On the Memorization Behavior of LLMs in Generative Recommendation: Observations, Implications, and Training Strategies
Pith reviewed 2026-06-27 02:27 UTC · model grok-4.3
The pith
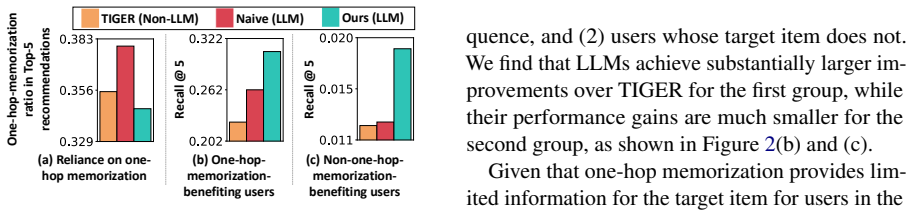
LLMs in generative recommendation achieve most of their gains over baselines through one-hop memorization of training sequences
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
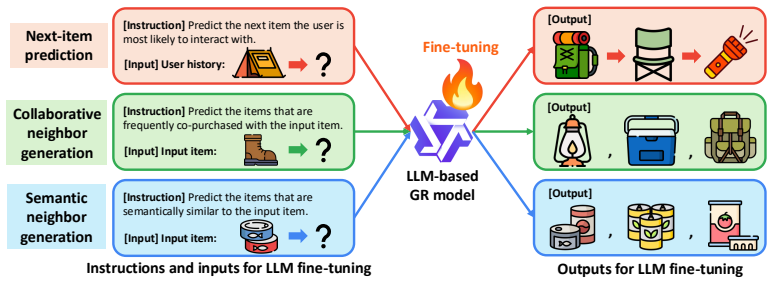
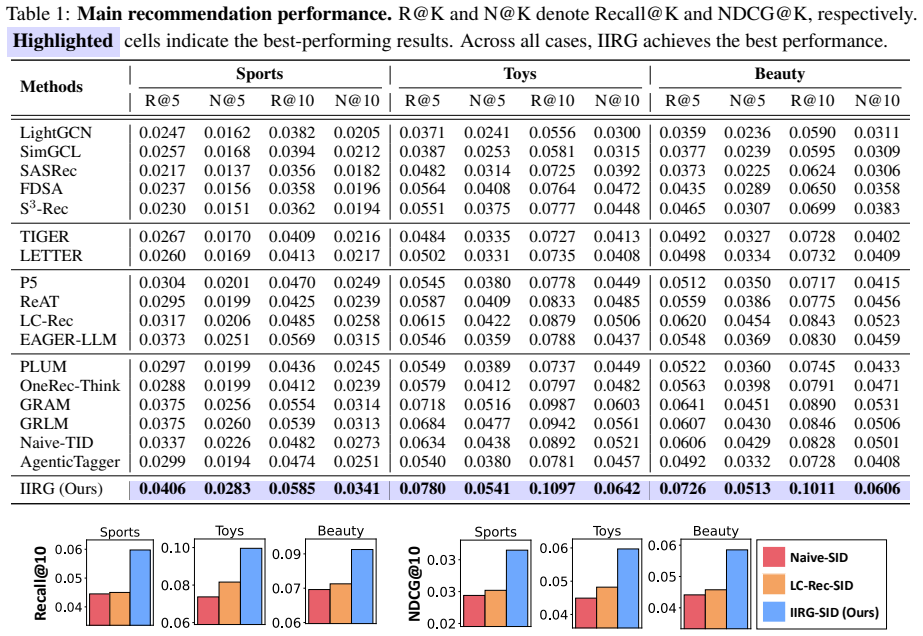
LLMs perform one-hop memorization more than non-LLM generative recommendation models, and the vast majority of their gains over baselines occur on users whose target items can be reached via one-hop transitions from training data. Teaching LLMs richer item-item relations through IIRG, which incorporates collaborative signals from multi-hop co-occurrences across user sequences and semantic relations among thematically similar items, improves results over standard next-item prediction training, with the largest lifts on users outside one-hop coverage.
What carries the argument
IIRG, a training strategy that adds collaborative relations from multi-hop item co-occurrences and semantic relations among similar items as additional signals during fine-tuning
If this is right
- Standard next-item prediction training causes LLMs to favor one-hop memorization over broader generalization.
- IIRG produces higher accuracy than next-item prediction alone, especially on users whose test items lack one-hop predecessors in training.
