OTRO: Oblivious Tokenization Path with Square-Root ORAM
Pith reviewed 2026-06-27 02:49 UTC · model grok-4.3
The pith
OTRO makes LLM tokenizers oblivious using replicated square-root ORAM instances, epoch rotation, and KV-cache chunking to limit TTFT overhead to 4.5%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
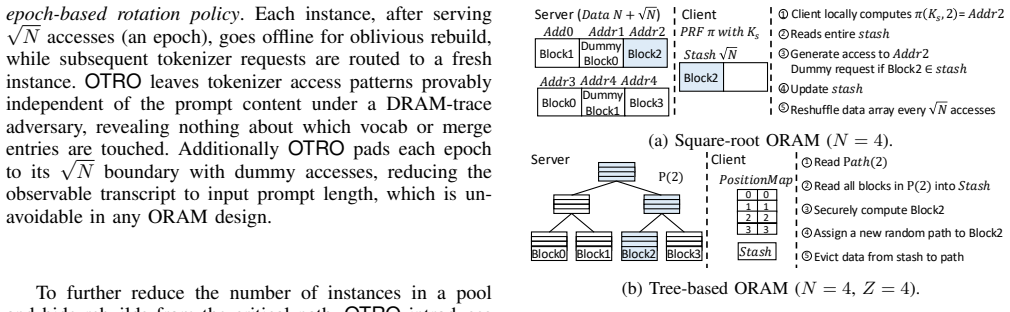
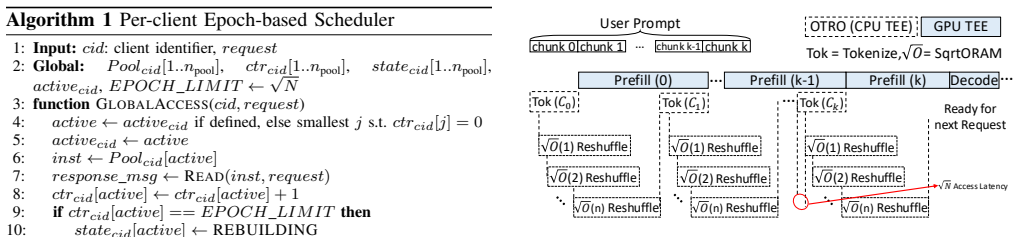
OTRO supplies an oblivious tokenization path by maintaining a pool of replicated square-root ORAM instances on the read-only tokenizer table, applying an epoch-based rotation policy that pads each epoch to its boundary with dummy accesses, and performing chunked KV-cache-aware tokenization that overlaps rebuilds with GPU prefill; when implemented in HuggingFace Tokenizers and nano-vLLM inside a TDX CVM on H100, the design bounds TTFT overhead at 4.5%, tokenizer latency below 10% of TTFT, and memory growth below 0.5 GB while lowering leakage.
What carries the argument
Pool of replicated square-root ORAM instances with epoch-based rotation and dummy padding, which decouples accesses from rebuilds by exploiting the tokenizer table's read-only property and KV-cache chunking.
If this is right
- Tokenizer access patterns cease to leak prompt content under the TEE threat model.
- TTFT increases by at most 4.5% while tokenizer work stays under 10% of total TTFT.
- Memory footprint grows by less than 0.5 GB across tested model sizes.
- The same modules integrate directly into existing HuggingFace and vLLM code paths.
- Leakage reduction holds across multiple model families and sizes without per-model tuning.
Where Pith is reading between the lines
- The replication technique could extend to any read-only lookup table whose updates are infrequent or centrally managed.
- Epoch padding length could be tuned per security policy to trade dummy overhead for lower information leakage.
- The chunking strategy may generalize to other GPU-CPU overlapped stages beyond KV-cache construction.
- If tokenizer tables ever become writable, a lightweight consistency protocol would be needed before replication remains safe.
Load-bearing premise
The tokenizer table is strictly read-only, so replicated ORAM instances never require consistency maintenance or extra rebuilds.
What would settle it
A side-channel experiment in the same TDX-plus-H100 setup that recovers a non-negligible fraction of prompts from OTRO-protected access patterns, or a timing measurement showing TTFT overhead above 4.5% under the reported model families and batch sizes.
