PDAGENT-BENCH: Characterizing, Grounding, and Architecting LLM Agents for VLSI Physical Design
Pith reviewed 2026-06-27 02:08 UTC · model grok-4.3
The pith
PDAGENT-BENCH shows current LLMs handle VLSI conceptual questions well but achieve only 42.2 percent success on Innovus script generation and long-horizon workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that modern LLMs and VLMs perform competitively on conceptual VLSI physical design tasks yet remain substantially limited in tool-centric execution such as Innovus script generation at 42.2 percent success and in long-horizon multi-stage reasoning, while human-skill-enhanced agentic workflows produce significant gains in complete physical design outcomes, all measured through the new PDAGENT-BENCH suite of 353 problems and its unified workflow framework.
What carries the argument
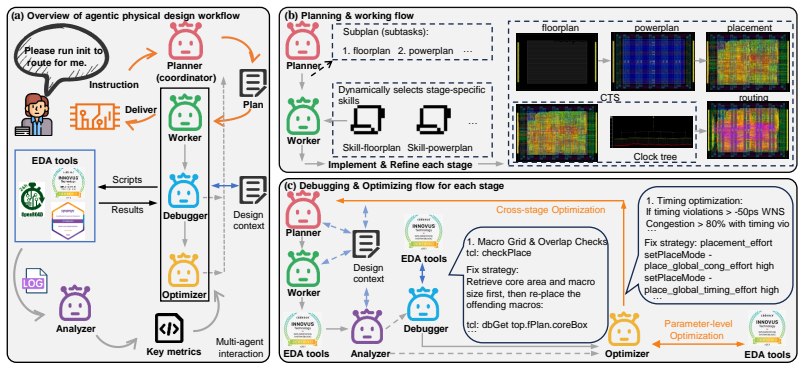
PDAGENT-BENCH, the benchmark that combines 353 curated problems across five capability dimensions with a unified human-aligned agentic physical design workflow framework for closed-loop evaluation inside realistic EDA tool environments.
If this is right
- Models require targeted gains in EDA tool interaction and iterative refinement to close the gap between conceptual understanding and executable physical design.
- Human-skill-enhanced agent workflows provide a measurable near-term route to higher end-to-end physical design quality.
- Performance varies across the five dimensions, with root-cause analysis and script generation showing the largest shortfalls among tested models.
- The benchmark supplies a reproducible yardstick that lets future agents be compared directly on the same set of industrial artifacts.
- Limitations in long-horizon reasoning suggest that single-pass or short-context approaches will continue to underperform on multi-stage design flows.
Where Pith is reading between the lines
- The same problem set could be reused to track whether newer models close the execution gap over successive releases.
- Extending the workflow framework to include visual layout feedback loops might improve handling of geometry-related constraints.
- The benchmark structure could be mirrored for adjacent EDA stages such as logic synthesis or timing closure to create comparable agent evaluations.
- Teams might test whether fine-tuning on the 353 reference solutions lifts script-generation scores without changing the base model architecture.
Load-bearing premise
The 353 curated problems together with their expert-validated references and the unified workflow framework represent typical industrial VLSI physical design challenges, tool interactions, and constraints without large selection bias.
What would settle it
A new model that reaches above 70 percent success on the full-flow implementation tasks using only its own agentic workflow without added human skills would indicate the reported execution limits are not as general as claimed.
