TuneAhead: Predicting Fine-tuning Performance Before Full Training Begins
Pith reviewed 2026-06-27 01:37 UTC · model grok-4.3
The pith
TUNEAHEAD predicts LLM fine-tuning performance from dataset features and a short probe run.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
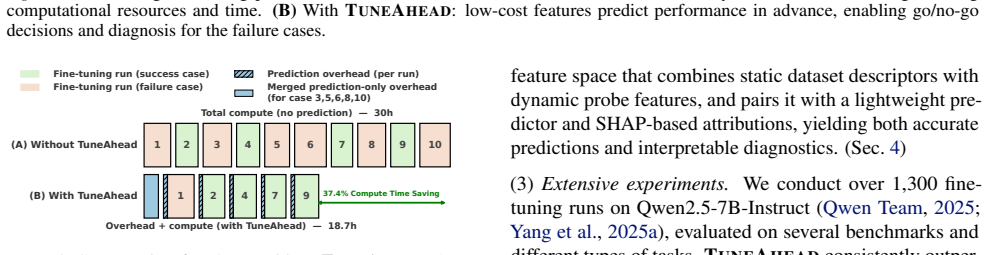
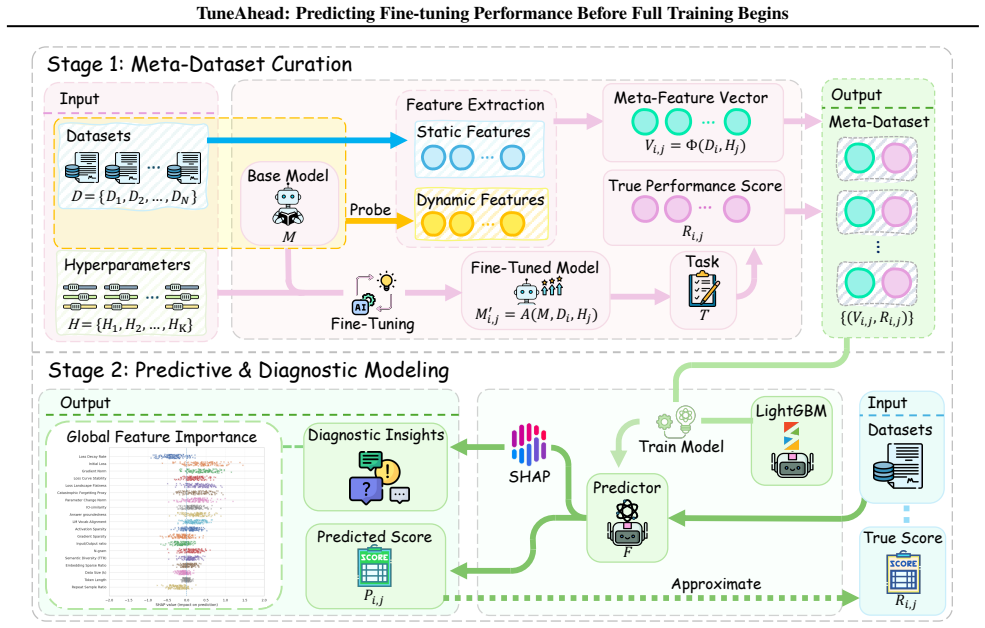
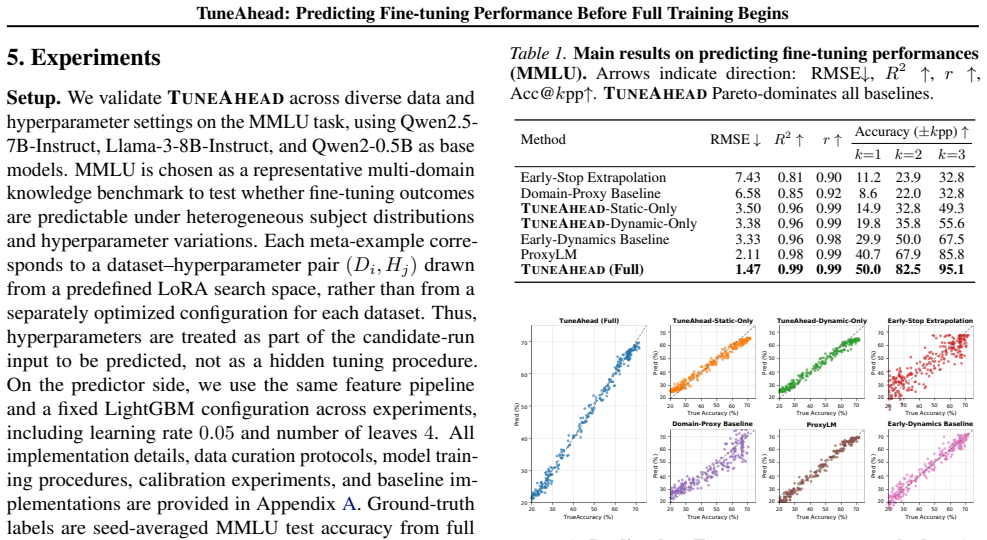
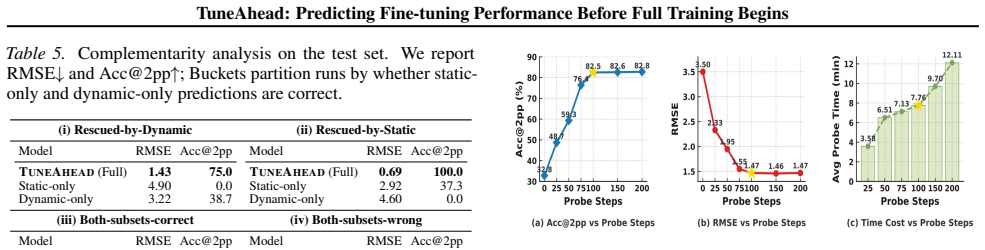
TUNEAHEAD encodes each candidate run as a meta-feature vector that combines static dataset descriptors with dynamic probe features from a short standardized probe. A predictor maps these features to performance estimates. Across 1,300+ fine-tuning runs on Qwen2.5-7B-Instruct, TUNEAHEAD consistently outperforms strong baselines such as Early-Stop Extrapolation and ProxyLM. On a held-out test set of 370 runs, TUNEAHEAD achieves an RMSE of 1.47 percentage points and places 95.1% of predictions within +3/-3 percentage points of the true score.
What carries the argument
The meta-feature vector that combines static dataset descriptors with dynamic features from a short standardized probe and feeds them to a predictor for performance estimates.
Load-bearing premise
Static dataset descriptors together with measurements from one short probe already contain enough information to forecast final performance no matter how the data quality or hyperparameters vary.
What would settle it
Applying the same predictor to a fresh collection of fine-tuning runs on different models or datasets and obtaining RMSE well above 1.47 percentage points would show the method does not generalize.
Figures


read the original abstract
