Collaborative Large and Small Language Models for Accurate and Scalable Data Repair
Pith reviewed 2026-06-26 22:22 UTC · model grok-4.3
The pith
LasRepair++ pairs an LLM instructor with an SLM corrector, refines context via EM, and applies column-calibrated confidence to improve data repair.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
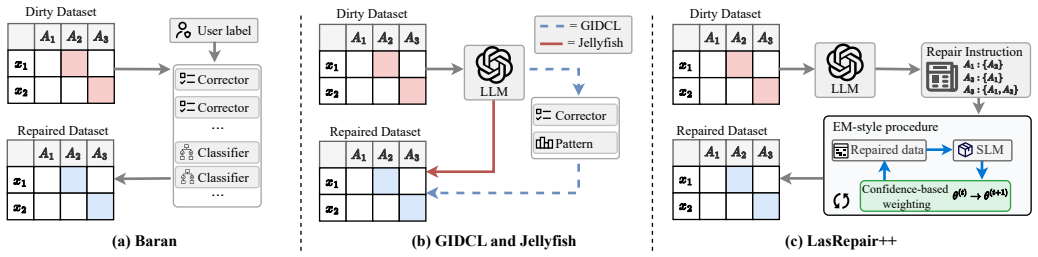
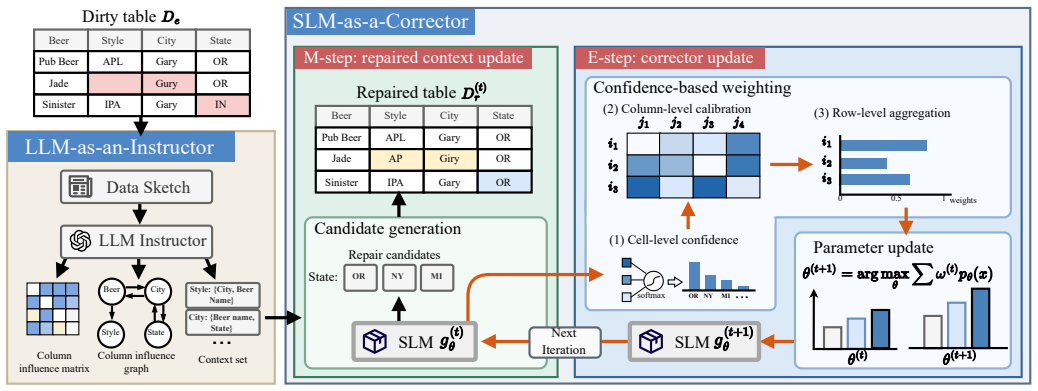
LasRepair uses an LLM to select global repair context that guides an SLM corrector; LasRepair+ casts the process as an EM procedure that alternates E-step parameter updates with M-step context refinement; LasRepair++ further weights rows by column-calibrated model confidence to down-weight unreliable repairs. Theoretical analysis proves the EM procedure and weighting are effective, and experiments on real-world datasets show LasRepair++ achieves an average 18.1% F1-score improvement over the strongest baseline.
What carries the argument
The LasRepair framework, in which the LLM instructor selects a global repair context to guide the SLM corrector, extended by an EM alternation for context refinement and column-calibrated confidence weighting to suppress unreliable rows.
If this is right
- The EM-style alternation between corrector updates and context refinement raises repair quality.
- Column-calibrated confidence weighting reduces the effect of uncertain model outputs on the final repairs.
- Using the SLM for the actual correction step improves efficiency while the LLM supplies only high-level guidance.
- The theoretical guarantees on the EM procedure and weighting hold under the stated model assumptions.
Where Pith is reading between the lines
- The same instructor-corrector split could be tested on other data-cleaning subtasks such as duplicate detection or schema matching.
- If context selection quality varies across domains, the method may need an explicit verification step before EM begins.
- The approach suggests that hybrid large-small model pipelines can trade off accuracy and compute in settings where full LLM inference on every row is too costly.
Load-bearing premise
The LLM can reliably choose a global repair context that improves the SLM corrector's learning signal rather than adding noise or bias.