- Multi-hop co-occurrence and semantic signals can be added to LLM training without changing model architecture.
- Performance gaps on non-memorizable cases can be narrowed by exposing the model to these additional item relations.
Where Pith is reading between the lines
- The same one-hop bias may limit LLM performance in other sequential prediction tasks outside recommendation.
- IIRG-style signals could be tested as a lightweight addition to existing fine-tuning pipelines for sequential models.
- Measuring how IIRG affects memorization on longer sequences or in cross-domain settings would clarify its scope.
Load-bearing premise
One-hop memorization can be isolated as the dominant source of LLM performance gains without other pretrained knowledge or modeling factors explaining the same improvements.
What would settle it
Retraining the same LLMs on data with all one-hop transitions removed and finding that their advantage over non-LLM baselines remains would undermine the claim that one-hop memorization drives most gains.
Figures















read the original abstract
Generative recommendation (GR) has emerged as a promising direction for recommender systems. Recently, large language models (LLMs) have been increasingly adopted for GR, as their rich pretrained knowledge is expected to help them generalize beyond common user behavior patterns that traditional memorization-oriented baselines can capture. However, existing LLM-based GR works largely ignore LLMs' well-known tendency to memorize, which, if present in LLMs fine-tuned for GR, would restrict their utilization of pretrained knowledge. In this work, we investigate this concern by examining one-hop memorization, where a model recommends items that are direct successors of items in the training data. We show that LLMs do this more than non-LLM-based GR models-in fact, the vast majority of their gains over GR baselines are actually on users whose target items can be predicted through one-hop memorization. We intuit that improving performance on the remaining users requires LLMs to learn richer item-item relations beyond one-hop transitions. To achieve this, we propose IIRG, a novel training strategy that teaches LLMs to capture: (1) collaborative relations derived from item co-occurrences across multiple hops in user sequences, and (2) semantic relations among items with similar themes, both of which can serve as useful recommendation signals. We show that IIRG significantly improves over LLMs trained solely with standard next-item prediction, with especially large gains for users whose test items are not covered by train-time one-hop transitions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates one-hop memorization in LLM-based generative recommendation, where models recommend items that are direct successors in training sequences. It claims LLMs exhibit this behavior more than non-LLM GR baselines, with the vast majority of performance gains occurring for users whose test items are covered by such one-hop transitions. The authors propose IIRG, a training strategy that augments next-item prediction with multi-hop collaborative co-occurrences and semantic item relations, reporting significant improvements over standard fine-tuning, especially on users whose test items lack one-hop coverage.
Significance. If the empirical results hold after addressing potential confounds, the work identifies a key limitation in current LLM-GR approaches and supplies a concrete training method to encourage richer item-item relations. This could shift practice toward more generalizable LLM recommenders and prompt further study of memorization versus generalization trade-offs in sequential recommendation.
major comments (2)
- [experimental analysis of one-hop memorization] The user partitioning into one-hop versus non-one-hop groups (described in the experimental analysis of memorization behavior) does not report stratification, matching, or ablation on item popularity, user activity level, or semantic category. This partition is load-bearing for the central claim that LLM gains over GR baselines are driven by one-hop memorization; without such controls the attribution remains vulnerable to confounding.
- [IIRG training strategy and evaluation] The evaluation of IIRG gains on non-one-hop users assumes the added multi-hop and semantic signals improve generalization without new overfitting to training co-occurrences, yet no analysis of train/test overlap on the constructed IIRG signals or ablation removing high-frequency items is provided.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., relative improvement on non-one-hop users) and the primary datasets used.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and outline the revisions we will make to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [experimental analysis of one-hop memorization] The user partitioning into one-hop versus non-one-hop groups (described in the experimental analysis of memorization behavior) does not report stratification, matching, or ablation on item popularity, user activity level, or semantic category. This partition is load-bearing for the central claim that LLM gains over GR baselines are driven by one-hop memorization; without such controls the attribution remains vulnerable to confounding.
Authors: We acknowledge that explicit controls for item popularity, user activity, and semantic category would further isolate the role of one-hop memorization. While the head-to-head comparison with non-LLM GR baselines (trained on identical data) already holds many distributional factors constant, we agree that stratification strengthens the attribution. In the revision we will add results stratified by item popularity quartiles and user activity levels, plus a brief discussion of semantic category balance. These additional tables will show that the concentration of LLM gains on one-hop users persists across strata. revision: yes
-
Referee: [IIRG training strategy and evaluation] The evaluation of IIRG gains on non-one-hop users assumes the added multi-hop and semantic signals improve generalization without new overfitting to training co-occurrences, yet no analysis of train/test overlap on the constructed IIRG signals or ablation removing high-frequency items is provided.
