MLLMs Get It Right, Then Get It Wrong: Tracing and Correcting Late-Layer Textual Bias
Pith reviewed 2026-06-27 01:26 UTC · model grok-4.3
The pith
When vision and text conflict, MLLMs compute the correct visual answer in intermediate layers before text overrides it in the end.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
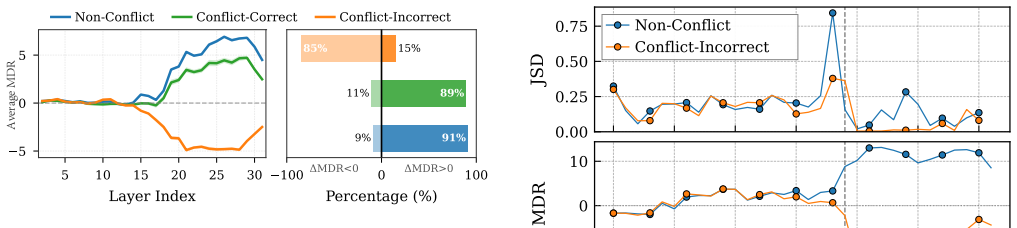
Models often get it right initially, forming correct vision-based predictions in their intermediate layers, before changing their minds and favoring text in the final output. The directional signature of these changes—85% of failures shift toward text, while 89% of successes shift toward vision—enables a training-free method called CALRD to recover the overridden visual predictions.
What carries the argument
Late-layer textual override, the mechanism where correct intermediate visual predictions are suppressed by text bias in later layers; the directional signature of prediction shifts that identifies when to intervene and restore the visual answer.
Load-bearing premise
The assumption that a shift toward text reliably signals that the intermediate visual prediction was correct and should be restored rather than the final text answer.
What would settle it
A dataset of conflict examples where restoring the intermediate prediction decreases accuracy on the visual ground truth, or where the directional signature does not correlate with actual correctness.
Figures








read the original abstract
When vision contradicts text, multimodal large language models (MLLMs) consistently favor text, even when images provide clear evidence otherwise. This bias poses risks for applications requiring visual grounding, yet its cause remains unclear. In this paper, we uncover a surprising finding: models often get it right initially, forming correct vision-based predictions in their intermediate layers, before changing their minds and favoring text in the final output. We call this "late-layer textual override". The visual information is encoded, it simply does not survive to the output. More intriguingly, we find that how predictions change reveals whether they're correct: 85% of failures shift toward text, while 89% of successes shift toward vision. This directional signature enables a simple but powerful intervention: when we detect a confident visual prediction being suppressed, we restore it. We propose CALRD (Conflict-Aware Layer Reference Decoding), a training-free method that recovers overridden predictions at inference time. Experiments across five MLLMs of varying architectures demonstrate up to 9.4% absolute improvements on conflict benchmarks while largely preserving standard performance, without training or external knowledge. It recovers what the model already knew but failed to preserve.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
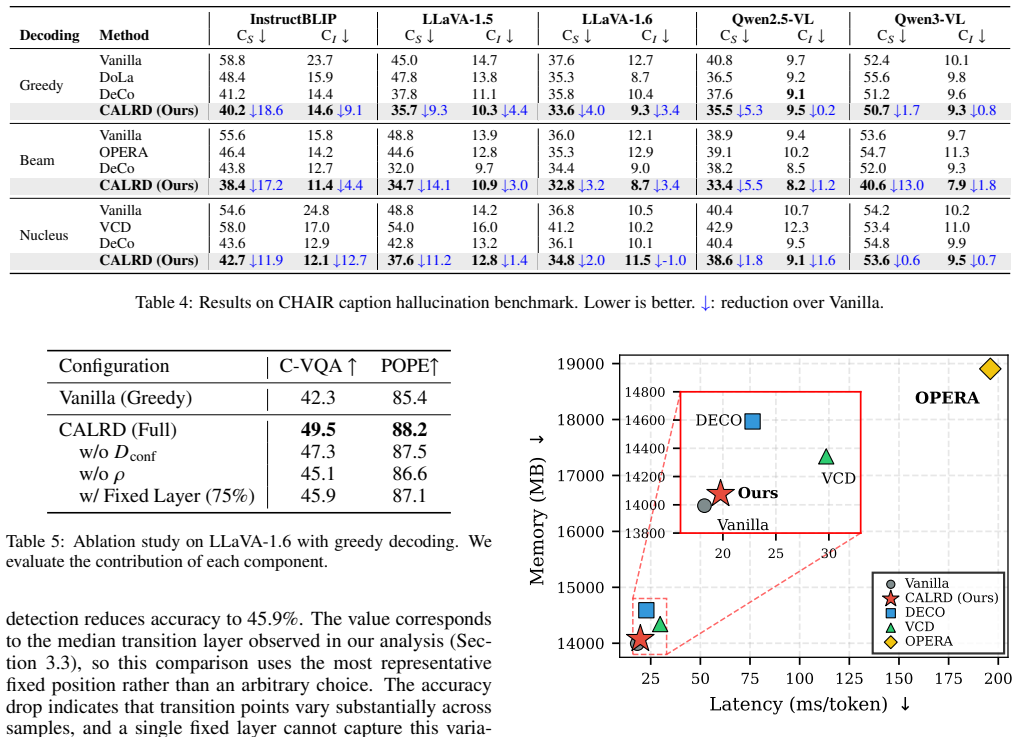
Summary. The paper claims that MLLMs encode correct vision-based predictions in intermediate layers but suffer late-layer textual override, favoring text when vision and text conflict. It reports that 85% of failures show shifts toward text and 89% of successes shift toward vision; this directional signature is used to detect and restore overridden visual predictions via the training-free CALRD method, yielding up to 9.4% absolute gains on conflict benchmarks across five MLLMs while preserving standard performance.
Significance. If the core measurement and intervention are valid, the work supplies a lightweight, inference-only technique for reducing textual bias in MLLMs without retraining or external data. The empirical layer-wise observations could inform future architectural studies of multimodal alignment. The reported gains and preservation of non-conflict performance constitute a practical contribution if the directional signature reliably identifies correct intermediate predictions.
major comments (2)