What would settle it
A controlled test in which the LLM supplies deliberately poor or random contexts and the resulting SLM repair F1 score after EM updates is lower than when no context is supplied.
Figures







read the original abstract
We study the problem of data repair, a key task in data cleaning that corrects erroneous entries in raw datasets to improve overall data quality. Although recent data-driven methods, especially those based on large language models (LLMs), achieve remarkable performance, we observe that: (i) they directly repair data in the raw and low-quality context, which may compromise learning signals, and (ii) they directly use uncertain model outputs as repairs, potentially introducing unreliable corrections and compromising repair quality. Motivated by the efficiency of small language models (SLMs) and the capabilities of LLMs, and aiming to address the above limitations, we propose LasRepair, a framework that collaborates Large and small language models for data repair. LasRepair employs an LLM as an instructor, which selects a global repair context to guide the SLM. The SLM acts as a corrector, using the selected context to repair erroneous data more efficiently. Moreover, to further improve context quality, we extend LasRepair to LasRepair+, which formulates data repair as an Expectation-Maximisation (EM) procedure that alternates between an E-step for updating the corrector parameters and an M-step for refining the repair context. Furthermore, to mitigate model uncertainty, we propose LasRepair++, which uses column-calibrated model confidence to down-weight unreliable repaired rows when updating the corrector, thereby enhancing repair quality. Theoretical analysis and empirical evaluation demonstrate the superiority of our methods. We theoretically prove the effectiveness of the EM-style procedure and the confidence-based weighting. Experiments on real-world datasets show that LasRepair++~ achieves an average F1-score improvement of 18.1% over the strongest baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LasRepair, a framework collaborating LLMs (as instructors selecting global repair contexts) with SLMs (as correctors) for data repair. It extends to LasRepair+ via an EM procedure alternating E-step (corrector parameter updates) and M-step (context refinement), and to LasRepair++ adding column-calibrated confidence weighting to down-weight unreliable rows. The authors claim theoretical proofs for the EM procedure and weighting scheme, plus empirical results where LasRepair++ achieves 18.1% average F1 improvement over the strongest baseline on real-world datasets.
Significance. If the central claims hold, the work offers a promising direction for scalable data repair by leveraging LLM contextual capabilities with SLM efficiency while mitigating uncertainty via EM and weighting. The provision of theoretical analysis alongside empirical evaluation on real datasets is a strength, though the load-bearing premise on context selection requires further substantiation for the gains to be fully attributable to the proposed components.
major comments (3)
- [Abstract and §3] Abstract and §3 (Framework): The 18.1% F1 improvement is credited to the LLM instructor's selection of global repair context improving the SLM corrector's learning signal, yet no ablation isolating this selection (e.g., vs. random/fixed contexts or raw data) is reported; without it, alternative explanations such as introduction of correlated bias or noise cannot be ruled out, undermining attribution of the gain to LasRepair++.
- [§4] §4 (Theoretical Analysis): The claimed proofs for the EM-style procedure and confidence weighting do not explicitly address the potential circular dependence, where both E-step updates and M-step refinements operate on outputs from the same model being optimized; this risks making the analysis non-independent, as noted in the abstract's assertion of 'independent theoretical analysis'.
- [§5] §5 (Experiments): The reported average F1 lift lacks accompanying details on data splits, variance across runs, statistical significance, or error analysis, which are necessary to evaluate robustness of the 18.1% claim against post-hoc choices or dataset-specific effects.
minor comments (2)
- [Abstract] The progression from LasRepair to LasRepair+ to LasRepair++ could be more clearly delineated in the abstract and introduction to avoid notation confusion for readers.
- [§4] Variable definitions in the EM formulation and confidence weighting equations would benefit from explicit cross-references to avoid ambiguity in the derivations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Framework): The 18.1% F1 improvement is credited to the LLM instructor's selection of global repair context improving the SLM corrector's learning signal, yet no ablation isolating this selection (e.g., vs. random/fixed contexts or raw data) is reported; without it, alternative explanations such as introduction of correlated bias or noise cannot be ruled out, undermining attribution of the gain to LasRepair++.