Figures

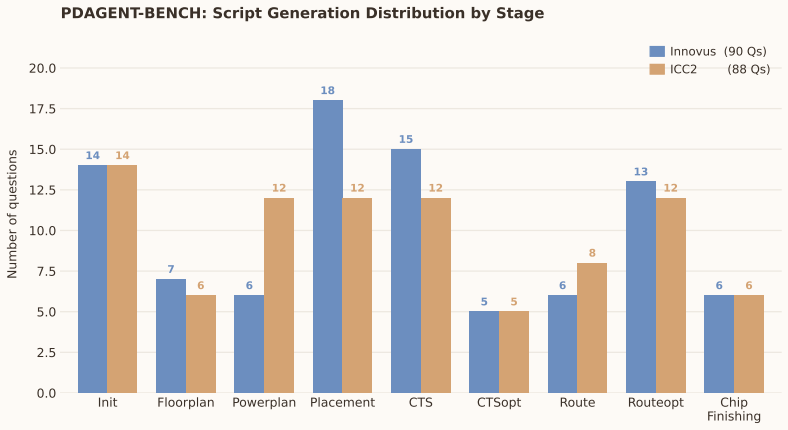



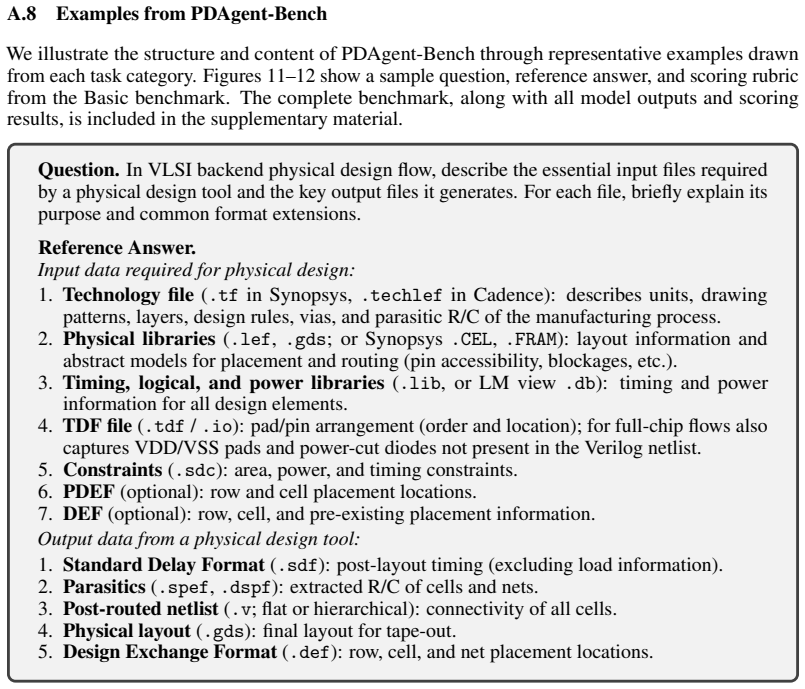
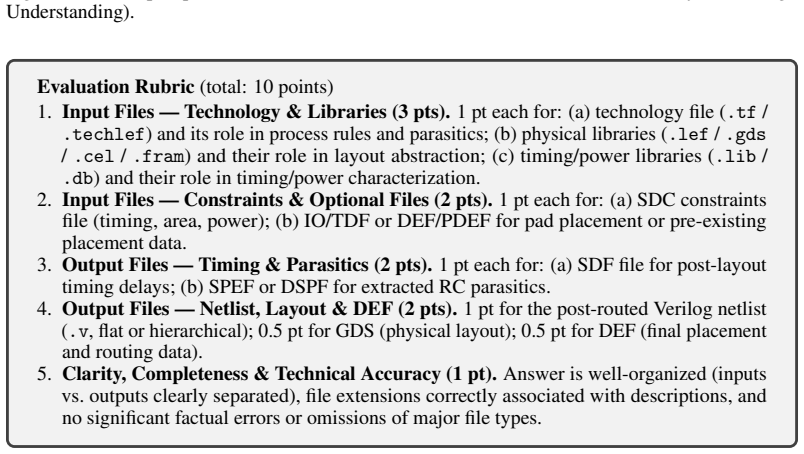
read the original abstract
Large Language Models and vision-language models have shown remarkable success in the front-end design of Very Large-Scale Integrated Circuits, yet their capabilities for VLSI physical design remain significantly underexplored. The primary cause is the lack of standardized benchmarks for evaluating agentic physical design workflows that require high-dimensional, multi-stage optimization under strict design constraints, coordinated interaction with diverse Electronic Design Automation tools, and iterative refinement. This work introduces PDAGENT-BENCH, a comprehensive and multi-dimensional benchmark for evaluating LLM/VLM-based agents across the physical design stack. PDAGENT-BENCH integrates both task-level assessment and workflow-level execution. The benchmark suite contains 353 curated problems that combine conceptual questions with real-world industrial artifacts, with expert-validated references and executable solutions. These tasks cover five key capability dimensions: foundational knowledge, report comprehension, root-cause analysis, script generation, and full-flow implementation. In addition, the benchmark provides a unified, human-aligned agentic physical design workflow framework that enables closed-loop evaluation of holistic physical design in realistic EDA environments. Experiments on 11 state-of-the-art models reveal that while modern LLMs/VLMs perform competitively on conceptual tasks, they remain substantially limited in tool-centric execution (e.g., 42.2% on Innovus script generation) and long-horizon, multi-stage reasoning. Our studies further show that human-skill-enhanced agentic workflows significantly improve end-to-end physical design performance. PDAGENT-BENCH establishes a standardized, reproducible, and realistic evaluation framework for advancing LLM/VLM-driven holistic physical design automation. We will open source the benchmark and framework soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PDAGENT-BENCH, a benchmark with 353 curated problems combining conceptual questions and real-world industrial artifacts for evaluating LLM/VLM agents on VLSI physical design. It defines five capability dimensions (foundational knowledge, report comprehension, root-cause analysis, script generation, full-flow implementation) and a unified agentic workflow framework for closed-loop EDA evaluation. Experiments on 11 models report competitive conceptual performance but limitations in tool-centric tasks (e.g., 42.2% on Innovus script generation) and long-horizon reasoning, with human-skill-enhanced workflows improving end-to-end results. The benchmark and framework are planned for open-sourcing.
Significance. If the benchmark's representativeness holds, the work would provide a valuable standardized, reproducible framework for assessing and advancing LLM-driven physical design automation, filling an underexplored gap in agentic EDA workflows and offering concrete metrics on current model limitations.
major comments (2)
- [Benchmark construction and validation section] The central claims (e.g., 42.2% on Innovus script generation and benefits of human-enhanced workflows) rest on PDAGENT-BENCH accurately representing industrial VLSI challenges, yet the manuscript provides no quantitative evidence—such as distributions of cell counts, layer counts, timing constraints, or tool-call patterns—comparing the 353 problems to typical industrial flows. Expert validation alone does not address potential selection bias. (Benchmark construction and validation section; Abstract)
