RSRank: Learning Relevance from Representational Shifts
Pith reviewed 2026-06-26 23:03 UTC · model grok-4.3
The pith
The alignment between representational shifts induced by a candidate document and those from an oracle document set indicates relevance for reranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We identify a principled signal for relevance: the representational shift (RS) induced in a query's internal state when conditioned on a document. We observe that the alignment between (a) RS induced by a candidate document and (b) RS induced by an oracle document-set provides a robust indicator of relevance. Building on this insight, we introduce a lightweight training framework that learns projections mapping RS to calibrated relevance scores. Our training objectives naturally filter irrelevant content at a zero threshold, reducing dependence on heuristic tuning. Across diverse retrieval datasets, our method delivers gains over SOTA rerankers.
What carries the argument
Representational shift (RS) — the change in a query's internal state when conditioned on a document — with alignment to oracle-induced RS as the relevance indicator.
If this is right
- RS alignment supplies a relevance signal independent of next-token logits.
- Training projects RS values to scores that separate relevant from irrelevant content at a zero threshold.
- The approach reduces dependence on manual heuristic threshold selection in RAG rerankers.
- Performance improves over state-of-the-art rerankers on multiple retrieval datasets.
Where Pith is reading between the lines
- The same RS alignment could be tested as a relevance signal in non-RAG retrieval settings where internal states remain accessible.
- If the signal holds across model scales, the method might support reranking without requiring logit access or full model fine-tuning.
- The zero-threshold property might simplify deployment in production systems that must handle varying query distributions.
- Connections to other internal-state analyses in language models could be explored to see whether RS alignment generalizes beyond reranking.
Load-bearing premise
Representational shifts induced in a query's internal state when conditioned on documents form a principled and generalizable signal for relevance that can be projected to calibrated scores via lightweight training without dataset-specific overfitting.
What would settle it
On a held-out retrieval dataset, if alignment scores between candidate-document RS and oracle-set RS show no higher correlation with human relevance judgments than logit-based baselines, the central claim would be falsified.
Figures

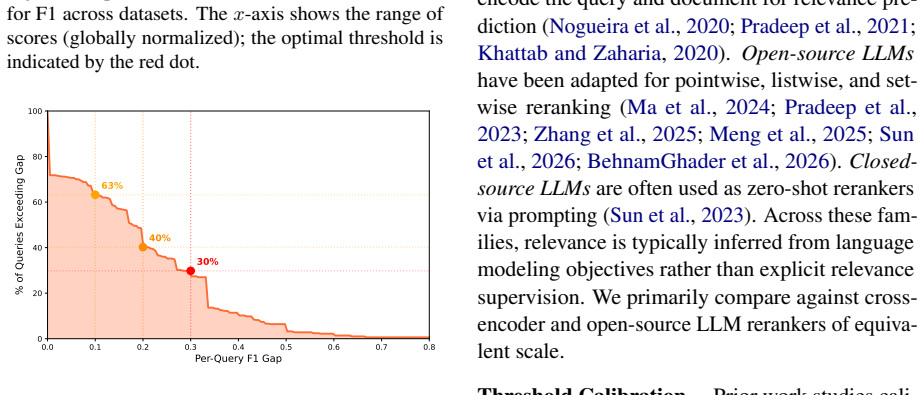
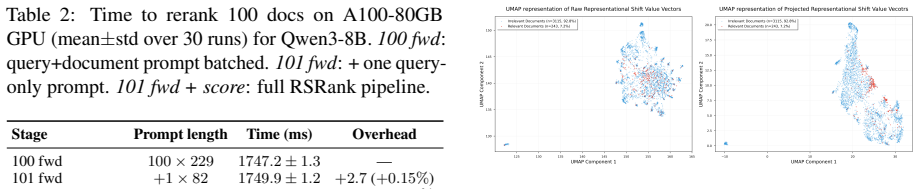
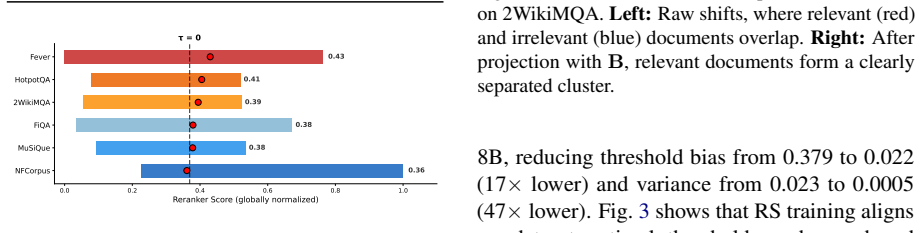

read the original abstract
As enterprises deploy RAG-based systems to provide grounded responses to user queries, reranking has become a critical component for the final filtering step that separates relevant from distracting or irrelevant documents. Existing rerankers often rely on heuristic thresholds to achieve optimal filtering. Moreover, for relevance scoring, state-of-the-art methods use a language model's logit signals, which are designed for next-token prediction, not for assessing relevance. To address these limitations, we identify a principled signal for relevance: the representational shift (RS) induced in a query's internal state when conditioned on a document. We observe that the alignment between (a) RS induced by a candidate document and (b) RS induced by an oracle document-set provides a robust indicator of relevance. Building on this