Authors: We agree that an ablation isolating the contribution of the LLM instructor's global context selection is needed to rule out alternative explanations. The current manuscript does not report such an ablation. In the revision we will add experiments comparing LasRepair++ against variants that use random contexts, fixed contexts, and raw data without instructor selection. revision: yes
-
Referee: [§4] §4 (Theoretical Analysis): The claimed proofs for the EM-style procedure and confidence weighting do not explicitly address the potential circular dependence, where both E-step updates and M-step refinements operate on outputs from the same model being optimized; this risks making the analysis non-independent, as noted in the abstract's assertion of 'independent theoretical analysis'.
Authors: The proofs in §4 follow standard EM convergence arguments and weighting analysis. We acknowledge that the section does not explicitly discuss potential circular dependence arising from E- and M-steps operating on outputs of the same model. We will revise §4 to clarify this point and adjust the independence claim in the abstract accordingly. revision: yes
-
Referee: [§5] §5 (Experiments): The reported average F1 lift lacks accompanying details on data splits, variance across runs, statistical significance, or error analysis, which are necessary to evaluate robustness of the 18.1% claim against post-hoc choices or dataset-specific effects.
Authors: We agree that robustness details are required. The revised manuscript will report data-split methodology, variance across multiple runs, statistical significance tests, and error analysis to support the 18.1% average F1 improvement. revision: yes
Circularity Check
No circularity: framework and EM procedure are standard and self-contained
full rationale
The abstract describes a collaborative LLM-SLM framework, an EM-style alternation for context refinement, and column-calibrated weighting, with a claimed theoretical proof of effectiveness. No equations, self-citations, or derivations are supplied that reduce any claimed result to a fitted input or self-defined quantity by construction. The EM loop follows the classic E/M structure without evidence that the 'prediction' of improvement is forced by the same outputs being optimized. The 18.1% F1 claim is presented as empirical, not as a derived identity. This is the normal case of an independent engineering contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cleanml: A study for evaluating the impact of data cleaning on ml classification tasks,
P. Li, X. Rao, J. Blase, Y . Zhang, X. Chu, and C. Zhang, “Cleanml: A study for evaluating the impact of data cleaning on ml classification tasks,” 2021. [Online]. Available: https://arxiv.org/abs/1904.09483
arXiv 2021
-
[2]
On llm- enhanced mixed-type data imputation with high-order message passing,
J. Wang, K. Wang, Y . Zhang, W. Zhang, X. Xu, and X. Lin, “On llm- enhanced mixed-type data imputation with high-order message passing,”
-
[3]
Available: https://arxiv.org/abs/2501.02191
[Online]. Available: https://arxiv.org/abs/2501.02191
-
[4]
Datacomp-lm: In search of the next gen- eration of training sets for language models,
J. Li, A. Fang, G. Smyrnis, M. Ivgi, M. Jordan, S. Gadre, H. Bansal, E. Guha, S. Keh, K. Arora, S. Garg, R. Xin, N. Muennighoff, R. Heckel, J. Mercat, M. Chen, S. Gururangan, M. Wortsman, A. Albalak, Y . Bitton, M. Nezhurina, A. Abbas, C.-Y . Hsieh, D. Ghosh, J. Gardner, M. Kilian, H. Zhang, R. Shao, S. Pratt, S. Sanyal, G. Ilharco, G. Daras, K. Marathe, ...
Pith/arXiv arXiv 2025
-
[5]
Data cleaning: Problems and current approaches,
E. Rahm and H. Do, “Data cleaning: Problems and current approaches,” IEEE Data Eng. Bull., vol. 23, pp. 3–13, 01 2000
2000
-
[6]
I. F. Ilyas and X. Chu,Data Cleaning. New York, NY , USA: Association for Computing Machinery, 2019
2019
-
[7]
Ensembling llm-induced decision trees for explainable and robust error detection,
M. Wang, J. Wang, Q. Liu, X. Xu, Z. Xing, L. Zhu, and W. Zhang, “Ensembling llm-induced decision trees for explainable and robust error detection,” 2025. [Online]. Available: https://arxiv.org/abs/2512.07246
arXiv 2025
-
[8]
Automatic data repair: Are we ready to deploy?
