VL-MemKnG: Hybrid Memory with a Spatio-Temporal Knowledge Graph for Question Answering over Long Egocentric Navigation Trajectories
Pith reviewed 2026-06-27 03:26 UTC · model grok-4.3
The pith
A hybrid memory combining knowledge graph and segment context improves top-1 accuracy on long egocentric navigation questions from 58% to 67%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The discovery is that extending a spatio-temporal knowledge graph with persistent segment-level contextual memory enables a hybrid module to better handle evidence retrieval and reasoning for navigation questions that span long trajectories, resulting in higher retrieval accuracy than graph-only methods or large vision-language models on the proposed benchmark.
What carries the argument
The hybrid retrieval-and-reasoning module that jointly operates over the spatio-temporal knowledge graph and the segment-level contextual memory.
Load-bearing premise
The hybrid retrieval-and-reasoning module can jointly operate over the knowledge graph and segment-level memory to produce evidence-grounded answers without introducing retrieval conflicts or losing efficiency.
What would settle it
Running the hybrid system on the benchmark questions and observing either lower accuracy than the graph-only version or increased query time due to conflicts in retrieved evidence.
Figures




read the original abstract
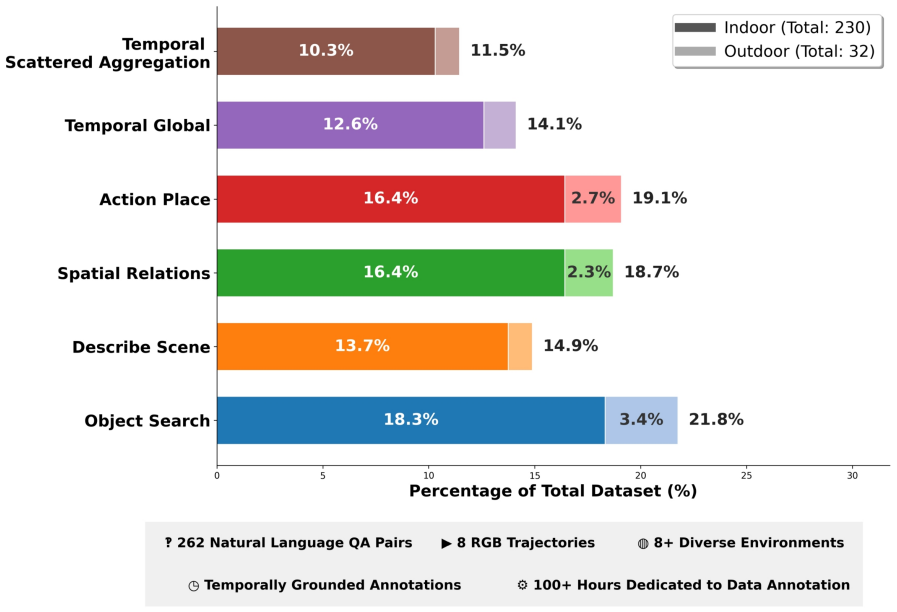
Answering navigation-relevant questions over long egocentric videos requires retrieving and organizing evidence distributed across distant temporal moments while maintaining spatial and contextual consistency. Although long-context vision--language models can achieve strong answer quality, they are computationally expensive for long trajectories and inefficient for repeated querying. Recent graph-based approaches such as VL-KnG address this challenge through persistent spatio-temporal knowledge graphs, but graph-centric retrieval alone may underrepresent broader temporal continuity and contextual cues. We present VL-MemKnG, a hybrid memory framework that extends VL-KnG by combining a spatio-temporal knowledge graph with persistent segment-level contextual memory. The knowledge graph captures structured relational information and long-range object associations, while segment-level memory preserves broader temporal context for long-horizon evidence retrieval. A hybrid retrieval-and-reasoning module jointly operates over both memory representations to produce evidence-grounded answers and temporally organized supporting evidence. We also introduce WalkieKnowledgeT+, an extension of WalkieKnowledge for long-horizon navigation-oriented video question answering. The benchmark includes temporally distributed reasoning tasks requiring evidence aggregation across multiple non-cooccurring moments. On WalkieKnowledgeT+, VL-MemKnG improves Top-1 retrieval accuracy from 58% to 67% and Recall@1 from 34.50% to 40.55%, outperforming all compared methods, including Gemini 2.5 Pro and Qwen 3.5+. The gains are particularly pronounced on temporal-global and temporally scattered aggregation questions, demonstrating the benefits of combining structured relational memory with segment-level contextual memory while maintaining efficient query-time inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VL-MemKnG, a hybrid memory framework extending VL-KnG by combining a spatio-temporal knowledge graph (for structured relational and long-range object information) with persistent segment-level contextual memory (for broader temporal continuity). A hybrid retrieval-and-reasoning module operates jointly over both to answer navigation questions over long egocentric trajectories. The work also presents the WalkieKnowledgeT+ benchmark for temporally distributed reasoning tasks and reports empirical gains on retrieval metrics.
