Approximation Preserving Coresets
Pith reviewed 2026-06-27 01:54 UTC · model grok-4.3
The pith
Approximation-preserving coresets can be smaller than strong coresets by preserving costs only for near-optimal solutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We define approximation-preserving coresets, which provide a weaker guarantee than strong coresets while providing stronger guarantees than weak coresets. We devise such coresets with sizes smaller than those for strong coresets. We complement this by showing that even a very small distortion in the approximation factor cannot admit coresets of this size.
What carries the argument
The approximation-preserving coreset: a weighted subset Ω of input P such that cost(Ω, S) approximates cost(P, S) only when solution S already has low cost.
If this is right
- Clustering pipelines can safely use smaller sketches when the goal is only to recover near-optimal clusterings.
- The three-way separation between strong, approximation-preserving, and weak coresets quantifies the size cost of each level of guarantee.
- Any attempt to compress below the new bound requires accepting a distorted approximation factor on the preserved solutions.
Where Pith is reading between the lines
- The same relaxation may yield smaller sketches for other optimization problems where only good solutions are relevant in downstream use.
- In streaming or distributed clustering, these coresets could reduce communication while still guaranteeing that the output solution remains near-optimal.
- Empirical checks on real datasets could test whether the cost distortion for bad solutions indeed occurs without harming the quality of recovered solutions.
Load-bearing premise
It suffices to preserve the objective value only for solutions that are already nearly optimal rather than for arbitrary solutions.
What would settle it
An input point set and clustering cost function for which every weighted subset of the claimed small size distorts the cost of at least one near-optimal solution by more than the allowed factor.
Figures

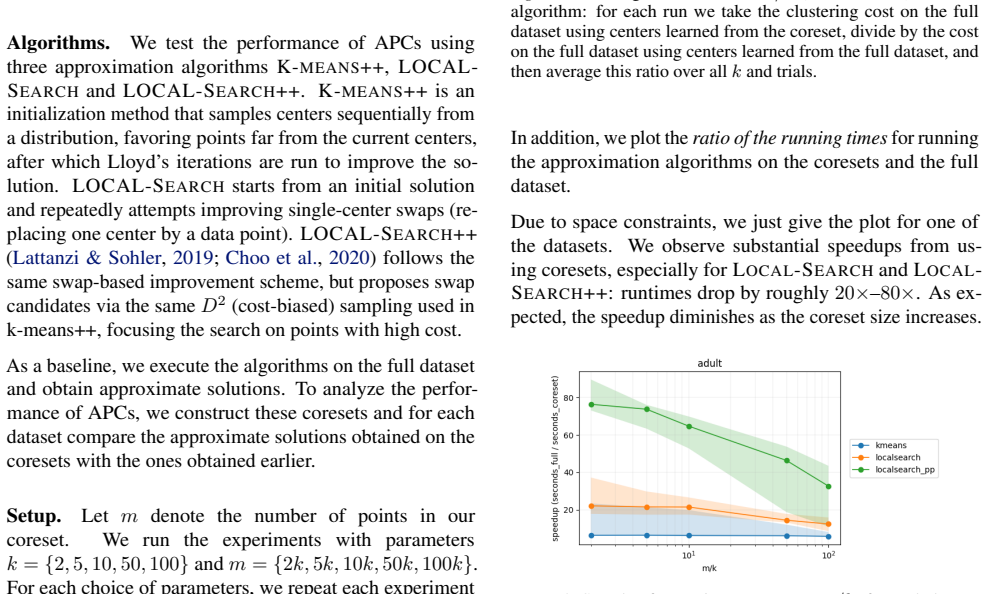
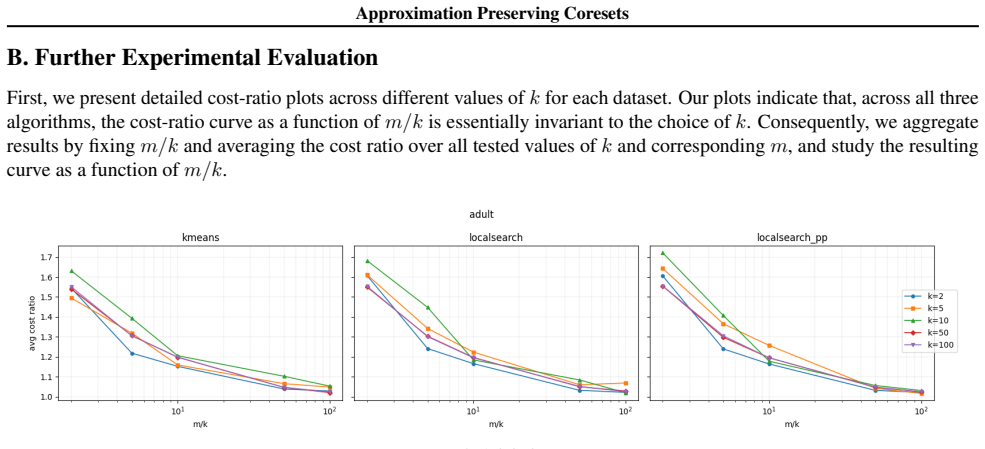
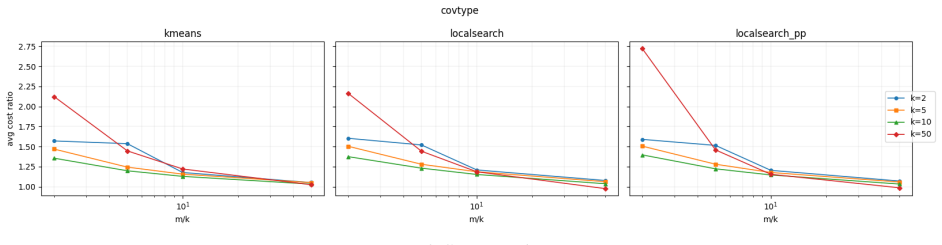


read the original abstract