Figures






read the original abstract
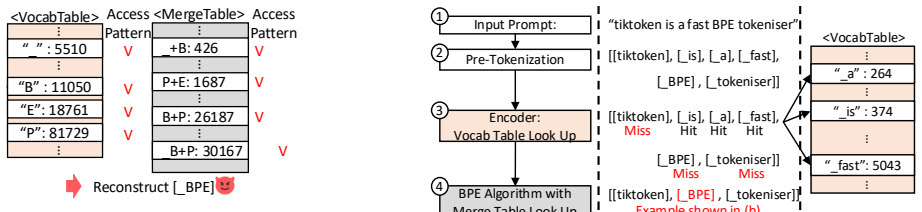
The CPU-side large language model (LLM) tokenizer is a critical security gap in LLM serving through a confidential computing stack with CPU and GPU trusted execution environments (TEEs). Tokenizers converts the prompts through table-driven lookups, and the resulting memory access patterns are a powerful source of side-channel leakage. Recent work demonstrates end-to-end recovery of user prompts from tokenizer access pattern on production Intel TDX. However, a drop-in use of the popular tree-based Oblivious RAMs (e.g., PathORAM) to prevent access-pattern leakage introduces $\sim$13$\times$ tokenizer slowdown, resulting in 10-58% higher time-to-first-token (TTFT). In this paper, we present OTRO, an efficient, oblivious tokenization path tailored to latency-critical LLM serving. OTRO relies on square-root ORAM for fast single-access lookups, but avoids its prohibitive $O(N\log^2N$) rebuild cost every $\sqrt{N}$ accesses through three key innovations. First, OTRO provides a pool of replicated square-root ORAM instances that utilize the read-only nature of tokenizer table. Second, an epoch-based rotation policy decouples accesses from rebuilds and pads each epoch with dummy accesses to its boundaries, minimizing observable information. Lastly, chunked KV-cache-aware tokenization further overlaps rebuilds with GPU prefill and minimizes the instance count. Implemented as modules in HuggingFace Tokenizers and nano-vLLM, running within a TDX-enabled CVM with an NVIDIA H100 GPU, OTRO limits TTFT overhead to at most 4.5%, keeps tokenizer-induced latency under 10\% of total TTFT, and adds less than 0.5 GB of memory overhead while reducing the tokenizer's observable leakage across various model families and sizes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OTRO, an oblivious tokenization scheme for LLM serving in confidential computing (TDX + GPU TEEs) that uses square-root ORAM with a pool of replicated instances, epoch-based rotation plus dummy padding, and chunked KV-cache-aware tokenization to avoid the O(N log²N) rebuild cost. It claims concrete performance bounds (≤4.5% TTFT overhead, tokenizer latency <10% of TTFT, <0.5 GB memory overhead) while reducing observable leakage, with an implementation in HuggingFace Tokenizers and nano-vLLM evaluated on an NVIDIA H100 inside a TDX CVM across model families.
Significance. If the overhead bounds and leakage reduction hold under the stated assumptions, the work is significant for closing a demonstrated side-channel in production LLM tokenizers without prohibitive latency cost. The concrete implementation in real tokenization and serving libraries plus hardware evaluation on H100/TDX is a strength that makes the result directly usable.
major comments (2)
- [Abstract] Abstract and design description: the claimed TTFT overhead (≤4.5%), memory (<0.5 GB), and rebuild avoidance all rest on maintaining a pool of replicated square-root ORAM instances without consistency or rebuild costs. This is explicitly justified by “utiliz[ing] the read-only nature of tokenizer table.” No mechanism, analysis, or fallback is provided for vocabulary extension, per-user custom tokenizers, or multi-tenant updates; any write would invalidate the replication premise and the reported bounds.
- [Abstract] Abstract: concrete overhead numbers (4.5% TTFT, <10% tokenizer share, <0.5 GB) are stated without reference to evaluation methodology, baselines, number of runs, or error bars. The reader cannot assess whether the numbers reflect post-hoc selection, specific prompt distributions, or measurement artifacts.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity on assumptions and evaluation details.
read point-by-point responses
-
Referee: [Abstract] Abstract and design description: the claimed TTFT overhead (≤4.5%), memory (<0.5 GB), and rebuild avoidance all rest on maintaining a pool of replicated square-root ORAM instances without consistency or rebuild costs. This is explicitly justified by “utiliz[ing] the read-only nature of tokenizer table.” No mechanism, analysis, or fallback is provided for vocabulary extension, per-user custom tokenizers, or multi-tenant updates; any write would invalidate the replication premise and the reported bounds.