- [Method (layer-wise decoding procedure)] The central identification of 'correct vision predictions' in intermediate layers (and thus the 85%/89% directional statistics and the trigger for CALRD) relies on applying the final LM head to each layer's hidden states. This procedure assumes intermediate representations already lie in the final output space, yet subsequent layers continue to transform the state via attention and MLP blocks; apparent shifts may therefore be decoding artifacts. The manuscript does not report controls (e.g., layer-specific heads, linear probes, or representation similarity metrics) that would validate the assumption. This measurement is load-bearing for both the empirical claim and the proposed intervention.
- [Experiments (conflict benchmark results)] The directional signature used to decide when to restore a visual prediction is defined from the same conflict examples on which performance is later measured. No held-out validation set, cross-model consistency test, or statistical control for multiple comparisons is described to establish that the 85%/89% figures generalize beyond the evaluation distribution.
minor comments (2)
- [Abstract / §3] The abstract and introduction should explicitly state the exact layer indices or selection criterion used for 'intermediate' versus 'late' layers, as this choice directly affects reproducibility.
- [Results tables] Table or figure reporting per-model gains should include standard deviations across prompts or seeds to allow assessment of effect stability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas for strengthening the methodological rigor and experimental validation of our layer-wise analysis and intervention. We respond point-by-point below and will incorporate revisions to address the concerns.
read point-by-point responses
-
Referee: [Method (layer-wise decoding procedure)] The central identification of 'correct vision predictions' in intermediate layers (and thus the 85%/89% directional statistics and the trigger for CALRD) relies on applying the final LM head to each layer's hidden states. This procedure assumes intermediate representations already lie in the final output space, yet subsequent layers continue to transform the state via attention and MLP blocks; apparent shifts may therefore be decoding artifacts. The manuscript does not report controls (e.g., layer-specific heads, linear probes, or representation similarity metrics) that would validate the assumption. This measurement is load-bearing for both the empirical claim and the proposed intervention.
Authors: We acknowledge that applying the final LM head to intermediate hidden states (a logit-lens style procedure) is an approximation, as later layers continue to transform representations. This technique is standard in interpretability work, and the observed directional patterns are consistent across five MLLMs with different architectures. The practical effectiveness of CALRD, which uses these signals to achieve up to 9.4% gains while preserving non-conflict performance, provides supporting evidence that the decoded outputs reflect meaningful content. Nevertheless, we agree that additional validation would strengthen the claim. In revision we will add linear probes on a subset of layers, cosine similarity metrics between projected activations, and an explicit discussion of the approximation's limitations. This constitutes a partial revision, as the core empirical results and intervention remain unchanged. revision: partial
-
Referee: [Experiments (conflict benchmark results)] The directional signature used to decide when to restore a visual prediction is defined from the same conflict examples on which performance is later measured. No held-out validation set, cross-model consistency test, or statistical control for multiple comparisons is described to establish that the 85%/89% figures generalize beyond the evaluation distribution.
