, exact hyperparameter search for PC count, and per-baseline numbers with variance; without these, it is not possible to determine whether the headline gains are robust or driven by specific choices.
Authors: We acknowledge that the experimental reporting in §4.2 and Table 2 requires greater rigor. The original runs used multiple random seeds, but details were omitted. In the revision we will report results aggregated over five independent runs with different seeds, include per-baseline means and standard deviations in Table 2, add statistical significance tests (paired t-tests against the strongest baseline), and describe the procedure used to select the number of principal components (grid search on a small validation split). revision: yes
-
Referee: [§4.3] §4.3 (robustness evaluation): The near-perfect robustness to few-shot prompting is presented without ablation on whether the collapsed directions overlap with prompting-induced recovery directions or on retain-set performance degradation after unlearning, leaving open whether general capabilities remain intact as claimed.
Authors: We will strengthen §4.3 by adding two requested analyses: (1) an ablation measuring the cosine overlap between the collapsed principal components and the gradient directions recovered by few-shot prompting attacks, and (2) explicit retain-set accuracy and perplexity numbers before and after unlearning for all methods. These additions will directly address whether general capabilities are preserved and whether the collapsed directions are distinct from prompting-recovery directions. revision: yes
Circularity Check
No significant circularity; empirical method with external baselines
full rationale
The paper describes an empirical unlearning technique (collapsing top PCs of weight gradients) and evaluates it via direct comparison to five external baselines across multiple models and tasks. No equations, derivations, or 'predictions' are presented that reduce reported gains to quantities defined by fitted parameters from the same data. The root-cause analysis is framed as observational identification of shared representations rather than a self-referential or fitted-input construction. No self-citation chains or ansatzes are invoked as load-bearing premises. The evaluation remains falsifiable against independent baselines, satisfying the criteria for a self-contained, non-circular result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Representations shared with both retain set and fine-tuning attacker subspace cause shallow, reversible unlearning
Reference graph
Works this paper leans on
-
[1]
Optuna: A Next-generation Hyperparameter Optimization Framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A Next -generation Hyperparameter Optimization Framework , July 2019. arXiv:1907.10902
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
Extracting training data from large language models, 2021
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, and et al. Extracting training data from large language models, 2021. arXiv: 2012.07805
-
[3]
Efficient Lifelong Learning with A-GEM
Arslan Chaudhry, Marc'Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient Lifelong Learning with A - GEM , January 2019. arXiv:1812.00420 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[4]
Do Unlearning Methods Remove Information from Language Model Weights ?, November 2024
Aghyad Deeb and Fabien Roger. Do Unlearning Methods Remove Information from Language Model Weights ?, November 2024. arXiv:2410.08827
-
[5]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI , Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, et al. DeepSeek-V2 : A strong, economical, and efficient mixture-of-experts language model, May 2024. arXiv:2405.04434
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
UNDIAL : Self-distillation with adjusted logits for robust unlearning in large language models
Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ramon Huerta, and Ivan Vuli \'c . UNDIAL : Self-distillation with adjusted logits for robust unlearning in large language models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers...
2025
- [7]
-
[8]
European Parliament and Council of the European Union . Art. 17 gdpr -- right to erasure (`right to be forgotten'). https://gdpr-info.eu/art-17-gdpr/, 2016. Regulation (EU) 2016/679, OJ L 119. Accessed 2026-06-15
2016
-
[9]
arXiv preprint arXiv:2410.07163 (2024)
Chongyu Fan, Jiancheng Liu, Licong Lin, Jinghan Jia, Ruiqi Zhang, et al. Simplicity prevails: Rethinking negative preference optimization for llm unlearning, 2025. arXiv: 2410.07163
-
[10]
Kuda: Knowledge unlearning by deviating representation for large language models, 2026
Ce Fang, Zhikun Zhang, Min Chen, Qing Liu, Lu Zhou, Zhe Liu, and Yunjun Gao. Kuda: Knowledge unlearning by deviating representation for large language models, 2026. arXiv: 2602.19275
-
[11]
Fast machine unlearning without retraining through selective synaptic dampening, 2024
Jack Foster, Stefan Schoepf, and Alexandra Brintrup. Fast machine unlearning without retraining through selective synaptic dampening, 2024. arXiv: 2308.07707
-
[12]
Gemma Team . Gemma 4 . https://huggingface.co/google/gemma-4-E4B, April 2026. HuggingFace: google/gemma-4-E4B
2026
-
[13]
Mor Geva, Avi Caciularu, Kevin Ro Wang, and Yoav Goldberg. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space, 2022. arXiv: 2203.14680
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, and et al. The llama 3 herd of models, 2024. arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Manning, Dan Jurafsky, and Chelsea Finn
Peter Henderson, Eric Mitchell, Christopher D. Manning, Dan Jurafsky, and Chelsea Finn. Self- Destructing Models : Increasing the Costs of Harmful Dual Uses of Foundation Models , August 2023. arXiv:2211.14946 [cs]
-
[16]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, and et al. Measuring massive multitask language understanding, 2021. arXiv: 2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, et al. Lora: Low-rank adaptation of large language models, 2021. arXiv:2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, et al. BeaverTails : Towards Improved Safety Alignment of LLM via a Human - Preference Dataset , November 2023. arXiv:2307.04657
-
[19]
On the societal impact of open foundation models, 2024
Sayash Kapoor, Rishi Bommasani, Kevin Klyman, Shayne Longpre, Ashwin Ramaswami, and et al. On the societal impact of open foundation models, 2024. arXiv: 2403.07918
-
[20]
Copyright violations and large language models
Antonia Karamolegkou, Jiaang Li, Li Zhou, and Anders S gaard. Copyright violations and large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7403--7412, Singapore, December 2023. Association for Computational Linguistics. doi:10.18653/v1/2...