Authors: The design explicitly targets the common case of fixed, read-only tokenizer tables used in production LLM serving for pre-trained models. The replication and epoch-rotation approach is justified only under this assumption, as stated in the manuscript. We agree that no mechanism is provided for dynamic updates, vocabulary extensions, or per-user custom tokenizers, as these would require separate handling (e.g., rebuilds or isolated instances) and fall outside the paper's scope. We will add an explicit statement of this assumption and its implications in the abstract and Section 3 to prevent misinterpretation. revision: partial
-
Referee: [Abstract] Abstract: concrete overhead numbers (4.5% TTFT, <10% tokenizer share, <0.5 GB) are stated without reference to evaluation methodology, baselines, number of runs, or error bars. The reader cannot assess whether the numbers reflect post-hoc selection, specific prompt distributions, or measurement artifacts.
Authors: The full evaluation (Section 5) details the methodology: implementation in HuggingFace Tokenizers and nano-vLLM, execution inside TDX CVM with H100 GPU, across multiple model families, using representative prompt distributions from standard benchmarks, with multiple runs and reported averages. However, the abstract presents the headline numbers without cross-references or qualifiers. We will revise the abstract to include a brief pointer to the evaluation setup and ensure the results section explicitly states run counts, error bars, and baseline comparisons to address this presentation concern. revision: yes
Circularity Check
No significant circularity; claims rest on implementation and direct measurement
full rationale
The paper describes an engineering system (OTRO) that applies square-root ORAM to tokenizers, with three concrete mechanisms (replicated instances, epoch rotation with dummy padding, chunked KV-cache overlap) whose overhead bounds are obtained by running the implementation inside TDX CVMs on H100 GPUs and measuring TTFT, latency, and memory. No equations, fitted parameters, or self-citations are presented as load-bearing derivations; the read-only table premise is an explicit environmental assumption that enables replication but does not create a self-referential loop in any claimed result. The central performance numbers are therefore externally falsifiable benchmarks rather than tautological reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tokenizer table is read-only
- domain assumption Epoch boundaries can be padded with dummy accesses without leaking timing information beyond the epoch
Reference graph
Works this paper leans on
-
[1]
What was your prompt? a remote keylogging attack on{AI}assistants,
R. Weiss, D. Ayzenshteyn, and Y . Mirsky, “What was your prompt? a remote keylogging attack on{AI}assistants,” in33rd USENIX Security Symposium (USENIX Security 24), 2024, pp. 3367–3384
2024
-
[2]
Data mixture inference attack: Bpe tokenizers reveal training data compositions,
J. Hayase, A. Liu, Y . Choi, S. Oh, and N. A. Smith, “Data mixture inference attack: Bpe tokenizers reveal training data compositions,” Advances in Neural Information Processing Systems, vol. 37, pp. 8956–8983, 2024
2024
-
[3]
Z. Gao, J. Hu, F. Guo, Y . Zhang, Y . Han, S. Liu, H. Li, and Z. Lv, “I know what you said: Unveiling hardware cache side-channels in local large language model inference,”arXiv preprint arXiv:2505.06738, 2025
-
[4]
Time will tell: Timing side channels via output token count in large language models,
T. Zhang, G. Saileshwar, and D. Lie, “Time will tell: Timing side channels via output token count in large language models,”arXiv preprint arXiv:2412.15431, 2024. 13
-
[5]
arXiv preprint arXiv:2403.06634 , year=
N. Carlini, D. Paleka, K. D. Dvijotham, T. Steinke, J. Hayase, A. F. Cooper, K. Lee, M. Jagielski, M. Nasr, A. Conmy, I. Yona, E. Wallace, D. Rolnick, and F. Tram `er, “Stealing part of a production language model,” 2024. [Online]. Available: https://arxiv.org/abs/2403.06634
-
[6]
Amd secure encrypted virtualization (sev),
“Amd secure encrypted virtualization (sev),” https://www.amd.com/ en/developer/sev.html, AMD, accessed: 2024-10-07
2024
-
[7]
Strengthening vm isolation with integrity protection and more,
A. Sev-Snp, “Strengthening vm isolation with integrity protection and more,”White Paper, January, vol. 53, no. 2020, pp. 1450–1465, 2020
2020
-
[8]
Intel trust domain extensions,
“Intel trust domain extensions,” https://www.intel.com/content/www/ us/en/developer/tools/trust-domain-extensions/overview.html, Intel, accessed: 2024-10-07
2024
-
[9]
Architecture Specification: Intel Trust Domain Extensions (In- tel TDX) Module,
Intel, “Architecture Specification: Intel Trust Domain Extensions (In- tel TDX) Module,” 2020
2020
-
[10]
What is Azure confidential computing?