insight, we introduce a lightweight training framework that learns projections mapping RS to calibrated relevance scores. Our training objectives naturally filter irrelevant content at a zero threshold, reducing dependence on heuristic tuning. Across diverse retrieval datasets, our method delivers gains over SOTA rerankers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RSRank for reranking in RAG systems. It identifies the representational shift (RS) induced in a query's internal state when conditioned on a document as a relevance signal, observing that alignment between the RS induced by a candidate document and the RS induced by an oracle document-set provides a robust indicator of relevance. A lightweight training framework learns projections mapping these RS vectors to calibrated relevance scores; the training objectives are described as naturally enabling zero-threshold filtering of irrelevant content. The method is reported to deliver gains over state-of-the-art rerankers across diverse retrieval datasets.
Significance. If the empirical observations and gains hold under full experimental scrutiny, the work supplies a relevance signal grounded in internal model states rather than next-token logits, together with a training procedure that reduces dependence on post-hoc thresholds. This could strengthen the final filtering step in enterprise RAG pipelines and offers a concrete alternative to existing logit-based rerankers.
minor comments (2)
- [Abstract] The abstract states that the method 'delivers gains over SOTA rerankers' but supplies no quantitative deltas, dataset names, or baseline comparisons; these must appear with error bars and ablation results in §4 or §5 to allow verification of the central claim.
- [§3] The description of the oracle document-set construction and the precise definition of 'alignment' between RS vectors should be expanded with an equation or pseudocode in §3 to make the signal reproducible.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work, the assessment of its potential significance for RAG pipelines, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper's central claim rests on an empirical observation that alignment between representational shifts (RS) from candidate documents and an oracle document-set serves as a relevance signal, followed by a lightweight training framework to project RS vectors to calibrated scores. No equations, self-definitional constructions, fitted parameters renamed as predictions, or load-bearing self-citations are present in the provided abstract or description. The derivation does not reduce to its inputs by construction; the training objectives are described as naturally producing zero-threshold filtering without evidence of statistical forcing or ansatz smuggling. This is a self-contained empirical approach against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Robertson, Stephen and Zaragoza, Hugo , title =. Found. Trends Inf. Retr. , month = apr, pages =. 2009 , issue_date =. doi:10.1561/1500000019 , abstract =
-
[2]
2026 , eprint=
LLM2Vec-Gen: Generative Embeddings from Large Language Models , author=. 2026 , eprint=
2026
-
[3]
2024 , eprint=
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders , author=. 2024 , eprint=
2024
-
[4]
Proceedings of the ACM Web Conference 2025 , year =
Chen, Yiqun and Liu, Qi and Zhang, Yi and Sun, Weiwei and Ma, Xinyu and Yang, Weiwei and Shi, Daiting and Mao, Jiaxin and Yin, Dawei , title =. Proceedings of the ACM Web Conference 2025 , year =. doi:10.1145/3696410.3714863 , publisher =
-
[5]
arXiv preprint arXiv:2312.02724 , year=
RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze! , author=. arXiv preprint arXiv:2312.02724 , year=
-
[6]
Zhuang, Shengyao and Zhuang, Honglei and Koopman, Bevan and Zuccon, Guido , title =. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2024 , isbn =. doi:10.1145/3626772.3657813 , abstract =
-
[7]
Attention-Guided Hierarchical Defense for Multimodal Attacks in Vision-Language Models , year=
Chen, Long and Chen, Yuling and Luo, Yun and Dou, Hui and Zhong, Xinyang , booktitle=. Attention-Guided Hierarchical Defense for Multimodal Attacks in Vision-Language Models , year=
-
[8]
Phukan, Anirudh and Somasundaram, Shwetha and Saxena, Apoorv and Goswami, Koustava and Srinivasan, Balaji Vasan. Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.682
-
[9]
2024 , url=
Jianyi Zhang and Da-Cheng Juan and Cyrus Rashtchian and Chun-Sung Ferng and Heinrich Jiang and Yiran Chen , booktitle=. 2024 , url=
2024
-
[10]
Document Re-Ranking With Evidential Neural Networks , year=
Yoon, Jeongnoh and Sael, Lee , journal=. Document Re-Ranking With Evidential Neural Networks , year=
-
[11]
CoRR , volume=
Le Zhang and Bo Wang and Xipeng Qiu and Siva Reddy and Aishwarya Agrawal , title=. CoRR , volume=. 2025 , month=
2025
-
[12]
On the Sentence Embeddings from Pre-trained Language Models
Li, Bohan and Zhou, Hao and He, Junxian and Wang, Mingxuan and Yang, Yiming and Li, Lei. On the Sentence Embeddings from Pre-trained Language Models. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.733
-
[13]
Proceedings of the ACM on Web Conference 2025 , pages =
Ren, Ruiyang and Wang, Yuhao and Zhou, Kun and Zhao, Wayne Xin and Wang, Wenjie and Liu, Jing and Wen, Ji-Rong and Chua, Tat-Seng , title =. Proceedings of the ACM on Web Conference 2025 , pages =. 2025 , isbn =. doi:10.1145/3696410.3714658 , abstract =
-
[14]
Ethayarajh, Kawin. How Contextual are Contextualized Word Representations? C omparing the Geometry of BERT , ELM o, and GPT -2 Embeddings. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1006
-
[15]
Yu, Puxuan and Cohen, Daniel and Lamba, Hemank and Tetreault, Joel R. and Jaimes, Alejandro. Explain then Rank: Scale Calibration of Neural Rankers Using Natural Language Explanations from LLM s. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1167
-
[16]
CoRR , volume=
Wenhan Liu and Xinyu Ma and Weiwei Sun and Yutao Zhu and Yuchen Li and Dawei Yin and Zhicheng Dou , title=. CoRR , volume=. 2025 , month=
2025
-
[17]
Relevance Scores Calibration for Ranked List Truncation via TMP Adapter
Posokhov, Pavel and Masliukhin, Sergei and Stepan, Skrylnikov and Tirskikh, Danil and Makhnytkina, Olesia. Relevance Scores Calibration for Ranked List Truncation via TMP Adapter. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.402
-
[18]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
AcuRank: Uncertainty-Aware Adaptive Computation for Listwise Reranking , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[19]
Certified Error Control of Candidate Set Pruning for Two-Stage Relevance Ranking
Li, Minghan and Zhang, Xinyu and Xin, Ji and Zhang, Hongyang and Lin, Jimmy. Certified Error Control of Candidate Set Pruning for Two-Stage Relevance Ranking. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.23
-
[20]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
Nandan Thakur and Nils Reimers and Andreas R. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
-
[21]
CoRR , volume=
Ronak Pradeep and Rodrigo Frassetto Nogueira and Jimmy Lin , title=. CoRR , volume=. 2021 , cdate=
2021
-
[22]
Khattab, Omar and Zaharia, Matei , title =. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2020 , isbn =. doi:10.1145/3397271.3401075 , abstract =