W. Ni, X. Miao, X. Zhao, Y . Wu, S. Liang, and J. Yin, “Automatic data repair: Are we ready to deploy?”Proc. VLDB Endow., vol. 17, no. 10, pp. 2617–2630, 2024. [Online]. Available: https://www.vldb.org/pvldb/ vol17/p2617-miao.pdf
2024
-
[9]
Holistic data cleaning: Putting violations into context,
X. Chu, I. F. Ilyas, and P. Papotti, “Holistic data cleaning: Putting violations into context,” in2013 IEEE 29th International Conference on Data Engineering (ICDE), 2013, pp. 458–469
2013
-
[10]
Bigdansing: A system for big data cleansing,
Z. Khayyat, I. F. Ilyas, A. Jindal, S. Madden, M. Ouzzani, P. Papotti, J. Quian´e-Ruiz, N. Tang, and S. Yin, “Bigdansing: A system for big data cleansing,” inProceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, Victoria, Australia, May 31 - June 4, 2015, T. K. Sellis, S. B. Davidson, and Z. G. Ives, Eds. ACM, 2015,...
-
[11]
A hybrid data cleaning framework using markov logic networks,
Y . Gao, C. Ge, X. Miao, H. Wang, B. Yao, and Q. Li, “A hybrid data cleaning framework using markov logic networks,” 2019. [Online]. Available: https://arxiv.org/abs/1903.05826
Pith/arXiv arXiv 2019
-
[12]
Horizon: scalable dependency-driven data cleaning,
E. K. Rezig, M. Ouzzani, W. G. Aref, A. K. Elmagarmid, A. R. Mahmood, and M. Stonebraker, “Horizon: scalable dependency-driven data cleaning,”Proc. VLDB Endow., vol. 14, no. 11, p. 2546–2554, Jul
-
[13]
Available: https://doi.org/10.14778/3476249.3476301
[Online]. Available: https://doi.org/10.14778/3476249.3476301
-
[14]
Nadeef: a commodity data cleaning system,
M. Dallachiesa, A. Ebaid, A. Eldawy, A. Elmagarmid, I. F. Ilyas, M. Ouzzani, and N. Tang, “Nadeef: a commodity data cleaning system,” inProceedings of the 2013 ACM SIGMOD International Conference on Management of Data, ser. SIGMOD ’13. New York, NY , USA: Association for Computing Machinery, 2013, p. 541–552. [Online]. Available: https://doi.org/10.1145/2...
-
[15]
Holoclean: Holistic data repairs with probabilistic inference,
T. Rekatsinas, X. Chu, I. F. Ilyas, and C. R ´e, “Holoclean: Holistic data repairs with probabilistic inference,”Proc. VLDB Endow., vol. 10, no. 11, pp. 1190–1201, 2017. [Online]. Available: http://www.vldb.org/ pvldb/vol10/p1190-rekatsinas.pdf
2017
-
[16]
A unified model for data and constraint repair,
F. Chiang and R. J. Miller, “A unified model for data and constraint repair,” inProceedings of the 27th International Conference on Data Engineering, ICDE 2011, April 11-16, 2011, Hannover, Germany, S. Abiteboul, K. B ¨ohm, C. Koch, and K. Tan, Eds. IEEE Computer Society, 2011, pp. 446–457. [Online]. Available: https://doi.org/10.1109/ ICDE.2011.5767833
arXiv 2011
-
[17]
On the relative trust between inconsistent data and inaccurate constraints,
G. Beskales, I. F. Ilyas, L. Golab, and A. Galiullin, “On the relative trust between inconsistent data and inaccurate constraints,” 2012. [Online]. Available: https://arxiv.org/abs/1207.5226
Pith/arXiv arXiv 2012
-
[18]
Conditional functional dependencies for data cleaning,
P. Bohannon, W. Fan, F. Geerts, X. Jia, and A. Kementsietsidis, “Conditional functional dependencies for data cleaning,” in2007 IEEE 23rd International Conference on Data Engineering, 2007, pp. 746–755
2007
-
[19]
Don’t be scared: use scalable automatic repairing with maximal likelihood and bounded changes,
M. Yakout, L. Berti- ´Equille, and A. K. Elmagarmid, “Don’t be scared: use scalable automatic repairing with maximal likelihood and bounded changes,” inProceedings of the ACM SIGMOD International Confer- ence on Management of Data, SIGMOD 2013, New York, NY, USA, June 22-27, 2013, K. A. Ross, D. Srivastava, and D. Papadias, Eds. ACM, 2013, pp. 553–564. [O...