Clustering in a big data setting is an intensively studied problem, with coresets emerging as one of the important paradigms in this line of work. Given a cost function $\text{cost}(P,S)$ mapping input points $P$ and a solution $S$ to an objective value, a coreset is a typically weighted sketch $\Omega\subseteq P$ such that $\text{cost}(\Omega,S)\approx \text{cost}(P,S)$. In practice, coreset sizes much smaller than those suggested by theoretical guarantees are often found to be sufficient. In this paper, we offer an explanation for this phenomenon. Smaller coreset sizes suffice if we only wish to preserve the costs of \emph{good} solutions, i.e., solutions with low cost. We define and devise \emph{approximation-preserving coresets}, which provide a weaker guarantee than strong coresets, which apply to all solutions, while providing stronger guarantees than weak coresets, which apply only to the optimum solution. We complement this result by showing that even a very small distortion in the approximation factor cannot admit coresets of this size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines approximation-preserving coresets for clustering cost functions, which preserve cost(Ω,S) ≈ cost(P,S) only for solutions S that already have low cost(P,S) (near OPT(P)). This is presented as intermediate between strong coresets (all S) and weak coresets (only the optimum), with constructions provided and a complementary lower bound showing that even small distortion of the approximation factor precludes coresets of the claimed small size. The abstract positions the definition as explaining why very small coresets often suffice in practice.
Significance. If the definition yields usable approximation algorithms, it would provide a formal middle ground that matches observed practical coreset sizes. The lower-bound result is a clear strengthening. Credit is due for formalizing a notion that attempts to capture the 'good solutions only' regime without reducing to parameter fitting.
major comments (2)
- [Abstract] Abstract: the modeling premise that it suffices to preserve costs only for already-near-optimal solutions does not automatically transfer to the standard algorithmic usage (compute S* = argmin cost(Ω,S) and claim it is good for P). A low value of cost(Ω,S*) supplies no a-priori evidence that the precondition cost(P,S*) ≈ OPT(P) holds, so the stated guarantee does not apply to the returned solution.