Authors: We agree this raises a valid concern about potential circularity in deriving the directional signature from the evaluation distribution. While the 85%/89% statistics held across multiple models and benchmarks, a held-out protocol would better demonstrate robustness. In the revised manuscript we will partition the conflict benchmarks into validation and test splits, derive signature parameters exclusively on the validation portion, evaluate on the held-out test set, and report cross-model consistency. We will also address multiple-comparison considerations. These changes directly incorporate the referee's point. revision: yes
Circularity Check
No significant circularity: empirical observations and inference-time heuristic
full rationale
The paper reports measured layer-wise prediction shifts on conflict benchmarks (85% of failures shift toward text; 89% of successes shift toward vision) and proposes CALRD as a training-free rule that restores the intermediate prediction when the directional signature is detected. These statistics and the intervention are presented as direct experimental outcomes rather than quantities fitted from the same data or defined in terms of the target result. No equations, self-citations, or ansatzes are shown that would make the central claims equivalent to their inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[Baiet al., 2025a ] Shuai Bai, Yuxuan Cai, Ruizhe Chen, Ke- qin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhi- fang Guo, et al. Qwen3-vl technical report.CoRR, abs/2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
[Baiet al., 2025b ] Shuai Bai, Keqin Chen, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
[Bannuret al., 2024 ] Shruthi Bannur, Kenza Bouzid, et al. Maira-2: Grounded radiology report generation.arXiv preprint arXiv:2406.04449,
-
[4]
Rich knowl- edge sources bring complex knowledge conflicts: Recali- brating models to reflect conflicting evidence
[Chen and others, 2022] Hung-Ting Chen et al. Rich knowl- edge sources bring complex knowledge conflicts: Recali- brating models to reflect conflicting evidence. InProceed- ings of the 2022 Conference on Empirical Methods in Nat- ural Language Processing, pages 2292–2307,
2022
-
[5]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
[Chenet al., 2024 ] Zhe Chen, Jiannan Wu, Wenhai Wang, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the conference on computer vision and pattern recogni- tion, pages 24185–24198,
2024
-
[6]
Multimodal language models see bet- ter when they look shallower
[Chenet al., 2025 ] Haoran Chen, Junyan Lin, Xinghao Chen, Yue Fan, Jianfeng Dong, Xin Jin, Hui Su, Jinlan Fu, and Xiaoyu Shen. Multimodal language models see bet- ter when they look shallower. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6688–6706,
2025
-
[7]
Glass, and Pengcheng He
[Chuanget al., 2024 ] Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R. Glass, and Pengcheng He. Dola: Decoding by contrasting layers improves factuality in large language models. InICLR,
2024
-
[8]
Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing sys- tems, 36:49250–49267,
[Daiet al., 2023 ] Wenliang Dai, Junnan Li, Dongxu Li, An- thony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing sys- tems, 36:49250–49267,
2023
-
[9]
Words or vi- sion: Do vision-language models have blind faith in text? InProceedings of the Computer Vision and Pattern Recog- nition Conference, pages 3867–3876,
[Denget al., 2025 ] Ailin Deng, Tri Cao, et al. Words or vi- sion: Do vision-language models have blind faith in text? InProceedings of the Computer Vision and Pattern Recog- nition Conference, pages 3867–3876,
2025
-
[10]
Depth-adaptive transformer
[Elbayadet al., 2020 ] Maha Elbayad, Jiatao Gu, Edouard Grave, et al. Depth-adaptive transformer. InInternational Conference on Learning Representations,
2020
-
[11]
Visipruner: Decoding discontinuous cross-modal dynamics for efficient multimodal llms
[Fanet al., 2025 ] Yingqi Fan, Anhao Zhao, Jinlan Fu, Jun- long Tong, Hui Su, Yijie Pan, Wei Zhang, and Xiaoyu Shen. Visipruner: Decoding discontinuous cross-modal dynamics for efficient multimodal llms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18896–18913,
2025
-
[12]
Ecd: Efficient contrastive decoding with proba- bilistic hallucination detection
[Fiebacket al., 2025 ] Laura Fieback, Nishilkumar Balar, et al. Ecd: Efficient contrastive decoding with proba- bilistic hallucination detection. InJoint European Con- ference on Machine Learning and Knowledge Discovery in Databases, pages 21–38. Springer,
