Towards Auditing AI Systems in the Wild
Pith reviewed 2026-06-27 01:43 UTC · model grok-4.3
The pith
AI auditing should frame fairness and safety as statistical monitoring of risk-controlled constraints under uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Auditing deployed AI systems should be reframed as a statistical problem of monitoring constraint violations under uncertainty, where desired properties such as fairness and safety are treated as risk-controlled constraints that are continuously evaluated as the systems evolve through iterative feedback, requiring uncertainty-aware methods, socio-technical audit criteria, and supporting infrastructures.
What carries the argument
The statistical framing of auditing as ongoing monitoring of risk-controlled constraint violations under uncertainty.
If this is right
- Auditing must occur throughout the entire system lifecycle rather than at fixed evaluation points.
- Properties like fairness and safety become risk-controlled constraints that are checked continuously.
- Uncertainty-aware statistical methods become necessary to handle dynamic environments and feedback.
- Socio-technical specifications must define the audit criteria before monitoring can begin.
- Dedicated auditing infrastructures are required to enable real-time oversight in the wild.
Where Pith is reading between the lines
- The framing could support regulatory requirements that mandate ongoing monitoring protocols for high-stakes AI deployments.
- It suggests connections to monitoring practices already used in safety-critical control systems where state changes over time.
- Practical tests on current production models could expose whether existing safety claims hold under continuous scrutiny.
- New statistical tools for high-dimensional constraint tracking may need to be built before the approach becomes routine.
Load-bearing premise
Socio-technical specifications of audit criteria and uncertainty-aware monitoring methods can be developed and deployed to support continuous oversight of evolving AI systems.
What would settle it
An empirical case where no set of uncertainty-aware methods can detect fairness or safety violations in a deployed AI system without either missing real violations or producing unmanageable false alarms.
Figures
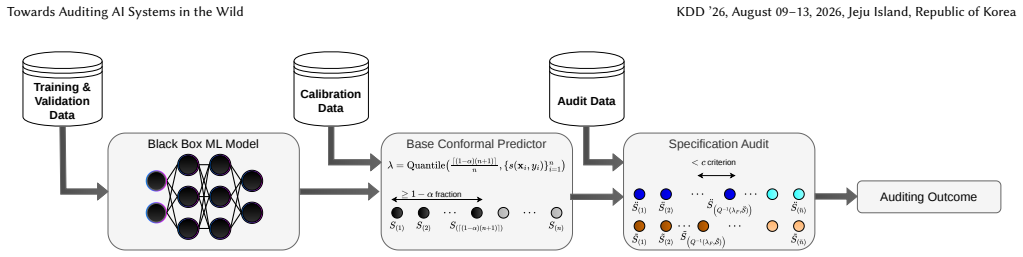
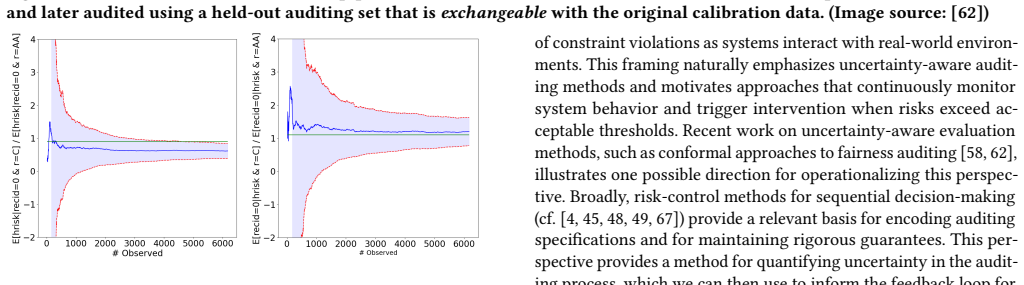
read the original abstract
AI systems are increasingly deployed in real-world settings where their behavior is shaped by dynamic environments, evolving data distributions, and complex interactions with users and infrastructure. Traditional machine learning evaluation focuses on benchmarks and operates within sandboxed environments, providing only a limited view of the true system behavior in the wild. We argue for the development of principled auditing frameworks that monitor deployed AI systems throughout their lifecycle. We further propose framing auditing as a statistical problem of monitoring constraint violations under uncertainty, where desired properties (e.g., fairness and safety) are treated as risk-controlled constraints that must be continuously evaluated as systems evolve through iterative feedback. This perspective highlights the need for uncertainty-aware monitoring methods, socio-technical specifications of audit criteria, and auditing infrastructures that enable ongoing oversight of AI systems in the wild.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that traditional benchmark-based ML evaluation provides only a limited view of AI system behavior in dynamic real-world environments. It advocates for the development of principled auditing frameworks to monitor deployed systems throughout their lifecycle and proposes reframing auditing as a statistical problem of monitoring constraint violations under uncertainty, where properties such as fairness and safety are treated as risk-controlled constraints requiring continuous evaluation amid evolving data and feedback loops.