- [Abstract] Abstract (lower-bound paragraph): the claim that 'even a very small distortion in the approximation factor cannot admit coresets of this size' is load-bearing for the overall contribution, yet the abstract supplies neither the formal statement of the cost function nor a proof sketch; without these it is impossible to verify whether the lower bound is tight against the proposed definition or merely rules out a stronger variant.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the modeling premise that it suffices to preserve costs only for already-near-optimal solutions does not automatically transfer to the standard algorithmic usage (compute S* = argmin cost(Ω,S) and claim it is good for P). A low value of cost(Ω,S*) supplies no a-priori evidence that the precondition cost(P,S*) ≈ OPT(P) holds, so the stated guarantee does not apply to the returned solution.
Authors: We agree that the abstract does not explicitly discuss end-to-end algorithmic deployment. The definition is motivated by explaining observed practical behavior where small coresets suffice for good solutions; in an algorithmic setting the candidate S* obtained from the coreset can be validated on a small independent sample of P (or via other standard techniques) to confirm it is near-optimal before invoking the preservation guarantee. We will revise the abstract to include a short clarifying sentence on this usage model. revision: yes
-
Referee: [Abstract] Abstract (lower-bound paragraph): the claim that 'even a very small distortion in the approximation factor cannot admit coresets of this size' is load-bearing for the overall contribution, yet the abstract supplies neither the formal statement of the cost function nor a proof sketch; without these it is impossible to verify whether the lower bound is tight against the proposed definition or merely rules out a stronger variant.
Authors: The abstract is a concise summary; the formal cost function (standard clustering objectives such as k-means) and the full proof of the lower bound are given in the body of the paper. The lower-bound argument is stated and proved directly for the approximation-preserving definition introduced in the manuscript, showing that even a (1+δ)-distortion of the approximation factor for near-optimal solutions forces super-linear size. No change to the abstract is required, as abstracts routinely omit proof sketches. revision: no
Circularity Check
No circularity: new definition plus lower bound are self-contained
full rationale
The paper defines approximation-preserving coresets explicitly as a weaker notion that preserves costs only for low-cost solutions, then proves existence results and a lower bound on distortion. No equations reduce claimed sizes to fitted parameters, no self-citation chains support the central premise, and no ansatz or renaming is smuggled in. The derivation is direct from the stated definitions and standard coreset constructions adapted to the weaker guarantee; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arthur, D. and Vassilvitskii, S. k-means++: the advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2007, New Orleans, Louisiana, USA, January 7-9, 2007 , pp.\ 1027--1035, 2007. URL http://dl.acm.org/citation.cfm?id=1283383.1283494
arXiv 2007
-
[2]
Local search heuristic for k-median and facility location problems
Arya, V., Garg, N., Khandekar, R., Meyerson, A., Munagala, K., and Pandit, V. Local search heuristic for k-median and facility location problems. In Proceedings of the thirty-third annual ACM symposium on Theory of computing, pp.\ 21--29, 2001
2001
-
[3]
Scalable k -means clustering via lightweight coresets
Bachem, O., Lucic, M., and Krause, A. Scalable k -means clustering via lightweight coresets. In Knowledge Discovery & Data Mining, KDD , pp.\ 1119--1127, 2018. doi:10.1145/3219819.3219973. URL https://doi.org/10.1145/3219819.3219973
-
[4]
Badoiu, M. and Clarkson, K. L. Optimal core-sets for balls. Comput. Geom., 40 0 (1): 0 14--22, 2008. doi:10.1016/j.comgeo.2007.04.002. URL http://dx.doi.org/10.1016/j.comgeo.2007.04.002
-
[5]
Baker, D., Braverman, V., Huang, L., Jiang, S. H. C., Krauthgamer, R., and Wu, X. Coresets for clustering in graphs of bounded treewidth, 2020
2020
-
[6]
Bandyapadhyay, S., Fomin, F. V., and Inamdar, T. Coresets for clustering in geometric intersection graphs. In Chambers, E. W. and Gudmundsson, J. (eds.), 39th International Symposium on Computational Geometry, SoCG 2023, Dallas, Texas, USA, June 12-15, 2023, volume 258 of LIPIcs, pp.\ 10:1--10:16. Schloss Dagstuhl - Leibniz-Zentrum f \" u r Informatik, 20...