Significance. If the hybrid module can be shown to operate without retrieval conflicts while preserving efficiency, the approach would offer a practical alternative to long-context VLMs for repeated querying on extended navigation videos, with particular value for temporal-global and scattered aggregation questions. The emphasis on persistent memory structures and query-time efficiency is a constructive direction for egocentric video QA in robotics.
major comments (2)
- [Abstract] Abstract: The central performance claims (Top-1 retrieval accuracy rising from 58% to 67%, Recall@1 from 34.50% to 40.55% on WalkieKnowledgeT+) are stated without any experimental protocol, baseline descriptions, dataset statistics, error bars, ablation studies, or controls. This directly blocks verification of whether the reported gains follow from the hybrid retrieval-and-reasoning module or from uncontrolled factors.
- [Abstract] Abstract: No description, pseudocode, or analysis is supplied for the conflict-resolution logic or efficiency properties of the joint operation over the spatio-temporal KG and segment-level memory. This leaves the core assumption that the hybrid module produces evidence-grounded answers without introducing retrieval conflicts or efficiency loss entirely untestable.
minor comments (1)
- [Abstract] Abstract: The citation to VL-KnG is given without a reference entry or explicit differentiation of the new hybrid component from the prior graph-centric method.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the positive assessment of the work's significance for egocentric video QA. We address the two major comments on the abstract point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (Top-1 retrieval accuracy rising from 58% to 67%, Recall@1 from 34.50% to 40.55% on WalkieKnowledgeT+) are stated without any experimental protocol, baseline descriptions, dataset statistics, error bars, ablation studies, or controls. This directly blocks verification of whether the reported gains follow from the hybrid retrieval-and-reasoning module or from uncontrolled factors.
Authors: We agree that the abstract's brevity omits these details. The full manuscript describes the experimental protocol, WalkieKnowledgeT+ benchmark statistics, baselines (including Gemini 2.5 Pro and Qwen 3.5+), ablations, and controls in Sections 4 and 5, with the gains linked to the hybrid module via targeted ablations on temporal-global and scattered questions. To address the concern, we will revise the abstract to briefly note the evaluation setup and main baselines. revision: yes
-
Referee: [Abstract] Abstract: No description, pseudocode, or analysis is supplied for the conflict-resolution logic or efficiency properties of the joint operation over the spatio-temporal KG and segment-level memory. This leaves the core assumption that the hybrid module produces evidence-grounded answers without introducing retrieval conflicts or efficiency loss entirely untestable.
Authors: The manuscript's Method section details the hybrid retrieval-and-reasoning module's joint operation over the KG and segment memory, including prioritization rules that avoid conflicts by favoring structured relations for long-range associations while using segment context for continuity, plus efficiency measurements showing no added latency at query time. No pseudocode is present. We will revise the abstract to include a concise statement on the conflict-free joint operation and preserved efficiency. revision: yes
Circularity Check
No derivation chain or self-referential predictions; purely empirical contribution
full rationale
The paper introduces VL-MemKnG as a hybrid extension of prior graph-based methods (VL-KnG) and a new benchmark WalkieKnowledgeT+, then reports empirical retrieval improvements (Top-1 from 58% to 67%, Recall@1 from 34.50% to 40.55%) against baselines. No equations, derivations, fitted parameters presented as predictions, uniqueness theorems, or ansatzes appear in the text. All claims rest on experimental comparisons rather than any reduction of outputs to inputs by construction. This is a standard empirical methods paper with no detectable circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Zhang, Sixian and Song, Xinhang and Bai, Yubing and Li, Weijie and Chu, Yakui and Jiang, Shuqiang , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[2]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages =
Yokoyama, Naoki and Ha, Sehoon and Batra, Dhruv and Wang, Jiuguang and Bucher, Bernadette , title =. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages =. 2024 , doi =
2024
-
[3]
Vision-and-Language Navigation: Interpreting Visually-Grounded Navigation Instructions in Real Environments , booktitle =
Anderson, Peter and Wu, Qi and Teney, Damien and Bruce, Jake and Johnson, Mark and S. Vision-and-Language Navigation: Interpreting Visually-Grounded Navigation Instructions in Real Environments , booktitle =
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Majumdar, Arjun and Ajay, Anurag and Zhang, Xiaohan and Putta, Pranav and Yenamandra, Sriram and Henaff, Mikael and Silwal, Sneha and Mcvay, Paul and Maksymets, Oleksandr and Arnaud, Sergio and Yadav, Karmesh and Li, Qiyang and Newman, Ben and Sharma, Mohit and Berges, Vincent and Zhang, Shiqi and Agrawal, Pulkit and Bisk, Yonatan and Batra, Dhruv and Kal...