arXiv 2013
-
[20]
Baran: Effective error correction via a unified context representation and transfer learning,
M. Mahdavi and Z. Abedjan, “Baran: Effective error correction via a unified context representation and transfer learning,”Proc. VLDB Endow., vol. 13, no. 11, pp. 1948–1961, 2020. [Online]. Available: http://www.vldb.org/pvldb/vol13/p1948-mahdavi.pdf
1948
-
[21]
GIDCL: A graph- enhanced interpretable data cleaning framework with large language models,
M. Yan, Y . Wang, Y . Wang, X. Miao, and J. Li, “GIDCL: A graph- enhanced interpretable data cleaning framework with large language models,”Proc. ACM Manag. Data, vol. 2, no. 6, pp. 236:1–236:29,
-
[22]
Available: https://doi.org/10.1145/3698811
[Online]. Available: https://doi.org/10.1145/3698811
-
[23]
Jellyfish: A large language model for data preprocessing,
H. Zhang, Y . Dong, C. Xiao, and M. Oyamada, “Jellyfish: A large language model for data preprocessing,” 2024. [Online]. Available: https://arxiv.org/abs/2312.01678
arXiv 2024
-
[24]
Stochastic gradient descent as approximate bayesian inference,
S. Mandt, M. D. Hoffman, and D. M. Blei, “Stochastic gradient descent as approximate bayesian inference,” 2018. [Online]. Available: https: //arxiv.org/abs/1704.04289
Pith/arXiv arXiv 2018
-
[25]
Uncertainty estimation in autoregressive structured prediction,
A. Malinin and M. Gales, “Uncertainty estimation in autoregressive structured prediction,” 2021. [Online]. Available: https://arxiv.org/abs/ 2002.07650
arXiv 2021
-
[26]
Listwise deletion in high dimensions,
J. S. Wang and P. M. Aronow, “Listwise deletion in high dimensions,” Political Analysis, vol. 31, no. 1, p. 149–155, 2023
2023
-
[27]
An introduction to variable and feature selection,
I. Guyon and A. Elisseeff, “An introduction to variable and feature selection,”J. Mach. Learn. Res., vol. 3, no. null, p. 1157–1182, Mar. 2003
2003
-
[28]
Efficient feature selection via analysis of relevance and redundancy,
L. Yu and H. Liu, “Efficient feature selection via analysis of relevance and redundancy,”J. Mach. Learn. Res., vol. 5, p. 1205–1224, Dec. 2004
2004
-
[29]
Hyperjoin: Llm-augmented hypergraph link prediction for joinable table discovery,
S. Liu, J. Wang, X. Lin, L. Qin, W. Zhang, and Y . Zhang, “Hyperjoin: Llm-augmented hypergraph link prediction for joinable table discovery,”
-
[30]
Available: https://arxiv.org/abs/2601.01015
[Online]. Available: https://arxiv.org/abs/2601.01015
-
[31]
Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift,
Y . Ovadia, E. Fertig, J. Ren, Z. Nado, D. Sculley, S. Nowozin, J. V . Dillon, B. Lakshminarayanan, and J. Snoek, “Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift,” 2019. [Online]. Available: https://arxiv.org/abs/1906.02530
arXiv 2019
-
[32]
Missing data im- putation with uncertainty-driven network,
J. Wang, Y . Zhang, K. Wang, X. Lin, and W. Zhang, “Missing data im- putation with uncertainty-driven network,” vol. 2, no. 3, 2024. [Online]. Available: https://doi.org/10.1145/3654920
-
[33]
Underspecification presents challenges for credibility in modern machine learning,
A. D’Amour, K. Heller, D. Moldovan, B. Adlam, B. Alipanahi, A. Beu- tel, C. Chen, J. Deaton, J. Eisenstein, M. D. Hoffman, F. Hormozdi- ari, N. Houlsby, S. Hou, G. Jerfel, A. Karthikesalingam, M. Lucic, Y . Ma, C. McLean, D. Mincu, A. Mitani, A. Montanari, Z. Nado, V . Natarajan, C. Nielson, T. F. Osborne, R. Raman, K. Ramasamy, R. Sayres, J. Schrouff, M....