-
[23]
Document Ranking with a Pretrained Sequence-to-Sequence Model
Nogueira, Rodrigo and Jiang, Zhiying and Pradeep, Ronak and Lin, Jimmy. Document Ranking with a Pretrained Sequence-to-Sequence Model. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.63
-
[24]
Sparse, Dense, and Attentional Representations for Text Retrieval
Luan, Yi and Eisenstein, Jacob and Toutanova, Kristina and Collins, Michael. Sparse, Dense, and Attentional Representations for Text Retrieval. Transactions of the Association for Computational Linguistics. 2021. doi:10.1162/tacl_a_00369
-
[25]
Wang, Lidan and Lin, Jimmy and Metzler, Donald , title =. Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2011 , isbn =. doi:10.1145/2009916.2009934 , abstract =
-
[26]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. arXiv preprint arXiv:2506.05176 , year=
-
[27]
2020 , eprint=
Passage Re-ranking with BERT , author=. 2020 , eprint=
2020
-
[28]
Liu, Shichen and Xiao, Fei and Ou, Wenwu and Si, Luo , title =. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =. 2017 , isbn =. doi:10.1145/3097983.3098011 , abstract =
-
[29]
The Science Behind Semantic Search: How
-
[30]
Retrieval-augmented generation for knowledge-intensive NLP tasks , year =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-augmented generation for knowledge-intensive NLP tasks , year =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
-
[31]
2024 , note=
Rerankers and Two-Stage Retrieval , author=. 2024 , note=
2024
-
[32]
2024 , note=
Amazon. 2024 , note=
2024
-
[33]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[34]
Su, Jianlin and Ahmed, Murtadha and Lu, Yu and Pan, Shengfeng and Bo, Wen and Liu, Yunfeng , title =. 2024 , issue_date =. doi:10.1016/j.neucom.2023.127063 , journal =
-
[35]
https://huggingface.co/jinaai/jina-reranker-v2-base-multilingual
jinaai/jina-reranker-v2-base-multilingual · Hugging Face , url = "https://huggingface.co/jinaai/jina-reranker-v2-base-multilingual", month =
-
[36]
2025 , note=
Boost your Search and. 2025 , note=
2025
-
[37]
URL https://aclanthology.org/2024.tacl-1.9/
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00638
-
[38]
First Conference on Language Modeling , year=
How Easily do Irrelevant Inputs Skew the Responses of Large Language Models? , author=. First Conference on Language Modeling , year=
-
[39]
Introducing reranking to Pinecone Inference , author =
-
[40]
Is ChatGPT good at search? investigating large language models as re-ranking agents
Sun, Weiwei and Yan, Lingyong and Ma, Xinyu and Wang, Shuaiqiang and Ren, Pengjie and Chen, Zhumin and Yin, Dawei and Ren, Zhaochun. Is C hat GPT Good at Search? Investigating Large Language Models as Re-Ranking Agents. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.923
-
[41]
The Thirteenth International Conference on Learning Representations , year=
Attention in Large Language Models Yields Efficient Zero-Shot Re-Rankers , author=. The Thirteenth International Conference on Learning Representations , year=
-
[42]
Chen, Jianlyu and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng. M 3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.137
-
[43]
2023 , eprint=
Making Large Language Models A Better Foundation For Dense Retrieval , author=. 2023 , eprint=
2023
-
[44]
Is Anisotropy Truly Harmful? A Case Study on Text Clustering
Ait-Saada, Mira and Nadif, Mohamed. Is Anisotropy Truly Harmful? A Case Study on Text Clustering. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023. doi:10.18653/v1/2023.acl-short.103
-
[45]
CoRR , volume=