Significance. If the proposed statistical framing can be made operational, the work could help shift the field from static sandbox evaluations toward ongoing, uncertainty-aware oversight of AI systems. The identification of the gap between controlled benchmarks and deployed behavior is a clear strength, and the emphasis on lifecycle monitoring and socio-technical criteria provides a useful conceptual foundation for future research in AI safety and governance.
major comments (1)
- [Abstract] Abstract: The central proposal to treat desired properties as 'risk-controlled constraints' that must be 'continuously evaluated' is load-bearing for the argument, yet the manuscript provides no sketch of how uncertainty quantification or constraint monitoring would be implemented for a property such as fairness, leaving the statistical framing at a level too abstract to evaluate its practicality.
minor comments (1)
- The manuscript would benefit from at least one concrete (even hypothetical) example illustrating how an evolving AI system might trigger a constraint violation under uncertainty.
Simulated Author's Rebuttal
We thank the referee for their constructive review and positive assessment of the paper's significance. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central proposal to treat desired properties as 'risk-controlled constraints' that must be 'continuously evaluated' is load-bearing for the argument, yet the manuscript provides no sketch of how uncertainty quantification or constraint monitoring would be implemented for a property such as fairness, leaving the statistical framing at a level too abstract to evaluate its practicality.
Authors: We agree that the current manuscript is conceptual and does not provide a concrete sketch of implementation details for uncertainty quantification or constraint monitoring (e.g., for fairness). The paper's primary aim is to introduce a high-level statistical framing rather than to solve the associated technical challenges. To address this valid concern and improve evaluability, we will revise the manuscript to include a new subsection outlining potential operational approaches, such as the use of conformal prediction or Bayesian methods for uncertainty-aware bounds on fairness metrics, combined with online statistical process control techniques for detecting constraint violations over time. This addition will remain consistent with the position-paper nature of the work while providing a clearer bridge to practicality. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a position/proposal piece advocating for auditing frameworks and a statistical framing of constraint monitoring; it contains no equations, derivations, fitted parameters, theorems, or empirical results. No load-bearing steps reduce to self-citations, self-definitions, or renamed inputs by construction. The central argument is self-contained as a call for future socio-technical work rather than a derivation whose validity depends on hidden circular premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2016.Recommender Systems(1 ed.)
