CIAN: Multi-Stage Framework for Event-Enriched Image Captioning via Retrieval-Augmented Generation
Pith reviewed 2026-06-27 02:22 UTC · model grok-4.3
The pith
CIAN retrieves relevant articles to generate image captions that include event timing, location and participants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
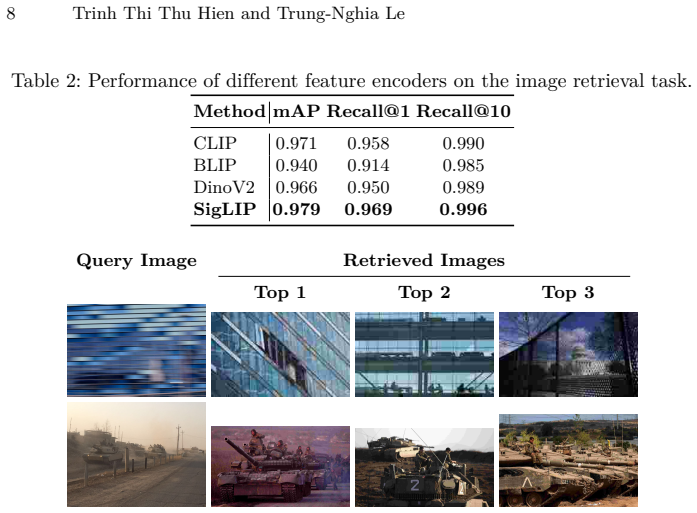
CIAN achieves retrieval mAP 0.979 and lifts CIDEr from 0.030 to 0.094 on OpenEvents-V1 by retrieving articles with SigLIP, summarizing them to guide a LoRA-fine-tuned Qwen model in a Narrative Generation stage, and applying N-Gram-based Refinement for fluency and coherence.
What carries the argument
The CIAN multi-stage pipeline in which SigLIP article retrieval supplies external narratives that are summarized to condition LoRA-fine-tuned Qwen generation, followed by N-Gram refinement.
If this is right
- Image captions can incorporate timing, location and participants that are not visible in the pixels.
- Retrieval-augmented generation plus n-gram refinement yields more coherent context-aware text.
- High retrieval precision (mAP 0.979) is attainable on event-focused benchmarks.
- The same staged process improves standard automatic metrics such as CIDEr.
Where Pith is reading between the lines
- The framework could be tested on video or social-media event data to handle time-varying context.
- Replacing the article corpus with domain-specific sources might extend the method to specialized fields such as sports or historical imagery.
- Measuring caption accuracy against ground-truth event logs would directly test whether retrieval noise propagates into hallucinations.
Load-bearing premise
Articles retrieved by SigLIP contain accurate event details that the summarization and fine-tuned model can integrate without adding factual errors.
What would settle it
A controlled test in which deliberately inaccurate or off-topic articles are fed into the pipeline and the resulting captions are checked for introduced factual errors or hallucinations.
Figures




read the original abstract
Event-enriched image captioning describes not only visible content but also the broader context of events, including timing, location, and participants, capabilities missing in most pixel-bound models. We propose the Contextual Image-Article Narrator (CIAN), a multi-stage framework that enriches captions with external narratives. CIAN retrieves relevant articles using SigLIP, summarizes them to guide a Narrative Generation stage with a LoRA-fine-tuned Qwen model, and applies N-Gram-based Refinement for fluency and coherence. On the OpenEvents-V1 benchmark, CIAN achieves high retrieval performance (mAP 0.979) and improves caption quality, increasing CIDEr from 0.030 to 0.094. These results highlight the effectiveness of retrieval-augmented reasoning combined with linguistic refinement for generating context-aware, human-like captions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CIAN, a multi-stage retrieval-augmented framework for event-enriched image captioning. It retrieves articles via SigLIP, summarizes them to condition a LoRA-fine-tuned Qwen model for narrative generation, and applies N-Gram refinement. On OpenEvents-V1 it reports retrieval mAP of 0.979 and a CIDEr increase from 0.030 to 0.094, claiming this demonstrates effective context-aware captioning.