Fine-tuning large language models (LLMs) is compute-intensive and error-prone: model performance depends sensitively on data quality and hyperparameter choices, and na\"ive runs can even degrade model performance. This raises a practical question:can we predict fine-tuning performance before committing to a full training run? We present TUNEAHEAD, a lightweight framework for pre-hoc prediction of fine-tuning performance. TUNEAHEAD encodes each candidate run as a meta-feature vector that combines static dataset descriptors with dynamic probe features from a short standardized probe. A predictor maps these features to performance estimates, while SHAP-based attributions provide interpretable diagnostics that reveal which specific features drive the prediction. Across 1,300+ fine-tuning runs on Qwen2.5-7B-Instruct, TUNEAHEAD consistently outperforms strong baselines such as Early-Stop Extrapolation and ProxyLM. On a held-out test set of 370 runs, TUNEAHEAD achieves an RMSE of 1.47 percentage points and places 95.1% of predictions within +3/-3 percentage points of the true score. These accurate continuous predictions support practical go/no-go screening policies that can reduce unnecessary full fine-tuning while retaining most promising runs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TUNEAHEAD, a lightweight framework for pre-hoc prediction of LLM fine-tuning performance. Each candidate run is encoded as a meta-feature vector combining static dataset descriptors with dynamic features extracted from a short standardized probe; a meta-predictor then maps these features to an estimated final performance score, accompanied by SHAP-based attributions. On more than 1,300 fine-tuning runs of Qwen2.5-7B-Instruct the method outperforms baselines such as Early-Stop Extrapolation and ProxyLM; on a held-out test set of 370 runs it reports RMSE = 1.47 percentage points and places 95.1 % of predictions inside a ±3 percentage-point band.