Microsoft, “What is Azure confidential computing?” May 2025, accessed: 2025-09-28. [Online]. Available: https://learn.microsoft. com/en-us/azure/confidential-computing/overview
2025
-
[11]
Confidential Compute on NVIDIA Hopper H100,
NVIDIA, “Confidential Compute on NVIDIA Hopper H100,” https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/ HCC-Whitepaper-v1.0.pdf, 2023
2023
-
[12]
AI security with confidential computing,
NVIDIA, “AI security with confidential computing,” https://www. nvidia.com/en-us/data-center/solutions/confidential-computing/
-
[13]
Private processing technical whitepaper,
Meta, “Private processing technical whitepaper,” Meta AI, Tech. Rep., June 2025, https://ai.meta.com/static-resource/ private-processing-technical-whitepaper
2025
-
[14]
How Confidential Accelerators can boost AI work- load security,
Google Cloud, “How Confidential Accelerators can boost AI work- load security,” 2025
2025
-
[15]
WhatsApp. About Private Processing. [Online]. Available: https: //faq.whatsapp.com/2089630958184255
-
[16]
{CIPHERLEAKS}: Breaking constant-time cryptography on{AMD}{SEV}via the ci- phertext side channel,
M. Li, Y . Zhang, H. Wang, K. Li, and Y . Cheng, “{CIPHERLEAKS}: Breaking constant-time cryptography on{AMD}{SEV}via the ci- phertext side channel,” in30th USENIX Security Symposium (USENIX Security 21), 2021, pp. 717–732
2021
-
[17]
SEVered: Subverting AMD’s virtual machine encryption,
M. Morbitzer, M. Huber, J. Horsch, and S. Wessel, “SEVered: Subverting AMD’s virtual machine encryption,” in11th European Workshop on Systems Security. ACM, 2018
2018
-
[18]
The SEVerESt of them all: Inference attacks against secure virtual enclaves,
J. Werner, J. Mason, M. Antonakakis, M. Polychronakis, and F. Mon- rose, “The SEVerESt of them all: Inference attacks against secure virtual enclaves,” inACM Asia Conference on Computer and Com- munications Security. ACM, 2019, pp. 73–85
2019
-
[19]
Flush+ reload: A high resolution, low noise, l3 cache side-channel attack
Y . Yarom and K. Falkner, “Flush+ reload: A high resolution, low noise, l3 cache side-channel attack.” inUSENIX Security Symposium, 2014, pp. 719–732
2014
-
[20]
Cachequote: Efficiently recovering long- term secrets of sgx epid via cache attacks,
F. Dall, G. De Micheli, T. Eisenbarth, D. Genkin, N. Heninger, A. Moghimi, and Y . Yarom, “Cachequote: Efficiently recovering long- term secrets of sgx epid via cache attacks,” 2018
2018
-
[22]
SGX-Step: A practical attack framework for precise enclave execution control,
J. Van Bulck, F. Piessens, and R. Strackx, “SGX-Step: A practical attack framework for precise enclave execution control,” inProceed- ings of the 2nd Workshop on System Software for Trusted Execution, 2017, pp. 1–6
2017
-
[23]
Relocate-vote: Using sparsity information to exploit cipher- text side-channels,
Y . Yan, W. Huang, I. Grishchenko, G. Saileshwar, A. Mehta, and D. Lie, “Relocate-vote: Using sparsity information to exploit cipher- text side-channels,” inProceedings of the 34th USENIX Conference on Security Symposium, 2025, pp. 5699–5717
2025
-
[24]
Hypertheft: Thieving model weights from tee-shielded neural net- works via ciphertext side channels,
Y . Yuan, Z. Liu, S. Deng, Y . Chen, S. Wang, Y . Zhang, and Z. Su, “Hypertheft: Thieving model weights from tee-shielded neural net- works via ciphertext side channels,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 4346–4360
2024
-
[25]
A systematic look at ciphertext side channels on amd sev- snp,