Authors: We agree that verifying the generalization of the IIRG signals is necessary. In the revised manuscript we will report the fraction of multi-hop co-occurrences and semantic relations that appear in the test set, and we will add an ablation that removes or down-weights high-frequency items from the IIRG objective. These analyses will demonstrate that the reported gains on non-one-hop users are not driven by leakage or frequency bias. revision: yes
Circularity Check
No circularity: empirical observational study with no self-referential derivations or fitted predictions.
full rationale
The paper presents an empirical investigation of LLM memorization in generative recommendation via user partitioning on one-hop transitions, followed by a proposed training strategy (IIRG) evaluated through experiments. No mathematical derivation chain, equations, or first-principles results are claimed that reduce to inputs by construction. Claims rest on experimental comparisons (LLM vs. GR baselines, IIRG vs. standard next-item prediction) rather than quantities defined inside the paper or self-citations that bear the central load. The one-hop partition and IIRG signals are defined externally to the results and tested on held-out data, making the work self-contained against external benchmarks with no patterns matching self-definitional, fitted-input, or ansatz-smuggling circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard next-item prediction loss is the baseline training objective for GR
Reference graph
Works this paper leans on
-
[1]
Code and datasets of this work , howpublished =
-
[2]
WWW , year=
Generative large recommendation models: emerging trends in llms for recommendation , author=. WWW , year=
-
[3]
CIKM , year=
Generative Recommendation with Semantic IDs: A Practitioner's Handbook , author=. CIKM , year=
-
[4]
NeurIPS , year=
Recommender systems with generative retrieval , author=. NeurIPS , year=
-
[5]
arXiv preprint arXiv:2510.24431 , year=
Minionerec: An open-source framework for scaling generative recommendation , author=. arXiv preprint arXiv:2510.24431 , year=
-
[6]
ACL , year=
Gram: Generative recommendation via semantic-aware multi-granular late fusion , author=. ACL , year=
-
[7]
WWW , year=
Plum: Adapting pre-trained language models for industrial-scale generative recommendations , author=. WWW , year=
-
[8]
arXiv preprint arXiv:2601.06798 , year=
Unleashing the Native Recommendation Potential: LLM-Based Generative Recommendation via Structured Term Identifiers , author=. arXiv preprint arXiv:2601.06798 , year=
-
[9]
arXiv preprint arXiv:2512.24762 , year=
OpenOneRec Technical Report , author=. arXiv preprint arXiv:2512.24762 , year=
-
[10]
ICDE , year=
Adapting large language models by integrating collaborative semantics for recommendation , author=. ICDE , year=
-
[11]
WWW , year=
Eager-llm: Enhancing large language models as recommenders through exogenous behavior-semantic integration , author=. WWW , year=
-
[12]
RecSys , year=
Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5) , author=. RecSys , year=
-
[13]
NAACL , year=
Aligning large language models with recommendation knowledge , author=. NAACL , year=
-
[14]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[15]
arXiv preprint arXiv:2302.13971 , year=
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
-
[16]
ACL , year=
Generative explore-exploit: Training-free optimization of generative recommender systems using llm optimizers , author=. ACL , year=
-
[17]
EMNLP , year=
LOHRec: Leveraging Order and Hierarchy in Generative Sequential Recommendation , author=. EMNLP , year=
-
[18]
NeurIPS , year=
Attention is all you need , author=. NeurIPS , year=
-
[19]
LREC-COLING , year=
Large language models for generative recommendation: A survey and visionary discussions , author=. LREC-COLING , year=
-
[20]
RecSys , year=
Semantic ids for joint generative search and recommendation , author=. RecSys , year=
-
[21]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[22]
ICDM , year=
Self-attentive sequential recommendation , author=. ICDM , year=
-
[23]
arXiv preprint arXiv:2602.05945 , year=
AgenticTagger: Structured Item Representation for Recommendation with LLM Agents , author=. arXiv preprint arXiv:2602.05945 , year=
-
[24]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 embedding: Advancing text embedding and reranking through foundation models , author=. arXiv preprint arXiv:2506.05176 , year=
-
[25]
IEEE Transactions on Audio, Speech and Language Processing , volume=
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-Tuning , author=. IEEE Transactions on Audio, Speech and Language Processing , volume=
-