Significance. If the reported accuracy generalizes, the approach could materially reduce wasted compute by enabling early go/no-go screening of fine-tuning configurations. The evaluation scale (>1,300 runs) and the explicitly non-circular feature construction (dataset descriptors plus an independent short probe) are concrete strengths. The provision of SHAP diagnostics adds practical interpretability that is often absent from pure black-box predictors.
major comments (2)
- [Abstract] Abstract: the claim that predictions succeed 'across varied … hyperparameter choices without requiring the full training trajectory' is load-bearing, yet the probe is described as 'standardized' (fixed settings). If the dynamic features (early loss, gradient norms, etc.) are collected under a single fixed learning rate/batch size/optimizer, they cannot reflect hyperparameter-specific convergence behavior; the low RMSE on the held-out set would then be consistent with learning correlations inside the probe regime rather than true transfer across HP regimes.
- [Evaluation] Evaluation section (implied by the 370-run held-out test set): no information is given on how the train/test split was constructed with respect to hyperparameter diversity or dataset similarity. Without explicit stratification or leakage controls, the 1.47 RMSE and 95.1 % within-band statistic cannot be taken as evidence of generalization across the very hyperparameter variations the central claim asserts.
minor comments (1)
- [Abstract] Abstract contains a typographic artifact ('na"ive'); standard spelling is 'naive'.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of our claims and evaluation design. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that predictions succeed 'across varied … hyperparameter choices without requiring the full training trajectory' is load-bearing, yet the probe is described as 'standardized' (fixed settings). If the dynamic features (early loss, gradient norms, etc.) are collected under a single fixed learning rate/batch size/optimizer, they cannot reflect hyperparameter-specific convergence behavior; the low RMSE on the held-out set would then be consistent with learning correlations inside the probe regime rather than true transfer across HP regimes.
Authors: We appreciate the referee pointing out this distinction. The probe is run under fixed, standardized settings to ensure consistent and low-cost feature extraction that does not depend on the target run's hyperparameters. The meta-predictor is trained across a collection of runs that themselves use varied hyperparameters, so it learns to associate the resulting (dataset + fixed-probe) feature vectors with the final performance achieved under those specific hyperparameters. We agree, however, that the features themselves do not encode hyperparameter-specific dynamics. To prevent any overstatement of the generalization claim, we will revise the abstract to clarify that predictions are made for the hyperparameter configurations observed in the training data, using static descriptors plus a fixed probe, rather than implying direct transfer to arbitrary unseen hyperparameter regimes. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by the 370-run held-out test set): no information is given on how the train/test split was constructed with respect to hyperparameter diversity or dataset similarity. Without explicit stratification or leakage controls, the 1.47 RMSE and 95.1 % within-band statistic cannot be taken as evidence of generalization across the very hyperparameter variations the central claim asserts.
Authors: The referee is correct that the manuscript currently lacks explicit details on the train/test split procedure with respect to hyperparameter diversity and dataset similarity. We will add a dedicated paragraph in the evaluation section describing how the 370-run held-out set was constructed, including any stratification by key hyperparameters (learning rate, batch size, etc.) and controls for dataset overlap or similarity to ensure the reported metrics reflect generalization across the hyperparameter variations present in the data. revision: yes
Circularity Check
No circularity: predictions use independent short-probe features
full rationale
The method constructs meta-feature vectors from static dataset descriptors plus dynamic signals extracted from a short standardized probe run; a separate predictor then maps these to performance estimates. No equation or step in the described pipeline reduces the output to a quantity defined by the full training trajectory itself. Evaluation on a held-out set of 370 runs is performed against actual full-run scores, preserving independence. No self-citation load-bearing steps or fitted-input-as-prediction patterns are present in the provided description.
