Complex Layout Classification in the Wild: A Low-Resource Approach with Layout-Preserving Augmentations
Pith reviewed 2026-06-27 02:55 UTC · model grok-4.3
The pith
Layout-specific augmentations let a CNN classify complex page layouts accurately even when labeled examples are scarce.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
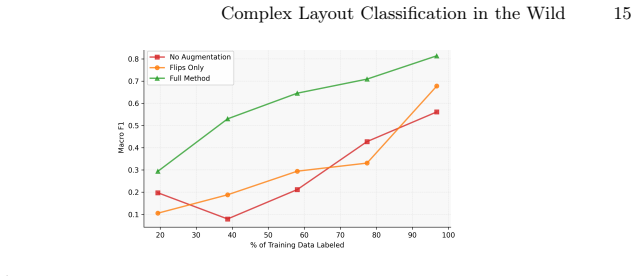
A CNN trained with narrow anisotropic Gaussian masking to hide incidental text and reflection-induced label transformations achieves substantially higher accuracy on eight-class page layout classification when annotation counts are low, because the model is forced to learn global geometric arrangements rather than local textual details.
What carries the argument
Layout-preserving augmentations consisting of narrow anisotropic Gaussian masking to suppress text while retaining separators, together with reflection-induced label transformations that maintain consistency for asymmetric categories.
If this is right
- The model learns to rely on global geometric structure instead of incidental textual content.
- Training data can be enriched without breaking label consistency across the eight layout types.
- Performance gains appear specifically under severe annotation scarcity rather than only with abundant data.
- The same masking and reflection steps can be applied to other page-level tasks that depend on separator geometry.
Where Pith is reading between the lines
- The same augmentations could be tested on non-CNN architectures to check whether the benefit is tied to convolutional feature extraction.
- The method might reduce annotation effort for layout analysis in additional languages or document genres beyond the curated set.
- If separator regions prove less reliable in some corpora, the masking step could be adapted to other structural cues such as column boundaries.
Load-bearing premise
The eight manually assigned layout classes based on separator regions correctly capture the distinctions that matter for downstream tasks, and the augmentations preserve those distinctions without adding label noise or shifting the data distribution.
What would settle it
If a CNN trained with only standard augmentations reaches the same accuracy as the proposed layout-preserving versions on a held-out test set of the same size and scarcity level, the claim that these specific augmentations drive the improvement would not hold.
Figures







read the original abstract
Many digitized corpora suffer from low resources because annotations may be scarce, page scans are noisy and of poor resolution, or layouts are structurally complex in ways that negatively affect the quality of automatic transcription. Developing robust classification models for low-resource languages is inhibited by the lack of large-scale annotated data and by the frequent semantic complexity of page layouts. To this end, we have curated a complex-layout dataset, manually classified into eight distinct layout types based on their separator regions. To overcome data scarcity, we propose a novel training strategy in the form of a CNN-based classifier that employs strong, domain-aware augmentations to improve generalization. We utilize narrow anisotropic Gaussian masking to suppress incidental textual details while preserving essential separations, compelling the model to learn global geometric arrangements. Additionally, we implement reflection-induced label transformations to enrich the training distribution while maintaining label consistency across asymmetric categories. The results demonstrate that layout-specific augmentations can substantially improve page-level layout classification under severe annotation scarcity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper curates an eight-class dataset of complex page layouts labeled manually by separator regions and proposes a CNN classifier trained with two layout-preserving augmentations—narrow anisotropic Gaussian masking to emphasize global geometry over text details, and reflection-induced label transformations to expand the training distribution—claiming that these domain-aware techniques substantially improve page-level layout classification accuracy under severe annotation scarcity.
Significance. If the empirical gains hold after verification of label fidelity, the work would offer a practical, low-cost strategy for bootstrapping layout classifiers in noisy, low-resource digitized corpora, with potential transfer to other document analysis tasks where separator geometry is the primary discriminative cue.
major comments (2)
- [Augmentation strategy] Augmentation section: the assertion that reflection-induced label transformations 'maintain label consistency across asymmetric categories' is presented without any supporting verification (e.g., manual re-labeling of reflected samples, ablation on label-flip rate, or comparison of separator geometry before/after reflection); because the eight classes are defined by separator configuration, any geometry change that crosses class boundaries would inject label noise and invalidate the reported accuracy improvements.