2024
-
[5]
and Fischer, Martin and Malik, Jitendra and Savarese, Silvio , title =
Armeni, Iro and He, Zhi-Yang and Gwak, JunYoung and Zamir, Amir R. and Fischer, Martin and Malik, Jitendra and Savarese, Silvio , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[6]
Proceedings of Robotics: Science and Systems (RSS) , year =
Hughes, Nathan and Chang, Yun and Carlone, Luca , title =. Proceedings of Robotics: Science and Systems (RSS) , year =
-
[7]
IEEE Robotics and Automation Letters , year =
Maggio, Dominic and Chang, Yun and Hughes, Nathan and Trang, Matthew and Griffith, Dan and Dougherty, Carlyn and Cristofalo, Eric and Schmid, Lukas and Carlone, Luca , title =. IEEE Robotics and Automation Letters , year =
-
[8]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Robohop: Segment-based topological map representation for open-world visual navigation , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[9]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[10]
Edge, Darren and Trinh, Ha and Cheng, Newman and Bradley, Joshua and Chao, Alex and Mody, Apurva and Truitt, Steven and Metropolitansky, Dasha and Ness, Robert Osazuwa and Larson, Jonathan , title =
-
[11]
Findings of the Association for Computational Linguistics: ACL 2025 , pages =
NavRAG: Generating User Demand Instructions for Embodied Navigation through Retrieval-Augmented LLM , author =. Findings of the Association for Computational Linguistics: ACL 2025 , pages =. 2025 , address =. doi:10.18653/v1/2025.findings-acl.442 , url =
-
[12]
2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Remembr: Building and reasoning over long-horizon spatio-temporal memory for robot navigation , author=. 2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2025 , organization=
2025
-
[13]
IEEE Transactions on Robotics , volume=
Toward robust robot 3-d perception in urban environments: The ut campus object dataset , author=. IEEE Transactions on Robotics , volume=. 2024 , publisher=
2024
-
[14]
Al Mdfaa, Mohamad and Lukina, Svetlana and Akhtyamov, Timur and Nigmatzyanov, Arthur and Nalberskii, Dmitrii and Zagoruyko, Sergey and Ferrer, Gonzalo , title =
-
[15]
European Conference on Computer Vision , pages=
Videoagent: A memory-augmented multimodal agent for video understanding , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[16]
European Conference on Computer Vision , pages=
Videoagent: Long-form video understanding with large language model as agent , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[17]
Findings of the Association for Computational Linguistics: ACL 2025 , year=
Language Repository for Long Video Understanding , author=. Findings of the Association for Computational Linguistics: ACL 2025 , year=
2025
-
[18]
IEEE Transactions on Circuits and Systems for Video Technology , year =
You, Zeng and Wen, Zhiquan and Chen, Yaofo and Li, Xin and Zeng, Runhao and Wang, Yaowei and Tan, Mingkui , title =. IEEE Transactions on Circuits and Systems for Video Technology , year =
-
[19]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Grounded multi-hop videoqa in long-form egocentric videos , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[20]
Learning Video Representations from Large Language Models , booktitle =
Zhao, Yue and Misra, Ishan and Kr. Learning Video Representations from Large Language Models , booktitle =. 2023 , pages =
2023
-
[21]
Proceedings of the International Conference on Machine Learning (ICML) , year=
Learning Transferable Visual Models From Natural Language Supervision , author=. Proceedings of the International Conference on Machine Learning (ICML) , year=
-
[22]
International Conference on Learning Representations , volume=
Internvid: A large-scale video-text dataset for multimodal understanding and generation , author=. International Conference on Learning Representations , volume=
-
[23]
Comanici, Gheorghe and
-
[24]
Gemini 2.5: Our most intelligent AI model , year =
-
[25]
EgoWalk: A Multimodal Dataset for Robot Navigation in the Wild
Akhtyamov, Timur and Al Mdfaa, Mohamad and Ramirez, Julio Antonio and Bakulin, Sergey and Devchich, German and Fatykhov, Daniil and Mazurov, Anton and Zipa, Konstantin and Mohrat, Mahmoud and Kolesnik, Pavel and others , title =. arXiv preprint arXiv:2505.21282 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Advances in Neural Information Processing Systems , year=
Vgent: Graph-based Retrieval-Reasoning-Augmented Generation For Long Video Understanding , author=. Advances in Neural Information Processing Systems , year=
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Describe anything anywhere at any moment , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Zemskova, Tatiana and Yudin, Dmitry , title=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[29]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Hou, Hao-Yu and Lee, Chun-Yi and Sonogashira, Motoharu and Kawanishi, Yasutomo , title=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[30]
8th Annual Conference on Robot Learning , year=
Mobility vla: Multimodal instruction navigation with long-context vlms and topological graphs , author=. 8th Annual Conference on Robot Learning , year=
-
[31]
2025 , pages=
Kaduri, Omri and Bagon, Shai and Dekel, Tali , booktitle=. 2025 , pages=
2025
-
[32]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
A survey of state of the art large vision language models: Benchmark evaluations and challenges , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[33]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Artificial Intelligence , volume=
Knowledge graphs as tools for explainable machine learning: A survey , author=. Artificial Intelligence , volume=. 2022 , doi=
2022
-
[36]
International Conference on Learning Representations (ICLR) , year=
General Scene Adaptation for Vision-and-Language Navigation , author=. International Conference on Learning Representations (ICLR) , year=
-
[37]
2015 , note =
Robinson, Ian and Webber, Jim and Eifrem, Emil , title =. 2015 , note =
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.