2025
-
[13]
Hallusionbench: an advanced diagnostic suite for entangled language hallu- cination and visual illusion in large vision-language mod- els
[Guan and others, 2024] Tianrui Guan et al. Hallusionbench: an advanced diagnostic suite for entangled language hallu- cination and visual illusion in large vision-language mod- els. InProceedings of the Conference on Computer Vision and Pattern Recognition, pages 14375–14385,
2024
-
[14]
One year on: assessing progress of multimodal large language model performance on rsna 2024 case of the day questions.Radiology, 316(2):e250617,
[Houet al., 2025 ] Benjamin Hou, Pritam Mukherjee, Vivek Batheja, Kenneth C Wang, Ronald M Summers, and Zhiy- ong Lu. One year on: assessing progress of multimodal large language model performance on rsna 2024 case of the day questions.Radiology, 316(2):e250617,
2025
-
[15]
Opera: Alle- viating hallucination in multi-modal large language mod- els via over-trust penalty and retrospection-allocation
[Huang and others, 2024] Qidong Huang et al. Opera: Alle- viating hallucination in multi-modal large language mod- els via over-trust penalty and retrospection-allocation. In Proceedings of the Conference on Computer Vision and Pattern Recognition, pages 13418–13427,
2024
-
[16]
Benchmarking mul- timodal knowledge conflict for large multimodal models
[Jiaet al., 2025 ] Yifan Jia, Kailin Jiang, Yuyang Liang, Qi- han Ren, Yi Xin, Rui Yang, Fenze Feng, Mingcai Chen, Hengyang Lu, Haozhe Wang, et al. Benchmarking mul- timodal knowledge conflict for large multimodal models. arXiv preprint arXiv:2505.19509,
-
[17]
Hallucination augmented contrastive learn- ing for multimodal large language model
[Jianget al., 2024 ] Chaoya Jiang, Haiyang Xu, Mengfan Dong, et al. Hallucination augmented contrastive learn- ing for multimodal large language model. InProceedings of the Conference on Computer Vision and Pattern Recog- nition, pages 27036–27046,
2024
-
[18]
Devils in mid- dle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens
[Jianget al., 2025 ] Zhangqi Jiang, Junkai Chen, Beier Zhu, Tingjin Luo, Yankun Shen, and Xu Yang. Devils in mid- dle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25004–25014,
2025
-
[19]
An analysis of visual question answering al- gorithms
[Kafle and Kanan, 2017] Kushal Kafle and Christopher Kanan. An analysis of visual question answering al- gorithms. InProceedings of the IEEE international conference on computer vision, pages 1965–1973,
2017
-
[20]
Mitigat- ing object hallucinations in large vision-language models through visual contrastive decoding
[Lenget al., 2024 ] Sicong Leng, Hang Zhang, et al. Mitigat- ing object hallucinations in large vision-language models through visual contrastive decoding. InProceedings of the Conference on Computer Vision and Pattern Recognition, pages 13872–13882,
2024
-
[21]
Evaluating ob- ject hallucination in large vision-language models
[Liet al., 2023 ] Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating ob- ject hallucination in large vision-language models. InPro- ceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 292–305,
2023
-
[22]
Vrr-vg: Re- focusing visually-relevant relationships
[Liang and others, 2019] Yuanzhi Liang et al. Vrr-vg: Re- focusing visually-relevant relationships. InProceedings of the international conference on computer vision, pages 10403–10412,
2019
-
[23]
Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning
[Liuet al., 2023a ] Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, and Lijuan Wang. Mitigating hallu- cination in large multi-modal models via robust instruction tuning.arXiv preprint arXiv:2306.14565,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Challenges in un- derstanding modality conflict in vision-language models
[Nguyenet al., 2025 ] Trang Nguyen, Jackson Michaels, Madalina Fiterau, and David Jensen. Challenges in un- derstanding modality conflict in vision-language models. arXiv preprint arXiv:2509.02805,
-
[25]
[Parket al., 2025 ] Woohyeon Park, Woojin Kim, Jaeik Kim, and Jaeyoung Do. Second: Mitigating perceptual hallu- cination in vision-language models via selective and con- trastive decoding.arXiv preprint arXiv:2506.08391,
-
[26]
[Qianet al., 2024 ] Yusu Qian, Haotian Zhang, Yinfei Yang, and Zhe Gan. How easy is it to fool your multimodal llms? an empirical analysis on deceptive prompts.arXiv preprint arXiv:2402.13220, 2(7),
-