Significance. If the factual correctness of the added event details can be established, the work would offer a concrete demonstration that retrieval-augmented generation can supply timing, location, and participant information missing from standard vision-language models. The explicit multi-stage pipeline and the use of an open-weight LLM with LoRA are positive elements that could be reproduced.
major comments (2)
- [Abstract] Abstract: The central quantitative claim (CIDEr rising from 0.030 to 0.094) is presented without naming the baseline model, reporting statistical significance, or providing error bars, so it is impossible to determine whether the gain supports the claim of improved event enrichment.
- [Abstract] Abstract and evaluation description: No factuality metric, human verification of event claims, or error analysis on generated captions is mentioned. CIDEr only measures n-gram overlap and cannot confirm that timing/location/participant facts supplied by the SigLIP-retrieved articles are accurately integrated rather than hallucinated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the presentation of results and evaluation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central quantitative claim (CIDEr rising from 0.030 to 0.094) is presented without naming the baseline model, reporting statistical significance, or providing error bars, so it is impossible to determine whether the gain supports the claim of improved event enrichment.
Authors: We agree that the abstract must explicitly identify the baseline. The reported CIDEr of 0.030 is from the LoRA-tuned Qwen model without retrieval augmentation or N-gram refinement. We will revise the abstract to name this baseline clearly. We will also add statistical significance testing and error bars (computed over multiple runs) to the results section and reference them in the abstract where space permits. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: No factuality metric, human verification of event claims, or error analysis on generated captions is mentioned. CIDEr only measures n-gram overlap and cannot confirm that timing/location/participant facts supplied by the SigLIP-retrieved articles are accurately integrated rather than hallucinated.
Authors: We acknowledge that CIDEr measures n-gram overlap and does not directly verify factual correctness of the added event details. Our design relies on the high retrieval mAP (0.979) together with article summarization to condition generation and thereby reduce unsupported claims, but we did not report a dedicated factuality metric or human verification. In the revision we will add an error analysis subsection with qualitative examples, a discussion of potential hallucinations, and a note on this limitation; we will also explore adding a simple factuality check if feasible within the current experimental setup. revision: yes
Circularity Check
No circularity: empirical framework with benchmark metrics only
full rationale
The paper describes a multi-stage retrieval-augmented captioning system (SigLIP retrieval, summarization, LoRA-tuned Qwen generation, N-gram refinement) and reports direct empirical scores (mAP 0.979, CIDEr 0.030→0.094) on OpenEvents-V1. No equations, parameter-fitting steps, or self-citations appear in the provided text that could reduce any claimed result to its own inputs by construction. The central claims rest on external benchmark evaluation rather than internal definitions or fitted predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Banerjee, S., Lavie, A.: METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. pp. 65–72. ACL, Ann Arbor, Michi- gan (Jun 2005)
2005
-
[2]
Cornia, M., Stefanini, M., Baraldi, L., Cucchiara, R.: M2: Meshed-memory trans- former for image captioning. CoRRabs/1912.08226(2019)
arXiv 1912
-
[3]
Faghri, F., Fleet, D.J., Kiros, J.R., Fidler, S.: Vse++: Improving visual-semantic embeddings with hard negatives (2018)
2018
-
[4]
In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T
Gong, Y., Wang, L., Hodosh, M., Hockenmaier, J., Lazebnik, S.: Improving image- sentence embeddings using large weakly annotated photo collections. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) Computer Vision – ECCV 2014. pp. 529–545. Springer International Publishing, Cham (2014)
2014
-
[5]
Hessel, J., Holtzman, A., Forbes, M., Bras, R.L., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning (2022)
2022
-
[6]
Hossain, M.Z., Sohel, F., Shiratuddin, M.F., Laga, H.: A comprehensive survey of deep learning for image captioning. CoRRabs/1810.04020(2018)