- [Abstract and Experiments section] The abstract states 'expert-validated references' and reports specific scores, but supplies no details on curation criteria, inter-expert agreement, statistical significance testing, or exclusion rules. This undermines verifiability of the performance claims. (Abstract and Experiments section)
minor comments (2)
- [Experiments section] Clarify whether the 11 models include both LLMs and VLMs and report per-model breakdowns for the five dimensions to strengthen the 'conceptual vs. tool-centric' distinction.
- [Results and discussion] The claim of 'significantly improve end-to-end physical design performance' would benefit from explicit metrics (e.g., timing, power, area deltas) rather than qualitative description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on benchmark validation and verifiability. We address the two major comments point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Benchmark construction and validation section] The central claims (e.g., 42.2% on Innovus script generation and benefits of human-enhanced workflows) rest on PDAGENT-BENCH accurately representing industrial VLSI challenges, yet the manuscript provides no quantitative evidence—such as distributions of cell counts, layer counts, timing constraints, or tool-call patterns—comparing the 353 problems to typical industrial flows. Expert validation alone does not address potential selection bias. (Benchmark construction and validation section; Abstract)
Authors: We agree that quantitative comparisons would strengthen claims of representativeness. The 353 problems are derived from real-world industrial artifacts, with expert validation by VLSI physical design specialists to ensure relevance to industrial challenges. However, due to confidentiality constraints with industry partners, we cannot release full distributions of proprietary metrics such as exact cell counts or timing constraints across all problems. In the revised manuscript, we will add available non-confidential summary statistics on problem characteristics (e.g., ranges of design sizes and constraint types) and expand discussion of curation to mitigate selection bias concerns. revision: partial
-
Referee: [Abstract and Experiments section] The abstract states 'expert-validated references' and reports specific scores, but supplies no details on curation criteria, inter-expert agreement, statistical significance testing, or exclusion rules. This undermines verifiability of the performance claims. (Abstract and Experiments section)
Authors: We acknowledge that the current manuscript lacks sufficient detail on these aspects. The benchmark construction section describes expert validation, but we will revise both the abstract and the dedicated benchmark section to explicitly state curation criteria, report inter-expert agreement metrics (e.g., percentage agreement among validators), detail exclusion rules, and clarify that reported scores are empirical results on the fixed benchmark without additional statistical hypothesis testing, consistent with standard practice in benchmark papers. revision: yes
- Full disclosure of quantitative distributions for all proprietary industrial metrics (e.g., exact cell counts, timing constraints) due to confidentiality agreements.
