Pareto Optimal Re-ranking with Semi-Automated Content Credibility Detection
Pith reviewed 2026-06-26 21:49 UTC · model grok-4.3
The pith
A dual-objective optimization re-ranks social media content to raise credibility while deviating at most 7% from the Pareto front in both objectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
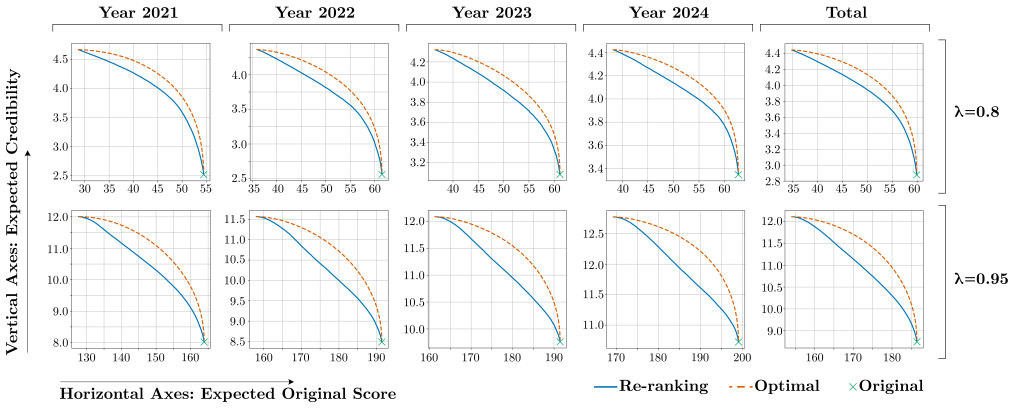
The authors develop a method for re-ranking social media posts that minimizes the Spearman's footrule distance to an existing ranking while also minimizing a linear cost based on credibility scores. They introduce a semi-automated pipeline that assigns these scores by combining retrieval-augmented generation with human-generated fact-checks such as community notes. On real-world X data, this yields re-rankings with at most 7% deviation in both objectives from the Pareto optimal front obtained when initial ranking values are known.
What carries the argument
The dual-objective optimization balancing Spearman's footrule distance to the original ranking against a linear credibility cost to produce near-Pareto optimal re-rankings.
Load-bearing premise
The credibility scores from the semi-automated pipeline accurately reflect actual content credibility without bias.
What would settle it
An experiment that applies the re-ranking to feeds with independently rated credibility improvements and checks whether the deviation from the Pareto front exceeds 7% when scores contain realistic noise or when initial rankings are not known in advance.
Figures

read the original abstract
Social media posts often include misinformative or misleading content, diminishing the expected credibility of content feeds. We present an optimization-based method to improve the credibility of news content on social media feeds by refining existing content rankings. This method is based on a dual-objective optimization approach that minimizes the Spearman's footrule distance to the original ranking to maintain the original content order while incorporating an additional linear cost objective to elevate the expected credibility of the content feed. Additionally, we propose a robust semi-automated pipeline for assigning credibility scores to content based on a mixture of retrieval-augmented score assignments and human-generated fact-checks. This semi-automated pipeline helps ground the credibility assignment using human-generated labels while ensuring the algorithm extends to posts with few or no human-generated labels. We showcase our approach through an experimental setup using real-world data collected over X (Twitter), where we assign the credibility scores based on a mixture of user-generated community notes and retrieval augmented generation. The method we present leads to at most 7% deviation in both optimization objectives from the Pareto optimal front with known initial ranking values. Additionally, the algorithm allows for incorporating different measures for source credibility, making it applicable across various social media platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a bi-objective optimization framework for re-ranking social media posts that minimizes Spearman's footrule distance to an initial ranking while applying a linear cost based on credibility scores. It introduces a semi-automated scoring pipeline that combines retrieval-augmented generation with human fact-checks (e.g., community notes) to assign credibility values. Experiments on real X (Twitter) data are reported to produce re-rankings with at most 7% deviation from the Pareto front in both objectives.
Significance. If the credibility scores prove reliable, the approach supplies a mathematically grounded method for trading off ranking stability against credibility gains, with the semi-automated pipeline offering a scalable labeling solution. The reported proximity to the Pareto front is a clean optimization result, but its downstream value depends entirely on whether the linear cost corresponds to actual content quality.
major comments (3)
- [Abstract / experimental setup] Abstract and experimental section: the central claim of 'at most 7% deviation in both optimization objectives from the Pareto optimal front' is presented without any description of how the front itself was computed, which trade-off weights were swept, what solver or approximation was used, or whether the 7% bound holds across data splits or parameter choices. This information is required to interpret the numerical result.