M. Li, L. Wilke, J. Wichelmann, T. Eisenbarth, R. Teodorescu, and Y . Zhang, “A systematic look at ciphertext side channels on amd sev- snp,” in2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022, pp. 337–351
2022
-
[26]
Gemma 3,
G. Team, “Gemma 3,” 2025. [Online]. Available: https://goo.gle/ Gemma3Report
2025
-
[27]
Llama 3 model card,
AI@Meta, “Llama 3 model card,” 2024. [Online]. Available: https://github.com/meta-llama/llama3/blob/main/MODEL CARD.md
2024
-
[28]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
M. Abdin, J. Aneja, H. Awadalla, A. Awadallah, A. A. Awan, N. Bach, A. Bahree, A. Bakhtiari, J. Bao, H. Behl, A. Benhaim, M. Bilenko, J. Bjorck, S. Bubeck, M. Cai, Q. Cai, V . Chaudhary, D. Chen, D. Chen, W. Chen, Y .-C. Chen, Y .-L. Chen, H. Cheng, P. Chopra, X. Dai, M. Dixon, R. Eldan, V . Fragoso, J. Gao, M. Gao, M. Gao, A. Garg, A. D. Giorno, A. Goswa...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Q. Team, “Qwen3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Time will tell: Timing side channels via output token count,
T. Zhang, “Time will tell: Timing side channels via output token count,” Master’s thesis, University of Toronto (Canada), 2025
2025
-
[31]
Tdxray: Microarchitectural side-channel analysis of intel tdx for real-world workloads
T. Hornetz, H. Yavarzadeh, A. Cheu, A. Gascon, L. Gerlach, D. Moghimi, P. Schoppmann, M. Schwarz, and R. Zhang, “Tdxray: Microarchitectural side-channel analysis of intel tdx for real-world workloads.”
-
[32]
Laoram: A look ahead oram architecture for training large embedding tables,
R. Rajat, Y . Wang, and M. Annavaram, “Laoram: A look ahead oram architecture for training large embedding tables,” inProceedings of the 50th Annual International Symposium on Computer Architecture, 2023, pp. 1–15
2023
-
[33]
Data leakage via access patterns of sparse features in deep learning-based recommendation systems,
H. Hashemi, W. Xiong, L. Ke, K. Maeng, M. Annavaram, G. E. Suh, and H.-H. S. Lee, “Data leakage via access patterns of sparse features in deep learning-based recommendation systems,”arXiv preprint arXiv:2212.06264, 2022
-
[34]
Efficient memory side-channel protection for embedding generation in machine learning,
M. Umar, A. P. Marathe, M. D. Gupta, S. J. Ghosh, G. E. Suh, and W. Xiong, “Efficient memory side-channel protection for embedding generation in machine learning,” in2025 IEEE International Sympo- sium on High Performance Computer Architecture (HPCA). IEEE, 2025, pp. 423–441
2025
-
[35]
Software protection and simulation on oblivious rams,
O. Goldreich and R. Ostrovsky, “Software protection and simulation on oblivious rams,”J. ACM, vol. 43, no. 3, p. 431–473, May 1996. [Online]. Available: https://doi.org/10.1145/233551.233553
-
[36]
Path oram: An extremely simple oblivious ram protocol,
E. Stefanov, M. van Dijk, E. Shi, C. Fletcher, L. Ren, X. Yu, and S. Devadas, “Path oram: An extremely simple oblivious ram protocol,” inProceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security (CCS), 2013
2013
-
[37]
Constants count: Practical improvements to oblivious RAM,
L. Ren, C. Fletcher, A. Kwon, E. Stefanov, E. Shi, M. van Dijk, and S. Devadas, “Constants count: Practical improvements to oblivious RAM,” in24th USENIX Security Symposium, 2015
2015
-
[38]
AMD memory encryption,
D. Kaplan, J. Powell, and T. Woller, “AMD memory encryption,” White paper, 2016. 14
2016
-
[39]
Intel Hardware Shield- Intel Total Memory Encryption,
