SEAGym: An Evaluation Environment for Self-Evolving LLM Agents
Pith reviewed 2026-06-27 01:30 UTC · model grok-4.3
The pith
SEAGym shows that multiple evaluation views are required to detect whether agent harness updates produce reusable gains or merely overfit recent tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SEAGym supplies dynamic task sources together with train, validation, test, replay, and cost views so that harness updates can be tracked for reusability, overfitting, cost growth, and retention of prior behavior; experiments on two benchmarks reveal that frequent updates may leave held-out performance unchanged, that intermediate snapshots can later degrade, and that source diversity plus model choice influence observed reliability.
What carries the argument
SEAGym evaluation environment that turns Harbor-compatible benchmarks into multi-view task sources with fixed update-validation, held-out transfer, replay, and snapshot recording.
If this is right
- Frequent harness updates can fail to raise held-out performance even while training scores rise.
- Intermediate snapshots that look strong on validation can later lose capability on the same tasks.
- Harness reliability depends on the diversity of task sources and the choice of model backend.
- Replay diagnostics are needed to detect whether an update harms earlier learned behavior.
Where Pith is reading between the lines
- Developers of self-evolving agents may need to optimize harnesses against a vector of views rather than a single scalar reward.
- Cost records could be used to penalize updates that increase token usage without corresponding generalization gains.
- The framework suggests that future work should test whether adding OOD transfer views changes which evolution method ranks highest.
Load-bearing premise
The selected benchmarks and shared epoch-batch protocol give an unbiased comparison of the three evolution methods without artifacts from task choice or model selection.
What would settle it
An experiment in which all evaluation views produce identical method rankings and identical conclusions about snapshot stability would falsify the claim that the views supply complementary signals.
Figures











read the original abstract
Self-evolving LLM-based agents improve mainly by changing their agent harness: the structured execution layer around a base model, including prompts, memory, tools, middleware, runtime state, and the model-tool interaction loop. Existing evaluations often reduce this process to isolated task scores or a single sequential curve, obscuring whether an update produces reusable improvement, overfits recent tasks, increases cost, or harms older behavior. We introduce SEAGym, an evaluation environment for measuring agent harness updates across training, validation, test, replay, and cost records. SEAGym turns Harbor-compatible benchmarks into dynamic self-evolution task sources with train batches, frozen update-validation, held-out ID and OOD transfer views, replay diagnostics, and saved snapshot and metric records. Instantiating SEAGym on Terminal-Bench 2.0 and HLE, we compare ACE, TF-GRPO, and AHE under a shared epoch/batch protocol. The results show that these evaluation views provide complementary signals about the evolution process: frequent updates may fail to improve held-out performance, useful intermediate snapshots may collapse later, and source diversity and model backend can affect harness reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SEAGym, an evaluation environment that converts Harbor-compatible benchmarks (Terminal-Bench 2.0 and HLE) into dynamic self-evolution task sources with train batches, frozen update-validation, held-out ID/OOD transfer, replay diagnostics, and cost records. It compares three harness-update methods (ACE, TF-GRPO, AHE) under a single shared epoch/batch protocol and claims that the multi-view evaluation yields complementary signals: frequent updates can fail to improve held-out performance, useful intermediate snapshots can later collapse, and source diversity plus model backend can affect reliability.
Significance. If the multi-view diagnostics are shown to be robust and the protocol artifacts are ruled out, SEAGym would provide a concrete advance over single-curve or isolated-task evaluations of self-evolving agents, enabling clearer detection of overfitting, collapse, and cost trade-offs. The work ships an explicit evaluation harness rather than isolated scores, which is a positive contribution to reproducibility in this area.
major comments (2)
- [Experimental protocol] Experimental protocol section: the central claim that the views supply complementary signals rests on the shared epoch/batch protocol being neutral across ACE, TF-GRPO, and AHE. No ablation or justification is given for the chosen batch sizes, epoch counts, or task ordering; if these hyperparameters are suboptimal for one method, the observed patterns (e.g., frequent updates failing held-out, snapshot collapse) could be protocol artifacts rather than intrinsic properties of self-evolution.