Charu C Aggarwal. 2016.Recommender Systems(1 ed.). Springer International Publishing, Cham, Switzerland
2016
-
[2]
Shawqi Al-Maliki, Faissal El Bouanani, Mohamed Abdallah, Junaid Qadir, and Ala Al-Fuqaha. 2024. Addressing Data Distribution Shifts in Online Machine Learning Powered Smart City Applications Using Augmented Test-Time Adap- tation.IEEE Internet of Things Magazine7, 4 (July 2024), 116–124. doi:10.1109/ iotm.001.2300135
2024
-
[3]
Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I
Anastasios N. Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I. Jordan, and Tijana Zrnic. 2023. Prediction-Powered Inference. arXiv:2301.09633 [stat.ML] https://arxiv.org/abs/2301.09633
arXiv 2023
-
[4]
Anastasios Nikolas Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster. 2024. Conformal Risk Control. InThe Twelfth International Conference on Learning Representations
2024
-
[5]
Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner. 2016. Machine bias. InEthics of Data and Analytics. Auerbach Publications, 254–264
2016
-
[6]
AI Anthropic. 2025. System card: Claude opus 4 & claude sonnet 4.Claude-4 Model Card(2025)
2025
-
[7]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. 2020. Invariant Risk Minimization. arXiv:1907.02893 [stat.ML] https://arxiv.org/abs/ 1907.02893
Pith/arXiv arXiv 2020
-
[8]
K.J. Arrow. 1974.The Limits of Organization. Norton. https://books.google.com/ books?id=_JHZAAAAMAAJ
1974
-
[9]
2023.Fairness and machine learning: Limitations and opportunities
Solon Barocas, Moritz Hardt, and Arvind Narayanan. 2023.Fairness and machine learning: Limitations and opportunities. MIT press
2023
-
[10]
Meshi Bashari, Roy Maor Lotan, Yonghoon Lee, Edgar Dobriban, and Yaniv Romano. 2025. Synthetic-Powered Predictive Inference. arXiv:2505.13432 [cs.LG] https://arxiv.org/abs/2505.13432
arXiv 2025
-
[11]
Yoshua Bengio, Stephen Clare, Carina Prunkl, Maksym Andriushchenko, Ben Bucknall, Malcolm Murray, Rishi Bommasani, Stephen Casper, Tom Davidson, Raymond Douglas, et al. 2026. International AI Safety Report 2026.arXiv preprint arXiv:2602.21012(2026)
arXiv 2026
-
[12]
Soumitra S Bhuyan, Vidyoth Sateesh, Naya Mukul, Alay Galvankar, Asos Mah- mood, Muhammad Nauman, Akash Rai, Kahuwa Bordoloi, Urmi Basu, and Jim Samuel. 2025. Generative Artificial Intelligence Use in Healthcare: Opportunities for Clinical Excellence and Administrative Efficiency.J Med Syst49, 1 (Jan. 2025), 10
2025
-
[13]
Allison J. B. Chaney, Brandon M. Stewart, and Barbara E. Engelhardt. 2018. How algorithmic confounding in recommendation systems increases homogeneity and decreases utility. InProceedings of the 12th ACM Conference on Recommender Systems (RecSys ’18). ACM, 224–232. doi:10.1145/3240323.3240370
-
[14]
Hongyan Chang, Brandon Edwards, Anindya S Paul, and Reza Shokri. 2024. Effi- cient privacy auditing in federated learning. In33rd USENIX Security Symposium (USENIX Security 24). 307–323
2024
-
[15]
You Chen, Ellen Wright Clayton, Laurie Lovett Novak, Shilo Anders, and Bradley Malin. 2023. Human-Centered Design to Address Biases in Artificial Intelligence. J Med Internet Res25 (2023), e43251
2023
-
[16]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. In Proceedings of the 31st International Conference on Neural Information Processing Systems(Long Beach, California, USA)(NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 4302–4310
2017
-
[17]
Jesse C Cresswell, Bhargava Kumar, Yi Sui, and Mouloud Belbahri. 2025. Confor- mal Prediction Sets Can Cause Disparate Impact. InThe Thirteenth International Conference on Learning Representations
2025
-
[18]
Fernando Delgado, Stephen Yang, Michael Madaio, and Qian Yang. 2023. The Participatory Turn in AI Design: Theoretical Foundations and the Current State of Practice. InProceedings of the 3rd ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization(Boston, MA, USA)(EAAMO ’23). Association for Computing Machinery, New York, NY, USA, Ar...