Intel, “Intel Hardware Shield- Intel Total Memory Encryption,” https: //www.intel.com/content/www/us/en/architecture-and-technology/ total-memory-encryption-security-paper.html, 2017
2017
-
[40]
Intel trust domain extensions whitepaper,
——, “Intel trust domain extensions whitepaper,” https: //software.intel.com/content/dam/develop/external/us/en/documents/ tdx-whitepaper-final9-17.pdf, 2020
2020
-
[41]
SEV API version 0.22,
AMD, “SEV API version 0.22,” 2019
2019
-
[42]
ARM CCA Security Model 1.0,
ARM, “ARM CCA Security Model 1.0,” 2021
2021
-
[43]
Intel SGX explained
V . Costan and S. Devadas, “Intel SGX explained.”IACR Cryptol. ePrint Arch., vol. 2016, no. 86, pp. 1–118, 2016
2016
-
[44]
AMD64 architecture programmer’s manual volume 2: System programming,
AMD, “AMD64 architecture programmer’s manual volume 2: System programming,” 2019
2019
-
[45]
Upcoming x86 technologies for malicious hyper- visor protection,
D. Kaplan, “Upcoming x86 technologies for malicious hyper- visor protection,” https://static.sched.com/hosted files/lsseu2019/65/ SEV-SNP%20Slides%20Nov%201%202019.pdf, 2020
2020
-
[46]
Protecting VM register state with SEV-ES,
——, “Protecting VM register state with SEV-ES,”White paper, 2017
2017
-
[47]
NVIDIA Attestation,
Nvidia, “NVIDIA Attestation,” https://docs.nvidia.com/attestation/ index.html, 2025
2025
-
[48]
Private processing for whatsapp: Tech- nical whitepaper,
Meta AI, “Private processing for whatsapp: Tech- nical whitepaper,” https://ai.meta.com/static-resource/ private-processing-technical-whitepaper, Jun. 2025
2025
-
[49]
Azure AI Confidential Inferenc- ing: Technical Deep-Dive,
Microsoft, “Azure AI Confidential Inferenc- ing: Technical Deep-Dive,” https://techcommunity. microsoft.com/blog/azureconfidentialcomputingblog/ azure-ai-confidential-inferencing-technical-deep-dive/4253150, 2025
-
[50]
(2023) Blindai: Confidential ai deployment with trusted execution environments
Mithril Security. (2023) Blindai: Confidential ai deployment with trusted execution environments. [Online]. Available: https: //github.com/mithril-security/blindai
2023
-
[51]
(2024) Blindllama: Zero-trust confidential ai for llms
——. (2024) Blindllama: Zero-trust confidential ai for llms. [Online]. Available: https://blindllama.mithrilsecurity.io/en/latest/
2024
-
[52]
(2024, Jul.) Continuum: The first confidential llm platform to revolutionize secure, privacy-preserving ai with nvidia h100 gpus
Edgeless Systems. (2024, Jul.) Continuum: The first confidential llm platform to revolutionize secure, privacy-preserving ai with nvidia h100 gpus. [Online]. Available: https://www.edgeless.systems/blog/ launching-confidential-llm-platform-continuum-ai
2024
-
[53]
Neural machine translation of rare words with subword units,
R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” inProceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers), 2016, pp. 1715–1725
2016
-
[54]
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Y . Wu, M. Schuster, Z. Chen, Q. V . Le, M. Norouzi, W. Macherey, M. Krikun, Y . Cao, Q. Gao, K. Macherey, J. Klingner, A. Shah, M. Johnson, X. Liu, Łukasz Kaiser, S. Gouws, Y . Kato, T. Kudo, H. Kazawa, K. Stevens, G. Kurian, N. Patil, W. Wang, C. Young, J. Smith, J. Riesa, A. Rudnick, O. Vinyals, G. Corrado, M. Hughes, and J. Dean, “Google’s neural mach...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[55]
T. Kudo and J. Richardson, “Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text pro- cessing,”arXiv preprint arXiv:1808.06226, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[56]
Huggingface’s tokenizers,