- [Results] Results on Terminal-Bench 2.0 and HLE: the claim that source diversity and model backend affect harness reliability is demonstrated only on the two chosen benchmarks. Without a sensitivity study across additional task distributions or an explicit check that task selection does not systematically favor certain update frequencies, the generality of the complementary-signals conclusion remains under-supported.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction use “Harbor-compatible” without a forward reference or brief definition; a one-sentence gloss would improve accessibility.
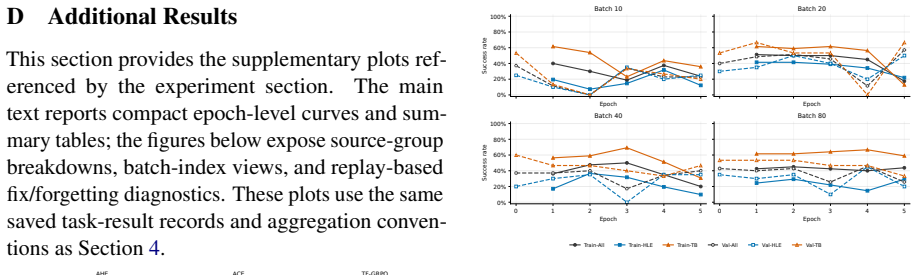
- [Figures] Figure captions for the multi-view diagrams should explicitly label which panels correspond to train, val, test, replay, and cost records.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on our manuscript. We address the major comments point by point below, indicating planned revisions where appropriate to strengthen the claims about complementary evaluation signals in SEAGym.
read point-by-point responses
-
Referee: [Experimental protocol] Experimental protocol section: the central claim that the views supply complementary signals rests on the shared epoch/batch protocol being neutral across ACE, TF-GRPO, and AHE. No ablation or justification is given for the chosen batch sizes, epoch counts, or task ordering; if these hyperparameters are suboptimal for one method, the observed patterns (e.g., frequent updates failing held-out, snapshot collapse) could be protocol artifacts rather than intrinsic properties of self-evolution.
Authors: We agree that justifying the shared protocol is important to support the claim of complementary signals. The protocol was designed to hold training conditions constant across methods, allowing us to attribute differences to the update strategies themselves. Specific choices for batch sizes and epochs were made to ensure feasible computation while providing multiple update opportunities within the self-evolution process. Task ordering was randomized per batch to avoid systematic biases. In the revised version, we will expand the experimental protocol section with a dedicated paragraph explaining these choices and their rationale, including references to preliminary tuning on smaller scales. This addresses the concern about potential artifacts. revision: yes
-
Referee: [Results] Results on Terminal-Bench 2.0 and HLE: the claim that source diversity and model backend affect harness reliability is demonstrated only on the two chosen benchmarks. Without a sensitivity study across additional task distributions or an explicit check that task selection does not systematically favor certain update frequencies, the generality of the complementary-signals conclusion remains under-supported.