-
[7]
Bansal, N., Cohen - Addad, V., Prabhu, M., Saulpic, D., and Schwiegelshohn, C. Sensitivity sampling for k-means: Worst case and stability optimal coreset bounds. In 65th IEEE Annual Symposium on Foundations of Computer Science, FOCS 2024, Chicago, IL, USA, October 27-30, 2024 , pp.\ 1707--1723. IEEE , 2024. doi:10.1109/FOCS61266.2024.00106. URL https://do...
-
[8]
Oblivious dimension reduction for k-means: beyond subspaces and the johnson-lindenstrauss lemma
Becchetti, L., Bury, M., Cohen - Addad, V., Grandoni, F., and Schwiegelshohn, C. Oblivious dimension reduction for k-means: beyond subspaces and the johnson-lindenstrauss lemma. In Symposium on Theory of Computing, STOC , pp.\ 1039--1050, 2019. URL https://doi.org/10.1145/3313276.3316318
-
[9]
Simple and optimal sublinear algorithms for mean estimation
Bertolotti, B., Russo, M., Schwiegelshohn, C., and Shyam, S. Simple and optimal sublinear algorithms for mean estimation. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=9MLfWJZXTn
2026
-
[10]
Coresets for fuzzy k-means with applications
Bl \" o mer, J., Brauer, S., and Bujna, K. Coresets for fuzzy k-means with applications. In Hsu, W., Lee, D., and Liao, C. (eds.), 29th International Symposium on Algorithms and Computation, ISAAC 2018, Jiaoxi, Yilan, Taiwan, December 16-19, 2018 , volume 123 of LIPIcs, pp.\ 46:1--46:12. Schloss Dagstuhl - Leibniz-Zentrum f \" u r Informatik, 2018. doi:10...
-
[11]
H., Krauthgamer, R., and Wu, X
Braverman, V., Jiang, S. H., Krauthgamer, R., and Wu, X. Coresets for clustering in excluded-minor graphs and beyond. CoRR, abs/2004.07718, 2020. Accepted for publication at SODA'21
arXiv 2004
-
[12]
H.-C., Krauthgamer, R., and Wu, X
Braverman, V., Jiang, S. H.-C., Krauthgamer, R., and Wu, X. Coresets for clustering in excluded-minor graphs and beyond. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms (SODA), pp.\ 2679--2696. SIAM, 2021
2021
-
[13]
Braverman, V., Cohen - Addad, V., Jiang, S. H., Krauthgamer, R., Schwiegelshohn, C., Toftrup, M. B., and Wu, X. The power of uniform sampling for coresets. In Symposium on Foundations of Computer Science, FOCS , pp.\ 462--473, 2022. doi:10.1109/FOCS54457.2022.00051. URL https://doi.org/10.1109/FOCS54457.2022.00051
-
[14]
and Krauthgamer, R
Carmel, A. and Krauthgamer, R. Stable coresets: Unleashing the power of uniform sampling. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=sOpAa8iR0A
2026
-
[15]
Carmel, A., Guo, C., Jiang, S. H., and Krauthgamer, R. Coresets for 1-center in _1 metrics. In Meka, R. (ed.), 16th Innovations in Theoretical Computer Science Conference, ITCS 2025, Columbia University, New York, NY, USA, January 7-10, 2025 , LIPIcs, pp.\ 28:1--28:20. Schloss Dagstuhl - Leibniz-Zentrum f \" u r Informatik, 2025. doi:10.4230/LIPICS.ITCS.2...