Circularity Check
No significant circularity
full rationale
The paper introduces PDAGENT-BENCH as an external benchmark consisting of 353 curated problems with expert-validated references, then reports empirical performance of 11 external LLMs/VLMs on those tasks and on human-enhanced workflows. No derivation chain reduces a claimed result to a fitted parameter, self-defined quantity, or self-citation by construction; the evaluations are presented as measurements against independently defined tasks rather than tautological outputs of the benchmark's own construction rules. The central claims rest on observable model behaviors and workflow outcomes, not on any internal redefinition or renaming that would force the reported numbers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five capability dimensions comprehensively cover the requirements for LLM agents in physical design.
Reference graph
Works this paper leans on
-
[1]
Abdelazeem
A. Abdelazeem. Systolic array implementation in RTL for TPU. https://github.com/ abdelazeem201/Systolic-array-implementation-in-RTL-for-TPU , 2021. Accessed: Apr. 2026
2021
-
[2]
Introducing claude opus 4.7, 2026
Anthropic. Introducing claude opus 4.7, 2026. URL https://www.anthropic.com/news/ claude-opus-4-7
2026
-
[3]
Introducing claude sonnet 4.6, 2026
Anthropic. Introducing claude sonnet 4.6, 2026. URL https://www.anthropic.com/news/ claude-sonnet-4-6
2026
-
[4]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Innovus implementation system
Cadence. Innovus implementation system. URL https://www.cadence.com/en_US/home/ tools/digital-design-and-signoff/soc-implementation-and-floorplanning/ innovus-implementation-system.html
-
[6]
C. Chen, X. Xiang, C. Liu, Y . Shang, R. Guo, D. Liu, Y . Lu, Z. Hao, J. Luo, Z. Chen, et al. Xuantie-910: A commercial multi-core 12-stage pipeline out-of-order 64-bit high performance risc-v processor with vector extension: Industrial product. In2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), pages 52–64. IEEE, 2020
2020
-
[7]
Q. Cheng, L. Lin, M. Huang, Q. Li, Z. Yang, L. Dai, H. Yu, Y .-J. Chen, Y . Shi, and M. Hashimoto. A 13-34 tops/w edge-ai processor featuring booth-value-confined accelerator, near-memory 10 computing, and contiguity-aware mapping. In2024 IEEE Asian Solid-State Circuits Conference (A-SSCC), pages 1–3, 2024. doi: 10.1109/A-SSCC60305.2024.10849341
-
[8]
Q. Cheng, Q. Li, W. Dong, M. Zhang, R. Zhang, M. Huang, H. Yu, Y . Shi, H. Awano, T. Sato, L. Lin, and M. Hashimoto. A 22nm resource-frugal hyper-heterogeneous multi-modal system- on-chip towards in-orbit computing. In2025 IEEE Custom Integrated Circuits Conference (CICC), pages 1–3, 2025. doi: 10.1109/CICC63670.2025.10983627
-
[9]
Q. Cheng, Q. Li, Z. Yang, Z. Kong, G. Niu, Y . Liang, J. Li, J. H. Park, W. Liao, H. Awano, T. Sato, L. Lin, and M. Hashimoto. A radiation-hardened neuromorphic imager with self-healing spiking pixels and unified spiking neural network for space robotics. In2025 Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), pages 1–3, 2025. doi...
work page doi:10.23919/vlsitechnologyandcir65189.2025.11075180 2025
-
[10]
Q. Cheng, Z. Yang, H. Li, Q. Li, Z. Kong, G. Niu, Y . Liang, J. Li, J. Yoo, M. Hashimoto, and L. Lin. A radiation-hardened self-healing cmos imager with online pixel/logic annealing and tile-adaptive compression for space applications. In2026 IEEE International Solid-State Circuits Conference (ISSCC), volume 69, pages 390–392, 2026. doi: 10.1109/ISSCC4966...