Pith/arXiv arXiv 2018
-
[7]
ICLR1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022)
2022
-
[8]
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q.V., Sung, Y., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision (2021)
2021
-
[9]
In: Yarowsky, D., Baldwin, T., Korhonen, A., Livescu, K., Bethard, S
Kalchbrenner, N., Blunsom, P.: Recurrent continuous translation models. In: Yarowsky, D., Baldwin, T., Korhonen, A., Livescu, K., Bethard, S. (eds.) Proceed- ings of the 2013 Conference on Empirical Methods in Natural Language Processing. pp. 1700–1709. ACL, Seattle, Washington, USA (Oct 2013)
2013
-
[10]
Karpukhin, V., O˘ guz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., tau Yih, W.: Dense passage retrieval for open-domain question answering (2020)
2020
-
[11]
Lee,K.H.,Chen,X.,Hua,G.,Hu,H.,He,X.:Stackedcrossattentionforimage-text matching (2018) CIAN: Multi-Stage Framework for Event-Enriched Image Captioning 11
2018
-
[12]
arXiv preprint arXiv:1910.13461 (2019)
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., Stoyanov, V., Zettlemoyer, L.: Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461 (2019)
Pith/arXiv arXiv 1910
-
[13]
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., K¨ uttler, H., Lewis, M., tau Yih, W., Rockt¨ aschel, T., Riedel, S., Kiela, D.: Retrieval-augmented generation for knowledge-intensive nlp tasks (2021)
2021
-
[14]
Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation (2022)
2022
-
[15]
IEEE/CAA Journal of Automatica Sinica9(8), 1339–1365 (2022)
Ming, Y., Hu, N., Fan, C., Feng, F., Zhou, J., Yu, H.: Visuals to text: A compre- hensive review on automatic image captioning. IEEE/CAA Journal of Automatica Sinica9(8), 1339–1365 (2022)
2022
-
[16]
In: ACM International Conference on Multimedia (2025)
Nguyen, H., Nguyen, P.T., Tran, T.P., Nguyen, M.Q., Nguyen, T.V., Tran, M.T., Le, T.N.: Openevents v1: Large-scale benchmark dataset for multimodal event grounding. In: ACM International Conference on Multimedia (2025)
2025
-
[17]
In: Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., Weinberger, K
Ordonez, V., Kulkarni, G., Berg, T.: Im2text: Describing images using 1 million captioned photographs. In: Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., Weinberger, K. (eds.) Advances in Neural Information Processing Systems. vol. 24. Curran Associates, Inc. (2011)
2011
-
[18]
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. pp. 311–318. Association for Computational Linguistics, Philadelphia, Pennsylvania, USA (Jul 2002)
2002
-
[19]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021)
2021
-
[20]
Sarto, S., Cornia, M., Cucchiara, R.: Image captioning evaluation in the age of multimodal llms: Challenges and future perspectives (2025)
2025
-
[21]
Stefanini, M., Cornia, M., Baraldi, L., Cascianelli, S., Fiameni, G., Cucchiara, R.: From show to tell: A survey on deep learning-based image captioning (2021)
2021
-
[22]
Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks (2014)
2014
-
[23]
In: ACM International Conference on Multimedia (2025)
Tran, T.P., Nguyen, M.Q., Tran, M.T., Nguyen, T.V., Do, T.L., Ly, D.N., Huynh, V.T., Le, K.D., Tran, M.K., Le, T.N.: Event-enriched image analysis grand chal- lenge at acm multimedia 2025. In: ACM International Conference on Multimedia (2025)
2025
-
[24]
In: CVPR (June 2015)
Vedantam, R., Lawrence Zitnick, C., Parikh, D.: Cider: Consensus-based image description evaluation. In: CVPR (June 2015)
2015
-
[25]
Vedantam, R., Zitnick, C.L., Parikh, D.: Cider: Consensus-based image description evaluation (2015)
2015
-
[26]
arXiv preprint arXiv:2409.12191 (2024)
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., Fan, Y., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., Lin, J.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
Pith/arXiv arXiv 2024
-
[27]
National Science Review11(12) (Nov 2024)
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on multimodal large language models. National Science Review11(12) (Nov 2024)
2024
-
[28]
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre-training (2023)
2023
-
[29]
In: Proceedings of the 62nd Annual Meeting of the ACL (Volume 3: System Demonstrations)
Zheng, Y., Zhang, R., Zhang, J., Ye, Y., Luo, Z., Feng, Z., Ma, Y.: Llamafactory: Unified efficient fine-tuning of 100+ language models. In: Proceedings of the 62nd Annual Meeting of the ACL (Volume 3: System Demonstrations). ACL, Bangkok, Thailand (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.