A. Moi and N. Patry, “Huggingface’s tokenizers,” accessed: 2025- 11-22. [Online]. Available: https://github.com/huggingface/tokenizers
2025
-
[57]
Nvidia confidential computing,
“Nvidia confidential computing,” https://images.nvidia.com/ aem-dam/en-zz/Solutions/data-center/HCC-Whitepaper-v1.0.pdf, NVIDIA, accessed: 2024-10-07
2024
-
[58]
Wiretap: Breaking server sgx via dram bus inter- position,
A. Seto, O. K. Duran, S. Amer, J. Chuang, S. van Schaik, D. Genkin, and C. Garman, “Wiretap: Breaking server sgx via dram bus inter- position,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, 2025, pp. 708–722
2025
-
[59]
Badram: Practical memory aliasing attacks on trusted execution environments,
J. De Meulemeester, L. Wilke, D. Oswald, T. Eisenbarth, I. Ver- bauwhede, and J. Van Bulck, “Badram: Practical memory aliasing attacks on trusted execution environments,” in2025 IEEE Symposium on Security and Privacy (SP). IEEE, 2025, pp. 4117–4135
2025
-
[60]
Pageoram: An efficient dram page aware oram strategy,
R. Rajat, Y . Wang, and M. Annavaram, “Pageoram: An efficient dram page aware oram strategy,” in2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2022, pp. 91– 107
2022
-
[61]
nano-vllm,
X. Yu, “nano-vllm,” 2025. [Online]. Available: https://github.com/ GeeeekExplorer/nano-vllm
2025
-
[62]
Cache attacks on intel sgx,
J. G ¨otzfried, M. Eckert, S. Schinzel, and T. M ¨uller, “Cache attacks on intel sgx,” inProceedings of the 10th European Workshop on Systems Security, 2017, pp. 1–6
2017
-
[63]
Platypus: Software-based power side-channel attacks on x86,
M. Lipp, A. Kogler, D. Oswald, M. Schwarz, C. Easdon, C. Canella, and D. Gruss, “Platypus: Software-based power side-channel attacks on x86,” in2021 IEEE Symposium on Security and Privacy (SP). IEEE, 2021, pp. 355–371
2021
-
[64]
Software grand exposure:{SGX}cache attacks are practical,
F. Brasser, U. M ¨uller, A. Dmitrienko, K. Kostiainen, S. Capkun, and A.-R. Sadeghi, “Software grand exposure:{SGX}cache attacks are practical,” in11th USENIX workshop on offensive technologies (WOOT 17), 2017
2017
-
[65]
Cachequote: Efficiently recovering long- term secrets of sgx epid via cache attacks,
F. Dall, G. De Micheli, T. Eisenbarth, D. Genkin, N. Heninger, A. Moghimi, and Y . Yarom, “Cachequote: Efficiently recovering long- term secrets of sgx epid via cache attacks,”IACR Transactions on Cryptographic Hardware and Embedded Systems, vol. 2018, no. 2, 2018
2018
-
[66]
Cachezoom: How sgx amplifies the power of cache attacks,
A. Moghimi, G. Irazoqui, and T. Eisenbarth, “Cachezoom: How sgx amplifies the power of cache attacks,” inInternational conference on cryptographic hardware and embedded systems. Springer, 2017, pp. 69–90
2017
-
[67]
Malware guard extension: Using sgx to conceal cache attacks,
M. Schwarz, S. Weiser, D. Gruss, C. Maurice, and S. Mangard, “Malware guard extension: Using sgx to conceal cache attacks,” in International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment. Springer, 2017, pp. 3–24
2017
-
[68]
Nemesis: Studying mi- croarchitectural timing leaks in rudimentary cpu interrupt logic,
J. Van Bulck, F. Piessens, and R. Strackx, “Nemesis: Studying mi- croarchitectural timing leaks in rudimentary cpu interrupt logic,” in Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, 2018, pp. 178–195
2018
-
[69]
Private in- formation retrieval,
B. Chor, E. Kushilevitz, O. Goldreich, and M. Sudan, “Private in- formation retrieval,”Journal of the ACM (JACM), vol. 45, no. 6, pp. 965–981, 1998
1998
-
[70]