Authors: The two benchmarks were chosen to represent different domains: Terminal-Bench 2.0 for practical terminal interactions and HLE for advanced reasoning tasks, providing initial evidence that source diversity impacts reliability. We acknowledge that this does not constitute a full sensitivity analysis across many distributions. To strengthen the manuscript, we will add a limitations paragraph in the discussion noting the scope of the benchmarks used and the need for future work on broader task sets. Additionally, we will include an explicit statement that task selection was based on availability in Harbor-compatible format rather than optimization for specific methods. revision: partial
Circularity Check
No circularity: purely empirical evaluation framework with no derivations
full rationale
The paper describes SEAGym, an evaluation harness for agent evolution, and reports empirical results from running ACE, TF-GRPO, and AHE on Terminal-Bench 2.0 and HLE under a shared protocol. No equations, parameter fits, predictions, or derivation chains exist that could reduce to inputs by construction. Claims about complementary signals rest on direct experimental observations rather than self-definitional mappings, fitted inputs renamed as predictions, or load-bearing self-citations. The work is self-contained as a benchmark and protocol description; the reader's assessment of score 1.0 aligns with the absence of any mathematical or definitional circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2023 , url =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , url =
2023
-
[2]
Advances in Neural Information Processing Systems , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems , year =
-
[3]
Advances in Neural Information Processing Systems , year =
Self-Refine: Iterative Refinement with Self-Feedback , author =. Advances in Neural Information Processing Systems , year =
-
[4]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle =
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle =. 2024 , url =
2024
-
[5]
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle =. 2024 , url =
2024
-
[6]
2024 , url =
Xie, Tianbao and Zhang, Danyang and Chen, Jixuan and Li, Xiaochuan and Zhao, Siheng and Cao, Ruisheng and Hua, Tuo and Cheng, Zhoujun and Shin, Dongchan and Lei, Fangyu and Liu, Yiheng and Xu, Yiheng and Zhou, Shuyan and Savarese, Silvio and Xiong, Caiming and Zhong, Victor and Yu, Tao , journal =. 2024 , url =
2024
-
[7]
International Conference on Learning Representations , year =
Mialon, Gr. International Conference on Learning Representations , year =
-
[8]
and Mao, Huanzhi and Yan, Fanjia and Ji, Charlie Cheng-Jie and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E
Patil, Shishir G. and Mao, Huanzhi and Yan, Fanjia and Ji, Charlie Cheng-Jie and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E. , booktitle =. The. 2025 , url =
2025
-
[9]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
tau-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author =. arXiv preprint arXiv:2406.12045 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
2026 , url =
Merrill, William and others , journal =. 2026 , url =
2026
-
[11]
Humanity's Last Exam , author =. arXiv preprint arXiv:2501.14249 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2412.19437 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
2026 , howpublished =
2026
-
[14]
2025 , howpublished =
2025
-
[15]
2025 , url =
Zeng, Aohan and others , journal =. 2025 , url =
2025
-
[16]
Neural Networks , volume =
Continual Lifelong Learning with Neural Networks: A Review , author =. Neural Networks , volume =. 2019 , doi =
2019
-
[17]
2026 , url =
Jiang, Sihang and Ma, Lipeng and Hong, Zhonghua and Wang, Keyi and Lu, Zhiyu and Chen, Shisong and Zhang, Jinghao and Pan, Tianjun and Zhou, Weijia and Liang, Jiaqing and Xiao, Yanghua , journal =. 2026 , url =
2026
-
[18]
2025 , url =
Zheng, Junhao and Cai, Xidi and Li, Qiuke and Zhang, Duzhen and Li, ZhongZhi and Zhang, Yingying and Song, Le and Ma, Qianli , journal =. 2025 , url =