-
[19]
Yuri Demchenko, Paola Grosso, Cees de Laat, and Peter Membrey. 2013. Ad- dressing big data issues in Scientific Data Infrastructure. In2013 International Conference on Collaboration Technologies and Systems (CTS). 48–55. doi:10.1109/ CTS.2013.6567203
arXiv 2013
-
[20]
William Dieterich, Christina Mendoza, and Tim Brennan. 2016. COMPAS risk scales: Demonstrating accuracy equity and predictive parity.Northpointe Inc7, 4 (2016)
2016
-
[21]
2020.Machine learning in finance
Matthew F Dixon, Igor Halperin, Paul Bilokon, et al. 2020.Machine learning in finance. Vol. 1170. Springer
2020
-
[22]
The U.S. EEOC. 1979. Uniform guidelines on employee selection procedures. (March 1979)
1979
-
[23]
Gregory Falco, Ben Shneiderman, Julia Badger, Ryan Carrier, Anton Dahbura, David Danks, Martin Eling, Alwyn Goodloe, Jerry Gupta, Christopher Hart, et al. 2021. Governing AI safety through independent audits.Nature Machine Intelligence3, 7 (2021), 566–571
2021
-
[24]
Tongtong Feng, Xin Wang, Yu-Gang Jiang, and Wenwu Zhu. 2025. Embodied ai: From llms to world models.IEEE CIRCUITS AND SYSTEMS MAGAZINE(2025)
2025
-
[25]
Iason Gabriel, Arianna Manzini, Geoff Keeling, Lisa Anne Hendricks, Verena Rieser, Hasan Iqbal, Nenad Tomašev, Ira Ktena, Zachary Kenton, Mikel Rodriguez, et al. 2024. The ethics of advanced AI assistants.arXiv preprint arXiv:2404.16244 (2024)
arXiv 2024
-
[26]
Bishwamittra Ghosh, Debabrota Basu, and Kuldeep S Meel. 2021. Justicia: A stochastic SAT approach to formally verify fairness. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 7554–7563
2021
-
[27]
Moshe Glickman and Tali Sharot. 2025. How human-AI feedback loops alter human perceptual, emotional and social judgements.Nat. Hum. Behav.9, 2 (Feb. 2025), 345–359
2025
-
[28]
Ryan Greenblatt, Buck Shlegeris, Kshitij Sachan, and Fabien Roger. 2024. AI Control: Improving Safety Despite Intentional Subversion. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235), Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlet...
2024
-
[29]
2024.Business data ethics: Emerging models for governing AI and advanced analytics
Dennis Hirsch, Timothy Bartley, Aravind Chandrasekaran, Davon Norris, Srini- vasan Parthasarathy, and Piers Norris Turner. 2024.Business data ethics: Emerging models for governing AI and advanced analytics. Springer
2024
-
[30]
Zonghao Huang, Neil Zhenqiang Gong, and Michael K. Reiter. 2024. A General Framework for Data-Use Auditing of ML Models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security (CCS ’24). ACM, 1300–1314. doi:10.1145/3658644.3690226
-
[31]
Sathwik Karnik, Zhang-Wei Hong, Nishant Abhangi, Yen-Chen Lin, Tsun-Hsuan Wang, Christophe Dupuy, Rahul Gupta, and Pulkit Agrawal. 2024. Embodied red teaming for auditing robotic foundation models.arXiv preprint arXiv:2411.18676 (2024)
arXiv 2024
-
[32]
Noam Kolt, Nicholas Caputo, Jack Boeglin, Cullen O’Keefe, Rishi Bommasani, Stephen Casper, Mariano-Florentino Cuéllar, Noah Feldman, Iason Gabriel, Gillian K Hadfield, et al. 2026. Legal Alignment for Safe and Ethical AI.arXiv preprint arXiv:2601.04175(2026)
Pith/arXiv arXiv 2026
-
[33]
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning.nature 521, 7553 (2015), 436–444
2015
-
[34]
Jiashuo Liu, Zheyan Shen, Yue He, Xingxuan Zhang, Renzhe Xu, Han Yu, and Peng Cui. 2023. Towards Out-Of-Distribution Generalization: A Survey. arXiv:2108.13624 [cs.LG] https://arxiv.org/abs/2108.13624
arXiv 2023
-
[35]
Pranav Maneriker, Codi Burley, and Srinivasan Parthasarathy. 2023. Online Fairness Auditing through Iterative Refinement. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Long Beach, CA, USA)(KDD ’23). Association for Computing Machinery, New York, NY, USA, 1665–1676. doi:10.1145/3580305.3599454
-
[36]
Robertson, Karrie Karahalios, Christo Wilson, Jeff Hancock, and Christian Sandvig
Danaë Metaxa, Joon Sung Park, Ronald E. Robertson, Karrie Karahalios, Christo Wilson, Jeff Hancock, and Christian Sandvig. 2021. Auditing Algorithms: Under- standing Algorithmic Systems from the Outside In.Found. Trends Hum.-Comput. Interact.14, 4 (Nov. 2021), 272–344. doi:10.1561/1100000083
-
[37]
Jakob Mökander. 2023. Auditing of AI: Legal, ethical and technical approaches. Digital Society2, 3 (2023), 49
2023
-
[38]
George E Monahan. 1982. State of the art—a survey of partially observable Markov decision processes: theory, models, and algorithms.Management science 28, 1 (1982), 1–16
1982
-
[39]
Victor Ojewale, Ryan Steed, Briana Vecchione, Abeba Birhane, and Inioluwa Debo- rah Raji. 2025. Towards AI Accountability Infrastructure: Gaps and Opportunities in AI Audit Tooling. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). ACM, 1–29. doi:10.1145/3706598.3713301
-
[40]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schul- man, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Pe- ter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human...