Replication is not needed: Single database, computationally-private information retrieval,
E. Kushilevitz and R. Ostrovsky, “Replication is not needed: Single database, computationally-private information retrieval,” inProceed- ings 38th annual symposium on foundations of computer science. IEEE, 1997, pp. 364–373
1997
-
[71]
Oblix: An efficient oblivious search index,
P. Mishra, R. Poddar, J. Chen, A. Chiesa, and R. A. Popa, “Oblix: An efficient oblivious search index,” in2018 IEEE symposium on security and privacy (SP). IEEE, 2018, pp. 279–296
2018
-
[72]
{EnigMap}:{External-Memory} oblivious map for secure enclaves,
A. Tinoco, S. Gao, and E. Shi, “{EnigMap}:{External-Memory} oblivious map for secure enclaves,” in32nd USENIX Security Sym- posium (USENIX Security 23), 2023, pp. 4033–4050
2023
-
[73]
Design space exploration and optimization of path oblivious ram in secure processors,
L. Ren, X. Yu, C. W. Fletcher, M. Van Dijk, and S. Devadas, “Design space exploration and optimization of path oblivious ram in secure processors,” inProceedings of the 40th Annual International Symposium on Computer Architecture, 2013, pp. 571–582
2013
-
[74]
Constants count: Practical improvements to oblivious {RAM},
L. Ren, C. Fletcher, A. Kwon, E. Stefanov, E. Shi, M. Van Dijk, and S. Devadas, “Constants count: Practical improvements to oblivious {RAM},” in24th USENIX Security Symposium (USENIX Security 15), 2015, pp. 415–430
2015
-
[75]
Ir-oram: Path access type based memory intensity reduction for path-oram,
M. Raoufi, Y . Zhang, and J. Yang, “Ir-oram: Path access type based memory intensity reduction for path-oram,” in2022 IEEE Inter- national Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2022, pp. 360–372
2022
-
[76]
Ep-oram: efficient nvm- friendly path eviction for ring oram in hybrid memory,
M. Raoufi, J. Yang, X. Tang, and Y . Zhang, “Ep-oram: efficient nvm- friendly path eviction for ring oram in hybrid memory,” in2023 60th ACM/IEEE Design Automation Conference (DAC). IEEE, 2023, pp. 1–6. 15
2023
-
[77]
Ab-oram: Constructing adjustable buckets for space reduction in ring oram,
——, “Ab-oram: Constructing adjustable buckets for space reduction in ring oram,” in2023 IEEE International Symposium on High- Performance Computer Architecture (HPCA). IEEE, 2023, pp. 361– 373
2023
-
[78]
Ps-oram: Efficient crash consistency support for oblivious ram on nvm,
G. Liu, K. Li, Z. Xiao, and R. Wang, “Ps-oram: Efficient crash consistency support for oblivious ram on nvm,” inProceedings of the 49th Annual International Symposium on Computer Architecture, 2022, pp. 188–203
2022
-
[79]
H2oram: Low response latency optimized oram for hybrid memory systems,
W. He, F. Wang, and D. Feng, “H2oram: Low response latency optimized oram for hybrid memory systems,” in2020 IEEE 38th International Conference on Computer Design (ICCD). IEEE, 2020, pp. 405–408
2020
-
[80]
Multi-range supported oblivious ram for efficient block data retrieval,
Y . Che and R. Wang, “Multi-range supported oblivious ram for efficient block data retrieval,” in2020 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2020, pp. 369–382
2020
-
[81]
Streamline ring oram accesses through spatial and temporal op- timization,
D. Cao, M. Zhang, H. Lu, X. Ye, D. Fan, Y . Che, and R. Wang, “Streamline ring oram accesses through spatial and temporal op- timization,” in2021 IEEE International Symposium on High- Performance Computer Architecture (HPCA). IEEE, 2021, pp. 14– 25
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.