-
[11]
C.-T. Ho, H. Ren, and B. Khailany. Verilogcoder: Autonomous verilog coding agents with graph-based planning and abstract syntax tree (ast)-based waveform tracing tool. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 300–307, 2025
2025
-
[12]
A. B. Kahng, J. Lienig, I. L. Markov, and J. Hu.VLSI physical design: from graph partitioning to timing closure, volume 312. Springer, 2011
2011
-
[13]
J. Kindér. AES: Verilog implementation of the advanced encryption standard (AES-256). https://github.com/secworks/aes, 2014. Accessed: Apr. 2026
2014
-
[14]
Lavagno, L
L. Lavagno, L. Scheffer, and G. Martin.EDA for IC implementation, circuit design, and process technology. CRC press, 2018
2018
-
[15]
K. Liang. TinyRISC-V: A simple RISC-V core. https://github.com/liangkangnan/ tinyriscv, 2020. Accessed: Apr. 2026
2020
-
[16]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [17]
- [18]
-
[19]
W.-H. Liu, S. Mantik, W.-K. Chow, Y . Ding, A. Farshidi, and G. Posser. Ispd 2019 initial detailed routing contest and benchmark with advanced routing rules. InProceedings of the 2019 international symposium on physical design, pages 147–151, 2019
2019
- [20]
-
[21]
NVDLA: Open source deep learning accelerator
NVIDIA. NVDLA: Open source deep learning accelerator. https://github.com/nvdla/hw,
-
[22]
Ethernet MAC 10/100 Mbps
OpenCores. Ethernet MAC 10/100 Mbps. https://opencores.org/projects/, 2001. Accessed: Apr. 2026
2001
-
[23]
N. Pinckney, C. Batten, M. Liu, H. Ren, and B. Khailany. Revisiting verilogeval: Newer llms, in-context learning, and specification-to-rtl tasks.arXiv preprint arXiv:2408.11053, 2024
-
[24]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Vc formal: Formal verification solution,
Synopsys. Vc formal: Formal verification solution, . URL https://www.synopsys.com/ verification/static-and-formal-verification/vc-formal.html
-
[26]
Ic compiler ii: Place & route solution,
Synopsys. Ic compiler ii: Place & route solution, . URL https://www.synopsys.com/ implementation-and-signoff/physical-implementation/ic-compiler.html
-
[27]
Primetime static timing analysis,
Synopsys. Primetime static timing analysis, . URL https://www.synopsys.com/ implementation-and-signoff/signoff/primetime.html
-
[28]
UART controller IP core
Ultra-Embedded. UART controller IP core. https://github.com/ultraembedded/cores,
-
[29]
M. Wang, Y . Wen, Y . Lu, F. Liu, Y . Zhao, B. Han, J. Mu, Y . Lin, R. Wang, B. Yu, et al. Circuitnet 3.0: A multi-modal dataset with task-oriented augmentation for ai-driven circuit design. InThe Fourteenth International Conference on Learning Representations
- [30]
-
[31]
N. H. Weste and D. Harris.CMOS VLSI design: a circuits and systems perspective. Pearson Education India, 2015
2015
-
[32]
H. Wu, Z. He, X. Zhang, X. Yao, S. Zheng, H. Zheng, and B. Yu. Chateda: A large language model powered autonomous agent for eda.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 43(10):3184–3197, 2024
2024
- [33]
-
[34]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
B. Yu. Machine learning in eda: When and how. In2023 ACM/IEEE 5th Workshop on Machine Learning for CAD (MLCAD), pages 1–6. IEEE, 2023