-
[16]
On coresets for k -median and k-means clustering in metric and E uclidean spaces and their applications
Chen, K. On coresets for k -median and k-means clustering in metric and E uclidean spaces and their applications. SIAM J. Comput. , 39 0 (3): 0 923--947, 2009
2009
-
[17]
k-means++: few more steps yield constant approximation
Choo, D., Grunau, C., Portmann, J., and Rozhon, V. k-means++: few more steps yield constant approximation. In International Conference on Machine Learning, pp.\ 1909--1917. PMLR, 2020
1909
-
[18]
Cohen, M. B., Musco, C., and Musco, C. Input sparsity time low-rank approximation via ridge leverage score sampling. In Klein, P. N. (ed.), Proceedings of the Twenty-Eighth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2017, Barcelona, Spain, Hotel Porta Fira, January 16-19 , pp.\ 1758--1777. SIAM , 2017. doi:10.1137/1.9781611974782.115. URL http...
-
[19]
Tight fpt approximations for k -median and k -means
Cohen-Addad, V., Gupta, A., Kumar, A., Lee, E., and Li, J. Tight fpt approximations for k -median and k -means. arXiv preprint arXiv:1904.12334, 2019
Pith/arXiv arXiv 1904
-
[20]
Improved Dynamic Algorithms for Longest Increasing Subsequence , booktitle =
Cohen - Addad, V., Saulpic, D., and Schwiegelshohn, C. A new coreset framework for clustering. In Symposium on Theory of Computing, STOC , pp.\ 169--182, 2021 a . doi:10.1145/3406325.3451022. URL https://doi.org/10.1145/3406325.3451022
-
[21]
Improved coresets and sublinear algorithms for power means in euclidean spaces
Cohen - Addad, V., Saulpic, D., and Schwiegelshohn, C. Improved coresets and sublinear algorithms for power means in euclidean spaces. In Neural Information Processing Systems, NeurIPS , pp.\ 21085--21098, 2021 b . URL https://proceedings.neurips.cc/paper/2021/hash/b035d6563a2adac9f822940c145263ce-Abstract.html
2021
-
[22]
An improved local search algorithm for k-median
Cohen-Addad, V., Gupta, A., Hu, L., Oh, H., and Saulpic, D. An improved local search algorithm for k-median. In Proceedings of the 2022 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pp.\ 1556--1612. SIAM, 2022
2022
-
[23]
G., Saulpic, D., and Schwiegelshohn, C
Cohen - Addad, V., Larsen, K. G., Saulpic, D., and Schwiegelshohn, C. Towards optimal lower bounds for k-median and k-means coresets. In Symposium on Theory of Computing, STOC , pp.\ 1038--1051, 2022 a . doi:10.1145/3519935.3519946. URL https://doi.org/10.1145/3519935.3519946
-
[24]
G., Saulpic, D., Schwiegelshohn, C., and Sheikh - Omar, O
Cohen - Addad, V., Larsen, K. G., Saulpic, D., Schwiegelshohn, C., and Sheikh - Omar, O. A. Improved coresets for euclidean k-means. In NeurIPS, 2022 b
2022
-
[25]
On small-depth Frege proofs for
Cohen - Addad, V., Saulpic, D., and Schwiegelshohn, C. Deterministic clustering in high dimensional spaces: Sketches and approximation. In 64th IEEE Annual Symposium on Foundations of Computer Science, FOCS 2023, Santa Cruz, CA, USA, November 6-9, 2023 , pp.\ 1105--1130. IEEE , 2023. doi:10.1109/FOCS57990.2023.00066. URL https://doi.org/10.1109/FOCS57990....
-
[26]
A tight vc-dimension analysis of clustering coresets with applications
Cohen - Addad, V., Draganov, A., Russo, M., Saulpic, D., and Schwiegelshohn, C. A tight vc-dimension analysis of clustering coresets with applications. In Azar, Y. and Panigrahi, D. (eds.), Proceedings of the 2025 Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2025, New Orleans, LA, USA, January 12-15, 2025 , pp.\ 4783--4808. SIAM , 2025 a . doi:1...