Shengyao Zhuang and Honglei Zhuang and Bevan Koopman and Guido Zuccon , title=. CoRR , volume=. 2023 , cdate=
2023
-
[46]
The Shape of Learning: Anisotropy and Intrinsic Dimensions in Transformer-Based Models
Razzhigaev, Anton and Mikhalchuk, Matvey and Goncharova, Elizaveta and Oseledets, Ivan and Dimitrov, Denis and Kuznetsov, Andrey. The Shape of Learning: Anisotropy and Intrinsic Dimensions in Transformer-Based Models. Findings of the Association for Computational Linguistics: EACL 2024. 2024
2024
-
[47]
Anisotropy Is Inherent to Self-Attention in Transformers
Godey, Nathan and Clergerie, \'E ric and Sagot, Beno \^i t. Anisotropy Is Inherent to Self-Attention in Transformers. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.eacl-long.3
-
[48]
Shrink the Longest: Improving Latent Space Isotropy with Simplicial Geometry
Kudrjashov, Sergej and Karpik, Olesya and Klyshinsky, Eduard. Shrink the Longest: Improving Latent Space Isotropy with Simplicial Geometry. Analysis of Images, Social Networks and Texts. 2025
2025
-
[49]
2024 , cdate=
Xueguang Ma and Liang Wang and Nan Yang and Furu Wei and Jimmy Lin , title=. 2024 , cdate=
2024
-
[50]
2026 , eprint=
Rethinking the Reranker: Boundary-Aware Evidence Selection for Robust Retrieval-Augmented Generation , author=. 2026 , eprint=
2026
-
[51]
CoRR , volume=
Siyuan Meng and Junming Liu and Yirong Chen and Song Mao and Pinlong Cai and Guohang Yan and Botian Shi and Ding Wang , title=. CoRR , volume=. 2025 , month=
2025
-
[52]
Forty-second International Conference on Machine Learning , year=
Layer by Layer: Uncovering Hidden Representations in Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[53]
Ho, Xanh and Duong Nguyen, Anh-Khoa and Sugawara, Saku and Aizawa, Akiko. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.580
-
[54]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1259
-
[55]
♫ M u S i Q ue: Multihop Questions via Single-hop Question Composition
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish. M u S i Q ue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00475
-
[56]
WWW'18 Open Challenge: Financial Opinion Mining and Question Answering , year =
Maia, Macedo and Handschuh, Siegfried and Freitas, Andr\'. WWW'18 Open Challenge: Financial Opinion Mining and Question Answering , year =. Companion Proceedings of the The Web Conference 2018 , pages =. doi:10.1145/3184558.3192301 , abstract =
-
[57]
InCoCo@NIPS 2016 (Workshop at NIPS/NeurIPS 2016) , year=
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset , author=. InCoCo@NIPS 2016 (Workshop at NIPS/NeurIPS 2016) , year=
2016
-
[58]
2018 , howpublished =
Quora Question Pairs Dataset , author =. 2018 , howpublished =
2018
-
[59]
FEVER: a large-scale dataset for Fact Extraction and VERification
Thorne, James and Vlachos, Andreas and Christodoulopoulos, Christos and Mittal, Arpit. FEVER : a Large-scale Dataset for Fact Extraction and VER ification. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1074
work page internal anchor Pith review doi:10.18653/v1/n18-1074 2018
-
[60]
Proceedings of the 38th European Conference on Information Retrieval (ECIR) , year =
Boteva, Vera and Gholipour, Demian and Sokolov, Artem and Riezler, Stefan , title =. Proceedings of the 38th European Conference on Information Retrieval (ECIR) , year =
-
[61]
2023 , eprint=
RoFormer: Enhanced Transformer with Rotary Position Embedding , author=. 2023 , eprint=
2023
-
[62]
Advances in Large Margin Classifiers , editor=
Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods , author=. Advances in Large Margin Classifiers , editor=. 1999 , pages=
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.