- [Experimental results] Results section: no quantitative details (dataset cardinality, train/test split sizes, baseline accuracies, ablation tables, or error bars) are referenced in the provided text, making it impossible to assess whether the claimed 'substantial improvement' exceeds what would be expected from standard augmentations or from label noise alone.
minor comments (2)
- [Abstract] The abstract and introduction should explicitly state the total number of annotated pages and the severity of the scarcity (e.g., samples per class) so readers can judge the low-resource regime.
- [Dataset curation] Notation for the eight layout classes and the precise definition of 'separator regions' used for manual labeling should be formalized, perhaps with a figure or table, to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the two major comments point-by-point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Augmentation strategy] Augmentation section: the assertion that reflection-induced label transformations 'maintain label consistency across asymmetric categories' is presented without any supporting verification (e.g., manual re-labeling of reflected samples, ablation on label-flip rate, or comparison of separator geometry before/after reflection); because the eight classes are defined by separator configuration, any geometry change that crosses class boundaries would inject label noise and invalidate the reported accuracy improvements.
Authors: We agree that the current manuscript presents the claim without explicit empirical verification. While the reflections were selected to preserve separator configurations defining each class (e.g., avoiding flips that would map one separator pattern to another), this was based on design rationale rather than post-hoc checks. In the revision we will add: (i) manual re-labeling results on 100 reflected samples, (ii) an ablation varying reflection probability with corresponding accuracy impact, and (iii) side-by-side geometry visualizations. These additions will directly address the risk of label noise. revision: yes
-
Referee: [Experimental results] Results section: no quantitative details (dataset cardinality, train/test split sizes, baseline accuracies, ablation tables, or error bars) are referenced in the provided text, making it impossible to assess whether the claimed 'substantial improvement' exceeds what would be expected from standard augmentations or from label noise alone.
Authors: The referee is correct that the provided text (and the current manuscript) does not include these quantitative details. We will revise the Results section to report dataset cardinality (total pages and per-class counts), explicit train/test splits, baseline accuracies without the proposed augmentations, full ablation tables, and error bars from repeated runs. This will enable direct evaluation of the gains relative to standard methods and potential label noise. revision: yes
Circularity Check
No circularity: purely empirical augmentation proposal with no derivation chain
full rationale
The paper curates a dataset, defines eight layout classes by manual separator inspection, proposes two families of domain-specific augmentations (anisotropic Gaussian masking and reflection-induced label transformations), trains a CNN, and reports accuracy gains under data scarcity. No equations, fitted parameters, uniqueness theorems, or self-citations appear in the provided text. The central claim is an empirical statement about augmentation effectiveness; it does not reduce any prediction or result to its own inputs by construction. The reader's circularity score of 1.0 is consistent with this assessment.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ICDAR
Antonacopoulos, A., Bridson, D., Papadopoulos, C., Pletschacher, S.: A realistic dataset for performance evaluation of document layout analysis. In: ICDAR. pp. 296–300 (2009) Complex Layout Classification in the Wild 17