-
[27]
Almost optimal PAC learning for k-means
Cohen - Addad, V., Lattanzi, S., and Schwiegelshohn, C. Almost optimal PAC learning for k-means. In Kouck \' y , M. and Bansal, N. (eds.), Proceedings of the 57th Annual ACM Symposium on Theory of Computing, STOC 2025, Prague, Czechia, June 23-27, 2025 , pp.\ 2019--2030. ACM , 2025 b . doi:10.1145/3717823.3718180. URL https://doi.org/10.1145/3717823.3718180
-
[28]
Fast approximations and coresets for (k, l)-median under dynamic time warping
Conradi, J., Kolbe, B., Psarros, I., and Rohde, D. Fast approximations and coresets for (k, l)-median under dynamic time warping. CoRR, abs/2312.09838, 2023. doi:10.48550/ARXIV.2312.09838. URL https://doi.org/10.48550/arXiv.2312.09838
-
[29]
Draganov, A., Saulpic, D., and Schwiegelshohn, C. Settling time vs. accuracy tradeoffs for clustering big data. Proc. ACM Manag. Data , 2 0 (3): 0 173, 2024. doi:10.1145/3654976. URL https://doi.org/10.1145/3654976
-
[30]
Feldman, D. Core-sets: An updated survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov., 10 0 (1), 2020. doi:10.1002/widm.1335. URL https://doi.org/10.1002/widm.1335
-
[31]
and Langberg, M
Feldman, D. and Langberg, M. A unified framework for approximating and clustering data. In Symposium on Theory of Computing, STOC , pp.\ 569--578, 2011
2011
-
[32]
A PTAS for k-means clustering based on weak coresets
Feldman, D., Monemizadeh, M., and Sohler, C. A PTAS for k-means clustering based on weak coresets. In Erickson, J. (ed.), Proceedings of the 23rd ACM Symposium on Computational Geometry, Gyeongju, South Korea, June 6-8, 2007 , pp.\ 11--18. ACM , 2007. doi:10.1145/1247069.1247072. URL https://doi.org/10.1145/1247069.1247072
-
[33]
Turning big data into tiny data: Constant-size coresets for k-means, pca, and projective clustering
Feldman, D., Schmidt, M., and Sohler, C. Turning big data into tiny data: Constant-size coresets for k-means, pca, and projective clustering. SIAM J. Comput. , 49 0 (3): 0 601--657, 2020. doi:10.1137/18M1209854. URL https://doi.org/10.1137/18M1209854
-
[34]
and Sohler, C
Frahling, G. and Sohler, C. Coresets in dynamic geometric data streams. In Proceedings of the 37th Annual ACM Symposium on Theory of Computing ( STOC ) , pp.\ 209--217, 2005
2005
-
[35]
and Kushal, A
Har - Peled, S. and Kushal, A. Smaller coresets for k-median and k-means clustering. Discrete & Computational Geometry , 37 0 (1): 0 3--19, 2007
2007
-
[36]
and Mazumdar, S
Har - Peled, S. and Mazumdar, S. On coresets for k-means and k-median clustering. In Symposium on Theory of Computing, STOC , pp.\ 291--300, 2004
2004
-
[37]
Hoeffding, W. Probability inequalities for sums of bounded random variables. Journal of the American Statistical Association, 58 0 (301): 0 13--30, 1963. doi:10.1080/01621459.1963.10500830
-
[38]
Huang, L. and Vishnoi, N. K. Coresets for clustering in euclidean spaces: importance sampling is nearly optimal. In Symposium on Theory of Computing, STOC 2020 , 2020. doi:10.1145/3357713.3384296. URL https://doi.org/10.1145/3357713.3384296
-
[39]
Epsilon-coresets for clustering (with outliers) in doubling metrics
Huang, L., Jiang, S., Li, J., and Wu, X. Epsilon-coresets for clustering (with outliers) in doubling metrics. In 59th IEEE Annual Symposium on Foundations of Computer Science, FOCS 2018, Paris, France, October 7-9, 2018 , pp.\ 814--825, 2018. doi:10.1109/FOCS.2018.00082. URL https://doi.org/10.1109/FOCS.2018.00082
-
[40]
Huang, L., Sudhir, K., and Vishnoi, N. K. Coresets for time series clustering. In Neural Information Processing Systems, NeurIPS , pp.\ 22849--22862, 2021. URL https://proceedings.neurips.cc/paper/2021/hash/c115ba9e04ab27fbbb664f932112246d-Abstract.html
2021
-
[41]
On optimal coreset construction for euclidean (k, z)-clustering
Huang, L., Li, J., and Wu, X. On optimal coreset construction for euclidean (k, z)-clustering. In Mohar, B., Shinkar, I., and O'Donnell, R. (eds.), Proceedings of the 56th Annual ACM Symposium on Theory of Computing, STOC 2024, Vancouver, BC, Canada, June 24-28, 2024 , pp.\ 1594--1604. ACM , 2024. doi:10.1145/3618260.3649707. URL https://doi.org/10.1145/3...