[27]
Object hallucination in image captioning
[Rohrbachet al., 2018 ] Anna Rohrbach, Lisa Anne Hen- dricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045,
2018
-
[28]
Con- fident adaptive language modeling.Advances in Neural Information Processing Systems, 35:17456–17472,
[Schusteret al., 2022 ] Tal Schuster, Adam Fisch, et al. Con- fident adaptive language modeling.Advances in Neural Information Processing Systems, 35:17456–17472,
2022
-
[29]
[Tong and others, 2025] Bingkui Tong et al. Mitigating hal- lucination in multimodal llms with layer contrastive de- coding.arXiv preprint arXiv:2509.25177,
-
[30]
Towards under- standing how knowledge evolves in large vision-language models
[Wang and others, 2025] Sudong Wang et al. Towards under- standing how knowledge evolves in large vision-language models. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 29858–29868,
2025
-
[31]
mDPO: Conditional preference optimization for multi- modal large language models
[Wanget al., 2024a ] Fei Wang, Wenxuan Zhou, et al. mDPO: Conditional preference optimization for multi- modal large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8078–8088,
2024
-
[32]
[Wanget al., 2024b ] Jiaqi Wang, Yifei Gao, and Jitao Sang. Valid: Mitigating the hallucination of large vision lan- guage models by visual layer fusion contrastive decoding. arXiv preprint arXiv:2411.15839,
-
[33]
[Wanget al., 2025c ] Yujun Wang, Jinhe Bi, Soeren Pirk, Yunpu Ma, et al. Ascd: Attention-steerable contrastive de- coding for reducing hallucination in mllm.arXiv preprint arXiv:2506.14766,
-
[34]
[Wuet al., 2024 ] Xiyang Wu, Tianrui Guan, Dianqi Li, Shuaiyi Huang, Xiaoyu Liu, Xijun Wang, Ruiqi Xian, Abhinav Shrivastava, Furong Huang, Jordan Lee Boyd- Graber, et al. Autohallusion: Automatic generation of hal- lucination benchmarks for vision-language models.arXiv preprint arXiv:2406.10900,
-
[35]
Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts
[Xie and others, 2023] Jian Xie et al. Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts. InThe International Con- ference on Learning Representations,
2023
-
[36]
Knowledge conflicts for LLMs: A survey
[Xuet al., 2024 ] Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu. Knowledge conflicts for LLMs: A survey. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8541–8565,
2024
-
[37]
Lifting the veil on visual information flow in mllms: Un- locking pathways to faster inference
[Yinet al., 2025 ] Hao Yin, Guangzong Si, and Zilei Wang. Lifting the veil on visual information flow in mllms: Un- locking pathways to faster inference. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9382–9391,
2025
-
[38]
Rlhf-v: To- wards trustworthy mllms via behavior alignment from fine-grained correctional human feedback
[Yuet al., 2024 ] Tianyu Yu, Yuan Yao, et al. Rlhf-v: To- wards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. InProceedings of the Conference on Computer Vision and Pattern Recog- nition, pages 13807–13816,
2024
-
[39]
[Zhanget al., 2025a ] Yu Zhang, Jinlong Ma, et al. Evaluat- ing and steering modality preferences in multimodal large language model.arXiv preprint arXiv:2505.20977,
-
[40]
Robust multimodal large lan- guage models against modality conflict.arXiv preprint arXiv:2507.07151,
[Zhanget al., 2025b ] Zongmeng Zhang, Wengang Zhou, Jie Zhao, and Houqiang Li. Robust multimodal large lan- guage models against modality conflict.arXiv preprint arXiv:2507.07151,
-
[41]
[Zhuet al., 2024 ] Tinghui Zhu, Qin Liu, Fei Wang, Zhengzhong Tu, and Muhao Chen. Unraveling cross- modality knowledge conflicts in large vision-language models.arXiv preprint arXiv:2410.03659,
-
[42]
Appendix C offers additional analysis of the late-layer textual override phenomenon, including a representative case study and discussion of potential causes. The remaining sec- tions present additional experimental results (Appendix D), formal definitions of evaluation metrics (Appendix E), imple- mentation details for reproducibility (Appendix F), and q...
2019
-
[43]
yellow” reaches rank 1 but is overridden by “brown
This case exemplifies our central finding: the failure is not one of perception but of preservation. The model correctly encoded the visual information in intermediate layers but did not maintain it through the output. C.2 Why Does Late-Layer Override Occur? We hypothesize that late-layer override stems from train- ing asymmetries in MLLMs. The language m...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.