- [Credibility scoring pipeline] Credibility pipeline description: no accuracy, correlation, or agreement metrics are supplied for the mixture of RAG-generated scores and community notes against any independent ground-truth labels or downstream misinformation indicators. Because these scores directly define the linear cost objective, their unvalidated status renders the real-world interpretation of the 7% deviation result load-bearing and unsupported.
- [Optimization model] Optimization formulation: the bi-objective problem treats the credibility scores as fixed, accurate inputs; the manuscript provides no sensitivity analysis showing how noise or bias in those scores propagates to the reported deviation from the front. This omission directly affects whether the mathematical guarantee translates to improved feed quality.
minor comments (3)
- [Optimization model] Clarify the exact definition and normalization of the linear credibility cost term and how the single free parameter (trade-off weight) is selected or tuned in the reported experiments.
- [Method] Add pseudocode or a clear algorithmic description of the Pareto-front approximation procedure and the re-ranking solver.
- [Experiments] Specify the data collection period, number of posts, and any filtering steps used for the X dataset.
Simulated Author's Rebuttal
Thank you for the constructive referee report. We respond to each major comment in turn and will make revisions to improve the clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract / experimental setup] Abstract and experimental section: the central claim of 'at most 7% deviation in both optimization objectives from the Pareto optimal front' is presented without any description of how the front itself was computed, which trade-off weights were swept, what solver or approximation was used, or whether the 7% bound holds across data splits or parameter choices. This information is required to interpret the numerical result.
Authors: We agree that the experimental section lacks sufficient detail on the Pareto front computation. In the revised manuscript, we will provide a complete description of the procedure used to generate the Pareto front, the trade-off weights considered, the solver or approximation method applied, and results demonstrating the 7% bound across data splits and parameter choices. revision: yes
-
Referee: [Credibility scoring pipeline] Credibility pipeline description: no accuracy, correlation, or agreement metrics are supplied for the mixture of RAG-generated scores and community notes against any independent ground-truth labels or downstream misinformation indicators. Because these scores directly define the linear cost objective, their unvalidated status renders the real-world interpretation of the 7% deviation result load-bearing and unsupported.
Authors: The semi-automated pipeline uses community notes as human fact-check anchors. We acknowledge that explicit quantitative metrics comparing the RAG component to these notes are not reported. In the revision, we will include correlation and agreement metrics on posts with community notes to validate the scores and support the interpretation of the optimization results. revision: yes
-
Referee: [Optimization model] Optimization formulation: the bi-objective problem treats the credibility scores as fixed, accurate inputs; the manuscript provides no sensitivity analysis showing how noise or bias in those scores propagates to the reported deviation from the front. This omission directly affects whether the mathematical guarantee translates to improved feed quality.
Authors: The optimization provides guarantees with respect to the given credibility scores as inputs. We agree that a sensitivity analysis would strengthen the claims regarding real-world applicability. In the revised manuscript, we will add an analysis examining the effect of perturbations in the credibility scores on the deviation from the Pareto front. revision: yes
Circularity Check
No circularity: optimization proximity claim is independent of inputs
full rationale
The paper defines two explicit objectives (Spearman's footrule distance to the initial ranking plus linear credibility cost) and reports that its re-ranking solutions deviate at most 7% from the Pareto front of those same objectives. This is a standard statement about optimizer quality relative to the theoretical front; it does not reduce the reported deviation to a fitted parameter, self-citation, or redefinition of the inputs. The credibility scores enter as fixed external inputs from the described pipeline, and no derivation step equates a result to its own construction. The chain is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- trade-off weight between footrule distance and credibility cost
axioms (2)
- standard math A Pareto front exists and can be approximated for the chosen objectives on the given data.
- domain assumption Credibility scores from the semi-automated pipeline can be treated as a reliable linear cost.