Pith/arXiv arXiv 2022
-
[41]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22
2023
-
[42]
Ambreesh Parthasarathy, Aditya Phalnikar, Ameen Jauhar, Dhruv Somaya- jula, Gokul S Krishnan, and Balaraman Ravindran. 2024. Participatory Approaches in AI Development and Governance: A Principled Approach. arXiv:2407.13100 [cs.CY] https://arxiv.org/abs/2407.13100
arXiv 2024
-
[43]
Jonas Peters, Peter Bühlmann, and Nicolai Meinshausen. 2016. Causal Inference by using Invariant Prediction: Identification and Confidence Intervals.Journal of the Royal Statistical Society Series B: Statistical Methodology78, 5 (11 2016), 947–1012. doi:10.1111/rssb.12167
-
[44]
Neoklis Polyzotis, Martin Zinkevich, Sudip Roy, Eric Breck, and Steven Whang
-
[45]
Data validation for machine learning.Proceedings of machine learning and systems1 (2019), 334–347
2019
-
[46]
Drew Prinster, Xing Han, Anqi Liu, and Suchi Saria. 2025. WATCH: Adaptive Monitoring for AI Deployments via Weighted-Conformal Martingales. InForty- second International Conference on Machine Learning. https://openreview.net/ Towards Auditing AI Systems in the Wild KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea forum?id=GMjkK2CKx5
2025
-
[47]
Bender, Alex Hanna, and Aman- dalynne Paullada
Deborah Raji, Emily Denton, Emily M. Bender, Alex Hanna, and Aman- dalynne Paullada. 2021. AI and the Everything in the Whole Wide World Benchmark. InProceedings of the Neural Information Processing Sys- tems Track on Datasets and Benchmarks, J. Vanschoren and S. Yeung (Eds.), Vol. 1. https://datasets-benchmarks-proceedings.neurips.cc/paper_files/paper/ 2...
2021
-
[48]
White, Margaret Mitchell, Timnit Gebru, Ben Hutchinson, Jamila Smith-Loud, Daniel Theron, and Parker Barnes
Inioluwa Deborah Raji, Andrew Smart, Rebecca N. White, Margaret Mitchell, Timnit Gebru, Ben Hutchinson, Jamila Smith-Loud, Daniel Theron, and Parker Barnes. 2020. Closing the AI Accountability Gap: Defining an End-to-End Frame- work for Internal Algorithmic Auditing. InProceedings of the 2020 Conference on Fairness, Accountability, and Transparency. ACM, 33–44
2020
-
[49]
Aaditya Ramdas, Peter Grünwald, Vladimir Vovk, and Glenn Shafer. 2023. Game- theoretic statistics and safe anytime-valid inference.Statist. Sci.38, 4 (2023), 576–601
2023
-
[50]
Aaditya Ramdas, Johannes Ruf, Martin Larsson, and Wouter Koolen. 2022. Admis- sible anytime-valid sequential inference must rely on nonnegative martingales. arXiv:2009.03167 [math.ST] https://arxiv.org/abs/2009.03167
arXiv 2022
-
[51]
2026.Challenges to the monitoring of deployed AI systems
Anita Rao. 2026.Challenges to the monitoring of deployed AI systems. Technical Report. National Institute of Standards and Technology, Gaithersburg, MD
2026
-
[52]
Yaniv Romano, Rina Foygel Barber, Chiara Sabatti, and Emmanuel Can- dès. 2020. With Malice Toward None: Assessing Uncertainty via Equal- ized Coverage.Harvard Data Science Review2, 2 (apr 30 2020). https://hdsr.mitpress.mit.edu/pub/qedrwcz3
2020
-
[53]
Everyone wants to do the model work, not the data work
Nithya Sambasivan, Shivani Kapania, Hannah Highfill, Diana Akrong, Praveen Paritosh, and Lora M Aroyo. 2021. “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI. Inproceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 1–15
2021
-
[54]
Christian Sandvig, Kevin Hamilton, Karrie Karahalios, and Cédric Langbort
-
[55]
https://api.semanticscholar.org/CorpusID:15686114