Axiom & Free-Parameter Ledger
free parameters (1)
- meta-predictor parameters
axioms (1)
- domain assumption Short standardized probe features correlate sufficiently with full fine-tuning outcomes
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
2025 , eprint=
COSMOS: Predictable and Cost-Effective Adaptation of LLMs , author=. 2025 , eprint=
2025
-
[5]
2024 , eprint=
Fine-Tuning or Fine-Failing? Debunking Performance Myths in Large Language Models , author=. 2024 , eprint=
2024
-
[6]
2025 , eprint=
LENSLLM: Unveiling Fine-Tuning Dynamics for LLM Selection , author=. 2025 , eprint=
2025
-
[7]
2017 , eprint=
A Unified Approach to Interpreting Model Predictions , author=. 2017 , eprint=
2017
-
[8]
2020 , eprint=
Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples , author=. 2020 , eprint=
2020
-
[9]
2021 , eprint=
Dataset2Vec: Learning Dataset Meta-Features , author=. 2021 , eprint=
2021
-
[10]
2022 , eprint=
Model Zoos: A Dataset of Diverse Populations of Neural Network Models , author=. 2022 , eprint=
2022
-
[11]
Proceedings of the 24th International Conference on Artificial Intelligence , pages =
Domhan, Tobias and Springenberg, Jost Tobias and Hutter, Frank , title =. Proceedings of the 24th International Conference on Artificial Intelligence , pages =. 2015 , isbn =
2015
-
[12]
2020 , eprint=
Scaling Laws for Neural Language Models , author=. 2020 , eprint=
2020
-
[13]
2024 , eprint=
ProxyLM: Predicting Language Model Performance on Multilingual Tasks via Proxy Models , author=. 2024 , eprint=
2024
-
[14]
2020 , eprint=
Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics , author=. 2020 , eprint=
2020
-
[15]
2019 , eprint=
Data Shapley: Equitable Valuation of Data for Machine Learning , author=. 2019 , eprint=
2019
-
[16]
2025 , eprint=
Refine-n-Judge: Curating High-Quality Preference Chains for LLM-Fine-Tuning , author=. 2025 , eprint=
2025
-
[17]
2018 , eprint=
The Dataset Nutrition Label: A Framework To Drive Higher Data Quality Standards , author=. 2018 , eprint=
2018
-
[18]
2021 , eprint=
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers , author=. 2021 , eprint=
2021
-
[19]
2023 , eprint=
GENTLE: A Genre-Diverse Multilayer Challenge Set for English NLP and Linguistic Evaluation , author=. 2023 , eprint=
2023
-
[20]
2021 , eprint=
On the Importance of Gradients for Detecting Distributional Shifts in the Wild , author=. 2021 , eprint=
2021
-
[21]
2018 , eprint=
GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks , author=. 2018 , eprint=
2018
-
[22]
Louis , year=
Shuofeng Zhang and Isaac Reid and Guillermo Valle-Perez and Ard A. Louis , year=
-
[23]
2024 , url=
Gradient norm as a powerful proxy to out-of-distribution error estimation , author=. 2024 , url=
2024
-
[24]
2023 , eprint=
Gradient Norm Aware Minimization Seeks First-Order Flatness and Improves Generalization , author=. 2023 , eprint=
2023
-
[25]
2021 , eprint=
Self-Validation: Early Stopping for Single-Instance Deep Generative Priors , author=. 2021 , eprint=
2021
-
[26]
2025 , eprint=
Autoencoder-Based Framework to Capture Vocabulary Quality in NLP , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint=
Massive Supervised Fine-tuning Experiments Reveal How Data, Layer, and Training Factors Shape LLM Alignment Quality , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
Assessing the Impact of the Quality of Textual Data on Feature Representation and Machine Learning Models , author=. 2025 , eprint=
2025
-
[29]
Model Explainability using SHAP Values for LightGBM Predictions , year=
Bugaj, Michal and Wrobel, Krzysztof and Iwaniec, Joanna , booktitle=. Model Explainability using SHAP Values for LightGBM Predictions , year=