-
[21]
Andrew Lee, Xiaoyan Bai, Itamar Pres, Martin Wattenberg, Jonathan K. Kummerfeld, et al. A Mechanistic Understanding of Alignment Algorithms : A Case Study on DPO and Toxicity , January 2024. arXiv:2401.01967 [cs]
-
[22]
Lora fine-tuning efficiently undoes safety training in llama 2-chat 70b, 2024
Simon Lermen, Charlie Rogers-Smith, and Jeffrey Ladish. Lora fine-tuning efficiently undoes safety training in llama 2-chat 70b, 2024. arXiv:2310.20624
-
[23]
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, et al. The WMDP Benchmark : Measuring and Reducing Malicious Use With Unlearning , May 2024. arXiv:2403.03218 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Continual learning and private unlearning, 2022
Bo Liu, Qiang Liu, and Peter Stone. Continual learning and private unlearning, 2022. arXiv:2203.12817
-
[25]
Rethinking Machine Unlearning for Large Language Models , July 2024
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, et al. Rethinking Machine Unlearning for Large Language Models , July 2024. arXiv:2402.08787 [cs]
-
[26]
arXiv preprint arXiv:2402.16835 , year =
Aengus Lynch, Phillip Guo, Aidan Ewart, Stephen Casper, and Dylan Hadfield-Menell. Eight Methods to Evaluate Robust Unlearning in LLMs , February 2024. arXiv:2402.16835 [cs]
-
[27]
Finefineweb: A comprehensive study on fine-grained domain web corpus, December 2024
M-A-P , Ge Zhang, Xinrun Du, Zhimiao Yu, Zili Wang, et al. Finefineweb: A comprehensive study on fine-grained domain web corpus, December 2024
2024
-
[28]
Lipton, and J
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C. Lipton, and J. Zico Kolter. TOFU : A task of fictitious unlearning for LLMs . In Proceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[29]
Lev McKinney, Anvith Thudi, Juhan Bae, Tara Rezaei, Nicolas Papernot, Sheila A. McIlraith, and Roger Grosse. Gauss-newton unlearning for the LLM era, 2026. arXiv:2602.10568
-
[30]
Locating and Editing Factual Associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and Editing Factual Associations in GPT , January 2023. arXiv:2202.05262 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models, 2016. arXiv:1609.07843
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[32]
BBQ: A Hand-Built Bias Benchmark for Question Answering
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, and et al. Bbq: A hand-built bias benchmark for question answering, 2022. arXiv: 2110.08193
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, et al. Fine-tuning Aligned Language Models Compromises Safety , Even When Users Do Not Intend To !, October 2023. arXiv:2310.03693 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Smith and Chiyuan Zhang , year=
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, and et al. Muse: Machine unlearning six-way evaluation for language models, 2024. arXiv:2407.06460
-
[35]
Ununlearning: Unlearning is not sufficient for content regulation in advanced generative ai, 2024
Ilia Shumailov, Jamie Hayes, Eleni Triantafillou, Guillermo Ortiz-Jimenez, Nicolas Papernot, and et al. Ununlearning: Unlearning is not sufficient for content regulation in advanced generative ai, 2024. arXiv:2407.00106
-
[36]
Filip Sondej, Yushi Yang, Mikołaj Kniejski, and Marcel Windys. Robust LLM Unlearning with MUDMAN : Meta - Unlearning with Disruption Masking And Normalization , June 2025. arXiv:2506.12484 [cs]
-
[37]
Tamper- Resistant Safeguards for Open - Weight LLMs , August 2024
Rishub Tamirisa, Bhrugu Bharathi, Long Phan, Andy Zhou, Alice Gatti, et al. Tamper- Resistant Safeguards for Open - Weight LLMs , August 2024. arXiv:2408.00761 [cs]
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, and et al. Qwen3 technical report, 2025 a . arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
How does DPO reduce toxicity? A mechanistic neuron-level analysis
Yushi Yang, Filip Sondej, Harry Mayne, Andrew Lee, and Adam Mahdi. How does DPO reduce toxicity? A mechanistic neuron-level analysis. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, November 2025 b
2025
-
[40]
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning, 2024. arXiv:2404.05868
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Geometric-disentangelment unlearning.arXiv preprint arXiv:2511.17100, 2026
Duo Zhou, Yuji Zhang, Tianxin Wei, Ruizhong Qiu, Ke Yang, and et al. Geometric-disentangelment unlearning, 2026. arXiv:2511.17100
-
[42]
Improving Alignment and Robustness with Circuit Breakers , July 2024
Andy Zou, Long Phan, Justin Wang, Derek Duenas, Maxwell Lin, et al. Improving Alignment and Robustness with Circuit Breakers , July 2024. arXiv:2406.04313 [cs]
-
[43]
An Adversarial Perspective on Machine Unlearning for AI Safety , January 2025
Jakub Łucki, Boyi Wei, Yangsibo Huang, Peter Henderson, Florian Tramèr, et al. An Adversarial Perspective on Machine Unlearning for AI Safety , January 2025. arXiv:2409.18025 [cs]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.