Reference graph
Works this paper leans on
-
[1]
Social media and news fact sheet,
J. Liedke and L. Wang, “Social media and news fact sheet,”Pew Research Center, November 2023. [On- line]. Available: https://www.pewresearch.org/journalism/fact-sheet/ social-media-and-news-fact-sheet/
2023
-
[2]
A survey on web page ranking algorithms,
V . Jain and S. Sharma, “A survey on web page ranking algorithms,” AIP Conference Proceedings, vol. 2721, no. 1, p. 070043, 07 2023. [Online]. Available: https://doi.org/10.1063/5.0156038
-
[3]
Algorithmic amplification of politics on twitter,
F. Husz ´ar, S. I. Ktena, C. O’Brien, L. Belli, A. Schlaikjer, and M. Hardt, “Algorithmic amplification of politics on twitter,” Proceedings of the National Academy of Sciences, vol. 119, no. 1, p. e2025334119, 2022. [Online]. Available: https://www.pnas.org/doi/ abs/10.1073/pnas.2025334119
-
[4]
Combining interventions to reduce the spread of viral misinformation,
J. B. Bak-Coleman, I. Kennedy, M. Wack, A. Beers, J. S. Schafer, E. S. Spiro, K. Starbird, and J. D. West, “Combining interventions to reduce the spread of viral misinformation,”Nature Human Behaviour, vol. 6, no. 10, pp. 1372–1380, Oct 2022. [Online]. Available: https://doi.org/10.1038/s41562-022-01388-6
-
[5]
Returning is believing: Optimizing long-term user engagement in recommender systems,
Q. Wu, H. Wang, L. Hong, and Y . Shi, “Returning is believing: Optimizing long-term user engagement in recommender systems,” CIKM ’17 Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. [Online]. Available: https://par.nsf.gov/biblio/10066038
arXiv 2017
-
[6]
Shifting attention to accuracy can reduce misinformation online,
G. Pennycook, Z. Epstein, M. Mosleh, A. A. Arechar, D. Eckles, and D. G. Rand, “Shifting attention to accuracy can reduce misinformation online,”Nature, vol. 592, no. 7855, pp. 590–595, Apr 2021. [Online]. Available: https://doi.org/10.1038/s41586-021-03344-2
-
[7]
Spearman’s footrule as a measure of disarray,
P. Diaconis and R. L. Graham, “Spearman’s footrule as a measure of disarray,”Journal of the Royal Statistical Society: Series B (Methodological), vol. 39, no. 2, pp. 262–268,
-
[8]
Available: https://rss.onlinelibrary.wiley.com/doi/abs/ 10.1111/j.2517-6161.1977.tb01624.x
[Online]. Available: https://rss.onlinelibrary.wiley.com/doi/abs/ 10.1111/j.2517-6161.1977.tb01624.x
-
[9]
On implementing 2d rectangular assignment algo- rithms,
D. F. Crouse, “On implementing 2d rectangular assignment algo- rithms,”IEEE Transactions on Aerospace and Electronic Systems, vol. 52, no. 4, pp. 1679–1696, 2016
2016
-
[10]
Social media news use and covid- 19 misinformation engagement: survey study,
S. Ahmed and M. E. Rasul, “Social media news use and covid- 19 misinformation engagement: survey study,”Journal of Medical Internet Research, vol. 24, no. 9, p. e38944, 2022
2022
-
[11]
Multimodal fake news detection on social media: a survey of deep learning techniques,
C. Comito, L. Caroprese, and E. Zumpano, “Multimodal fake news detection on social media: a survey of deep learning techniques,” Social Network Analysis and Mining, vol. 13, no. 1, p. 101, 2023
2023
-
[12]
Fake news, disinformation and misinformation in social media: a review,
E. A ¨ımeur, S. Amri, and G. Brassard, “Fake news, disinformation and misinformation in social media: a review,”Social Network Analysis and Mining, vol. 13, no. 1, p. 30, 2023
2023
-
[13]
O’Connor and J
C. O’Connor and J. O. Weatherall,The misinformation age: How false beliefs spread. Yale University Press, 2019
2019
-
[14]
“fake news
M. D. Molina, S. S. Sundar, T. Le, and D. Lee, ““fake news” is not simply false information: A concept explication and taxonomy of online content,”American behavioral scientist, vol. 65, no. 2, pp. 180–212, 2021
2021
-
[15]
The effects of repeating false and misleading information on belief,
R. M. Pillai and L. K. Fazio, “The effects of repeating false and misleading information on belief,”Wiley Interdisciplinary Reviews: Cognitive Science, vol. 12, no. 6, p. e1573, 2021
2021
-
[16]
Media trust under threat: Antecedents and consequences of misinformation perceptions on so- cial media,
M. Stubenvoll, R. Heiss, and J. Matthes, “Media trust under threat: Antecedents and consequences of misinformation perceptions on so- cial media,”International Journal of Communication, vol. 15, p. 22, 2021
2021
-
[17]
The erosion of public trust and sars-cov-2 vaccines—more action is needed,
A. Nahum, D. M. Drekonja, and J. D. Alpern, “The erosion of public trust and sars-cov-2 vaccines—more action is needed,” inOpen forum infectious diseases, vol. 8, no. 2. Oxford University Press US, 2021, p. ofaa657