-
[30]
Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
Ke, Guolin and Meng, Qi and Finley, Thomas and Wang, Taifeng and Chen, Wei and Ma, Weidong and Ye, Qiwei and Liu, Tie-Yan , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[31]
Wang, Ying and Wang, Pengxin and Tansey, Kevin and Liu, Junming and Delaney, Bethany and Quan, Wenting , title =. 2025 , issue_date =. doi:10.1016/j.compag.2024.109758 , journal =
-
[32]
Garcia and Carlos Soares and Joaquin Vanschoren and André C.P.L.F
Adriano Rivolli and Luís P.F. Garcia and Carlos Soares and Joaquin Vanschoren and André C.P.L.F. Meta-features for meta-learning , journal =. 2022 , issn =. doi:https://doi.org/10.1016/j.knosys.2021.108101 , url =
-
[33]
2022 , eprint=
Predicting Fine-Tuning Performance with Probing , author=. 2022 , eprint=
2022
-
[34]
2024 , eprint=
Predictable Emergent Abilities of LLMs: Proxy Tasks Are All You Need , author=. 2024 , eprint=
2024
-
[35]
2020 , eprint=
The Break-Even Point on Optimization Trajectories of Deep Neural Networks , author=. 2020 , eprint=
2020
-
[36]
2019 , eprint=
Visualizing and Understanding the Effectiveness of BERT , author=. 2019 , eprint=
2019
-
[37]
2023 , eprint=
Efficient Bayesian Learning Curve Extrapolation using Prior-Data Fitted Networks , author=. 2023 , eprint=
2023
-
[38]
International Conference on Learning Representations (ICLR) , year =
Measuring Massive Multitask Language Understanding , author =. International Conference on Learning Representations (ICLR) , year =
-
[39]
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =. doi:10.48550/arXiv.2412.15115 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115
-
[40]
2025 , url =
Qwen2.5-7B-Instruct , author =. 2025 , url =
2025
-
[41]
2025 , eprint=
A Multi-Power Law for Loss Curve Prediction Across Learning Rate Schedules , author=. 2025 , eprint=
2025
-
[42]
2020 , eprint=
Don't Stop Pretraining: Adapt Language Models to Domains and Tasks , author=. 2020 , eprint=
2020
-
[43]
Mu, Yida and Jin, Mali and Song, Xingyi and Aletras, Nikolaos. Enhancing Data Quality through Simple De-duplication: Navigating Responsible Computational Social Science Research. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.694
-
[44]
2025 , eprint=
Measuring Data Diversity for Instruction Tuning: A Systematic Analysis and A Reliable Metric , author=. 2025 , eprint=
2025
-
[45]
2023 , eprint=
The Vendi Score: A Diversity Evaluation Metric for Machine Learning , author=. 2023 , eprint=
2023
-
[46]
2018 , eprint=
Visualizing the Loss Landscape of Neural Nets , author=. 2018 , eprint=
2018
-
[47]
2020 , eprint=
Adversarial Weight Perturbation Helps Robust Generalization , author=. 2020 , eprint=
2020
-
[48]
Mathematics , VOLUME =
Liang, Hailun and Zheng, Haowen and Wang, Hao and He, Liu and Lin, Haoyi and Liang, Yanyan , TITLE =. Mathematics , VOLUME =. 2025 , NUMBER =
2025
-
[49]
Technometrics , volume =
Ridge Regression: Biased Estimation for Nonorthogonal Problems , author =. Technometrics , volume =. 1970 , publisher =
1970
-
[50]
Advances in Neural Information Processing Systems , volume =
Support Vector Regression Machines , author =. Advances in Neural Information Processing Systems , volume =. 1997 , publisher =
1997
-
[51]
Statistics and Computing , volume =
A Tutorial on Support Vector Regression , author =. Statistics and Computing , volume =. 2004 , doi =
2004
-
[52]
Machine Learning , volume =
Random Forests , author =. Machine Learning , volume =. 2001 , doi =
2001
-
[53]
Nature , volume =
Learning Representations by Back-Propagating Errors , author =. Nature , volume =. 1986 , doi =
1986
-
[54]
Neural Networks , volume =