arXiv 2020
-
[34]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging llm-as-a-judge with mt-bench and chatbot arena,”
-
[35]
Available: https://arxiv.org/abs/2306.05685
[Online]. Available: https://arxiv.org/abs/2306.05685
-
[36]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert- V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Am...
Pith/arXiv arXiv 2020
-
[37]
Maximum likelihood estimation of observer error-rates using the em algorithm,
A. P. Dawid and A. M. Skene, “Maximum likelihood estimation of observer error-rates using the em algorithm,”Journal of the Royal Statistical Society. Series C (Applied Statistics), vol. 28, no. 1, pp. 20– 28, 1979. [Online]. Available: http://www.jstor.org/stable/2346806
arXiv 1979
-
[38]
R. M. Neal and G. E. Hinton,A View of the Em Algorithm that Justifies Incremental, Sparse, and other Variants. Dordrecht: Springer Netherlands, 1998, pp. 355–368. [Online]. Available: https://doi.org/10. 1007/978-94-011-5014-9 12
1998
-
[39]
Maximum likelihood from incomplete data via the em algorithm,
A. P. Dempster, N. M. Laird, and D. B. Rubin, “Maximum likelihood from incomplete data via the em algorithm,”Journal of the Royal Statistical Society. Series B (Methodological), vol. 39, no. 1, pp. 1–38,
-
[40]
Available: http://www.jstor.org/stable/2984875
[Online]. Available: http://www.jstor.org/stable/2984875
-
[41]
Self-training with noisy student improves imagenet classification,
Q. Xie, M.-T. Luong, E. Hovy, and Q. V . Le, “Self-training with noisy student improves imagenet classification,” 2020. [Online]. Available: https://arxiv.org/abs/1911.04252
arXiv 2020
-
[42]
Learning to reweight examples for robust deep learning,
M. Ren, W. Zeng, B. Yang, and R. Urtasun, “Learning to reweight examples for robust deep learning,” 2019. [Online]. Available: https: //arxiv.org/abs/1803.09050
Pith/arXiv arXiv 2019
-
[43]
Neural attributed community search at billion scale,
J. Wang, K. Wang, X. Lin, W. Zhang, and Y . Zhang, “Neural attributed community search at billion scale,” 2024. [Online]. Available: https: //arxiv.org/abs/2403.18874
arXiv 2024
-
[44]
Efficient unsupervised community search with pre-trained graph transformer,
——, “Efficient unsupervised community search with pre-trained graph transformer,” 2024. [Online]. Available: https://arxiv.org/abs/2403.18869
arXiv 2024
-
[45]
Tabllm: Few-shot classification of tabular data with large language models,
S. Hegselmann, A. Buendia, H. Lang, M. Agrawal, X. Jiang, and D. Son- tag, “Tabllm: Few-shot classification of tabular data with large language models,” 2023. [Online]. Available: https://arxiv.org/abs/2210.10723
arXiv 2023
-
[46]
Lift: Language-interfaced fine-tuning for non-language machine learning tasks,
T. Dinh, Y . Zeng, R. Zhang, Z. Lin, M. Gira, S. Rajput, J. yong Sohn, D. Papailiopoulos, and K. Lee, “Lift: Language-interfaced fine-tuning for non-language machine learning tasks,” 2022. [Online]. Available: https://arxiv.org/abs/2206.06565
arXiv 2022
-
[47]
Mentornet: Learn- ing data-driven curriculum for very deep neural networks on corrupted labels,
L. Jiang, Z. Zhou, T. Leung, L.-J. Li, and L. Fei-Fei, “Mentornet: Learn- ing data-driven curriculum for very deep neural networks on corrupted labels,” 2018. [Online]. Available: https://arxiv.org/abs/1712.05055
Pith/arXiv arXiv 2018
-
[48]
Pseudo-labeling and confirmation bias in deep semi-supervised learn- ing,