2023
-
[36]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
G. Zhang, H. Geng, X. Yu, Z. Yin, Z. Zhang, Z. Tan, H. Zhou, Z. Li, X. Xue, Y . Li, et al. The land- scape of agentic reinforcement learning for llms: A survey.arXiv preprint arXiv:2509.02547, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Zheng, W.-L
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[38]
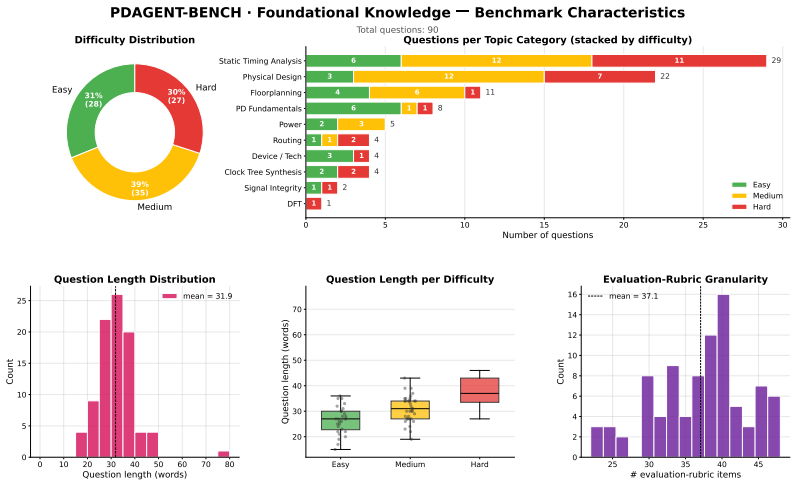
Y . Zhu, D. Huang, H. Lyu, X. Zhang, C. Li, W. Shi, Y . Wu, J. Mu, J. Wang, Y . Zhao, et al. Qimeng-codev-r1: Reasoning-enhanced verilog generation.arXiv preprint arXiv:2505.24183, 2025. 12 Easy 31% (28) Medium 39% (35) Hard30% (27) Difficulty Distribution 0 5 10 15 20 25 30 Number of questions Static Timing Analysis Physical Design Floorplanning PD Funda...
-
[39]
Technology file( .tf in Synopsys, .techlef in Cadence): describes units, drawing patterns, layers, design rules, vias, and parasitic R/C of the manufacturing process
-
[40]
Physical libraries( .lef, .gds; or Synopsys .CEL, .FRAM): layout information and abstract models for placement and routing (pin accessibility, blockages, etc.)
-
[41]
Timing, logical, and power libraries( .lib, or LM view .db): timing and power information for all design elements
-
[42]
5.Constraints(.sdc): area, power, and timing constraints
TDF file( .tdf / .io): pad/pin arrangement (order and location); for full-chip flows also captures VDD/VSS pads and power-cut diodes not present in the Verilog netlist. 5.Constraints(.sdc): area, power, and timing constraints. 6.PDEF(optional): row and cell placement locations. 7.DEF(optional): row, cell, and pre-existing placement information. Output dat...
-
[43]
Input Files — Technology & Libraries (3 pts).1 pt each for: (a) technology file ( .tf / .techlef) and its role in process rules and parasitics; (b) physical libraries (.lef / .gds / .cel / .fram) and their role in layout abstraction; (c) timing/power libraries ( .lib / .db) and their role in timing/power characterization
-
[44]
Input Files — Constraints & Optional Files (2 pts).1 pt each for: (a) SDC constraints file (timing, area, power); (b) IO/TDF or DEF/PDEF for pad placement or pre-existing placement data
-
[45]
Output Files — Timing & Parasitics (2 pts).1 pt each for: (a) SDF file for post-layout timing delays; (b) SPEF or DSPF for extracted RC parasitics
-
[46]
Output Files — Netlist, Layout & DEF (2 pts).1 pt for the post-routed Verilog netlist (.v, flat or hierarchical); 0.5 pt for GDS (physical layout); 0.5 pt for DEF (final placement and routing data)
-
[47]
outputs clearly separated), file extensions correctly associated with descriptions, and no significant factual errors or omissions of major file types
Clarity, Completeness & Technical Accuracy (1 pt).Answer is well-organized (inputs vs. outputs clearly separated), file extensions correctly associated with descriptions, and no significant factual errors or omissions of major file types. Figure 12: Scoring rubric corresponding to Figure 11, used by the LLM-Judge to grade model responses. 21
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.