Multilayer Feedforward Networks Are Universal Approximators , author =. Neural Networks , volume =. 1989 , doi =
1989
-
[55]
Journal of Machine Learning Research , volume =
Scikit-learn: Machine Learning in Python , author =. Journal of Machine Learning Research , volume =. 2011 , url =
2011
-
[56]
arXiv preprint arXiv:1706.10239 , year=
Towards Understanding Generalization of Deep Learning: Perspective of Loss Landscapes , author=. arXiv preprint arXiv:1706.10239 , year=
-
[57]
arXiv preprint arXiv:2412.13573 , year=
Seeking Consistent Flat Minima for Better Domain Generalization via Refining Loss Landscapes , author=. arXiv preprint arXiv:2412.13573 , year=
-
[58]
2019 , eprint=
Characterizing classification datasets: a study of meta-features for meta-learning , author=. 2019 , eprint=
2019
-
[59]
2024 , eprint=
Machine Translation Meta Evaluation through Translation Accuracy Challenge Sets , author=. 2024 , eprint=
2024
-
[60]
2023 , eprint=
Advances and Challenges in Meta-Learning: A Technical Review , author=. 2023 , eprint=
2023
-
[61]
2018 , eprint=
Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization , author=. 2018 , eprint=
2018
-
[62]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[63]
2018 , eprint=
A Survey of Machine Learning for Big Code and Naturalness , author=. 2018 , eprint=
2018
-
[64]
, title =
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J. , title =. J. Mach. Learn. Res. , month = jan, articleno =. 2020 , issue_date =
2020
-
[65]
2022 , eprint=
Deduplicating Training Data Makes Language Models Better , author=. 2022 , eprint=
2022
-
[66]
2023 , eprint=
Extracting Training Data from Diffusion Models , author=. 2023 , eprint=
2023
-
[67]
2022 , eprint=
Training Compute-Optimal Large Language Models , author=. 2022 , eprint=
2022
-
[68]
2019 , eprint=
Deep Anomaly Detection with Outlier Exposure , author=. 2019 , eprint=
2019
-
[69]
2022 , eprint=
Confident Learning: Estimating Uncertainty in Dataset Labels , author=. 2022 , eprint=
2022
-
[70]
2021 , eprint=
Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus , author=. 2021 , eprint=
2021
-
[71]
2020 , eprint=
The Curious Case of Neural Text Degeneration , author=. 2020 , eprint=
2020
-
[72]
A Qualitative Comparison of C o QA , SQ u AD 2.0 and Q u AC
Yatskar, Mark. A Qualitative Comparison of C o QA , SQ u AD 2.0 and Q u AC. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1241
-
[73]
2016 , eprint=
Exploring the Limits of Language Modeling , author=. 2016 , eprint=
2016
-
[74]
2018 , eprint=
Universal Sentence Encoder , author=. 2018 , eprint=
2018
-
[75]
2020 , eprint=
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators , author=. 2020 , eprint=
2020
-
[76]
2016 , eprint=
A Diversity-Promoting Objective Function for Neural Conversation Models , author=. 2016 , eprint=
2016
-
[77]
2020 , eprint=
Fine-Tuning Language Models from Human Preferences , author=. 2020 , eprint=
2020
-
[78]
2020 , eprint=
Unsupervised Domain Clusters in Pretrained Language Models , author=. 2020 , eprint=
2020
-
[79]
Domain Adaptation via Pseudo In-Domain Data Selection
Axelrod, Amittai and He, Xiaodong and Gao, Jianfeng. Domain Adaptation via Pseudo In-Domain Data Selection. Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. 2011
2011
-
[80]
Khasentino, J., Belyaeva, A., Liu, X., Yang, Z., Furlotte, N
Ji, Ziwei and Lee, Nayeon and Frieske, Rita and Yu, Tiezheng and Su, Dan and Xu, Yan and Ishii, Etsuko and Bang, Ye Jin and Madotto, Andrea and Fung, Pascale , year=. Survey of Hallucination in Natural Language Generation , volume=. ACM Computing Surveys , publisher=. doi:10.1145/3571730 , number=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.