2009
-
[2]
In: ICFHR (2022)
Cheng, H., Jian, C., Wu, S., Jin, L.: SCUT-CAB: A new benchmark dataset of ancient Chinese books with complex layouts for document layout analysis. In: ICFHR (2022)
2022
-
[3]
In: CVPR
Cheng, H., Zhang, P., Wu, S., Zhang, J., Zhu, Q., Xie, Z., Li, J., Ding, K., Jin, L.: M6Doc: A large-scale multi-format, multi-type, multi-layout, multi-language, multi-annotation category dataset for modern document layout analysis. In: CVPR. pp. 15138–15147 (Jun 2023)
2023
-
[4]
Magazén: Intl
Gogawale, S., Bambaci, L., Kurar-Barakat, B., Vasyutinsky Shapira, D., Stökl Ben Ezra, D., Dershowitz, N.: NetLay: Layout classification dataset for enhancing layout analysis. Magazén: Intl. J. for Digital and Public Humanities5, 1–14 (2024)
2024
-
[5]
In: SIGIR ’21
Hamdi, A., Linhares Pontes, E., Boros, E., Nguyen, T.T.H., Hackl, G., Moreno, J.G.,Doucet,A.:Amultilingualdatasetfornamedentityrecognition,entitylinking and stance detection in historical newspapers. In: SIGIR ’21. pp. 2328–2334 (2021)
2021
-
[6]
In: 8th Intl
Josi, F., Wartena, C., Heid, U.: Preparing legal documents for NLP analysis: Im- proving the classification of text elements by using page features. In: 8th Intl. Conf. on Natural Language Processing (NATP). vol. 12 (Jan 2022)
2022
-
[7]
In: ICDAR
Lee, J., Hayashi, H., Ohyama, W., Uchida, S.: Page segmentation using a con- volutional neural network with trainable co-occurrence features. In: ICDAR. pp. 1023–1028 (2019)
2019
-
[8]
In: CVPR (2022)
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A ConvNet for the 2020s. In: CVPR (2022)
2022
-
[9]
In: KDD ’22
Pfitzmann, B., Auer, C., Dolfi, M., Nassar, A.S., Staar, P.W.J.: DocLayNet: A large human-annotated dataset for document-layout segmentation. In: KDD ’22. pp. 3743–3751 (2022)
2022
-
[10]
In: ICDAR
Saha, R., Mondal, A., Jawahar, C.V.: Graphical object detection in document images. In: ICDAR. pp. 51–58 (2019)
2019
-
[11]
Applied Sciences15(6) (2025)
Santos Júnior, E.S.d., Paixão, T., Alvarez, A.B.: Comparative performance of YOLOv8, YOLOv9, YOLOv10, and YOLOv11 for layout analysis of historical documents images. Applied Sciences15(6) (2025)
2025
-
[12]
In: CVPR Workshops
Shen, Z., Zhang, K., Dell, M.: A large dataset of historical Japanese documents with complex layouts. In: CVPR Workshops. pp. 2336–2343 (Jun 2020)
2020
-
[13]
In: ICFHR
Simistira,F.,Seuret,M.,Eichenberger,N.,Garz,A.,Liwicki,M.,Ingold,R.:DIVA- HisDB: A precisely annotated large dataset of challenging medieval manuscripts. In: ICFHR. pp. 471–476 (2016)
2016
-
[14]
Classics@ Journal18(2021)
Stokes, P., Kiessling, B., Stökl Ben Ezra, D., Tissot, R., Gargem, E.H.: The eS- criptorium VRE for manuscript cultures. Classics@ Journal18(2021)
2021
-
[15]
In: CVPR
Yang, X., Yumer, E., Asente, P., Kraley, M., Kifer, D., Giles, C.L.: Learning to extract semantic structure from documents using multimodal fully convolutional neural networks. In: CVPR. pp. 4342–4351 (2017)
2017
-
[16]
In: VRHCIAI
Zhang, C., Ibrayim, M., Hamdulla, A.: A methodological study of document layout analysis. In: VRHCIAI. pp. 12–17 (2022)
2022
-
[17]
In: ICDAR
Zhong, X., Tang, J., Yepes, A.J.: PubLayNet: largest dataset ever for document layout analysis. In: ICDAR. pp. 1015–1022 (Sep 2019)
2019
-
[18]
In: ICDAR
Zottin, S., De Nardin, A., Branca, G., Piciarelli, C., Foresti, G.L.: ICDAR 2025 competition on few-shot text line segmentation of ancient handwritten documents (FEST). In: ICDAR. pp. 586–602. Cham (2026)
2025
-
[19]
Zottin, S., De Nardin, A., Colombi, E., Piciarelli, C., Pavan, F., Foresti, G.L.: U- DIADS-Bib: A full and few-shot pixel-precise dataset for document layout analysis of ancient manuscripts. Neural Comput. Appl.36(20), 11777–11789 (Jan 2024). https://doi.org/10.1007/s00521-023-09356-5
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.