2025
-
[19]
Advances in Neural Information Processing Systems , year =
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. Advances in Neural Information Processing Systems , year =
-
[20]
and Zhang, Tianjun and Wang, Xin and Gonzalez, Joseph E
Patil, Shishir G. and Zhang, Tianjun and Wang, Xin and Gonzalez, Joseph E. , journal =. Gorilla: Large Language Model Connected with Massive. 2023 , url =
2023
-
[21]
2024 , url =
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Hong, Lauren and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , booktitle =. 2024 , url =
2024
-
[22]
2025 , doi =
Yuan, Siyu and Song, Kaitao and Chen, Jiangjie and Tan, Xu and Shen, Yongliang and Kan, Ren and Li, Dongsheng and Yang, Deqing , booktitle =. 2025 , doi =
2025
-
[23]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An Open-Ended Embodied Agent with Large Language Models , author =. arXiv preprint arXiv:2305.16291 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Wang, Xingyao and Rosenberg, Simon and Michelini, Juan and Smith, Calvin and Tran, Hoang and Nyst, Engel and Malhotra, Rohit and Zhou, Xuhui and Chen, Valerie and Brennan, Robert and others , journal =. The. 2025 , url =
2025
-
[25]
and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle =
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle =. 2024 , url =
2024
-
[26]
How Memory Management Impacts
Xiong, Guangzhi and Jin, Qiao and Zhang, Zhizheng and Lu, Xiao and Wang, Zhiyong and Ma, Meng and Wang, Xunzhu and Wang, Yiyang and Liu, Yikai and Sun, Huaxiu and Wang, Fei and Liu, Zhiyong and Liu, Chenyan , booktitle =. How Memory Management Impacts. 2025 , url =
2025
-
[27]
A Survey of Agent Interoperability Protocols: Model Context Protocol (
Ehtesham, Usama and Dib, Salam and Almajali, Sufian and Peixoto, Tiago and Bhattacharya, Jay and Singla, Anupam and Diamantopoulos, Themistoklis , journal =. A Survey of Agent Interoperability Protocols: Model Context Protocol (. 2025 , url =
2025
-
[28]
and Sun, Jun , booktitle =
Wang, Haoyu and Poskitt, Christopher M. and Sun, Jun , booktitle =. 2026 , url =
2026
-
[29]
2026 , note =
Agent Harness Engineering: A Survey , author =. 2026 , note =
2026
-
[30]
2026 , howpublished =
Harness Engineering: Leveraging. 2026 , howpublished =
2026
-
[31]
2026 , howpublished =
Harness Design for Long-Running Application Development , author =. 2026 , howpublished =
2026
-
[32]
2025 , howpublished =
Agent Frameworks, Runtimes, and Harnesses - Oh My! , author =. 2025 , howpublished =
2025
-
[33]
2026 , howpublished =
How Middleware Lets You Customize Your Agent Harness , author =. 2026 , howpublished =
2026
-
[34]
Natural-Language Agent Harnesses
Natural-Language Agent Harnesses , author =. arXiv preprint arXiv:2603.25723 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
International Conference on Learning Representations , year =
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models , author =. International Conference on Learning Representations , year =
-
[36]
and Tan, Shangyin and Soylu, Dilara and Ziems, Noah and Khare, Rishi and Opsahl-Ong, Krista and Singhvi, Arnav and Shandilya, Herumb and Ryan, Michael J
Agrawal, Lakshya A. and Tan, Shangyin and Soylu, Dilara and Ziems, Noah and Khare, Rishi and Opsahl-Ong, Krista and Singhvi, Arnav and Shandilya, Herumb and Ryan, Michael J. and Jiang, Meng and Potts, Christopher and Sen, Koushik and Dimakis, Alexandros G. and Stoica, Ion and Klein, Dan and Zaharia, Matei and Khattab, Omar , booktitle =. 2026 , url =
2026
-
[37]
arXiv preprint arXiv:2510.08191 , year=
Training-Free Group Relative Policy Optimization , author =. arXiv preprint arXiv:2510.08191 , year =
-
[38]
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses , author =. arXiv preprint arXiv:2604.25850 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Connection Science , volume =
Catastrophic Forgetting, Rehearsal and Pseudorehearsal , author =. Connection Science , volume =. 1995 , doi =