2021
-
[18]
De Condorcetet al.,Essai sur l’application de l’analyse `a la probabilit´e des d ´ecisions rendues `a la pluralit ´e des voix
N. De Condorcetet al.,Essai sur l’application de l’analyse `a la probabilit´e des d ´ecisions rendues `a la pluralit ´e des voix. Cambridge University Press, 2014
2014
-
[19]
Condorcet’s theory of voting,
H. P. Young, “Condorcet’s theory of voting,”American Political Science Review, vol. 82, no. 4, p. 1231–1244, 1988
1988
-
[20]
Rank aggregation methods for the web,
C. Dwork, R. Kumar, M. Naor, and D. Sivakumar, “Rank aggregation methods for the web,” inProceedings of the 10th International Conference on World Wide Web, ser. WWW ’01. New York, NY , USA: Association for Computing Machinery, 2001, p. 613–622. [Online]. Available: https://doi.org/10.1145/371920.372165
-
[21]
J. G. Kemeny, “Mathematics without numbers,”Daedalus, vol. 88, no. 4, pp. 577–591, 1959. [Online]. Available: http://www.jstor.org/ stable/20026529
arXiv 1959
-
[22]
A new measure of rank correlation,
M. G. Kendall, “A new measure of rank correlation,”Biometrika, vol. 30, no. 1/2, pp. 81–93, 1938. [Online]. Available: http: //www.jstor.org/stable/2332226
arXiv 1938
-
[23]
Unsupervised ensemble of ranking models for news comments using pseudo answers,
S. Fujita, H. Kobayashi, and M. Okumura, “Unsupervised ensemble of ranking models for news comments using pseudo answers,”Advances in Information Retrieval, vol. 12036, pp. 133–140, Mar. 2020
2020
-
[24]
Combination of multiple searches,
E. A. Fox and J. A. Shaw, “Combination of multiple searches,” in Proceedings of The Second Text REtrieval Conference, TREC 1993, Gaithersburg, Maryland, USA, August 31 - September 2, 1993, ser. NIST Special Publication, D. K. Harman, Ed., vol. 500-215. National Institute of Standards and Technology (NIST), 1993, pp. 243–252. [Online]. Available: http://tr...
1993
-
[25]
Efficient similarity search and classification via rank aggregation,
R. Fagin, R. Kumar, and D. Sivakumar, “Efficient similarity search and classification via rank aggregation,” inACM SIGMOD Conference,
-
[26]
Available: https://api.semanticscholar.org/CorpusID: 2358180
[Online]. Available: https://api.semanticscholar.org/CorpusID: 2358180
-
[27]
Reciprocal rank fusion outperforms condorcet and individual rank learning methods,
G. V . Cormack, C. L. A. Clarke, and S. Buettcher, “Reciprocal rank fusion outperforms condorcet and individual rank learning methods,” inProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR ’09. New York, NY , USA: Association for Computing Machinery, 2009, p. 758–759. [Online]. Avail...
arXiv 2009
-
[28]
S. Wang, Q. Deng, S. Feng, H. Zhang, and C. Liang, “A survey on rank aggregation,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, K. Larson, Ed. International Joint Conferences on Artificial Intelligence Organization, 8 2024, pp. 8281–8289, survey Track. [Online]. Available: https://doi.org/10.24963/...
-
[29]
S. Wojcik, S. Hilgard, N. Judd, D. Mocanu, S. Ragain, M. Hunzaker, K. Coleman, and J. Baxter, “Birdwatch: Crowd wisdom and bridging algorithms can inform understanding and reduce the spread of misin- formation,”arXiv preprint arXiv:2210.15723, 2022
arXiv 2022
-
[30]
A survey on automated fact-checking,
Z. Guo, M. Schlichtkrull, and A. Vlachos, “A survey on automated fact-checking,”Transactions of the Association for Computational Linguistics, vol. 10, pp. 178–206, 2022. [Online]. Available: https://aclanthology.org/2022.tacl-1.11
2022
-
[31]
The challenges of machine learning for trust and safety: A case study on misinformation detection,
M. Xiao and J. Mayer, “The challenges of machine learning for trust and safety: A case study on misinformation detection,” 2024. [Online]. Available: https://arxiv.org/abs/2308.12215
arXiv 2024
-
[32]
Api platform
OpenAI, “Api platform.” [Online]. Available: https://openai.com/api
-
[33]
The hungarian method for the assignment problem,
H. W. Kuhn, “The hungarian method for the assignment problem,” Naval Research Logistics Quarterly, vol. 2, no. 1-2, pp. 83–97,
-
[34]
Available: https://onlinelibrary.wiley.com/doi/abs/10
[Online]. Available: https://onlinelibrary.wiley.com/doi/abs/10. 1002/nav.3800020109
-
[35]
Web retrieval agents for evidence-based misinformation detection,
J.-J. Tian, H. Yu, Y . Orlovskiy, T. Vergho, M. Rivera, M. Goel, Z. Yang, J.-F. Godbout, R. Rabbany, and K. Pelrine, “Web retrieval agents for evidence-based misinformation detection,” in First Conference on Language Modeling, 2024. [Online]. Available: https://openreview.net/forum?id=pKMxO0wBYZ
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.