-
[42]
Applications of weighted voronoi diagrams and randomization to variance-based k-clustering (extended abstract)
Inaba, M., Katoh, N., and Imai, H. Applications of weighted voronoi diagrams and randomization to variance-based k-clustering (extended abstract). In Proceedings of the Tenth Annual Symposium on Computational Geometry, Stony Brook, New York, USA, June 6-8, 1994, pp.\ 332--339, 1994
1994
-
[43]
Jaiswal, R. and Kumar, A. Universal weak coreset. In Wooldridge, M. J., Dy, J. G., and Natarajan, S. (eds.), Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, Febru...
-
[44]
M., Netanyahu, N
Kanungo, T., Mount, D. M., Netanyahu, N. S., Piatko, C. D., Silverman, R., and Wu, A. Y. A local search approximation algorithm for k-means clustering. In Proceedings of the eighteenth annual symposium on Computational geometry, pp.\ 10--18, 2002
2002
-
[45]
Langberg, M. and Schulman, L. J. Universal -approximators for integrals. In Symposium on Discrete Algorithms, SODA , pp.\ 598--607, 2010. doi:10.1137/1.9781611973075.50. URL http://dx.doi.org/10.1137/1.9781611973075.50
-
[46]
and Sohler, C
Lattanzi, S. and Sohler, C. A better k-means++ algorithm via local search. In Chaudhuri, K. and Salakhutdinov, R. (eds.), International Conference on Machine Learning, ICML , volume 97, pp.\ 3662--3671, 2019
2019
-
[47]
Least squares quantization in pcm
Lloyd, S. Least squares quantization in pcm. IEEE transactions on information theory, 28 0 (2): 0 129--137, 1982
1982
-
[48]
and Schwiegelshohn, C
Munteanu, A. and Schwiegelshohn, C. Coresets-methods and history: A theoreticians design pattern for approximation and streaming algorithms. K \" u nstliche Intell. , 32 0 (1): 0 37--53, 2018
2018
-
[49]
Schwiegelshohn, C. and Sheikh - Omar, O. A. An empirical evaluation of k-means coresets. In Chechik, S., Navarro, G., Rotenberg, E., and Herman, G. (eds.), 30th Annual European Symposium on Algorithms, ESA 2022, Berlin/Potsdam, Germany, September 5-9, 2022 , volume 244 of LIPIcs, pp.\ 84:1--84:17. Schloss Dagstuhl - Leibniz-Zentrum f \" u r Informatik, 20...
-
[50]
Woodruff, D. P. and Yasuda, T. Coresets for multiple _p regression. In Salakhutdinov, R., Kolter, Z., Heller, K. A., Weller, A., Oliver, N., Scarlett, J., and Berkenkamp, F. (eds.), Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 , Proceedings of Machine Learning Research, pp.\ 53202--53233. PMLR / Op...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.