E. Arazo, D. Ortego, P. Albert, N. E. O’Connor, and K. McGuinness, “Pseudo-labeling and confirmation bias in deep semi-supervised learn- ing,” 2020. [Online]. Available: https://arxiv.org/abs/1908.02983
arXiv 2020
-
[49]
Learning with noisy labels,
N. Natarajan, I. S. Dhillon, P. Ravikumar, and A. Tewari, “Learning with noisy labels,” inProceedings of the 27th International Conference on Neural Information Processing Systems - Volume 1, ser. NIPS’13. Red Hook, NY , USA: Curran Associates Inc., 2013, p. 1196–1204
2013
-
[50]
Confident learning: Estimating uncertainty in dataset labels,
C. Northcutt, L. Jiang, and I. Chuang, “Confident learning: Estimating uncertainty in dataset labels,”J. Artif. Int. Res., vol. 70, p. 1373–1411, May 2021. [Online]. Available: https://doi.org/10.1613/jair.1.12125
-
[51]
A baseline for detecting misclassified and out-of-distribution examples in neural networks,
D. Hendrycks and K. Gimpel, “A baseline for detecting misclassified and out-of-distribution examples in neural networks,” 2018. [Online]. Available: https://arxiv.org/abs/1610.02136
Pith/arXiv arXiv 2018
-
[52]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” 2017. [Online]. Available: https://arxiv.org/ abs/1706.04599
Pith/arXiv arXiv 2017
-
[53]
Lasrepair++: Full version,
Q. C. Jianwei Wang, Wenjie Zhang, “Lasrepair++: Full version,” https: //github.com/OZCQC/LasRepair, 2026
2026
-
[54]
Messing up with bart: error generation for evaluating data- cleaning algorithms,
P. C. Arocena, B. Glavic, G. Mecca, R. J. Miller, P. Papotti, and D. Santoro, “Messing up with bart: error generation for evaluating data- cleaning algorithms,”Proc. VLDB Endow., vol. 9, no. 2, p. 36–47, Oct
-
[55]
Available: https://doi.org/10.14778/2850578.2850579
[Online]. Available: https://doi.org/10.14778/2850578.2850579
-
[56]
D. B. Rubin, “Inference and missing data,”Biometrika, vol. 63, no. 3, pp. 581–592, 1976. [Online]. Available: http://www.jstor.org/stable/2335739
arXiv 1976
-
[57]
Boostclean: Automated error detection and repair for machine learning,
S. Krishnan, M. J. Franklin, K. Goldberg, and E. Wu, “Boostclean: Automated error detection and repair for machine learning,”CoRR, vol. abs/1711.01299, 2017. [Online]. Available: http://arxiv.org/abs/1711. 01299
Pith/arXiv arXiv 2017
-
[58]
The truth of the f-measure,
Y . Sasakiet al., “The truth of the f-measure,”Teach tutor mater, vol. 1, no. 5, pp. 1–5, 2007
2007
-
[59]
Binary codes capable of correcting deletions, inser- tions and reversals,
V . I. Levenshtein, “Binary codes capable of correcting deletions, inser- tions and reversals,”Soviet Physics Doklady, vol. 10, no. 8, pp. 707–710, 1966
1966
-
[60]
Exploring the limits of transfer learn- ing with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learn- ing with a unified text-to-text transformer,” 2023. [Online]. Available: https://arxiv.org/abs/1910.10683
Pith/arXiv arXiv 2023
-
[61]
OpenAI, “Openai gpt-5 system card,” 2026. [Online]. Available: https: //arxiv.org/abs/2601.03267
Pith/arXiv arXiv 2026
-
[62]
——, “Gpt-4o system card,” 2024. [Online]. Available: https://arxiv.org/ abs/2410.21276
Pith/arXiv arXiv 2024
-
[63]
M. Lewis, Y . Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V . Stoyanov, and L. Zettlemoyer, “Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehen- sion,” 2019. [Online]. Available: https://arxiv.org/abs/1910.13461
Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.