[26]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , year=
-
[27]
WWW , year=
Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering , author=. WWW , year=
-
[28]
SIGIR , year=
Lightgcn: Simplifying and powering graph convolution network for recommendation , author=. SIGIR , year=
-
[29]
SIGIR , year=
Are graph augmentations necessary? simple graph contrastive learning for recommendation , author=. SIGIR , year=
-
[30]
, author=
Feature-level deeper self-attention network for sequential recommendation. , author=. IJCAI , year=
-
[31]
CIKM , year=
S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization , author=. CIKM , year=
-
[32]
CIKM , year=
Learnable item tokenization for generative recommendation , author=. CIKM , year=
-
[33]
CVPR , year=
Autoregressive image generation using residual quantization , author=. CVPR , year=
-
[34]
SIGIR , year=
Idgenrec: Llm-recsys alignment with textual id learning , author=. SIGIR , year=
-
[35]
ACL , year=
Llamafactory: Unified efficient fine-tuning of 100+ language models , author=. ACL , year=
-
[36]
ICLR , year=
Decoupled weight decay regularization , author=. ICLR , year=
-
[37]
COLING , year=
Learning transition patterns by large language models for sequential recommendation , author=. COLING , year=
-
[38]
ICML , year=
Actionpiece: Contextually tokenizing action sequences for generative recommendation , author=. ICML , year=
-
[39]
ICLR , year=
Efficient inference for large language model-based generative recommendation , author=. ICLR , year=
-
[40]
WWW , year=
Item-based collaborative filtering recommendation algorithms , author=. WWW , year=
-
[41]
arXiv preprint arXiv:2510.11639 , year=
Onerec-think: In-text reasoning for generative recommendation , author=. arXiv preprint arXiv:2510.11639 , year=
-
[42]
arXiv preprint arXiv:2603.17540 , year=
Deploying Semantic ID-based Generative Retrieval for Large-Scale Podcast Discovery at Spotify , author=. arXiv preprint arXiv:2603.17540 , year=
-
[43]
KDD , year=
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters , author=. KDD , year=
-
[44]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[45]
NeurIPS , year=
Sequence to sequence learning with neural networks , author=. NeurIPS , year=
-
[46]
RecSys , year=
Beyond accuracy: evaluating recommender systems by coverage and serendipity , author=. RecSys , year=
-
[47]
KDD , year=
Inferring networks of substitutable and complementary products , author=. KDD , year=
-
[48]
AAAI , year=
Align ^3 GR: Unified Multi-Level Alignment for LLM-based Generative Recommendation , author=. AAAI , year=
-
[49]
arXiv preprint arXiv:2509.25522 , year=
Understanding generative recommendation with semantic ids from a model-scaling view , author=. arXiv preprint arXiv:2509.25522 , year=
-
[50]
Communications of the ACM , volume=
Shortcut learning of large language models in natural language understanding , author=. Communications of the ACM , volume=. 2023 , publisher=
2023
-
[51]
ICLR , year=
Assessing robustness to spurious correlations in post-training language models , author=. ICLR , year=
-
[52]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Do llms overcome shortcut learning? an evaluation of shortcut challenges in large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[53]
arXiv preprint arXiv:2410.02650 , year=
Undesirable memorization in large language models: A survey , author=. arXiv preprint arXiv:2410.02650 , year=
-
[54]
ACL , year=
Exploring memorization in fine-tuned language models , author=. ACL , year=
-
[55]
arXiv preprint arXiv:2502.01187 , year=
Skewed memorization in large language models: Quantification and decomposition , author=. arXiv preprint arXiv:2502.01187 , year=
-
[56]
Ranaldi, Leonardo and Ruzzetti, Elena Sofia and Zanzotto, Fabio Massimo Angelova, Galia , booktitle =
-
[57]
Journal of Machine Learning Research , volume=
Foundation models and fair use , author=. Journal of Machine Learning Research , volume=
-
[58]
INLG , year=
Preventing generation of verbatim memorization in language models gives a false sense of privacy , author=. INLG , year=
-
[59]
ACL , year=
Deduplicating training data makes language models better , author=. ACL , year=
-
[60]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[61]
arXiv preprint arXiv:2401.04088 , year=
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
-
[62]
EMNLP , year=
An empirical analysis of memorization in fine-tuned autoregressive language models , author=. EMNLP , year=
-
[63]
EMNLP , year=
Preserving privacy through dememorization: An unlearning technique for mitigating memorization risks in language models , author=. EMNLP , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.