Auditing Algorithms : Research Methods for Detecting Discrimination on Internet Platforms. https://api.semanticscholar.org/CorpusID:15686114
-
[56]
David Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Diet- mar Ebner, Vinay Chaudhary, Michael Young, Jean-Francois Crespo, and Dan Dennison. 2015. Hidden technical debt in machine learning systems.Advances in neural information processing systems28 (2015)
2015
-
[57]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al
-
[58]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267(2025)
Pith/arXiv arXiv 2025
-
[59]
Edward Small, Yueqing Xuan, Danula Hettiachchi, and Kacper Sokol. 2023. Help- ful, misleading or confusing: How humans perceive fundamental building blocks of artificial intelligence explanations.arXiv preprint arXiv:2303.00934(2023)
arXiv 2023
-
[60]
Anutam Srinivasan, Antoine Leeman, and Glen Chou. 2026. Safety Beyond the Training Data: Robust Out-of-Distribution MPC via Conformalized System Level Synthesis. In8th Annual Learning for Dynamics & Control Conference
2026
-
[61]
Vadlamani, Amin Meghrazi, and Srinivasan Parthasarathy
Anutam Srinivasan, Aditya T. Vadlamani, Amin Meghrazi, and Srinivasan Parthasarathy. 2026. FedCF: Fair Federated Conformal Prediction. https: //openreview.net/forum?id=6rCsaBOQON
2026
-
[62]
2026.Industry-Wide Forum: Overall Summary
Stanford Deliberative Democracy Lab and Center on Democracy, Development and the Rule of Law. 2026.Industry-Wide Forum: Overall Summary. Summary Report. Stanford University. In partnership with Meta, Oracle, DoorDash, PayPal, Cohere, and Microsoft
2026
-
[63]
2023.Artificial intelligence risk management Framework (AI RMF 1.0)
Elham Tabassi. 2023.Artificial intelligence risk management Framework (AI RMF 1.0). Technical Report. National Institute of Standards and Technology (U.S.), Gaithersburg, MD
2023
-
[64]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
Pith/arXiv arXiv 2023
-
[65]
Vadlamani, Anutam Srinivasan, Pranav Maneriker, Ali Payani, and Srinivasan Parthasarathy
Aditya T. Vadlamani, Anutam Srinivasan, Pranav Maneriker, Ali Payani, and Srinivasan Parthasarathy. 2025. A Generic Framework for Conformal Fairness. InThe Thirteenth International Conference on Learning Representations. https: //openreview.net/forum?id=xiQNfYl33p
2025
-
[66]
Michael Veale, Max Van Kleek, and Reuben Binns. 2018. Fairness and Accountabil- ity Design Needs for Algorithmic Support in High-Stakes Public Sector Decision- Making. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems(Montreal QC, Canada)(CHI ’18). Association for Computing Machinery, New York, NY, USA, 1–14. doi:10.1145/31735...
-
[67]
2005.Algorithmic learning in a random world
Vladimir Vovk, Alexander Gammerman, and Glenn Shafer. 2005.Algorithmic learning in a random world. Vol. 29. Springer
2005
-
[68]
WIRED. [n. d.]. Sun Called on Java Claims. https://www.wired.com/1997/11/sun- called-on-java-claims/
1997
-
[69]
2023.Statistical foundations of actuarial learning and its applications
Mario V Wüthrich and Michael Merz. 2023.Statistical foundations of actuarial learning and its applications. Springer
2023
-
[70]
Ziyu Xu, Nikos Karampatziakis, and Paul Mineiro. 2024. Active, anytime-valid risk controlling prediction sets. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=4ZH48aGD60
2024
-
[71]
Tom Yan and Chicheng Zhang. 2022. Active fairness auditing. InInternational Conference on Machine Learning. PMLR, 24929–24962
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.