1995
-
[40]
Proceedings of the National Academy of Sciences , volume =
Overcoming Catastrophic Forgetting in Neural Networks , author =. Proceedings of the National Academy of Sciences , volume =. 2017 , doi =
2017
-
[41]
Advances in Neural Information Processing Systems , year =
Gradient Episodic Memory for Continual Learning , author =. Advances in Neural Information Processing Systems , year =
-
[42]
On Tiny Episodic Memories in Continual Learning
On Tiny Episodic Memories in Continual Learning , author =. arXiv preprint arXiv:1902.10486 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[43]
Three scenarios for continual learning
Three Scenarios for Continual Learning , author =. arXiv preprint arXiv:1904.07734 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[44]
A Comprehensive Survey of Self-Evolving
Fang, Jinyuan and Peng, Yanwen and Zhang, Xi and Wang, Yingxu and Yi, Xinhao and Zhang, Guibin and Xu, Yi and Wu, Bin and Liu, Siwei and Li, Zihao and Ren, Zhaochun and Aletras, Nikos and Wang, Xi and Zhou, Han and Meng, Zaiqiao , journal =. A Comprehensive Survey of Self-Evolving. 2025 , url =
2025
-
[45]
International Conference on Machine Learning , year =
Self-Rewarding Language Models , author =. International Conference on Machine Learning , year =
-
[46]
Training Language Models to Self-Correct via Reinforcement Learning
Training Language Models to Self-Correct via Reinforcement Learning , author =. arXiv preprint arXiv:2409.12917 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Rewarding Progress: Scaling Automated Process Verifiers for
Setlur, Amrith and Nagpal, Chirag and Fisch, Adam and Geng, Xinyang and Eisenstein, Jacob and Agarwal, Rishabh and Agarwal, Alekh and Berant, Jonathan and Kumar, Aviral , booktitle =. Rewarding Progress: Scaling Automated Process Verifiers for. 2025 , url =
2025
-
[48]
Process Reward Models for
Choudhury, Sanjiban , journal =. Process Reward Models for. 2025 , url =
2025
-
[49]
2025 , url =
Wang, Zihan and Wang, Kangrui and Wang, Qineng and Zhang, Pingyue and Li, Linjie and Yang, Zhengyuan and Jin, Xing and Yu, Kefan and Nguyen, Minh Nhat and Liu, Licheng and Gottlieb, Eli and Lu, Yiping and Cho, Kyunghyun and Wu, Jiajun and Fei-Fei, Li and Wang, Lijuan and Choi, Yejin and Li, Manling , journal =. 2025 , url =
2025
-
[50]
2025 , url =
Feng, Jiazhan and Huang, Shijue and Qu, Xingwei and Zhang, Ge and Qin, Yujia and Zhong, Baoquan and Jiang, Chengquan and Chi, Jinxin and Zhong, Wanjun , journal =. 2025 , url =
2025
-
[51]
International Conference on Machine Learning , year =
Language Agents as Optimizable Graphs , author =. International Conference on Machine Learning , year =
-
[52]
2025 , url =
Zhang, Jiayi and Xiang, Jinyu and Yu, Zhaoyang and Teng, Fengwei and Chen, Xionghui and Chen, Jiaqi and Zhuge, Mingchen and Cheng, Xin and Hong, Sirui and Wang, Jinlin and Zheng, Bingnan and Liu, Bang and Luo, Yuyu and Wu, Chenglin , journal =. 2025 , url =
2025
-
[53]
Agent Workflow Memory , author =. arXiv preprint arXiv:2409.07429 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
2025 , url =
Yuan, Siyu and Song, Kaitao and Chen, Jiangjie and Tan, Xu and Li, Dongsheng and Yang, Deqing , journal =. 2025 , url =
2025
-
[55]
2025 , url =
Xu, Wujiang and Liang, Zujie and Mei, Kai and Gao, Hang and Tan, Juntao and Zhang, Yongfeng , journal =. 2025 , url =
2025
-
[56]
Tang, Xiangru and Qin, Tianrui and Peng, Tianhao and Zhou, Ziyang and Shao, Daniel and Du, Tingting and Wei, Xinming and Xia, Peng and Wu, Fang and Zhu, He and Zhang, Ge and Liu, Jiaheng and Wang, Xingyao and Hong, Sirui and Wu, Chenglin and Cheng, Hao and Wang, Chi and Zhou, Wangchunshu , journal =. Agent. 2025 , url =
2025
-
[57]
Survey on Evaluation of
Yehudai, Asaf and Eden, Lilach and Li, Alan and Uziel, Guy and Zhao, Yilun and Bar-Haim, Roy and Cohan, Arman and Shmueli-Scheuer, Michal , journal =. Survey on Evaluation of. 2026 , url =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.